第四次作业:猫狗大战挑战赛
第四次作业:猫狗大战挑战赛
作为深度学习的基础案例,通过猫狗二分类来对深度学习的网络建立简单的功能映射,通过调整参数获得更好的结果。
代码参考:
(作业心得请直接跳到最后)
根据参考代码,我先在自己电脑的环境下运行了,得到的结果如下两张图:
训练处理过的1800张数据得到的结果,可以看到正确率为0.8211。
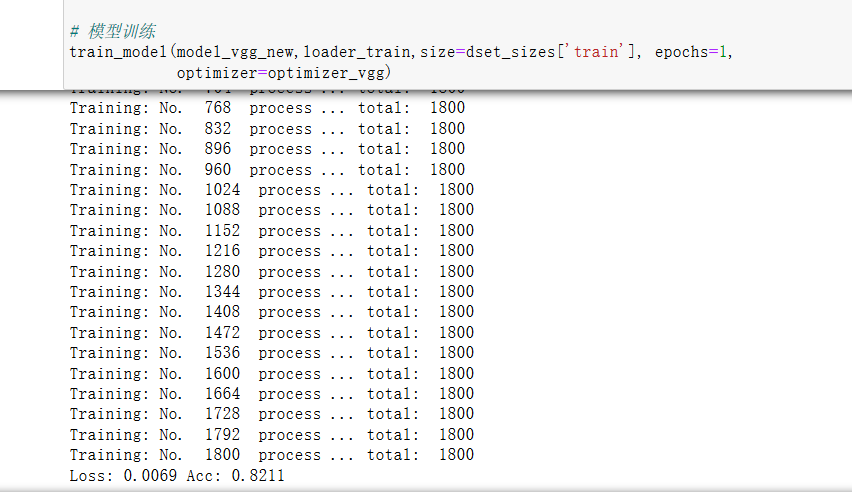
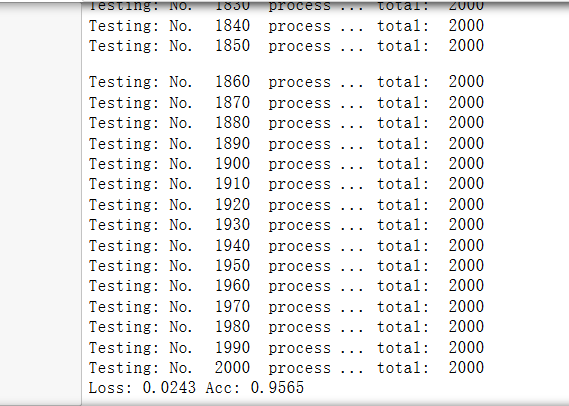
验证2000张图片的结果,正确率为0.9565
作为新生一代的 “调参侠” ,那我肯定不能放过这次机会,尽量通过修改可能影响正确率的参数来达到更高的正确率。
下面是处理过程:
1. 环境搭建
因为自己有一张 GTX 1660 Super 老黄显卡,本次作业没有选择在colab上进行。
实验环境 : PyTorch 1.7.0 + jupyter notebook (相关python包要自己安装)
1 import os 2 import torch 3 import torch.nn as nn 4 from torchvision import models,transforms,datasets 5 import tqdm 6 from tqdm import tqdm, trange
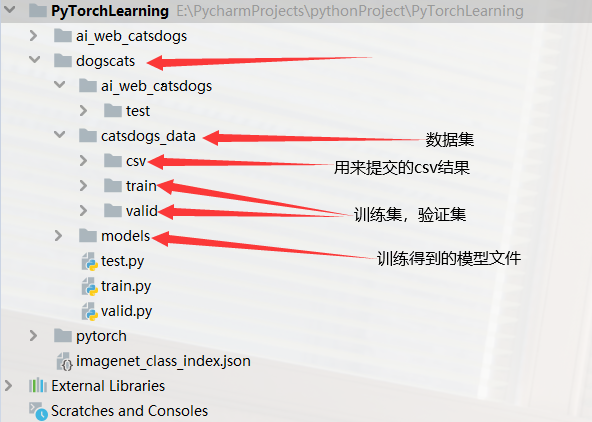
2.项目结构
大体结构如下图:
3.相关代码
3.1 train.py
训练模型,主要思路是将训练好的、效果比较好的模型使用PyTorch进行加载(当然有一个预先保存的模型文件),然后训练过程如果识别的准确率高于我们设定的值,就把模型保存下来,循环反复。
这里相对于原代码新加了两个线性层,并且使用Adam优化器替代SGD。
1 import os 2 import torch 3 import torch.nn as nn 4 from torchvision import models,transforms,datasets 5 import tqdm 6 from tqdm import tqdm, trange 7 8 # 判断是否存在GPU设备 9 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") 10 print('Using gpu: %s ' % torch.cuda.is_available()) 11 12 normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) 13 14 vgg_format = transforms.Compose([ 15 transforms.CenterCrop(224), 16 transforms.ToTensor(), 17 normalize, 18 ]) 19 20 data_dir = './catsdogs_data' 21 22 dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format) 23 for x in ['train', 'valid']} 24 25 dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid']} 26 dset_classes = dsets['train'].classes 27 28 loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=0) 29 30 model_vgg_new = torch.load("./models/save4/model85_0.9982_.pth") 31 model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 4096) 32 model_vgg_new.classifier._modules['7'] = torch.nn.Dropout() 33 model_vgg_new.classifier._modules['8'] = nn.Linear(4096, 4096) 34 model_vgg_new.classifier._modules['9'] = torch.nn.ReLU() 35 model_vgg_new.classifier._modules['10'] = nn.Linear(4096, 4096) 36 model_vgg_new.classifier._modules['11'] = torch.nn.ReLU() 37 model_vgg_new.classifier._modules['12'] = torch.nn.Dropout() 38 model_vgg_new.classifier._modules['13'] = nn.Linear(4096, 2) 39 model_vgg_new.classifier._modules['14'] = torch.nn.LogSoftmax(dim = 1) 40 model_vgg_new = model_vgg_new.to(device) 41 ''' 42 第一步:创建损失函数和优化器 43 44 