Hadoop综合大作业
Hadoop综合大作业
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
Hadoop综合大作业 要求:
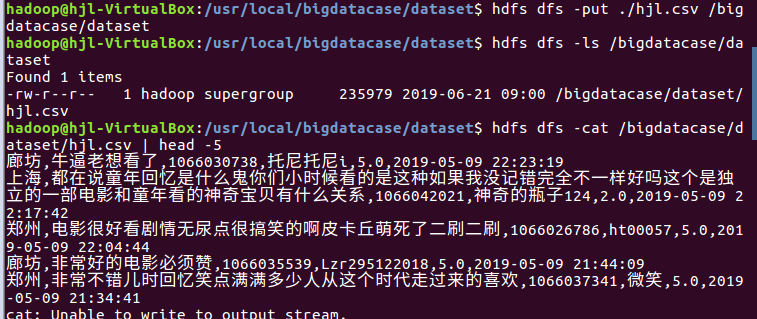
1.对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
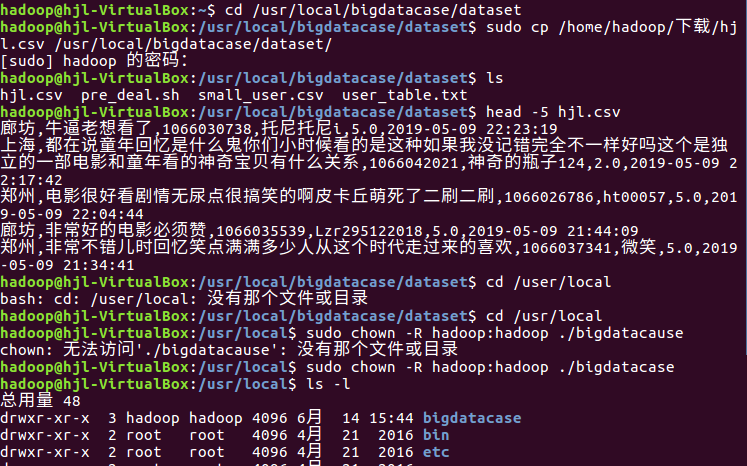
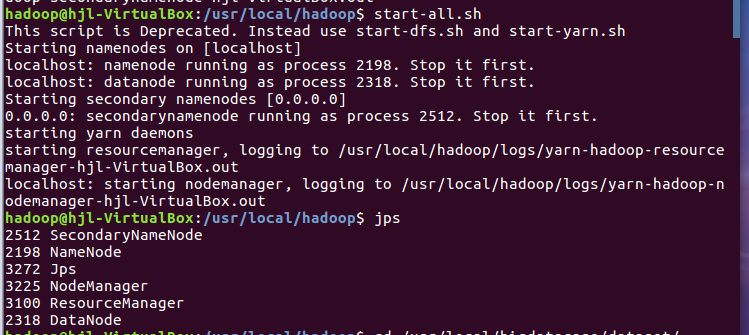
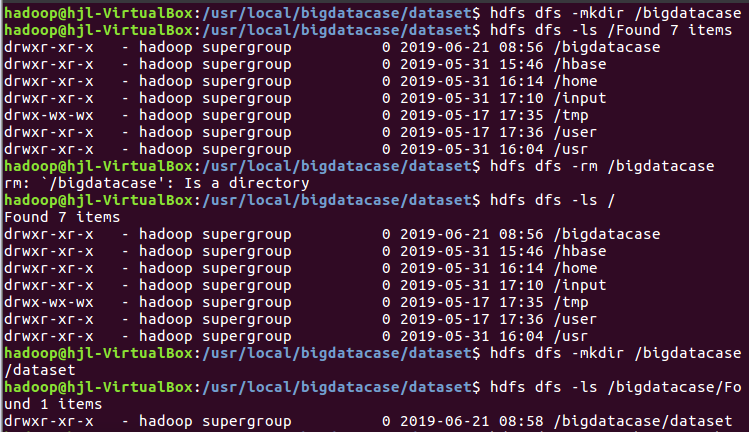
2.把hdfs中的文本文件最终导入到数据仓库Hive中

其次,把hdfs中的文本文件最终导入到数据仓库Hive中,并在Hive中查看并分析数据,具体步骤如下:
① create database db;
② use db;
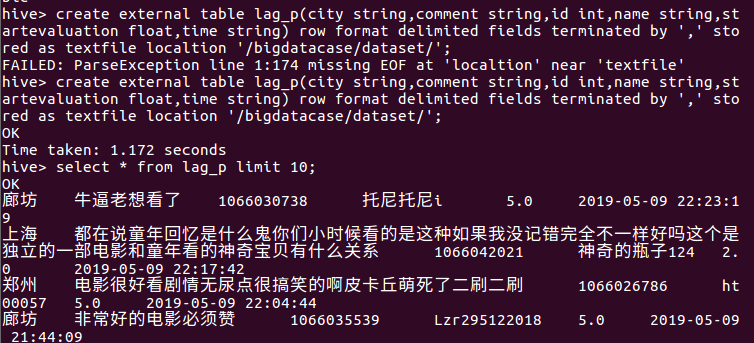
③ create external table lag_p(city string,comment string,id int,startevaluation float,time string) row format delimited fields terminated by ',' stored as textfile location '/bigdatacase/dataset/';
④ select * from lag_p limit 10;
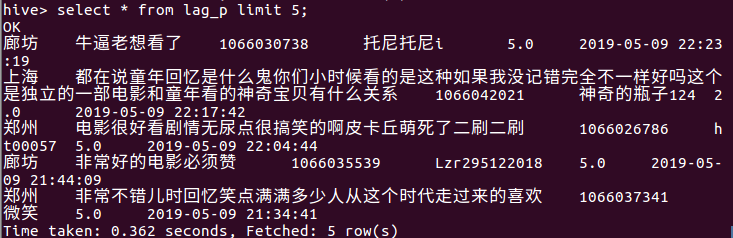
3.Hive中查看并分析数据
4.用Hive对爬虫大作业产生的数据进行分析(10条以上的查询分析)
(1)计算出表内一共有几条评论数据

