
Mysql基础
Mysql
DB
DCL:Data control language 数据控制语言
grant , revoke,commit,rollback、savepoint
DDL: Data Definition language 数据定义语言 也就是增删改查
create table xxx.
drop table.
alter
rename
DML: Data manipulation language 数据操纵语言
insert into XXX(id,xxx) values()
DBA: DataBase Administer 数据库管理人员
ER: Entity-Relationship 实体-联系方法
SQL: structured query language 结构化查询语言
GPL:GNU General public license 代码的开源/免费使用和引用/修改/衍生代码的开源/免费使用 比如linux使用该协议。
142、no Relational DB 有哪些
所谓关系型数据库,就是将复杂的数据归结为简单的二元关系。即为二维表格
mongdb: document
redis: key-value
elasticsearch: search engine
Hbase:列式存储
infoGrid:图形数据库
Mysql8一下默认字符集使用的是latin,utf字符集指向的是utf8mb3(3个字节存储汉字), 8以上默认utf-8mb4
使用soucre 文件路径的绝对路径 导入外部sql文件。
注意:我们使用的sql仅仅是sql标准在mysql中的体现,可以说是我们使用的mysql的sql方言
只有列名取别名的时候使用双引号“” . 其他字符串情况使用单引号 ''.
=,<=>(允许Null之间比较,安全等于),<>(不等于)
算术运算符
比较运算符


逻辑运算符

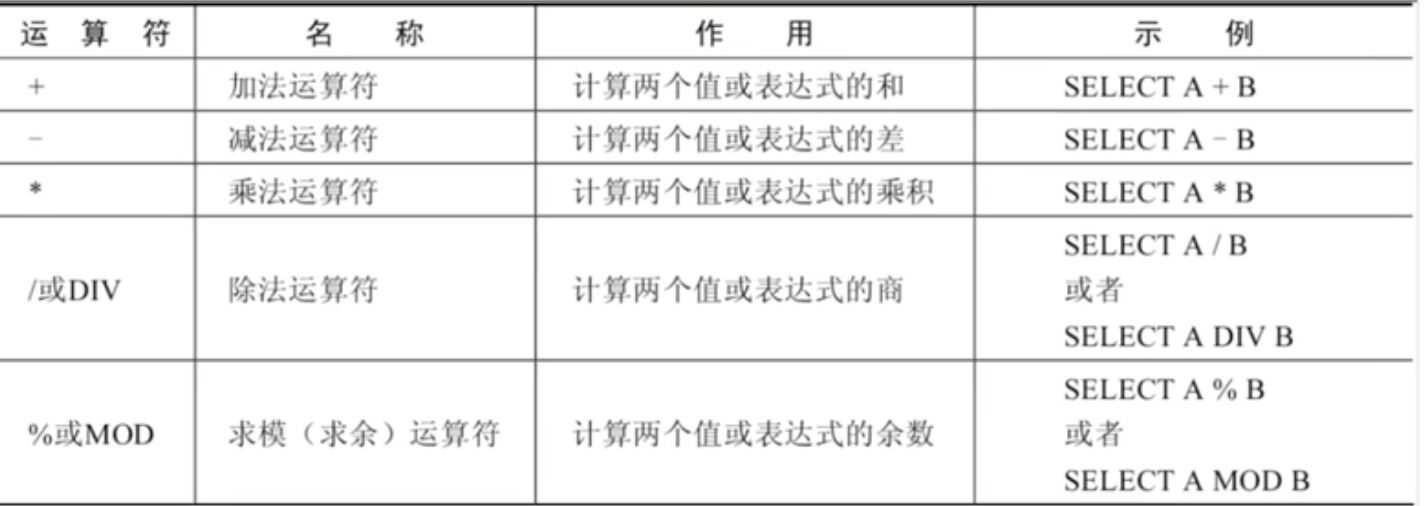
位运算符
**order by attribute asc/desc; **
注意:列的别名只能使用在having、order by 中、不能使用在where中
原理:操作从from开始,故where不能使用别名。 1、from where 过滤条件2、select 语句 3、select 出来的语句having 或者order by操作。
select salary sa,id
from employee
order by sa desc,id asc;
分页使用limit
mysql8.0新特性:limit pageSize offest (pageNum-1)*pageSize
select *
from employee
limit 0,20 # 每页显示20条记录,此时显示第一页
limit 20,20 # 每页显示20条记录,此时显示第二页
limit 40,40 # 每页显示20条记录,此时显示第三页
# 公式
limit (pageNum-1)*pageSize,pageSize
limit 位置偏移量,条目数
select ..
from ..
where .. and/or/not
order by .. (asc/desc)
limit ..
如果查询语句中出现了多个表中都存在的字段、则必须指明此字段所在的表 sql优化
select employee.employee_id,departments.department_name,employee.department_id
from employee,departments
where departments.`department_id` = employee.`employee_id`
sql92语法
select
from a,b,c
sql99语法实现内连接
Join = inner join
select *
from employee e join departments d
on e.xx = d.xx
join localtion l
on d.xxx = l.xxx
sql99语法实现外连接
Left join = left outer join
select *
from employee e left join departments d
on e.xx = d.xx
sql99语法实现全外连接、但是mysql不支持、pgsql、sqlLite支持
既然无法使用full join得到左下和右下的结果,我们采用左上和右中进行Union All的操作、左中和右中Union All得到右下的
select employee_id,department_name
from employee e left join departments d
on e.department_id = d.department_id
UNION ALL
select employee_id,department_name
from employee e right join departments d
on e.department_id = d.department_id
where e.department_id IS NULL
Union关键字