损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签. 45 它不会为我们计算对数概率,适合最后一层是log_softmax()的网络. 46 ''' 47 criterion = nn.NLLLoss() 48 49 # 学习率 50 lr = 0.001 51 52 # Adam优化器 53 optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(), lr=lr) 54 55 ''' 56 第二步:训练模型 57 ''' 58 59 def train_model(model, dataloader, size, epochs=1, optimizer=None): 60 model.train() 61 62 for epoch in range(epochs): 63 running_loss = 0.0 64 running_corrects = 0 65 count = 0 66 if __name__ == '__main__': 67 for inputs, classes in tqdm(dataloader): 68 inputs = inputs.to(device) 69 classes = classes.to(device) 70 outputs = model(inputs) 71 loss = criterion(outputs, classes) 72 optimizer = optimizer 73 optimizer.zero_grad() 74 loss.backward() 75 optimizer.step() 76 _, preds = torch.max(outputs.data, 1) 77 # statistics 78 running_loss += loss.data.item() 79 running_corrects += torch.sum(preds == classes.data) 80 count += len(inputs) 81 # print('Training: No. ', count, ' process ... total: ', size) 82 epoch_loss = running_loss / size 83 epoch_acc = running_corrects.data.item() / size 84 if (epoch_acc > 0.999): 85 path = './models/save5/model' + str(epoch) + '_' + str(epoch_acc) + '_' + '.pth' 86 torch.save(model, path) 87 print("save: ", path,"\n") 88 print("epoch: {:}, Loss: {:.4f} Acc: {:.4f}\n".format(epoch, 89 epoch_loss, epoch_acc)) 90 91 92 # 模型训练 93 train_model(model_vgg_new, loader_train, size=dset_sizes['train'], epochs=100, 94 optimizer=optimizer_vgg)
3.2 valid.py
验证集,读入训练的效果最好的模型,对2000个图片数据(初始数据)进行测试,如果效果好就去test.py测试研习社上的测试数据。
1 import numpy as np 2 import matplotlib.pyplot as plt 3 import os 4 import torch 5 import torch.nn as nn 6 import torchvision 7 from torchvision import models,transforms,datasets 8 import time 9 import json 10 import tqdm 11 12 # 判断是否存在GPU设备 13 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") 14 print('Using gpu: %s ' % torch.cuda.is_available()) 15 16 normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) 17 18 vgg_format = transforms.Compose([ 19 transforms.CenterCrop(224), 20 transforms.ToTensor(), 21 normalize, 22 ]) 23 data_dir = './catsdogs_data' 24 25 dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format) 26 for x in ['train', 'valid']} 27 28 dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid']} 29 dset_classes = dsets['train'].classes 30 31 loader_valid = torch.utils.data.DataLoader(dsets['valid'], batch_size=1, shuffle=False, num_workers=0) 32 33 model_vgg_new = torch.load("./models/save/model18_0.9847_.pth") 34 35 criterion = nn.NLLLoss() 36 37 # 学习率 38 lr = 0.001 39 40 # Adam优化器 41 optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(),lr = lr) 42 43 def test_model(model, dataloader, size): 44 model.eval() 45 predictions = np.zeros(size, dtype=int) 46 all_classes = np.zeros(size) 47 all_proba = np.zeros((size, 2)) 48 i = 0 49 running_loss = 0.0 50 running_corrects = 0 51 for inputs, classes in dataloader: 52 inputs = inputs.to(device) 53 classes = classes.to(device) 54 outputs = model(inputs) 55 loss = criterion(outputs, classes) 56 _, preds = torch.max(outputs.data, 1) 57 # statistics 58 running_loss += loss.data.item() 59 running_corrects += torch.sum(preds == classes.data) 60 predictions[i:i + len(classes)] = preds.to('cpu').numpy() 61 all_classes[i:i + len(classes)] = classes.to('cpu').numpy() 62 all_proba[i:i + len(classes), :] = outputs.data.to('cpu').numpy() 63 i += len(classes) 64 # print('Testing: No. ', i, ' process ... total: ', size, ' preds:', preds) 65 epoch_loss = running_loss / size 66 epoch_acc = running_corrects.data.item() / size 67 print('Loss: {:.4f} Acc: {:.4f} '.format( 68 epoch_loss, epoch_acc, predictions)) 69 return predictions, all_proba, all_classes 70 71 72 predictions, all_proba, all_classes = test_model(model_vgg_new, loader_valid, size=dset_sizes['valid']) 73 print("done")
3.3 test.py
读入训练得到效果最好的模型,测试研习社猫狗大战的测试数据,计算正确率,并且保存结果到csv文件,如果效果好,就直接到网站上提交。
1 import torchvision 2 import os 3 import torch 4 from torchvision import models,transforms,datasets 5 import numpy as np 6 7 # 判断是否存在GPU设备 8 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") 9 print('Using gpu: %s ' % torch.cuda.is_available()) 10 11 normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) 12 13 vgg_format = transforms.Compose([ 14 transforms.CenterCrop(224), 15 transforms.ToTensor(), 16 normalize, 17 ]) 18 19 dsets_mine = datasets.ImageFolder("./ai_web_catsdogs", vgg_format) 20 loader_test = torch.utils.data.DataLoader(dsets_mine, batch_size=1, shuffle=False, num_workers=0) 21 22 dic = {} 23 model_vgg_new = torch.load("./models/save4/model85_0.9982_.pth") 24 25 def test(model,dataloader,size): 26 model.eval() 27 predictions = np.zeros(size) 28 cnt = 0 29 for inputs,_ in dataloader: 30 inputs = inputs.to(device) 31 outputs = model(inputs) 32 _,preds = torch.max(outputs.data,1) 33 key = dsets_mine.imgs[cnt][0].split("\\")[-1].split('.')