Redis集群的三种姿势
一、Redis主从复制
主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主。
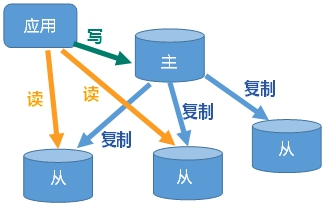
1、如何实现
- 新建三个配置文件,分别命名为redis_6380.conf、redis_6381.conf、redis_6382.conf
# 此处以6379为例,其他两个修改相应的端口号就行
include /root/myredis/redis.conf # 依赖的redis.conf
pidfile /var/run/redis_6380.pid
port 6381 # 端口
dbfilename dump6382.rdb # RDB存储文件名
# 注意需要修改redis.conf中daemonize yes,表示后台启动,Appendonly 关闭或换文件名
- 启动三台redis服务器
redis-server redis6380.conf
redis-server redis6381.conf
redis-server redis6382.conf
- 查看系统进程,看看三台服务器是否启动成功
ps -ef|grep redis
polkitd 5736 5715 0 20:48 ? 00:00:01 redis-server *:6379
root 5812 1 0 20:50 ? 00:00:00 redis-server 127.0.0.1:6380
root 5818 1 0 20:50 ? 00:00:00 redis-server 127.0.0.1:6381
root 5848 1 0 20:51 ? 00:00:00 redis-server 127.0.0.1:6382
root 5854 4995 0 20:51 pts/7 00:00:00 grep --color=auto redis
- 查看三台主机运行情况
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:e03d5976005aa18a6725e81034ee51c1e40e250a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:3273827012605ba03029999469a5b58fc2265e61
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6382> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:e851ff4b784f97be2ea8dcf847e0740b2d6f0c1c
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
-
配置从库,不配主库
slave of
成为某个实例的从服务器。
# 这里我们分别在6381和6382上执行,顾名思义,6380是主,6381和6382是从
slaveof 127.0.0.1 6380
- 再次查看三台主机运行情况
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:2 # 有两个从机
slave0:ip=127.0.0.1,port=6381,state=online,offset=84,lag=1
slave1:ip=127.0.0.1,port=6382,state=online,offset=84,lag=0
master_failover_state:no-failover
master_replid:334f3e0ffbb15cc13e825162841be0cbf88007b2
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:84
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:84
127.0.0.1:6381> info replication
# Replication
role:slave # 由master变为slave
master_host:127.0.0.1 # 主机host
master_port:6380 # 主机port
master_link_status:up
master_last_io_seconds_ago:3
master_sync_in_progress:0
slave_repl_offset:224
slave_priority:100
slave_read_only:1
connected_slaves:0
master_failover_state:no-failover # 主机的信息
master_replid:334f3e0ffbb15cc13e825162841be0cbf88007b2
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:224
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:224
127.0.0.1:6382> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6380
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_repl_offset:336
slave_priority:100
slave_read_only:1
connected_slaves:0
master_failover_state:no-failover
master_replid:334f3e0ffbb15cc13e825162841be0cbf88007b2
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:336
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:15
repl_backlog_histlen:322
至此我们的一主二从就搭建完毕。
2、测试
- 在主机上写入数据,丛机读取数据。丛机则不支持写入,只能读取
# 在主机写入
127.0.0.1:6380> set k1 v1
OK
# 在丛机读取
127.0.0.1:6380> set k1 v1
OK
127.0.0.1:6382> get k1
"v1"
# 在丛机写入
127.0.0.1:6382> set k2 v2
(error) READONLY You can't write against a read only replica.