建议使用union all,这样不会去重。
sql99新语法,Natural Join,它会帮你自动查询二张连接表中所有相同的字段,然后进行等值连接
select
from employee e NATURAL JOIN departments d;
sql99新语法,Using指定了具体的相同的字段名称,可以简化Join On的等值连接
select
from employee e JOIN departments d
using (department_id)
表连接的约束条件可以有三种方式:WHERE、ON、USING
- where 使用于所有关联查询
- ON 只能和JOIN一起使用
- USING 只能和JOIN一起使用,并且要求二个关联字段在关联表中名称一致

最好这样写:
select *
from employee e join departments d
on e.xx = d.xx
join localtion l
on d.xxx = l.xxx
而不是这样写:
select *
from employee e join departments d join location l
on e.xxx = d.xxx
and d.xx = l.xx
mysql系统函数
DBMS之间的差异性很大、远大于同一个语言不同版本之间的差异. mysql方言的sql函数与oracle方言的sql函数差别很大
Mysql提供的内置函数从实现的角度来看可以分为数值函数、字符串函数、日期和时间函数、流程控制函数、加密与解密函数、获取Mysql信息函数、聚合函数等。
在这里主要分为二类:单行函数【进去一个出来一个】,聚合函数(多行函数【进去多个出来一个】)
单行函数
- 数值函数
- 日期和时间函数
- 流程控制函数
- 加密与解密函数
- 获取mysql信息函数
聚合函数:它是对一组数据进行汇总的函数、输入的是一组数据的集合,输出的是单个值
1、常见的几个聚合函数
- AVG/SUM 不会计算空值
- MAX/MIN
- COUNT:计算指定字段在结构查询中出现的个数
- count(1)
- Count(*)
- Count(列名) 但是不包含Null值
count(1)、count(*)、count(列名)那个效率更高呢
如果使用的是MyISAM引擎,三者效率一样,都是O(1)。
如果使用的是InnoDB引擎,Count(*) = count(1)> count(字段)
2、Group By的使用
select department_id.job_id.AVG(salary)
from employees
group by department_id,job_id
# 二级分类
注意:select中出现的非组函数的字段必须声明在Group By中、反之,Group By中声明的字段可以不出现在select中。
比如:
select department_id.job_id.AVG(salary)
from employees
group by department_id
#会导致job_id 显示不全
3、Having的使用
如果过滤条件使用了聚合函数、那么久必须使用Having。
Having:对分组查询的结果进行过滤。
通常使用Having的前提是sql中使用了Group By.
# 推荐方式一、执行效率更高
select department_id,MAX(salary)
from employees
where department_id IN (10,20,30,40)
group by department_id
having MAX(salary) > 10000;
# 方式二
select department_id,MAX(salary)
from employees
group by department_id
having MAX(salary) > 10000 AND department_id IN (10,20,30,40).
4、SQL底层执行原理
当过滤条件中没有聚合函数时,则此过滤条件必须声明在having中。
当过滤条件中没有聚合函数时,则此过滤条件声明在Where中或者Haing中都行,但建议(一定)声明在Where中。
where 和having 的区别
1、适用范围:Having更广.
2、如果过滤条件中没有聚合函数,where的执行效率要高于having。
Select 语句的完整结构
# sql 92 语法
select ... (存在聚合函数)
From ..
Where 多表的连接条件 and 不包含聚合函数的过滤条件
group by ...,...
Having 包含聚合函数的过滤条件
order by .. asc/desc
Limit x,y
# sql 99 语法
select ... (存在聚合函数)
From ... (left/Right)join ... on 多表的连接条件
join ... on ...
where 不包含聚合函数的过滤条件
group by ...,...
Having 包含聚合函数的过滤条件
order by .. asc/desc
Limit x,y
sql语句的执行过程
From -> Where -> Group By -> Having
->select 的字段 -> Distinct
->Order By -> Limit
144、子查询
select last_name,salary
from employees
where salary > (
select salary
from employees
where last_name = 'Abel'
);
子查询在主查询之前一次执行完成。
1、单行子查询操作符
= < > <= >= <> .
2、多行子查询操作符
IN: 等于列表中的任意一个
ANY: 需要和单行操作符一起使用,和子查询返回的某一个值比较
ALL:需要和单行操作符一起使用,和子查询返回的全部值比较
SOME:与ANY一样
select employee_id,last_name,job_id,salary
from employees
where job_iod <> 'IT_PROG'
AND salary < ALL (
select salary
from employees
where job_id = 'IT_PROG'
);
extention :使用临时表
select MIN(avg_sal)
from (
select AVG(salary) avg_sal
from employees
group by department_id
) as t_dept_avg_sal
相关子查询
为什么是相关:因为子查询与主查询有关系,子查询是一个变量。
比如下面的sql, e1 与 e2笛卡尔积, e1的每一行的department_id 都是不一样的.
查询员工中工资大于本部门平均工资的员工的last_name, salary 和department_id
select last_name, salary, department_id
from employees e1
where salary > (
select AVG(salary)
from employees e2
where department_id = e1.department_id
);
EXISTES
关联子查询通常也会和Exists操作符一起来使用,用来检查在子查询中是否存在满足条件的行.
-
如果在子查询中不存在满足条件的行
- 条件返回false
- 继续在子查询中查找
-
如果在子查询中存在满足条件的行
-
条件返回true
-
不在子查询中查找
-
select employee_id,last_name,job_id,department_id
from employees e1
where exists(
select *
from employees e1
where e1.employee_id = e2.manager.id
);
e1 与 e2 笛卡尔积之后, 如果e1.employee_id = e2.manager.id成功就break. 效率会高一点.
DDL管理
1、create database test;
2、create database test character set '';
show create database test;
3、create database test if not exist character set '';
修改数据库
注意:数据库不能重命名.
alter database 数据库名 character set 'utf8mb4'
删除数据库
drop database test.
drop database test if exists.
创建数据库表
create table if not exists my_table(
id int,
emp_name varchar(15),
hire_date DATE
);
创建一个表mytemp,实现对employees表的复制、包括表数据。(数据库可视化工具重命名数据库就是这样做的)
create table mytemp
as
select * from employee
创建一个表mytemp,实现对employees表的复制、不包括表数据。
create table mytemp
as
select * from employee
where 1=0
修改表
添加一个字段:
alter table mytemp
add salary DOUBLE(10,2) # 小数点前10位,后面2位
;
修改一个字段:数据类型、长度、默认值
alter table mytemp
modify emp_name varchar(25) default 'A';
重命名一个字段:
alter table mytemp
change emp_name new_name DOUBLE(10,2);
删除一个字段:
alter table mytemp
drop column new_name
重命名表
rename table mytemp to mytemp_new; # method 1
alter table mytemp rename to mytemp_new # method 2
删除表
drop table if exists mytemp;
清空表
truncate table if exists mytemp; ## DDL
# 不可回滚
delete from table if exists mytemp; ## DML
# 可以删除全部或部分数据、可回滚
DDL 与 DML的区别
- 前者不可回滚、执行了 set atuocommit = false也不生效(执行DDL之后一定会执行commit,并且不受影响)
- 后者默认情况下不可回滚,但是如果在执行DML之前,执行了 set atuocommit = false. 则可以回滚。
阿里开发规范