[0] 34 dic[key] = preds[0] 35 cnt = cnt + 1 36 test(model_vgg_new,loader_test,size=2000) 37 38 with open("./catsdogs_data/csv/ans14.csv",'a+') as f: 39 for key in range(2000): 40 f.write("{},{}\n".format(key,dic[str(key)])) 41 print("done")
4.实验结果
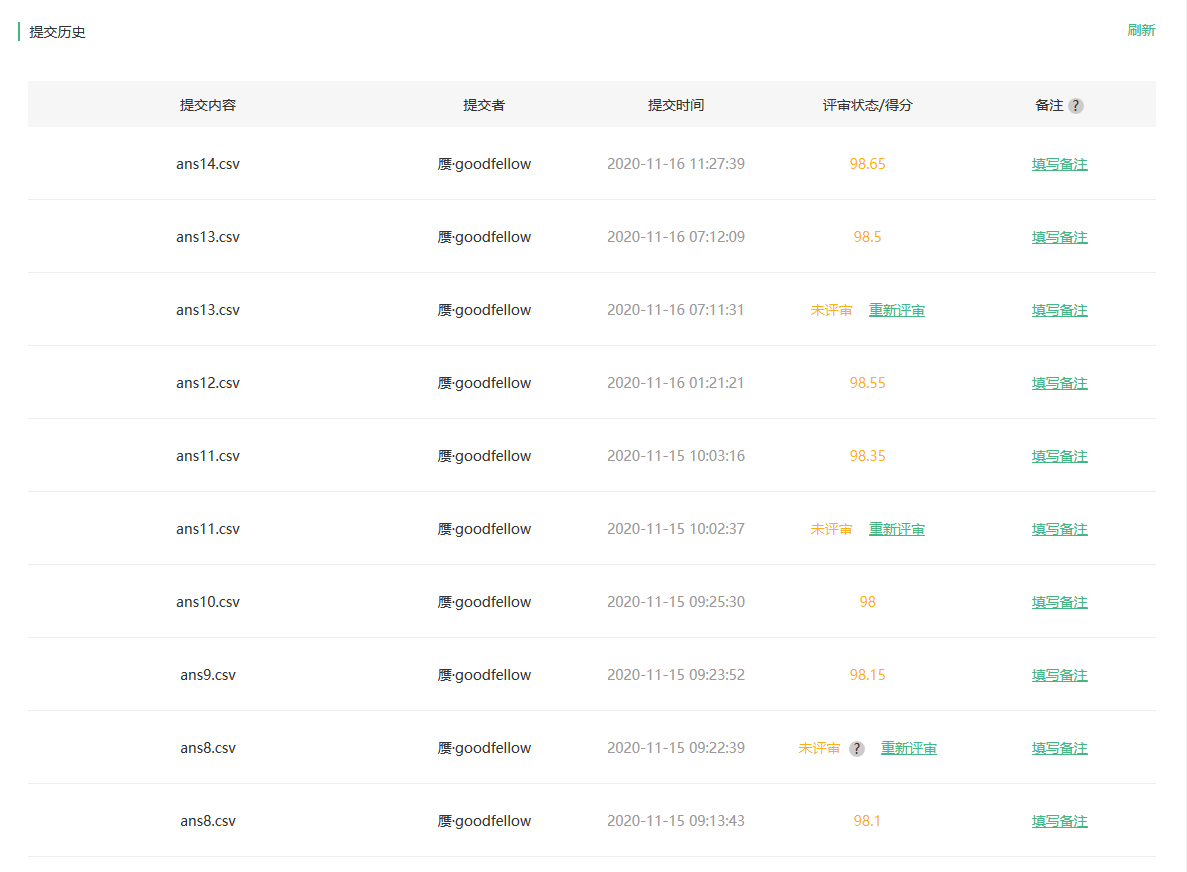
下图是研习社提交的分数截图,目前最高的是98.65分,希望在学习完课程之后能通过改进达到更高的分数!
下图是训练得到的模型文件
5.总结(心得)
总结来说,要得到更好的正确率,从我的角度来考虑,总共有以下几个方面:
1. 训练集的数据量,因为看到训练集只有1800张图片,显然我们有更多的数据,因此我采用了20000张猫狗图片进行训练。
2.隐藏层的数量,新加了两个线性隐藏层,正确率提高了大概0.5个百分点。
3.迭代的次数,初始只迭代一轮,改成了迭代100轮,通过计算得到的正确率数值,值大于期望值的时候,就将当前模型保存到本地。
4.优化器的选择,初始使用的SGD,经过测试,使用Adam优化器会在1800个图片训练集中明显提升训练正确率(3个百分点左右,但是20000个图片训练集相差不到1个百分点)。
5. batch_size的大小,初始值为64。在原始数据处理方式不变的情况下,我的机器最多选用 batch_size = 128,得到的最好的拟合正确率为0.9971。
我也试过对数据处理部分进行修改,我修改了图片的缩放比例。
原始是224*224,我改成512,但是显存明显不够了,无法在本地正常完成,因此改成300*300,得到训练集的正确率(1800张图片)很快的到了0.99+,当时还觉得高兴,但是拿来测试,得到的准确率并不高,因此没有保留结果。
(经验证,给的训练集(1800张)与验证集(2000张)数据有交集。而研习社上的测试集(2000张)和给的验证集(2000张)数据也有交集 , 意味这训练集和验证集没有完全分开)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2020年11月17日更新
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
在colab部署的时候重新写了一下 test.py 如下: (做记录)
用pandas处理数据.
(数据处理和模型load省略)
1 import pandas as pd 2 3 def test_best_model(best_model, dataloader, size): 4 5 ''' 6 测试研习社上的测试数据,存入csv文件。 7 总共有2000张图片, 8 这些图片初始数据名字是 "1.jpg","2.jpg","3.jpg", ... ,"1999.jpg" 9 经处理是 "000001.jpg","000002.jpg","000003.jpg", ... ,"001999.jpg", 10 因为 torch.utils.data.DataLoader 加载数据的时候是按字符的顺序来读取文件的 11 ''' 12 13 best_model.eval() 14 15 indices_list = torch.arange(0, data_size) 16 predicts_list = [] 17 18 for inputs, _ in tqdm(dataloader): 19 inputs = inputs.to(device) 20 outputs = best_model(inputs) 21 _, preds = torch.max(outputs.data, 1) 22 [predicts_list.append(x) for x in preds.cpu().numpy().tolist()] 23 ans_frame = pd.DataFrame({"indices":indices_list, "predicts_list":predicts_list}) 24 ans_frame.to_csv("/content/drive/MyDrive/catsdogs/csv/ans.csv", index=False, header=False, sep=',') 25 26 test_best_model(model_vgg_best, data_loader, data_size)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2020年11月18日更新
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
记录一下colab上的项目结构(准备删除了,colab普通用户限额)