- 主机挂掉,重启就行,一切如初
# kill掉主机
[root@localhost myredis]# ps -ef|grep 6380
root 5812 1 0 20:50 ? 00:00:13 redis-server 127.0.0.1:6380
root 6136 4995 0 21:18 pts/7 00:00:00 grep --color=auto 6380
[root@localhost myredis]# kill -9 5812
[root@localhost myredis]# ps -ef|grep 6380
root 6138 4995 0 21:18 pts/7 00:00:00 grep --color=auto 6380
# 重启6380
redis-server redis6380.conf
# 在6381和6382查看运行状态
info replication # 发现主机还是6380
-
丛机重启需要重新设置 slaveof 127.0.0.1 6380
可以将此设置写在配置文件中。
3、常用招式
- 一主二仆
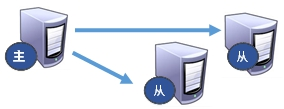
我们上面的示例就是一主二仆,只支持主机写入,丛机只能读取,主机挂掉后,丛机只能原地待命,主机恢复上线后,主机新增记录,丛机可以顺利复制。其中某个丛机挂掉后,恢复上线后会同步主机的内容。
- 薪火相传
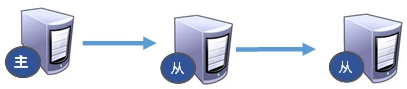
上一个Slave可以是下一个slave的Master,丛机同样可以接收其他slaves的连接和同步请求,那么该slave作为链条中下一个Slave的master,可以有效减轻master的写压力,去中心化降低风险。
风险是一旦某个slave宕机,后面的salve都无法备份。主机挂了,丛机还是丛机,无法写入数据。
- 反客为主
当一个master宕机后,后面的slave可以立刻升为master,其后面的slave不用做任何修改。
用slaveof no one将丛机变为主机。
4、复制原理
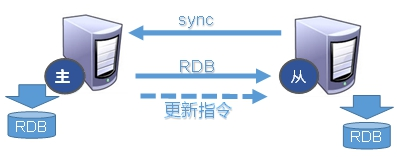
- Slave启动成功连接到master后会发送一个sync命令
- Master接到命令启动后台的存盘进程,同时收集所有接收到的写命令,在后台进程执行完毕之后,master将传送这个数据文件到slave,以完成一次完全同步
- 全量复制:slave在接收到master的文件数据后,将其存盘并加载到内存
- 增量复制:master继续将新的写命令依次传给slave,完成同步。
- 但是只要重连master,全量复制会被自动执行。
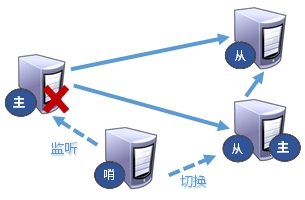
二、哨兵模式
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票自动将从库转换为主库。
1、如何实现
-
调整为一主二仆模式,6380带着6381和6382。