DCL
commit和rollback
commit:提交数据、一旦执行commit、则数据被永久的保存在了数据库中,意味着数据不可以回滚。
rollback:回滚数据,一旦执行rollback,则可以实现数据的回滚。回滚到最近的commit。
在ALTER table的时候,也应该确保数据的完整备份。
注意:mysql8以上,InnoDB表的DDL支持原子性DDL,即DDL操作要么成功要么回滚。DDL操作回滚日志写入到data dictionary数据字典表mysql.innodb_ddl_log(该表是隐藏的表,通过show tables无法查看)
drop table a1,a2.
# a1 存在、a2不存在。 在mysql8中要么成功、要么失败。
DML 之增删改
同时添加多条记录(推荐)
insert into emp1(id,name,salary)
values
(1,'1',3000),
(11,'12',4000)
将查询结果插入到表中
insert into emp1
select employee_id,employee_name,employee_salary
from employee
where department_id IN (60,70)
# 查询到字段一定要和添加到的表的字段一一对应
添加方式二:
insert into my_employees
select 1,'ad','23','12',899 UNION ALL
select 2,'add','213','112',19 ;
修改数据
update [tableName] set ... where...
update emp1
set salary=5000,name='222'
where id =4;
删除数据
在删除数据时,也有可能因为外健的约束、导致删除失败/
delete from [tableName] where ...
delete from emp1
where id=1;
DML默认情况下,执行完成后都会自动提交数据。如果希望执行完成之后不自动提交数据,则需要使用set autocommit=false 这样可以rollback到上次提交到的记录/
MYsql8新特性、计算列
某一列的值是通过别的列计算得来的。例如,a列值为1,b列值为2,c列不需要手动插入,定义a+b的结果为c的值,那么a+b就是c的值,那么c就是计算列。
create table test(
a int,
b int,
c int generated always as (a+b)
);
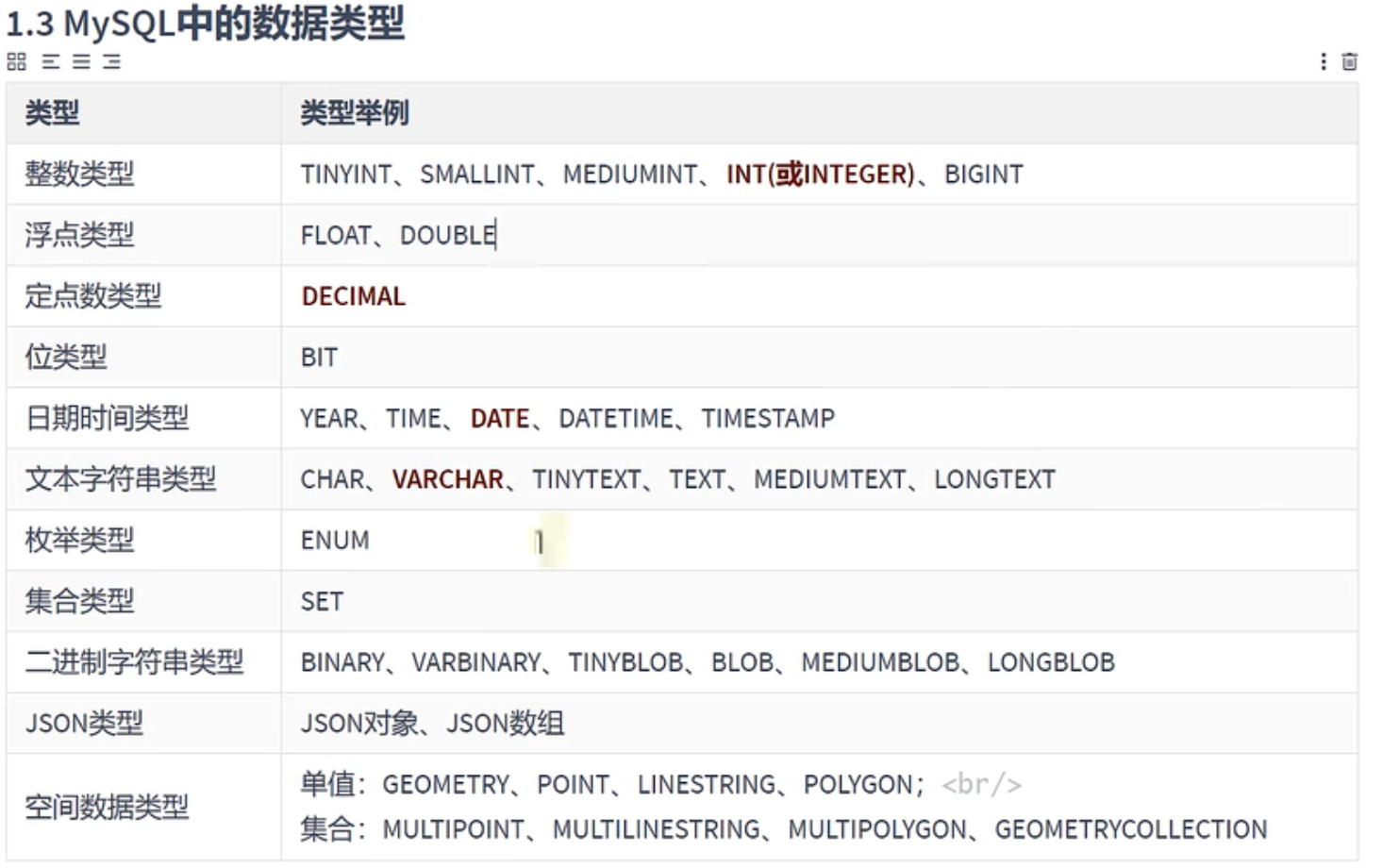
mysql数据类型

