

1.今天给大家介绍自己写的一个图片爬虫,说白了就是从网页自动上下载需要的图片
2.首先选取目标为:http://www.zhangzishi.cc/涨姿势这个网站如下图,我们的目标就是爬取该网站福利社的所有美图

3.福利社地址为http://www.zhangzishi.cc/category/welfare,获取图片就是获取所有网站图片的url地址,首先
A.打开URL,获取html代码
def url_open(url): req = urllib.request.Request(url) req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36') response = urllib.request.urlopen(req) html = response.read() print('url_open') return html
B.从html代码中摘取网页链接,返回的是一个列表

def page_htmls(url,count): html = url_open(url).decode('utf-8') pages = [] a = html.find('a target="_blank" href=') i = 0 while a != -1: i += 1 b = html.find('.html',a,a+200) if b != -1: pages.append(html[a+24:b+5]) else: b = a + 24 a = html.find('a target="_blank" href=',b) if i == count: break for each in pages: print(each) return pages
C.从每一个链接页中获取图片地址,我这用了两种方法
def find_imgs(url): html = url_open(url).decode('utf-8') imgs = [] a = html.find('img src=') while a != -1: b = html.find('.jpg',a,a+100) if b != -1: if html[a+9:b+4].find('http') == -1: imgs.append('http:'+html[a+9:b+4]) else: imgs.append(html[a+9:b+4]) else: b = a + 9 a = html.find('img src=',b) ''' for each in imgs: print(each) ''' return imgs def imgurl_get(url): html = url_open(url).decode('utf-8') imgurls = [] a = html.find('color: #555555;" src=') while a != -1: b = html.find('.jpg',a,a+100) if b != -1: imgurls.append('http:'+html[a+22:b+4]) else: b = a + 22 a = html.find('color: #555555;" src=',b) return imgurls
D.根据图片url下载图片到文件
def save_imgs(folder,imgs): for ea in imgs: filename = ea.split('/')[-1] with open(filename,'wb') as f: img = url_open(ea) f.write(img) def download_mm(folder='H:\\xxoo2',page_count = 100,count = 100): main_url = 'http://www.zhangzishi.cc/category/welfare' main_urls = [] for i in range(count): main_urls.append(main_url+'/page/'+str(i+1)) os.mkdir(folder) os.chdir(folder) for url in main_urls: htmls = page_htmls(url,page_count) for page in htmls: imgurls = imgurl_get(page) save_imgs(folder,imgurls)
E.开始下载
def download__img(folder='H:\\xxoo',page_count=100): main_url = 'http://www.zhangzishi.cc/category/welfare' os.mkdir(folder) os.chdir(folder) htmls = page_htmls(main_url,page_count) for page in htmls: imgs_url = find_imgs(page) save_imgs(folder,imgs_url) if __name__ == '__main__': download_mm() #download__img()
F:下载结果
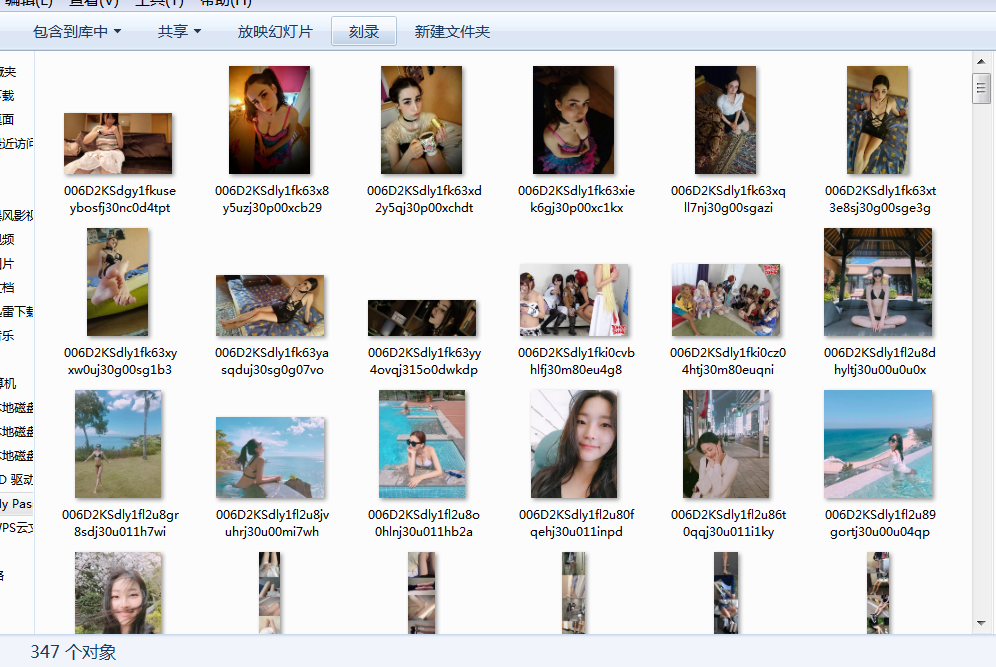
顺便附上全部代码:
import urllib.request import os def url_open(url): req = urllib.request.Request(url) req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36') response = urllib.request.urlopen(req) html = response.read() print('url_open') return html def page_htmls(url,count): html = url_open(url).decode('utf-8') pages = [] a = html.find('a target="_blank" href=') i = 0 while a != -1: i += 1 b = html.find('.html',a,a+200) if b != -1: pages.append(html[a+24:b+5]) else: b = a + 24 a = html.find('a target="_blank" href=',b) if i == count: break for each in pages: print(each) return pages ''' ''' def find_imgs(url): html = url_open(url).decode('utf-8') imgs = [] a = html.find('img src=') while a != -1: b = html.find('.jpg',a,a+100) if b != -1: if html[a+9:b+4].find('http') == -1: imgs.append('http:'+html[a+9:b+4]) else: imgs.append(html[a+9:b+4]) else: b = a + 9 a = html.find('img src=',b) ''' for each in imgs: print(each) ''' return imgs def imgurl_get(url): html = url_open(url).decode('utf-8') imgurls = [] a = html.find('color: #555555;" src=') while a != -1: b = html.find('.jpg',a,a+100) if b != -1: imgurls.append('http:'+html[a+22:b+4]) else: b = a + 22 a = html.find('color: #555555;" src=',b) return imgurls ''' for each in imgurls: print(each) ''' def save_imgs(folder,imgs): for ea in imgs: filename = ea.split('/')[-1] with open(filename,'wb') as f: img = url_open(ea) f.write(img) def download_mm(folder='H:\\xxoo2',page_count = 100,count = 100): main_url = 'http://www.zhangzishi.cc/category/welfare' main_urls = [] for i in range(count): main_urls.append(main_url+'/page/'+str(i+1)) os.mkdir(folder) os.chdir(folder) for url in main_urls: htmls = page_htmls(url,page_count) for page in htmls: imgurls = imgurl_get(page) save_imgs(folder,imgurls) def download__img(folder='H:\\xxoo',page_count=100): main_url = 'http://www.zhangzishi.cc/category/welfare' os.mkdir(folder) os.chdir(folder) htmls = page_htmls(main_url,page_count) for page in htmls: imgs_url = find_imgs(page) save_imgs(folder,imgs_url) if __name__ == '__main__': download_mm() #download__img()
需要程序源码的可以加我微信x241602私聊。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?