127.0.0.1:6380> info replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6381,state=online,offset=3818,lag=1 master_failover_state:no-failover master_replid:18f367f47ad7263532b1fde19d19259b23501784 master_repl_offset:3818 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:3818 -
在自定义的/myredis目录下新建sentinel.conf文件,文件名绝不能错
# 配置哨兵,填写内容 sentinel monitor mymaster 127.0.0.1 6380 1 # 其中mymaster为监控对象 起的服务器名称,1为至少有多少个哨兵统一迁移的数量 -
启动哨兵
cd /usr/local/bin redis-sentinel /root/myredis/sentinel.conf
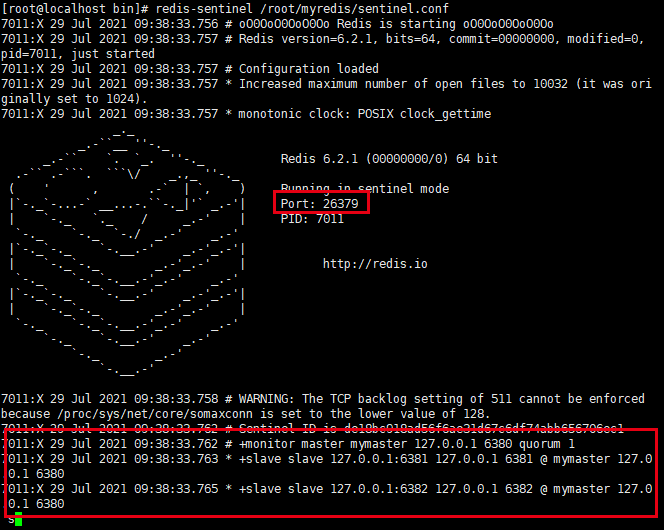
至此我们可以看到哨兵模式已经启动,监控的主机是6380,监控的丛机是6381,6382。
-
当主机挂掉后,在丛机中选举出新的主机
我们杀掉6380,观察哨兵窗口的变化
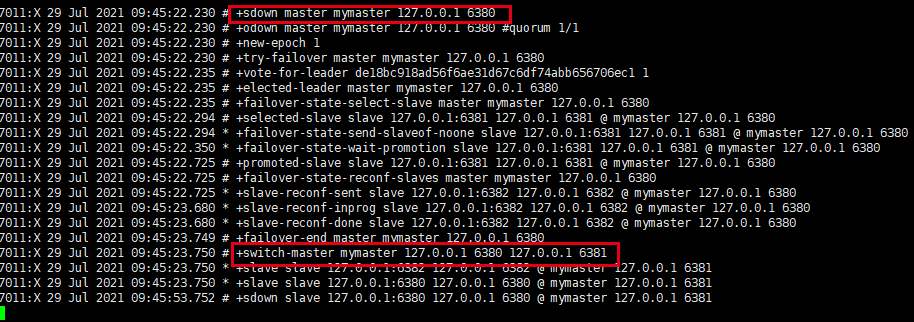
大概10秒左右可以看到哨兵窗口日志,切换了新主机,哪个丛机会被选举为主机呢?根据优先级别:slave-priority.
原主机重启后会变为主机。
3、复制延时
由于所有的写操作都是现在master上,然后才同步更新到Slave上,所以从Master同步到Slave机器有一定延迟,当系统很繁忙时候,延迟问题会更加严重,Slave机器数据的增加也会使这个问题严重。
4、故障恢复
-
新主登基
主服务器宕机后,在从服务李挑选一个,将其转为主服务。选择条件依次是:
- 选择优先级靠前的
- 优先级在redis.conf中默认:slave-priority 100,值越小优先级越高
- 选择偏移量最大的
- 偏移量是指获得原主机数据最全的
- 选择runid最小的
- 每个redis实例启动后都会随机生成一个40位的runid
- 选择优先级靠前的
-
群仆俯首
挑选出新的主服务后,sentinel向原主服务的从服务发送slaveof 新主服务的命令,复制新的master
-
旧主俯首
当已下线的服务重新上限时,sentinel会向其发送slaeof命令,让其成为新主的从。
Redis集群
容量不够,Redis如何进行扩容?
并发写操作,Redis如何分摊?
主从模式,薪火相传模式,主机宕机,导致IP地址发生变化,应用程序中配置需要修改对应主机地址,端口等信息。
之前通过代理主机来解决,但是Redis3.0中提供了解决方案,就是无中心化集群配置。
1、什么是集群
Redis集群实现了对Redis的水平扩容,即启动N个Redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N.