mysql字符集
字段字符集 look up 表字符集 look up 数据库字符集 look up my.ini 里面设置的字符集编码规则.
整数表示范围
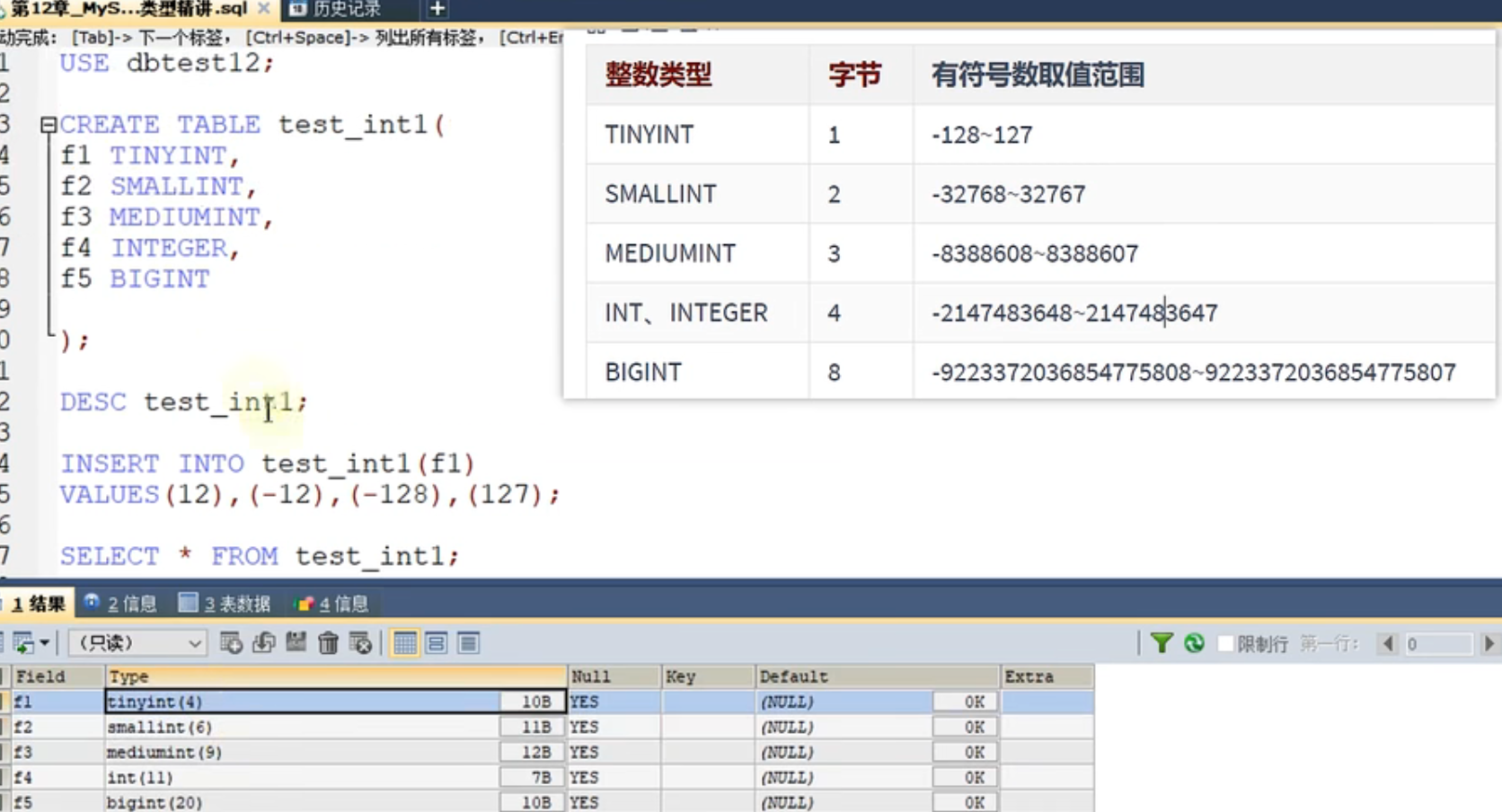
mysql8以下会默认带有数据的宽度, tinyint(4) 表示它表达的宽度为4位,负号也算一位。与Zero Fill搭配使用提供0填充的功能。mysql8以后不推荐使用宽度。
整数可选属性
- (M) 表示宽度
- unsigned 无符号
- zerofill 0填充
浮点数:float4字节、double 8字节。
浮点数数据精度说明: FLOAT(M,D)这里M称为精度,D称为标度. M = 整数位 + 小数位, D=小数位.FLOAT(5,2)的一个列可以显示为-999.99 ~ 999.99
定点数DECIMAL
DECIMAL(M,D) . 同理
DECIMAL(5,2)表示-999.99 ~ 999.99
定点数是使用字符串的形式进行存储的。所以是一定精准的
不指定精度和标度,其默认位DECIMAL(10,10)
当插入67.567 into DECIMAL(5,2)的时候会存在四舍五入的问题
插入0.001 和0.009的时候进行求和, 不会产生误差。
- 涉及到钱、或者要求特别精准的情况使用 decimal。
位类型BIT
位也有精度
Bit(0<M<=64)
日期与时间类型