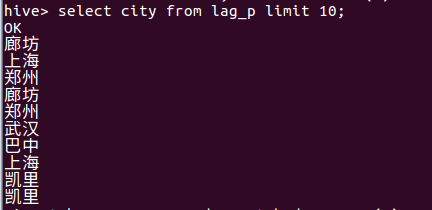
(2)查询前十条信息的所属城市
(3)查询前二十条信息的用户名
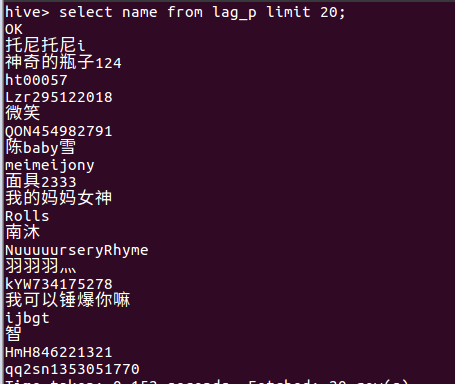
(4)查询不重复昵称的评论数
(5)查询城市中评分为5分的数量最多的前20名

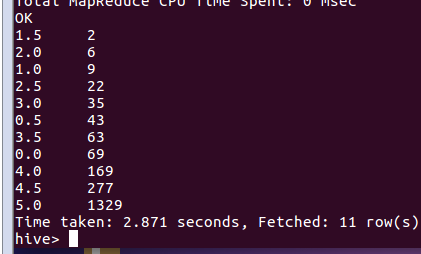
(6)查看评论里各评分的评论数

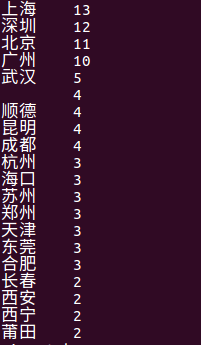
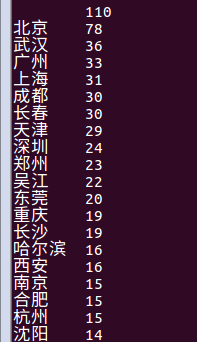
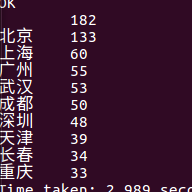
(7)查询评论数前10名的城市
![]()
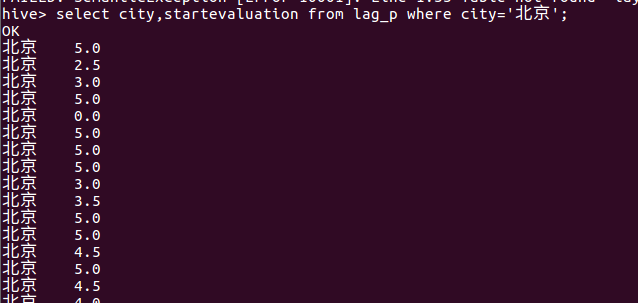
(8)查询北京的评分
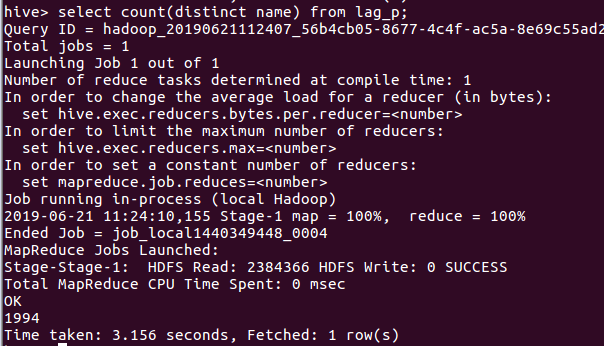
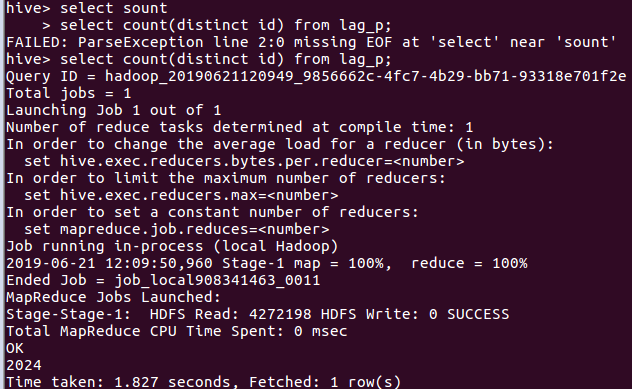
(9)查询不重复id的评论数
(10)查询城市中评低于3分的前20名
![]()