高光谱图像分类
总结
因篇幅较长,把总结写在开始。
我是使用自己的环境来跑的,没有使用colab,所有关键的输出都保留了。GTX1660 Super。
项目结构如下:
-
我觉得,实际问题需要根据应用场景来合理的提取特征,往往能得到更好的更稳定的效果。
-
论文里说到To increase the number of spectral-spatial feature maps simultaneously, 3D convolutions are applied thrice and can preserve the spectral information of input HSI data in the output volume.本例中对3D卷积没有使用比较合理的注意力机制,如果从维度上考虑,可以从图像空间,通道,和光谱的波长三个方向使用注意力机制来处理特征,理论上是可以得到更好的效果的。
-
我主要是对2D卷积部分使用了注意力机制。
-
论文还提到了提出方法的背景,是因为之前的方法大都是只考虑了空间上的特征信息,没有考虑光谱波长维度上的信息,不是效果不好就是训练太费时间。
-
该方法结合3D和2D卷积,依赖更少的训练数据(0.1的训练集,0.9的测试集),正确率却影响很小;
-
对于2D卷积和3D卷积,2D和3D卷积中都有多通道卷积,而区分二者的是3D卷积比2D卷积多了一个深度信息,2D卷积可以看成深度为1的3D卷积,二者在PyTorch网络骨架里的区别是,3D卷积shape为(batch_size,channel,depth,height,weight),2D卷积 shape为(batch_size,channel,height,weight)
-
在初始的模型上,如果多跑几次“模型测试代码块”,会发现每次分类的结果都不一样。这是因为原始的代码没有注意到pytorch模型网络的训练模式和测试模式即 net.train() 和 net.eval() (这里net是我们构建的HybirdSN),由于网络的全连接层中使用了 nn.Dropout(p=0.4)训练模式下是启用 Dropout和BN 层(本例没有)的,网络层的节点会随机失活。而原始代码在测试的时候没有启用测试模式,即使用的是训练模式,所以每次结果都是不一样的。
因此在训练和测试的时候分别启用相应模式就可以保证测试的结果是一样的了。
HybridSN 高光谱图像分类
S. K. Roy, G. Krishna, S. R. Dubey, B. B. Chaudhuri HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification, IEEE GRSL 2020
这篇论文构建了一个 混合网络 解决高光谱图像分类问题,首先用 3D卷积,然后使用 2D卷积,代码相对简单,下面是代码的解析。
数据集已经下载到 src/data 文件夹之中,论文中一共有三类数据{Indian-pines, PaviaU, Salinas},本例使用的是Indian-pines 数据集。
引入基本函数库
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report, cohen_kappa_score
import spectral
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
%matplotlib inline
1. 定义 HybridSN 类
模型的网络结构为如下图所示:
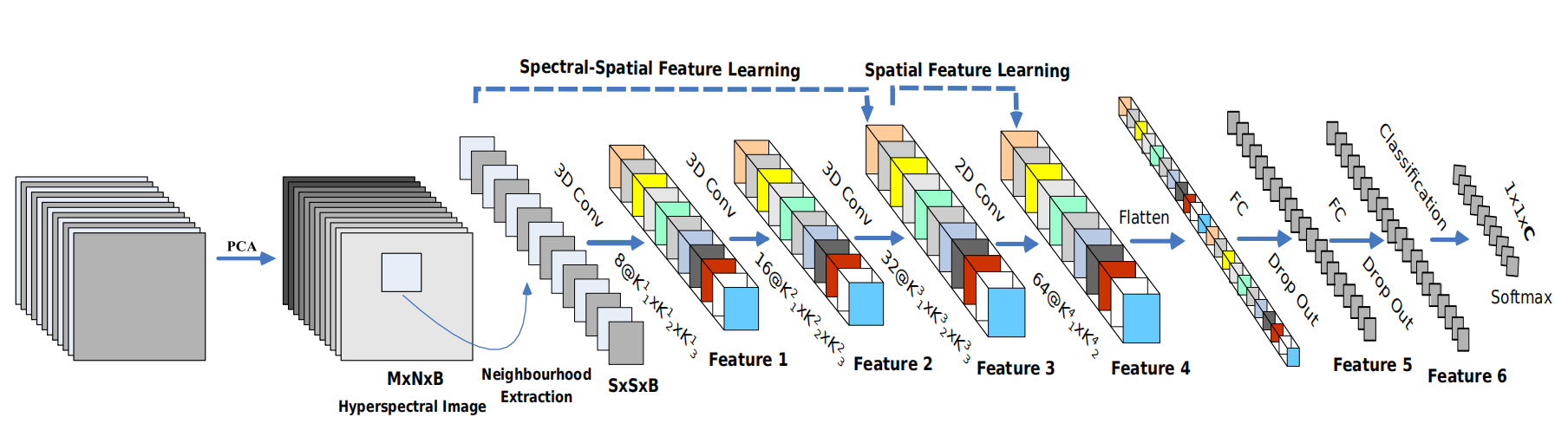
根据网络结构构建网络如下:
三维卷积部分:
conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
接下来是一个 flatten 操作,变为 18496 维的向量,
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
最后输出为 16 个节点,是最终的分类类别数。
在基础的HybirdSN网络骨架上使用注意力机制,主要从空间和通道两个方面考虑,使用注意力机制效果大概提升了一个多百分点,正确率从96.x%提升到了98.19%
证明注意力机制是有效果的,具体的实现如下:
在3D卷积完成后,对reshape的输出特征使用(这部分使用注意力机制我不知道准确的对应关系,但效果不错)
self.channel_attention_1 = ChannelAttention(576)
self.spatial_attention_1 = SpatialAttention(kernel_size=7)
在2D卷积完成后,对输出特征使用(从图像空间和通道两个维度使用注意力机制处理特征)
self.channel_attention_2 = ChannelAttention(64)
self.spatial_attention_2 = SpatialAttention(kernel_size=7)
下面是 HybridSN 类以及使用注意力机制的代码:
# 通道注意力机制
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