一句话:推荐使用DATETIME
文本字符串类型


Char类型
- Char(M)类型一般需要预先定义字符串长度。如果不指定,则默认长度是1个字符
- 如果保存时,数据的实际长度比Char类型声明的长度小,则会在右侧填充空格以达到指定的长度。当mysql检索char类型的数据时,char类型的字段会去除尾部的空格。
- 定义char类型字段时,声明的字段长度即为char类型字段所占的存储空间的字节数。
Varcahr类型
- varchar(M)定义时,必须指定长度M,否则报错。存储M个字符。
- 检索varchar类型的字段数据时,会保留尾部的空格。varchar实际占用的存储空间再加一个字节。

5.5 以后默认都是innoDB
Text类型
Text文本类型,可以存储较大的文本段,搜索速度较慢,如果不是特别大的,建议使用char、varchar。
text和blob类型删除后容易导致“空洞”,使得文件碎片较多,频繁使用的表不建议包含text,而是分出去,单独使用一个表。
ENUM类型
mysql> create table text_enum(
-> season enum('春','夏','秋'));
insert into text_enum values('春');
insert into text_enum values(1);
enum 是可以通过index添加的。
Set 类型
mysql> create table test_set(
-> s set('A','B','C'));
insert into test_set values('A'),('A,B');
insert into test_set values('A'),('B');
二进制字符串类型
二进制字符串类型

Blob类型


JSON类型
JSON可以将js对象转换为字符串。
#创建JSON字段
create table test_json(
js JSON);
#插入
insert into text_json(js) vlaues({"names":"123","age":18,"address":{"province":"hebei","city":"shijiazhuang"});
#查询
select js -> '$.name' as name,js ->'$.age'as age,js ->'$.address.province'as province, js->'$.address.city'as city
from test_json;
数据类型总结

