

通过requests和lxml模块对网站数据进行爬取
这里就举个简单的列子,来抓取首页图片的标题!

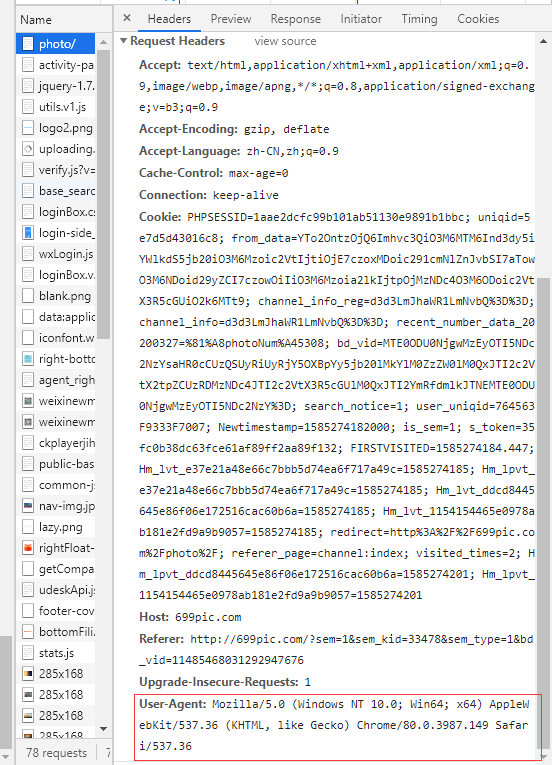
首先做爬虫第一步就是需要UA伪装,通过UA伪装伪装成浏览器对网站发起请求,request发请求时有一个参数为headers,我们可以把这个User-Agent参数放到headers这个参数中
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' }
这个参数你可以在浏览器的抓包工具中找到
好了,接下来我们就可以对页面发送请求了来获取页面数据了!
import requests from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' } url = 'http://699pic.com/photo/' response = requests.get(url=url, headers=headers).text # 此时已获取到页面数据了
接下来我们需要把获取到的页面传到etree生成的对象中
tree = etree.HTML(response)
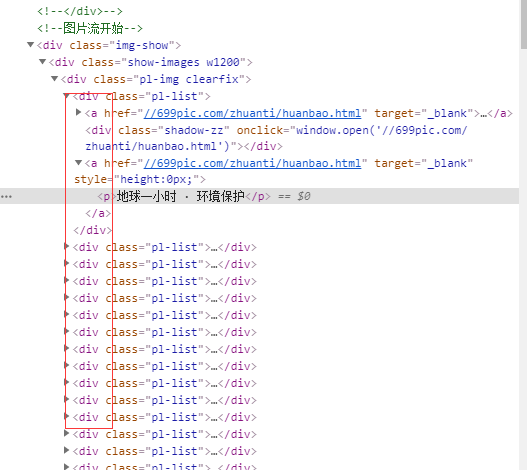
从这张图我们可以看出这件图片每个都是div而且都是在同一个div下,标题则是在每个div里面的p标签中,那我们可不可以把这些div放在一个地方,循环分别去取呢?
结果显而易见当然可以
div_list = tree.xpath('//div[@class="img-show"]/div/div/div') print(div_list) for div in div_list: name = div.xpath('./a[2]/p/text()')[0] print(name)
第一个div_list则是这些图片div的集合,打印看了一下保存在一个列表中了

然后再循环这个列表,把列表中的p元素对应的值取出来即可。
最终效果:
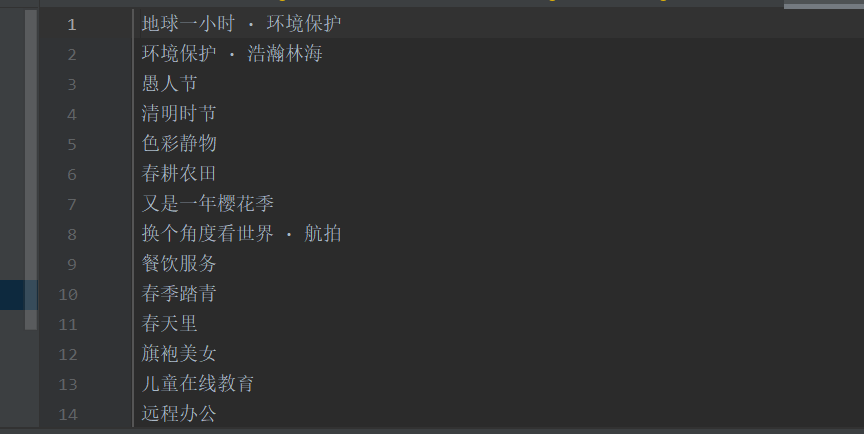
全部代码如下图所示:
import requests from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' } url = 'http://699pic.com/photo/' response = requests.get(url=url, headers=headers).text tree = etree.HTML(response) div_list = tree.xpath('//div[@class="img-show"]/div/div/div') print(div_list) f = open('name.txt', 'w', encoding='utf-8') for div in div_list: name = div.xpath('./a[2]/p/text()')[0] f.write(name + '\n')