# 空间注意力机制
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
# 网络骨架
class HybridSN(nn.Module):
def __init__(self, num_classes, self_attention=False):
super(HybridSN, self).__init__()
# out = (width - kernel_size + 2*padding)/stride + 1
# => padding = ( stride * (out-1) + kernel_size - width)
# 这里因为 stride == 1 所有卷积计算得到的padding都为 0
#默认不使用注意力机制
self.self_attention = self_attention
# 3D卷积块
self.block_1_3D = nn.Sequential(
nn.Conv3d(
in_channels=1,
out_channels=8,
kernel_size=(7, 3, 3),
stride=1,
padding=0
),
nn.ReLU(inplace=True),
nn.Conv3d(
in_channels=8,
out_channels=16,
kernel_size=(5, 3, 3),
stride=1,
padding=0
),
nn.ReLU(inplace=True),
nn.Conv3d(
in_channels=16,
out_channels=32,
kernel_size=(3, 3, 3),
stride=1,
padding=0
),
nn.ReLU(inplace=True)
)
if self_attention:
self.channel_attention_1 = ChannelAttention(576)
self.spatial_attention_1 = SpatialAttention(kernel_size=7)
# 2D卷积块
self.block_2_2D = nn.Sequential(
nn.Conv2d(
in_channels=576,
out_channels=64,
kernel_size=(3, 3)
),
nn.ReLU(inplace=True)
)
if self_attention:
self.channel_attention_2 = ChannelAttention(64)
self.spatial_attention_2 = SpatialAttention(kernel_size=7)
# 全连接层
self.classifier = nn.Sequential(
nn.Linear(
in_features=18496,
out_features=256
),
nn.Dropout(p=0.4),
nn.Linear(
in_features=256,
out_features=128
),
nn.Dropout(p=0.4),
nn.Linear(
in_features=128,
out_features=num_classes
)
# pytorch交叉熵损失函数是混合了softmax的。不需要再使用softmax
)
def forward(self, x):
y = self.block_1_3D(x)
y = y.view(-1, y.shape[1] * y.shape[2], y.shape[3], y.shape[4])
if self.self_attention:
y = self.channel_attention_1(y) * y
y = self.spatial_attention_1(y) * y
y = self.block_2_2D(y)
if self.self_attention:
y = self.channel_attention_2(y) * y
y = self.spatial_attention_2(y) * y
y = y.view(y.size(0), -1)
y = self.classifier(y)
return y
if __name__ == '__main__':
# 随机输入,测试网络结构是否通
x = torch.randn(1, 1, 30, 25, 25)
net = HybridSN(num_classes=16, self_attention=True)
y = net(x)
#print(y.shape)
print(y)
tensor([[ 0.0113, -0.0329, 0.0606, 0.0855, -0.0437, 0.0004, -0.0817, 0.0394,
-0.0442, -0.0537, -0.1194, 0.0064, 0.0013, -0.0181, 0.0586, 0.0076]],
grad_fn=<AddmmBackward>)
2. 创建数据集
首先对高光谱数据实施PCA降维;然后创建 keras 方便处理的数据格式;然后随机抽取 10% 数据做为训练集,剩余的做为测试集。
首先定义基本函数:
# 对高光谱数据 X 应用 PCA 变换
def applyPCA(X, numComponents):
