【Leetcode刷题】——Linked List - 链表
Linked List - 链表
1.编程实现
struct ListNode{
int val;
ListNode *next;
ListNode(int val,ListNode *next=NULL):val(val),next(next){}
}
2.链表的基本操作
1.反转链表
a.单向链表:链表的基本形式是:1 -> 2 -> 3 -> null,反转需要变为 3 -> 2 -> 1 -> null。这里要注意:
- 访问某个节点 curt.next 时,要检验 curt 是否为 null。
- 要把反转后的最后一个节点(即反转前的第一个节点)指向 null。
public ListNode reverseList(ListNode head) {
ListNode prev = null;
ListNode curr = head;
while (curr != null) {
ListNode nextTemp = curr.next;
curr.next = prev;
prev = curr;
curr = nextTemp;
}
return prev;
}
在遍历列表时,将当前节点的 next 指针改为指向前一个元素。由于节点没有引用其上一个节点,因此必须事先存储其前一个元素。在更改引用之前,还需要另一个指针来存储下一个节点。不要忘记在最后返回新的头引用!
b.双向链表:和单向链表的区别在于:双向链表的反转核心在于next和prev域的交换,还需要注意的是当前节点和上一个节点的递推。
- 确定当前要更改的节点curr
- head是下一个要遍历的节点,并且保存curr的next域
- 将curr的next域指向curr的prev域,这样就完成了next的反转
- 再将curr的prev域指向curr的next域(也就是之前head保存的),这样就完成了prev的反转
class DListNode {
int val;
DListNode prev, next;
DListNode(int val) {
this.val = val;
this.prev = this.next = null;
}
}
public DListNode reverse(DListNode head) {
DListNode curr = null;
while (head != null) {
curr = head;
head = curr.next;
curr.next = curr.prev;
curr.prev = head;
}
return curr;
}
2.删除链表中的某个节点
删除链表中的某个节点一定需要知道这个点的前继节点,所以需要一直有指针指向前继节点。还有一种删除是伪删除,是指复制一个和要删除节点值一样的节点,然后删除,这样就不必知道其真正的前继节点了。
然后只需要把 prev -> next = prev -> next -> next 即可。但是由于链表表头可能在这个过程中产生变化,导致我们需要一些特别的技巧去处理这种情况。(也就是当删除表头节点的时候会出现变化,表头节点没有pre)就是下面提到的 Dummy Node。其实就是经常提到的头结点。
Dummy Node
Dummy node 是链表问题中一个重要的技巧,中文翻译叫“哑节点”或者“假人头结点”。
Dummy node 是一个虚拟节点,也可以认为是标杆节点。Dummy node 就是在链表表头 head 前加一个节点指向 head,即 dummy -> head。Dummy node 的使用多针对单链表没有前向指针的问题,保证链表的 head 不会在删除操作中丢失。除此之外,还有一种用法比较少见,就是使用 dummy node 来进行head的删除操作,比如 Remove Duplicates From Sorted List II,一般的方法current = current.next 是无法删除 head 元素的,所以这个时候如果有一个dummy node在head的前面。
所以,当链表的 head 有可能变化(被修改或者被删除)时,使用 dummy node 可以很好的简化代码,最终返回 dummy.next 即新的链表。
3.快慢指针
首先创建两个指针1和2,同时指向这个链表的头节点。然后开始一个大循环,在循环体中,让指针1每次向下移动一个节点,让指针2每次向下移动两个节点,然后比较两个指针指向的节点是否相同。如果相同,则判断出链表有环,如果不同,则继续下一次循环。
例如链表A->B->C->D->B->C->D,两个指针最初都指向节点A,进入第一轮循环,指针1移动到了节点B,指针2移动到了C。第二轮循环,指针1移动到了节点C,指针2移动到了节点B。第三轮循环,指针1移动到了节点D,指针2移动到了节点D,此时两指针指向同一节点,判断出链表有环。
此方法也可以用一个更生动的例子来形容:在一个环形跑道上,两个运动员在同一地点起跑,一个运动员速度快,一个运动员速度慢。当两人跑了一段时间,速度快的运动员必然会从速度慢的运动员身后再次追上并超过,原因很简单,因为跑道是环形的。
public bool isLoopList(ListNode<T> head){
ListNode<T> slowPointer, fastPointer;
//使用快慢指针,慢指针每次向前一步,快指针每次两步
slowPointer = fastPointer = head;
while(fastPointer != null && fastPointer.next != null){
slowPointer = slowPointer.next;
fastPointer = fastPointer.next.next;
//两指针相遇则有环,但不一定是在入环点相遇
if(slowPointer == fastPointer){
return true;
}
}
return false;
}
假设从链表头节点到入环点的距离是D,链表的环长是S。那么循环会进行S次(为什么是S次,有心的同学可以自己揣摩下),可以简单理解为O(N)。除了两个指针以外,没有使用任何额外存储空间,所以空间复杂度是O(1)。
如何找出有环链表的入环点?