约束Constraint
数据完整性(Data Integrity)是指数据的精确性(Accuracy)和可靠性(Reliability)。它是防止数据库中存在不符合语义规定的数据和防止因错误信息的输入输出造成无效操作或错误信息而提出的。
为了保证数据的完整性,SQL规范以约束的方式对表数据进行额外的条件限制。从以下四个方面考虑
- 实体完整性(Entity Integrity):例如,同一个表中不能存在完全相同无法区分的记录。
- 域完整性(Domain Integrity):例如,年龄范围0-12,性别范围为“男/女”
- 引用完整性(Referential Integrity):例如,员工所在部门,在部门表中要能找到这个数据
- 用户自定义完整性(User-defined Integrity):例如,用户名唯一、密码不为空等。
约束是表级的强制规定,为了保证数据的完整性。
表级约束与列级约束:
- 列级约束:将此约束声明在对于字段的后面。
create table test1(
id int unique,
);
- 表级约束:在表中字段都声明完之后,在所有字段的后面声明约束。
create table test2(
id int unique,
last_name varchar(25),
email varchar(25),
salary decimal(10,2),
CONSTRAINT uk_test2_email UNIQUE(email)
);
约束的作用
- not null 非空约束
- unique 唯一性约束
- primary key 主键约束
- check 检查约束
- default 默认值约束
如何添加约束
create table 添加约束
alter table时添加约束。
alter table test
modify email varchar(25) not null;
#or
alter table test
add constraint yk_test_email unique(salary)
# or
alter table test
modify salary varchar(25)unique
删除约束
alter table test
drop index yk_test_email
主键约束
作用:用来唯一表示表中的一行记录。
primary key 相当于 not null + unique.
当创建主键索引时,系统默认会在所在的列或组合上建立对应的主键索引。
Mysql的主键名总是PRIMARY,就算自己起名了主键约束名也没用
1、创建主键索引
create table test(
id int primary key);
# or
create table test(
id int,
constraint primary key(id)
);
#or
alter table test
add primary key(id)
2、删除主键约束(但没人这么做)
alter table test
drop primary key
自增列
auto_increment 某个字段自增.
create table test(
id int primary key auto_increment
);
#or
alter table test modify id int auto_increment;
# 删除auto_increment
alter table test modify id int.
注意:
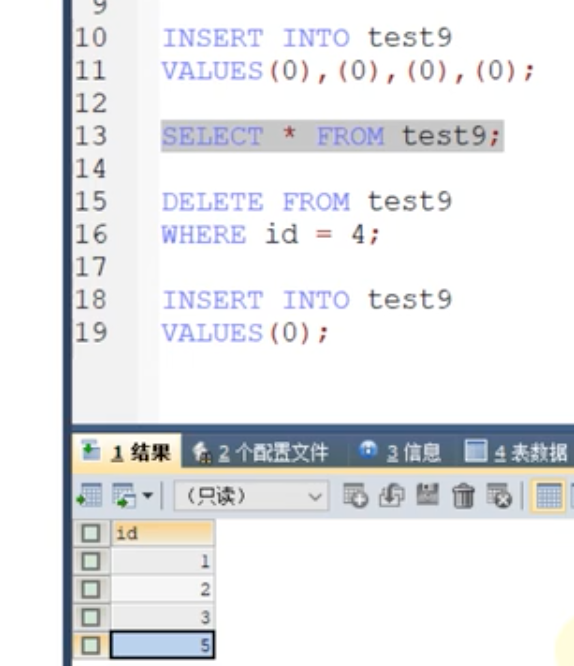

删除某一id时,再插入不会再连续了。
Mysql8新特性-自增变量的持久化:在mysql8以前:如果重启mysql服务,将id=5 删除再插入,新的id=4。这是因为,mysql 自增有缓存,重启清理了缓存之后,新的自增值从表中最新的id读取。
结论:mysql8以上将自增变量放入了undo日志,mysql8以前放在了内存中计数器
外键约束
作用:限制某个表的某个字段的引用完整性。
比如:员工表的员工所在部门的选择,必须在部门表中能找到对应的部分。
总结:阿里规范不得使用外键,一切外键必须在应用层解决。
学生表中的student_id是主键,那么成绩表中的student_id 则为外键。如果更新学生表中的studnet_id,同时触发成绩表中的student_id 更新,即为级联更新。外键与集联更新适用于单机地并发,不适合分布式、高并发集群。集联更新是强阻塞,存在数据库更新风暴的风险,外键影响数据库的插入速度。
check约束
作用:检查某个字段是否符合xx要求,一般是值的范围。
仅mysql8支持。
create table employee(
eid int ,
gender char check ('男' or '女'),
salary decimal(10,2) check(salary>2000)
);
default约束
作用:给某个字段指定默认值,一旦设置默认值,在插入数据的时候,如果此字段没有显示赋值,则赋值为默认值。
create table test(
id int,
last_name varchar(15),
salary decimal(10,2) default 2000);
添加、删除约束
alter table test modify salary decimal(10,2) default 2500; # add
alter table test modify salary decimal(10,2) ; # remove
视图
为什么使用视图:
视图一方面可以帮我们使用表的一部分而不是所有的表,另一方面也可以针对不同的用户指定不同的查询视图。
比如,一个公司的销售人员,只想给他看一部分数据,而敏感的数据不会提供给他。
视图的理解:
- 视图是一种虚拟表,本身是不具有数据的,占用很少的内存空间,它是SQL中的一个重要概念。
- 视图建立在已有表的基础上,视图赖以建立的这些表称为基表
- 本质:视图就是存储起来的select语句。
- 视图的优点:简化查询、控制数据的访问。
创建视图
create view my_view
as
select employee_id as id,last_name as name,salary
from employee
where salary > 4000;
查看视图的数据
select * from my_view;
查看视图
show tables; # 表和视图
desc [view_name]
show create view [view_name]
更新视图.只能更新基表中存在的字段。
update my_view
set salary = 20000
where employee_id = 101;
虽然可以更新视图数据,但总的来说,视图作为‘虚拟表’,主要用于‘方便查询‘。
对视图数据的更改,是不建议的。
存储过程(函数)与函数
前言:阿里开发规范禁止使用存储过程,因为难以调试和拓展,更没有移植性。
区别:次小章节与上面的“函数”的区别是,一个是用户自定义的,一个是系统的/
mysql从5.0 版本开始支持存储过程和函数。存储过程和函数能够将复杂的sql逻辑封装在一起,应用程序无须关注存储过程和函数内部复杂的SQL逻辑,只需要简单地调用存储过程和函数即可。
存储过程:Stored Procedure。它的思想很简单,就是一组经过“预先编译”的SQL语句的封装。
分类
- 1、没有参数(无参数无返回)
- 仅仅带IN类型(有参数无返回)
- 仅仅带OUT类型(无参数有返回)
- 即带IN又带OUT(有参数有返回)
- 带INOUT(有参数有返回)
语法
DELIMITER $
create procudure 存储过程名(IN|OUT|INOUT 参数名 参数类型,...)
[characteristics]
BEGIN
sql语句1,
sql语句2
EDN $
存储过程的创建
DELIMITER $
create procudure select_all_data
BEGIN
select * from emps;
EDN $
存储过程的创建
call select_all_data();
2、带OUT的存储过程
DELIMITER $
create procudure show_min_salary(OUT ms DOUBLE(10,2))
BEGIN
select MIN(salary) INTO ms
from employees;
EDN $
DELIMITER // # 更新DELIMITER
带OUT存储过程的调用
call show_min_salary(@ms)
# 查看变量值
select @ms
3、带IN存储过程的创建
DELIMITER $
create procudure show_some_salary(IN empname varchar(25))
BEGIN
select salary
from employees
where last_name = empname
EDN $
DELIMITER // # 更新DELIMITER
带IN存储过程的调用
set @empname := 'Abel'
call show_some_salary(@empname);
4、带IN和OUT
DELIMITER $
create procudure show_some_salary2(IN empname varchar(25),OUT empsalary DOUBLE(10,2))
BEGIN
select salary INTO empslary
from employees
where last_name = empname
EDN $
DELIMITER // # 更新DELIMITER
带IN和OUT存储过程的调用
set @empname := 'Abel'
call show_some_salary(@empname,@empsalary);
select @empsalary
5、带INOUT的存储过程
相当于共用一个参数了.
存储函数
存储函数就是用户自定义的函数。
语法分析
create function 函数名(参数名 参数类型,...)
returns 返回值类型
[characteristics ...]
BEGIN
函数体
END
1、参数列表:指定参数为IN、OUT或INOUT只对PROCEDURE有效。
练习
DELIMITER $
create function email_by_name(empname varchar(25))
returns varchar(25)
DETERMINISTIC
CONTAINS SQL
READS SQL DATA
COMMENT '根据name查询email'
begin
RETURN (select email from employees where last_name = empname);
end $
DELIMITER // # 更新DELIMITER
调用
set @empname := 'Abel'
select email_by_name(@empname)