newX = np.reshape(X, (-1, X.shape[2]))
pca = PCA(n_components=numComponents, whiten=True)
newX = pca.fit_transform(newX)
newX = np.reshape(newX, (X.shape[0], X.shape[1], numComponents))
return newX
# 对单个像素周围提取 patch 时,边缘像素就无法取了,因此,给这部分像素进行 padding 操作
def padWithZeros(X, margin=2):
newX = np.zeros((X.shape[0] + 2 * margin, X.shape[1] + 2* margin, X.shape[2]))
x_offset = margin
y_offset = margin
newX[x_offset:X.shape[0] + x_offset, y_offset:X.shape[1] + y_offset, :] = X
return newX
# 在每个像素周围提取 patch ,然后创建成符合 keras 处理的格式
def createImageCubes(X, y, windowSize=5, removeZeroLabels = True):
# 给 X 做 padding
margin = int((windowSize - 1) / 2)
zeroPaddedX = padWithZeros(X, margin=margin)
# split patches
patchesData = np.zeros((X.shape[0] * X.shape[1], windowSize, windowSize, X.shape[2]))
patchesLabels = np.zeros((X.shape[0] * X.shape[1]))
patchIndex = 0
for r in range(margin, zeroPaddedX.shape[0] - margin):
for c in range(margin, zeroPaddedX.shape[1] - margin):
patch = zeroPaddedX[r - margin:r + margin + 1, c - margin:c + margin + 1]
patchesData[patchIndex, :, :, :] = patch
patchesLabels[patchIndex] = y[r-margin, c-margin]
patchIndex = patchIndex + 1
if removeZeroLabels:
patchesData = patchesData[patchesLabels>0,:,:,:]
patchesLabels = patchesLabels[patchesLabels>0]
patchesLabels -= 1
return patchesData, patchesLabels
def splitTrainTestSet(X, y, testRatio, randomState=345):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=testRatio, random_state=randomState, stratify=y)
return X_train, X_test, y_train, y_test
下面读取并创建数据集:
# 地物类别
class_num = 16
X = sio.loadmat('./src/data/Indian_pines_corrected.mat')['indian_pines_corrected']
y = sio.loadmat('./src/data/Indian_pines_gt.mat')['indian_pines_gt']
# 用于测试样本的比例
test_ratio = 0.90
# 每个像素周围提取 patch 的尺寸
patch_size = 25
# 使用 PCA 降维,得到主成分的数量
pca_components = 30
print('Hyperspectral data shape: ', X.shape)
print('Label shape: ', y.shape)
print('\n... ... PCA tranformation ... ...')
X_pca = applyPCA(X, numComponents=pca_components)
print('Data shape after PCA: ', X_pca.shape)
print('\n... ... create data cubes ... ...')
X_pca, y = createImageCubes(X_pca, y, windowSize=patch_size)
print('Data cube X shape: ', X_pca.shape)
print('Data cube y shape: ', y.shape)
print('\n... ... create train & test data ... ...')