Redis集群通过分区(partition)来提供一定程度可用性(availability);即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
2、集群搭建
-
将rdb.aof文件都删掉。
-
制作6个实例,6380,6381,6382,6390,6391,6392
- 配置基本信息
开启daemonize yes Pid 文件名 指定端口 Log文件名 Dump.rdb 文件名 Appendonly 关闭或换名- cluster配置修改
cluster-enabled yes # 打开集群模式 cluster-config-file nodes-6380.conf # 设置节点配置文件名 cluster-node-timeout 15000 # 设节点失联时间,超过该时间(ms),集群自动进行主从切换# redis6380.conf include /root/myredis/redis.conf port 6380 pidfile "/var/run/redis_6380.pid" dbfilename "dump6380.rdb" dir "/root/myredis/redis_cluster" logfile "/root/myredis/redis_cluster/redis_err_6380.log" cluster-enabled yes cluster-config-file nodes-6380.conf cluster-node-timeout 15000 -
启动6个Redis服务
[root@localhost myredis]# redis-server redis6380.conf [root@localhost myredis]# redis-server redis6381.conf [root@localhost myredis]# redis-server redis6382.conf [root@localhost myredis]# redis-server redis6390.conf [root@localhost myredis]# redis-server redis6391.conf [root@localhost myredis]# redis-server redis6392.conf [root@localhost myredis]# ps -ef|grep redis polkitd 7728 7708 0 10:37 ? 00:00:02 redis-server *:6379 root 7938 1 0 10:51 ? 00:00:00 redis-server 127.0.0.1:6380 [cluster] root 7944 1 0 10:51 ? 00:00:00 redis-server 127.0.0.1:6381 [cluster] root 7950 1 0 10:51 ? 00:00:00 redis-server 127.0.0.1:6382 [cluster] root 7956 1 0 10:51 ? 00:00:00 redis-server 127.0.0.1:6390 [cluster] root 7962 1 0 10:51 ? 00:00:00 redis-server 127.0.0.1:6391 [cluster] root 7968 1 0 10:51 ? 00:00:00 redis-server 127.0.0.1:6392 [cluster] root 7974 6625 0 10:52 pts/4 00:00:00 grep --color=auto redis -
将六个节点合成一个集群
组合之前,请确保所有Redis实例启动后,nodes-xxxx.conf文件都生成。
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6390 127.0.0.1:6391 127.0.0.1:6392 # --replicas 1 采用最简单的方式配置集群,一台主机,一台丛机,正好三组 >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 127.0.0.1:6391 to 127.0.0.1:6380 Adding replica 127.0.0.1:6392 to 127.0.0.1:6381 Adding replica 127.0.0.1:6390 to 127.0.0.1:6382 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: d9676135759dc3aeb102efc122fdba8f46c85b5d 127.0.0.1:6380 slots:[0-5460] (5461 slots) master M: 1ba9f9a0cf32bdae4b14b2535d4a924ae30e034d 127.0.0.1:6381 slots:[5461-10922] (5462 slots) master M: 831f8eabc158e60e54da10e2521a904cd2e2b482 127.0.0.1:6382 slots:[10923-16383] (5461 slots) master S: 21d08adeb49f29d9f7db75eeee932aaf45c76c05 127.0.0.1:6390 replicates 831f8eabc158e60e54da10e2521a904cd2e2b482 S: db5ee9dd4fcd7854fc6e86e675a6e8ce2466c528 127.0.0.1:6391 replicates d9676135759dc3aeb102efc122fdba8f46c85b5d S: 991c2815de2683476af80e8eaf1fa3d68eada2bb 127.0.0.1:6392 replicates 1ba9f9a0cf32bdae4b14b2535d4a924ae30e034d Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join >>> Performing Cluster Check (using node 127.0.0.1:6380) M: d9676135759dc3aeb102efc122fdba8f46c85b5d 127.0.0.1:6380 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 1ba9f9a0cf32bdae4b14b2535d4a924ae30e034d 127.0.0.1:6381 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: 