存储过程和函数的查看
show create procedure XXX;
show create function XXX;
变量、流程控制与游标
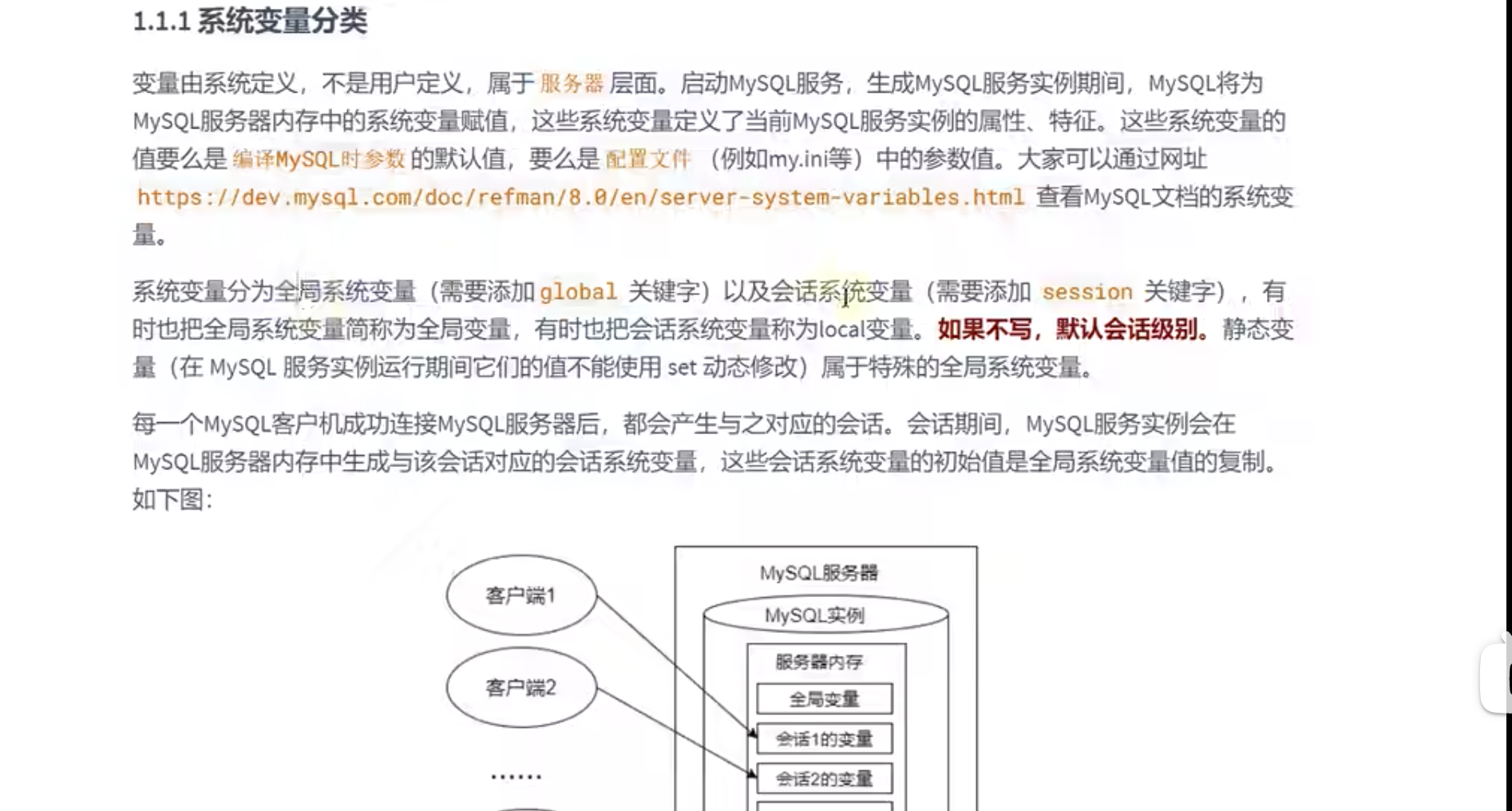
在mysql数据库中,变量分为系统变量和用户自定义变量。
系统变量分为全局系统变量和会话系统变量
会话:针对于mysql的一次连接,比如navicate可以新建多个连接。