Xtrain, Xtest, ytrain, ytest = splitTrainTestSet(X_pca, y, test_ratio)
print('Xtrain shape: ', Xtrain.shape)
print('Xtest shape: ', Xtest.shape)
# 改变 Xtrain, Ytrain 的形状,以符合 keras 的要求
Xtrain = Xtrain.reshape(-1, patch_size, patch_size, pca_components, 1)
Xtest = Xtest.reshape(-1, patch_size, patch_size, pca_components, 1)
print('before transpose: Xtrain shape: ', Xtrain.shape)
print('before transpose: Xtest shape: ', Xtest.shape)
# 为了适应 pytorch 结构,数据要做 transpose
Xtrain = Xtrain.transpose(0, 4, 3, 1, 2)
Xtest = Xtest.transpose(0, 4, 3, 1, 2)
print('after transpose: Xtrain shape: ', Xtrain.shape)
print('after transpose: Xtest shape: ', Xtest.shape)
""" Training dataset"""
class TrainDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtrain.shape[0]
self.x_data = torch.FloatTensor(Xtrain)
self.y_data = torch.LongTensor(ytrain)
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len
""" Testing dataset"""
class TestDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtest.shape[0]
self.x_data = torch.FloatTensor(Xtest)
self.y_data = torch.LongTensor(ytest)
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len
# 创建 trainloader 和 testloader
trainset = TrainDS()
testset = TestDS()
train_loader = torch.utils.data.DataLoader(dataset=trainset, batch_size=128, shuffle=True, num_workers=0)
test_loader = torch.utils.data.DataLoader(dataset=testset, batch_size=128, shuffle=False, num_workers=0)
Hyperspectral data shape: (145, 145, 200)
Label shape: (145, 145)
... ... PCA tranformation ... ...
Data shape after PCA: (145, 145, 30)
... ... create data cubes ... ...
Data cube X shape: (10249, 25, 25, 30)
Data cube y shape: (10249,)
... ... create train & test data ... ...
Xtrain shape: (1024, 25, 25, 30)
Xtest shape: (9225, 25, 25, 30)
before transpose: Xtrain shape: (1024, 25, 25, 30, 1)
before transpose: Xtest shape: (9225, 25, 25, 30, 1)
after transpose: Xtrain shape: (1024, 1, 30, 25, 25)
after transpose: Xtest shape: (9225, 1, 30, 25, 25)
3. 开始训练
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 网络放到GPU上
net = HybridSN(num_classes=16, self_attention=True).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 开始训练
total_loss = 0
net.train() #注意启用训练模式
for epoch in range(100):
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print('[Epoch: %d] [loss avg: %.6f] [current loss: %.6f]' %(epoch + 1, total_loss/(epoch+1), loss.item()))
print('Finished Training')
[Epoch: 1] [loss avg: 21.764485] [current loss: 2.707351]
[Epoch: 2] [loss avg: 21.528355] [current loss: 2.602004]
[Epoch: 3] [loss avg: 20.942521] [current loss: 2.320328]
[Epoch: 4] [loss avg: 20.466086] [current loss: 2.357273]
[Epoch: 5] [loss avg: 20.139084] [current loss: 2.337049]
[Epoch: 6] [loss avg: 19.841927] [current loss: 2.270184]
[Epoch: 7] [loss avg: 19.512924] [current loss: 2.151926]
[Epoch: 8] [loss avg: 19.195346] [current loss: 2.067162]
[Epoch: 9] [loss avg: 18.859384] [current loss: 2.023777]
[Epoch: 10] [loss avg: 18.501156] [current loss: 1.895740]
[Epoch: 11] [loss avg: 18.087192] [current loss: 1.740899]
[Epoch: 12] [loss avg: 17.625900] [current loss: 1.439154]
[Epoch: 13] [loss avg: 17.124464] [current loss: 1.248525]
[Epoch: 14] [loss avg: 16.571294] [current loss: 0.963299]
[Epoch: 15] [loss avg: 16.033480] [current loss: 1.084072]
