爬虫综合大作业
一.设置合理的user-agent,模拟成真实的浏览器去提取内容
# 设置合理的user-agent,爬取数据函数
def getData(url):
headers = [
{
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36',
'Cookie': '_lxsdk_cuid=16a8d7b1613c8-0a2b4d109e58f-b781636-144000-16a8d7b1613c8; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; uuid_n_v=v1; iuuid=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; webp=true; ci=20%2C%E5%B9%BF%E5%B7%9E; selectci=; __mta=45946523.1557151818494.1557367174996.1557368154367.23; _lxsdk=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; __mta=45946523.1557151818494.1557368154367.1557368240554.24; from=canary; _lxsdk_s=16a9a2807fa-ea7-e79-c55%7C%7C199'},
{
'User-Agent': 'Mozilla / 5.0(Linux;Android 6.0; Nexus 5 Build / MRA58N) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 73.0 .3683.103Mobile Safari / 537.36',
'Cookie': '_lxsdk_cuid=16a8d7b1613c8-0a2b4d109e58f-b781636-144000-16a8d7b1613c8; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; uuid_n_v=v1; iuuid=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; webp=true; ci=20%2C%E5%B9%BF%E5%B7%9E; selectci=; __mta=45946523.1557151818494.1557367174996.1557368154367.23; _lxsdk=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; __mta=45946523.1557151818494.1557368154367.1557368240554.24; from=canary; _lxsdk_s=16a9a2807fa-ea7-e79-c55%7C%7C199'},
{
'User-Agent': 'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Cookie': '_lxsdk_cuid=16a8d7b1613c8-0a2b4d109e58f-b781636-144000-16a8d7b1613c8; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; uuid_n_v=v1; iuuid=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; webp=true; ci=20%2C%E5%B9%BF%E5%B7%9E; selectci=; __mta=45946523.1557151818494.1557367174996.1557368154367.23; _lxsdk=1BB9A320700C11E995DE7D45B75E59C6FC50A50D996543D0819E9EB2E6507E92; __mta=45946523.1557151818494.1557368154367.1557368240554.24; from=canary; _lxsdk_s=16a9a2807fa-ea7-e79-c55%7C%7C199'}
]
get = requests.get(url, headers=headers[random.randint(0, 2)]);
get.encoding = 'utf-8'
return get
二、对爬取的数据进行处理,生成
# 数据处理函数
def dataProcess(data):
data = json.loads(data.text)['cmts']
allData = []
for i in data:
dataList = {}
dataList['id'] = i['id']
dataList['nickName'] = i['nickName']
dataList['cityName'] = i['cityName'] if 'cityName' in i else '' # 处理cityName不存在的情况
dataList['content'] = i['content'].replace('\n', ' ', 10) # 处理评论内容换行的情况
dataList['score'] = i['score']
dataList['startTime'] = i['startTime']
if "gender" in i:
dataList['gendar'] = i["gender"]
else:
dataList['gendar'] = i["gender"] = 0
allData.append(dataList)
return allData
三、把爬取的数据生成csv文件和保存到数据库。
# 处理后的数据保存为csv文件
pd.Series(allData)
newsdf = pd.DataFrame(allData)
newsdf.to_csv('hjl.csv', encoding='utf-8')

四、数据可视化分析。
# 评论者评分等级环状饼图
def scoreProcess(score):
from pyecharts import Pie
list_num = []
list_num.append(scores.count(0))
list_num.append(scores.count(0.5))
list_num.append(scores.count(1))
list_num.append(scores.count(1.5))
list_num.append(scores.count(2))
list_num.append(scores.count(2.5))
list_num.append(scores.count(3))
list_num.append(scores.count(3.5))
list_num.append(scores.count(4))
list_num.append(scores.count(4.5))
list_num.append(scores.count(5))
attr = ["0", "0.5", "1","1.5","2","2.5", "3", "3.5","4","4.5","5"]
pie = Pie("评分等级环状饼图",title_pos="center")
pie.add("", attr, list_num, is_label_show=True,
label_text_color=None,
radius=[40, 75],
legend_orient="vertical",
legend_pos="left",
legend_top="100px",
center=[50,60]
)
pie.render("score_pie.html")

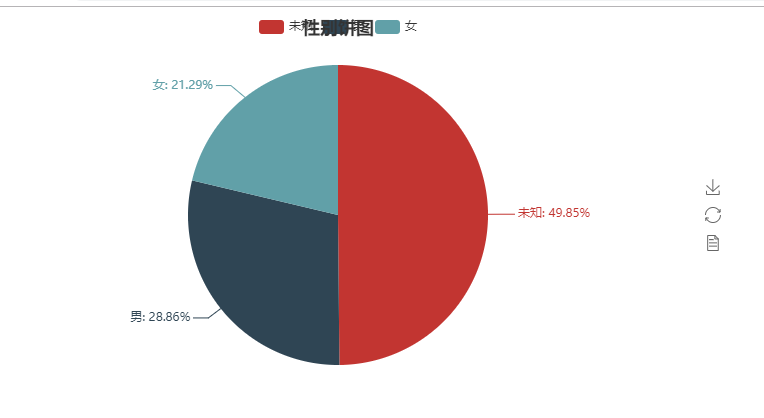
性别饼图