查看系统变量
select @@global.变量名
select @@session.变量名
select @@变量名

修改系统变量的值
set @@global.变量名 = 变量值
set global 变量名 = 变量值
-----
set @@ession.变量名 = 变量值;
set session 变量名=变量值;
用户变量
用户变量又分为:会话用户变量和局部变量。
- 会话用户变量:作用域和会话变量一样,只对当前连接有效。
- 局部变量:只在BEGIN 和END中有效。局部变量只能在存储过程和函数中使用。
会话用户变量的声明与赋值
set @用户变量 = 值;
set @用户变量 :=值
-----
select @用户变量 := 表达式
select 表达式 into @用户变量
局部变量的声明
DELIMITER //
create procedure test_var()
BEGIN
# 声明
DECLARE a int deafult 0;
DECLARE b int;
DECLARE emp_name varchar(25);
# 赋值
set a =1;
set b :=2;
select last_name into emp_name
from employee where emp_id = 101;
# 使用
select a,b,emp_name;
END
DELIMITER $
错误处理

declare Field_not_be_null condition for 1048; # 方式一
declre field_not_be_null condition for sqlstate '23000'; # 方式二
流程控制
分支结构IF.
IF 表达式 THEN 操作一
ELSE 表达式 THEN 操作二
分支结构CASE
case var
when 表达式 then 操作一;
when 表达式 then 操作二;
when 表达式 then 操作三;
else 操作四;
END CASE;
循环结构WHILE、LOOP、REPEAT
循环结构之LOOP
LOOP循环语句用来重复执行某些语句。LOOP内的语句一直重复执行直到循环被退出.(使用LEAVE)
[loop_label:] LOOP
循环执行的语句
END LOOP [loop_label]
declare id int default 0;
loop_label:LOOP # 标签随便起名
set id = id +1;
if id >=10 THEN LEAVE loop_label;
END LOOP loop_label;
# 查看
select id
WHILE语句创建一个带条件判断的循环过程。WHILE在执行过程中国,先对指定的表达式进行判断,如果为真,就执行循环的语句,否则推出循环。
[while_label:] WHILE 循环条件 DO
循环执行的语句
END WHILE [loop_label]
REPEAT 与WHILE不同的是,REPEAT会先执行一次,再判断。有点像do while
[repeat_label:] REPEAT
循环执行的语句
UNTIL 结束循环的条件表达式
END REPEAT [repeat_label]
游标
Cursor可以让我们能够对结果集中的每一条记录进行定位。
游标可以在存储过程或函数中使用。
1、声明游标
DECLARE cursor_name cursor for select_statement;
2、打开游标
open cursor_name
3、使用游标
fetch cursor_name
一般游标配合循环使用, 就像iterator一样。
触发器
在实际开发中,我们经常会遇到这样情况:有二个或者多个相互关联的表,比如商品信息和库存信息分别存放在二个不同的数据库中,我们在添加一条新商品记录的时候,为了保证数据的完整性,必须同时在库存中添加一个库存记录。
这样以来,我们就必须把这二个关联的操作写到程序里面,而且要用事物包裹起来,确保这二个事物成为一个原子操作。要么全部执行,要么全部不执行。
这样以来,我们可以使用触发器。让商品信息数据的插入操作自动触发库存数据的插入操作。
当insert 进商品表,会自动触发库存表的相关操作。
create trigger 触发器名称
{Before|After} {Insert|Update|Delete} ON 表名
for each row
触发器执行语句.
具体实例
DELIMITER //
create trigger before_insert_test_tri
After Insert on table_A
for each row
BEGIN
DECLARE var_a double = 100;
insert into table_B(t_log)
values('before insert...');
END //
DELIMITER $
删除触发器
drop trigger if exists 触发器名称;
查看触发器
show triggers. # 查看所有的触发器
show create trigger 触发器名. # 查看当前某个触发器的定义。
优点
- 数据的完整性
- 帮助我们记录日志
- 在插入前、进行合法性检查。
缺点
- 可读性差
- 相关数据的变更,可能会导致触发器出错。
mysql8新特性
//TODO
基础篇寄语:
无论从事什么行业,只要做好两件事就够了,一个是你的专业、一个是你的人品,专业决定了你的存在,人品决定了你的人脉,剩下的就是坚持,用善良專業和真诚赢取更多的信任。不忘初心 方得始终!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号