[Epoch: 16] [loss avg: 15.429372] [current loss: 0.781360]
[Epoch: 17] [loss avg: 14.819567] [current loss: 0.540260]
[Epoch: 18] [loss avg: 14.206630] [current loss: 0.498723]
[Epoch: 19] [loss avg: 13.615416] [current loss: 0.391289]
[Epoch: 20] [loss avg: 13.042928] [current loss: 0.244593]
[Epoch: 21] [loss avg: 12.510908] [current loss: 0.200380]
[Epoch: 22] [loss avg: 11.999399] [current loss: 0.124136]
[Epoch: 23] [loss avg: 11.514211] [current loss: 0.177381]
[Epoch: 24] [loss avg: 11.059299] [current loss: 0.041177]
[Epoch: 25] [loss avg: 10.664795] [current loss: 0.196543]
[Epoch: 26] [loss avg: 10.283437] [current loss: 0.073393]
[Epoch: 27] [loss avg: 9.928957] [current loss: 0.021290]
[Epoch: 28] [loss avg: 9.596673] [current loss: 0.039379]
[Epoch: 29] [loss avg: 9.277710] [current loss: 0.047792]
[Epoch: 30] [loss avg: 8.979761] [current loss: 0.053507]
[Epoch: 31] [loss avg: 8.694495] [current loss: 0.021412]
[Epoch: 32] [loss avg: 8.427991] [current loss: 0.016616]
[Epoch: 33] [loss avg: 8.175640] [current loss: 0.020091]
[Epoch: 34] [loss avg: 7.938644] [current loss: 0.008683]
[Epoch: 35] [loss avg: 7.721540] [current loss: 0.112816]
[Epoch: 36] [loss avg: 7.522946] [current loss: 0.006924]
[Epoch: 37] [loss avg: 7.346867] [current loss: 0.149762]
[Epoch: 38] [loss avg: 7.167441] [current loss: 0.076150]
[Epoch: 39] [loss avg: 6.990478] [current loss: 0.066644]
[Epoch: 40] [loss avg: 6.819399] [current loss: 0.008275]
[Epoch: 41] [loss avg: 6.654946] [current loss: 0.001498]
[Epoch: 42] [loss avg: 6.497471] [current loss: 0.002357]
[Epoch: 43] [loss avg: 6.347017] [current loss: 0.000123]
[Epoch: 44] [loss avg: 6.203608] [current loss: 0.001660]
[Epoch: 45] [loss avg: 6.067185] [current loss: 0.000271]
[Epoch: 46] [loss avg: 5.936537] [current loss: 0.010097]
[Epoch: 47] [loss avg: 5.810687] [current loss: 0.008158]
[Epoch: 48] [loss avg: 5.690655] [current loss: 0.001530]
[Epoch: 49] [loss avg: 5.575810] [current loss: 0.001173]
[Epoch: 50] [loss avg: 5.466054] [current loss: 0.028128]
[Epoch: 51] [loss avg: 5.360111] [current loss: 0.016782]
[Epoch: 52] [loss avg: 5.258327] [current loss: 0.015375]
[Epoch: 53] [loss avg: 5.159733] [current loss: 0.002847]
[Epoch: 54] [loss avg: 5.064858] [current loss: 0.001613]
[Epoch: 55] [loss avg: 4.973696] [current loss: 0.001816]
[Epoch: 56] [loss avg: 4.885957] [current loss: 0.002706]
[Epoch: 57] [loss avg: 4.801951] [current loss: 0.005691]
[Epoch: 58] [loss avg: 4.719515] [current loss: 0.003990]
[Epoch: 59] [loss avg: 4.639637] [current loss: 0.001771]
[Epoch: 60] [loss avg: 4.563024] [current loss: 0.016726]
[Epoch: 61] [loss avg: 4.489102] [current loss: 0.000318]
[Epoch: 62] [loss avg: 4.417193] [current loss: 0.000462]
[Epoch: 63] [loss avg: 4.347673] [current loss: 0.005741]
[Epoch: 64] [loss avg: 4.280079] [current loss: 0.001063]
[Epoch: 65] [loss avg: 4.214605] [current loss: 0.001747]
[Epoch: 66] [loss avg: 4.150949] [current loss: 0.000369]
[Epoch: 67] [loss avg: 4.089055] [current loss: 0.000031]
[Epoch: 68] [loss avg: 4.028967] [current loss: 0.000302]
[Epoch: 69] [loss avg: 3.970654] [current loss: 0.002976]
[Epoch: 70] [loss avg: 3.914038] [current loss: 0.000303]
[Epoch: 71] [loss avg: 3.858973] [current loss: 0.000061]
[Epoch: 72] [loss avg: 3.805428] [current loss: 0.001084]
