02 架构核心技术之分布式缓存(下)
-
-
旁路缓存:旁路缓存通常是一种独立的键值对存储,对象缓存就是一种旁路缓存。和通读缓存不同,客户端访问数据时,先到旁路缓存中查看,如果有就返回,如果没有,客户端自己到数据中心服务器获取数据。
-
各种介质数据访问延迟如下,1s=1000ms=10^9ns=10亿ns
![]()
-
合理使用缓存对象:
-
注意频繁修改的数据:缓存数据是为一次写入多次读取准备的,如果刚写入的数据就很快被修改,数据还没来得及被读取,那缓存就没有意义,还增加了系统负担。一般来说,数据的读写比例在2:1以上,缓存才有意义。
-
注意没有热点的数据:几乎不会被访问到的数据就不算热点数据,这样的数据缓存意义不大,浪费系统空间。
-
注意数据不一致和脏读:缓存中的数据可能和主存数据库中的数据不一致,这个问题主要通过时效来解决的。失效时间控制在业务能够容忍的范围内即可。如果业务场景对数据更新敏感,数据更新时,则不能靠失效来解决,需要进行失效通知,立刻清除缓存中数据,下次访问的时候再重新从主存数据库中加载到缓存中,这样实时得到最新数据。
-
缓存雪崩:如果缓存崩溃或所有缓存失效,则所有访问压力都到了数据库,数据库不堪重压也崩溃,大量请求堆积,最终导致应用程序崩溃,服务迟迟不能响应,可能最终导致整个服务网站崩溃,这就是缓存雪崩。缓存部分数据丢失可以到数据库加载,但是全部数据丢失就可能造成缓存雪崩,所以设计缓存时特别注意。缓存雪崩可以通过设置缓存不同Key不同过期时间、做多级缓存等,主要是避免大量请求到数据库。
-
-
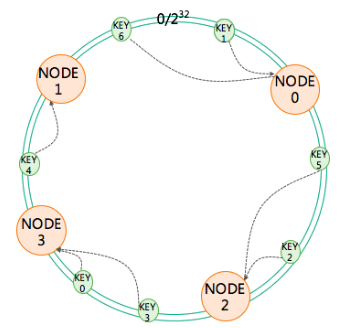
分布式对象缓存: 是指对象缓存以分布式集群的方式对外提供服务,多个应用使用同一个分布式对象缓存对外提供缓存服务,这样通过集群方式,提供了更多的缓存空间。 分布式缓存对象由多个服务器组成,所以需要路由算法来确定缓存对象在哪个服务器上。以Memcahed为例,Memcached客户端API程序根据Key进行计算,使用自己的路由算法选择缓存对象服务器。路由算法选择服务器,主要是通过哈希表的路由算法,比如是通过key的哈希值对缓存服务器个数求余取模得到服务器对象,这种算法有个缺陷,就是当缓存服务器数量变化时,之前路由算法得到的key全部失效,很可能造成缓存雪崩。解决这个问题的主要手段是使用一致性哈希算法。 一致性哈希算法不同于取模哈希,一致性哈希算法首先构建一个一致性哈希环的结构。一致性哈希环大小是0~2^32-1。
![]()
对所有缓存服务器取哈希值放到环上,每次存储缓存对象路由查找服务器时,对缓存对象Key求哈希值,也把Key的哈希值放到环上,然后顺时针查找距离这个Key最近的服务器节点,该服务器就是要存储这个缓存对象的服务器。如果出现缓存服务器增加或减少情况,根据上述路由算法,也只能影响到服务器逆时针方向上的到下一个缓存服务器之间的Key,并不会发生全部Key失效,造成缓存雪崩的现象。 一致性哈希算法也有个致命缺陷,就是出现服务器在环上分布不均匀,导致某些缓存服务器上数据很多,某些缓存服务器上数据几乎没有。这个算法的改进办法就是先将一台缓存服务器节点虚拟若干个节点,一般是200个,然后再放到一致性哈希环上。根据Key路由查找服务器方法不变,只是找到虚拟节点后,要根据一定的映射关系映射到真实的物理节点。这样不但可以解决缓存服务器集群负载不均衡问题,还可以在加入新节点时,由于是虚拟成若干节点,这样就有可能影响到环上的每个节点,从而分摊原先服务器上的一部分负载。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号