991c2815de2683476af80e8eaf1fa3d68eada2bb 127.0.0.1:6392 slots: (0 slots) slave replicates 1ba9f9a0cf32bdae4b14b2535d4a924ae30e034d S: 21d08adeb49f29d9f7db75eeee932aaf45c76c05 127.0.0.1:6390 slots: (0 slots) slave replicates 831f8eabc158e60e54da10e2521a904cd2e2b482 M: 831f8eabc158e60e54da10e2521a904cd2e2b482 127.0.0.1:6382 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: db5ee9dd4fcd7854fc6e86e675a6e8ce2466c528 127.0.0.1:6391 slots: (0 slots) slave replicates d9676135759dc3aeb102efc122fdba8f46c85b5d [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.- 普通方式登录
可以直接进入读主机,但是在存储数据时,会出现MOVED重定向操作。
[root@localhost bin]# redis-cli -p 6380 127.0.0.1:6380> keys * (empty array) 127.0.0.1:6380> set k1 v1 (error) MOVED 12706 127.0.0.1:6382- 采用集群策略连接,设置数据会自动切换到相应的写主机
[root@localhost bin]# redis-cli -c -p 6380 127.0.0.1:6380> keys * (empty array) 127.0.0.1:6380> set k1 v1 -> Redirected to slot [12706] located at 127.0.0.1:6382 OK -
通过cluster nodes命令查看集群信息
127.0.0.1:6382> cluster nodes
831f8eabc158e60e54da10e2521a904cd2e2b482 127.0.0.1:6382@16382 myself,master - 0 1627529428000 3 connected 10923-16383
991c2815de2683476af80e8eaf1fa3d68eada2bb 127.0.0.1:6392@16392 slave 1ba9f9a0cf32bdae4b14b2535d4a924ae30e034d 0 1627529424185 2 connected
1ba9f9a0cf32bdae4b14b2535d4a924ae30e034d 127.0.0.1:6381@16381 master - 0 1627529427000 2 connected 5461-10922
21d08adeb49f29d9f7db75eeee932aaf45c76c05 127.0.0.1:6390@16390 slave 831f8eabc158e60e54da10e2521a904cd2e2b482 0 1627529430242 3 connected
db5ee9dd4fcd7854fc6e86e675a6e8ce2466c528 127.0.0.1:6391@16391 slave d9676135759dc3aeb102efc122fdba8f46c85b5d 0 1627529429000 1 connected
d9676135759dc3aeb102efc122fdba8f46c85b5d 127.0.0.1:6380@16380 master - 0 1627529429231 1 connected 0-5460
-
Redis cluster如何分配这六个节点?
一个集群至少要有是三个节点,选项 --cluster-replicas 1表示我们希望为集群的每个主节点创建一个从节点,分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
-
什么是slots?
一个Redis集群包含16384个插槽(hash slot),数据库中的每个键都属于这16384个插槽的其中一个。集群采用公式RCR16(key)%16834来计算key属于哪个槽,其中CRC16(key)语句用于计算键key的CRC16校验和。
集群中每个节点负责处理一部分插槽,举个例子,如果一个集群可以有主节点,其中:
节点A负责处理0号至5460号插槽
节点B负责处理5461号至10992号插槽
节点C负责处理10923号至16383号插槽
-
在集群中录入值
在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应的服务器插槽,redis会报错,并告知应该前往的redis实例地址和端口。
redis-cli 客户端提供了 -c 参数实现自动重定向。
如 redis-cli -c -p 6380登入后,再录入、查询键值对可以自动重定向。
不在一个slot下的兼职,是不能使用mget,mset等多键操作。
127.0.0.1:6380> mset k1 v1 k2 v2 (error) CROSSSLOT Keys in request don't hash to the same slot可以通过{}来定义组的概念,从而使key中{}内相同内容的兼职对放到一个slot中。
127.0.0.1:6380> mset k1{cust} v1 k2{cust} v2 k3{cust} v3 OK -
查询集群中的值
cluster getkeysinslot
返回count个slot中的键 127.0.0.1:6380> cluster keyslot cust (integer) 4847 127.0.0.1:6380> cluster countkeysinslot 4847 (integer) 3 127.0.0.1:6380> cluster getkeysinslot 4847 10 1) "k1{cust}" 2) "k2{cust}" 3) "k3{cust}" -
故障恢复
-
如果主节点下线?从节点能否自动升为主节点,注意:15秒超时
-
主节点恢复后,主从关系如何?
主节点回来编程从节点。
-
如果所有某一段插槽的朱从节点都宕机了,Redis服务是否还能继续?
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage为yes,那么整个集群都挂掉;如果cluster-require-full-coverage为no,那么该插槽数据全部不能使用,也无法存储。
-