[Epoch: 73] [loss avg: 3.753602] [current loss: 0.001294]
[Epoch: 74] [loss avg: 3.703001] [current loss: 0.001381]
[Epoch: 75] [loss avg: 3.653658] [current loss: 0.000127]
[Epoch: 76] [loss avg: 3.606114] [current loss: 0.015526]
[Epoch: 77] [loss avg: 3.560532] [current loss: 0.009953]
[Epoch: 78] [loss avg: 3.517405] [current loss: 0.003453]
[Epoch: 79] [loss avg: 3.478270] [current loss: 0.186305]
[Epoch: 80] [loss avg: 3.445013] [current loss: 0.039273]
[Epoch: 81] [loss avg: 3.406654] [current loss: 0.041043]
[Epoch: 82] [loss avg: 3.367659] [current loss: 0.066007]
[Epoch: 83] [loss avg: 3.328158] [current loss: 0.002587]
[Epoch: 84] [loss avg: 3.290007] [current loss: 0.003981]
[Epoch: 85] [loss avg: 3.252402] [current loss: 0.018630]
[Epoch: 86] [loss avg: 3.215755] [current loss: 0.019555]
[Epoch: 87] [loss avg: 3.178974] [current loss: 0.000735]
[Epoch: 88] [loss avg: 3.142999] [current loss: 0.005287]
[Epoch: 89] [loss avg: 3.108082] [current loss: 0.000395]
[Epoch: 90] [loss avg: 3.073640] [current loss: 0.000322]
[Epoch: 91] [loss avg: 3.039948] [current loss: 0.002971]
[Epoch: 92] [loss avg: 3.007570] [current loss: 0.000320]
[Epoch: 93] [loss avg: 2.975409] [current loss: 0.005074]
[Epoch: 94] [loss avg: 2.944152] [current loss: 0.000311]
[Epoch: 95] [loss avg: 2.913317] [current loss: 0.000142]
[Epoch: 96] [loss avg: 2.883204] [current loss: 0.002172]
[Epoch: 97] [loss avg: 2.853543] [current loss: 0.000057]
[Epoch: 98] [loss avg: 2.824478] [current loss: 0.000356]
[Epoch: 99] [loss avg: 2.796013] [current loss: 0.000959]
[Epoch: 100] [loss avg: 2.768085] [current loss: 0.001082]
Finished Training
4. 模型测试
count = 0
# 模型测试
net.eval() #注意启用测试模式
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred_test = outputs
count = 1
else:
y_pred_test = np.concatenate( (y_pred_test, outputs) )
# 生成分类报告
classification = classification_report(ytest, y_pred_test, digits=4)
print(classification)
precision recall f1-score support
0.0 1.0000 0.8293 0.9067 41
1.0 0.9894 0.9463 0.9674 1285
2.0 0.9946 0.9906 0.9926 747
3.0 0.9952 0.9812 0.9882 213
4.0 0.9753 0.9977 0.9864 435
5.0 0.9908 0.9863 0.9886 657
6.0 1.0000 1.0000 1.0000 25
7.0 0.9908 1.0000 0.9954 430
8.0 0.9375 0.8333 0.8824 18
9.0 0.9863 0.9897 0.9880 875
10.0 0.9683 0.9950 0.9815 2210
11.0 0.9720 0.9738 0.9729 534
12.0 1.0000 0.9081 0.9518 185
13.0 0.9913 0.9991 0.9952 1139
14.0 0.9799 0.9827 0.9813 347
15.0 0.8721 0.8929 0.8824 84
accuracy 0.9819 9225
macro avg 0.9777 0.9566 0.9663 9225
weighted avg 0.9821 0.9819 0.9818 9225
5. 备用函数
下面是用于计算各个类准确率,显示结果的备用函数,以供参考
from operator import truediv
def AA_andEachClassAccuracy(confusion_matrix):
counter = confusion_matrix.shape[0]
list_diag = np.diag(confusion_matrix)
list_raw_sum = np.sum(confusion_matrix, axis=1)
each_acc = np.nan_to_num(truediv(list_diag, list_raw_sum))
average_acc = np.mean(each_acc)
return each_acc, average_acc
def reports (test_loader, y_test, name):
count = 0
# 模型测试
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred = outputs
count = 1
else:
y_pred = np.concatenate( (y_pred, outputs) )
if name == 'IP':
target_names = ['Alfalfa', 'Corn-notill', 'Corn-mintill', 'Corn'
,'Grass-pasture', 'Grass-trees', 'Grass-pasture-mowed',
'Hay-windrowed', 'Oats', 'Soybean-notill', 'Soybean-mintill',
'Soybean-clean', 'Wheat', 'Woods', 'Buildings-Grass-Trees-Drives',
'Stone-Steel-Towers']
elif name == 'SA':
target_names = ['Brocoli_green_weeds_1','Brocoli_green_weeds_2','Fallow','Fallow_rough_plow','Fallow_smooth',
'Stubble','Celery','Grapes_untrained','Soil_vinyard_develop','Corn_senesced_green_weeds',
'Lettuce_romaine_4wk','Lettuce_romaine_5wk','Lettuce_romaine_6wk','Lettuce_romaine_7wk',
'Vinyard_untrained','Vinyard_vertical_trellis']
elif name == 'PU':
target_names = ['Asphalt','Meadows','Gravel','Trees', 'Painted metal sheets','Bare Soil','Bitumen',
'Self-Blocking Bricks','Shadows']
classification = classification_report(y_test, y_pred, target_names=target_names)
oa = accuracy_score(y_test, y_pred)
confusion = confusion_matrix(y_test, y_pred)
each_acc, aa = AA_andEachClassAccuracy(confusion)
kappa = cohen_kappa_score(y_test, y_pred)
return classification, confusion, oa*100, each_acc*100, aa*100, kappa*100
检测结果写在文件里:
classification, confusion, oa, each_acc, aa, kappa = reports(test_loader, ytest, 'IP')
classification = str(classification)
confusion = str(confusion)
file_name = "classification_report.txt"
with open(file_name, 'w') as x_file:
x_file.write('\n')
x_file.write('{} Kappa accuracy (%)'.format(kappa))
x_file.write('\n')
x_file.write('{} Overall accuracy (%)'.format(oa))
x_file.write('\n')
x_file.write('{} Average accuracy (%)'.format(aa))
x_file.write('\n')
x_file.write('\n')
x_file.write('{}'.format(classification))
x_file.write('\n')
x_file.write('{}'.format(confusion))
下面代码用于显示分类结果:
# load the original image
X = sio.loadmat('./src/data/Indian_pines_corrected.mat')['indian_pines_corrected']
y = sio.loadmat('./src/data/Indian_pines_gt.mat')['indian_pines_gt']
height = y.shape[0]
width = y.shape[1]
X = applyPCA(X, numComponents= pca_components)
X = padWithZeros(X, patch_size//2)
# 逐像素预测类别
outputs = np.zeros((height,width))
for i in range(height):
for j in range(width):
if int(y[i,j]) == 0:
continue
else :
image_patch = X[i:i+patch_size, j:j+patch_size, :]
image_patch = image_patch.reshape(1,image_patch.shape[0],image_patch.shape[1], image_patch.shape[2], 1)
X_test_image = torch.FloatTensor(image_patch.transpose(0, 4, 3, 1, 2)).to(device)
prediction = net(X_test_image)
prediction = np.argmax(prediction.detach().cpu().numpy(), axis=1)
outputs[i][j] = prediction+1
if i % 20 == 0:
print('... ... row ', i, ' handling ... ...')
... ... row 0 handling ... ...
... ... row 20 handling ... ...
... ... row 40 handling ... ...
... ... row 60 handling ... ...
... ... row 80 handling ... ...
... ... row 100 handling ... ...
... ... row 120 handling ... ...
... ... row 140 handling ... ...
predict_image = spectral.imshow(classes = outputs.astype(int),figsize =(5,5))
D:\Anaconda3\envs\PyTorch\lib\site-packages\spectral\graphics\spypylab.py:27: MatplotlibDeprecationWarning:
The keymap.all_axes rcparam was deprecated in Matplotlib 3.3 and will be removed two minor releases later.
mpl.rcParams['keymap.all_axes'] = ''
D:\Anaconda3\envs\PyTorch\lib\site-packages\spectral\graphics\spypylab.py:905: MatplotlibDeprecationWarning: Passing parameters norm and vmin/vmax simultaneously is deprecated since 3.3 and will become an error two minor releases later. Please pass vmin/vmax directly to the norm when creating it.
self.class_axes = plt.imshow(self.class_rgb, **kwargs)