当fast若与slow相遇时,slow肯定没有走遍历完链表(不是一整个环,有开头部分,如上图)或者恰好遍历一圈(未做验证,看我的表格例子,在1处相遇)。于是我们从链表头、相遇点分别设一个指针,每次各走一步,两个指针必定相遇,且相遇第一点为环入口点(慢指针走了n步,第一次相遇在c点,对慢指针来说n=s+p,也就是说如果慢指针从c点再走n步,又会到c点,那么顺时针的CB距离是n-p=s,但是我们不知道s是几,那么当快指针此时在A点一步一步走,当快慢指针相遇时,相遇点恰好是圆环七点B(AB=CB‘=s))。
/**
* 找到有环链表的入口
* @param head
* @return
*/
public static <T> ListNode<T> findEntranceInLoopList(ListNode<T> head){
ListNode<T> slowPointer, fastPointer;
//使用快慢指针,慢指针每次向前一步,快指针每次两步
boolean isLoop = false;
slowPointer = fastPointer = head;
while(fastPointer != null && fastPointer.next != null){
slowPointer = slowPointer.next;
fastPointer = fastPointer.next.next;
//两指针相遇则有环
if(slowPointer == fastPointer){
isLoop = true;
break;
}
}
//一个指针从链表头开始,一个从相遇点开始,每次一步,再次相遇的点即是入口节点
if(isLoop){
slowPointer = head;
while(fastPointer != null && fastPointer.next != null){
//两指针相遇的点即是入口节点
if(slowPointer == fastPointer){
return slowPointer;
}
slowPointer = slowPointer.next;
fastPointer = fastPointer.next;
}
}
return null;
}
3.链表常见题目
本节包含链表的一些常用操作,如删除、插入和合并等。
常见错误有 遍历链表不向前递推节点,遍历链表前未保存头节点,返回链表节点指针错误。
下图是把本章中所有出现的题目归类总结了一下,便于记忆
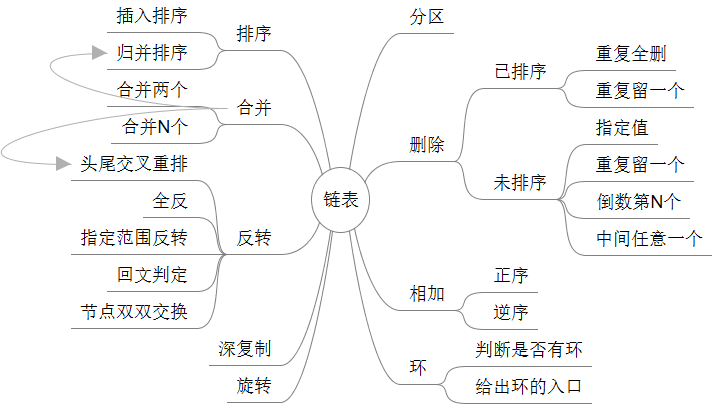
1.Remove Duplicates from Sorted List
题解
遍历之,遇到当前节点和下一节点的值相同时,删除下一节点,并将当前节点next值指向下一个节点的next, 当前节点首先保持不变,直到相邻节点的值不等时才移动到下一节点。
ListNode *deleteDuplicates(ListNode *head) {
ListNode *curr = head;
while (curr != NULL) {
while (curr->next != NULL && curr->val == curr->next->val) {
ListNode *temp = curr->next;
curr->next = curr->next->next;
delete(temp);
temp = NULL;
}
curr = curr->next;
}
return head;
}
2. Remove Duplicates from Sorted List II(82)
题解
上题为保留重复值节点的一个,这题删除全部重复节点,看似区别不大,但是考虑到链表头不确定(可能被删除,也可能保留),因此若用传统方式需要较多的if条件语句。这里介绍一个处理链表头节点不确定的方法——引入dummy node.
ListNode *dummy = new ListNode(0);
dummy->next = head;
ListNode *node = dummy;
引入新的指针变量dummy,并将其next变量赋值为head,考虑到原来的链表头节点可能被删除,故应该从dummy处开始处理,这里复用了head变量。考虑链表A->B->C,删除B时,需要处理和考虑的是A和C,将A的next指向C。如果从空间使用效率考虑,可以使用head代替以上的node,含义一样,node比较好理解点。
与上题不同的是,由于此题引入了新的节点dummy,不可再使用node->val == node->next->val,原因有二:
- 此题需要将值相等的节点全部删掉,而删除链表的操作与节点前后两个节点都有关系,故需要涉及三个链表节点。且删除单向链表节点时不能删除当前节点,只能改变当前节点的
next指向的节点。 - 在判断val是否相等时需先确定
node->next和node->next->next均不为空,否则不可对其进行取值。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (head == NULL) return NULL;
ListNode dummy(0);
dummy.next = head;
ListNode *node = &dummy;
while (node->next != NULL && node->next->next != NULL) {
if (node->next->val == node->next->next->val) {
int val_prev = node->next->val;
// remove ListNode node->next
while (node->next != NULL && val_prev == node->next->val) {
ListNode *temp = node->next;
node->next = node->next->next;
delete temp;
}
} else {
node = node->next;
}
}
return dummy.next;
}
3.Remove duplicates from an unsorted linked list - GeeksforGeeks
未排序,重复留一个
题解1 - 两重循环
Remove Duplicates 系列题,之前都是已排序链表,这个题为未排序链表。原题出自 CTCI 题2.1。
最容易想到的简单办法就是两重循环删除重复节点了,当前遍历节点作为第一重循环,当前节点的下一节点作为第二重循环。
ListNode *deleteDuplicates(ListNode *head) {
if (head == NULL) return NULL;
ListNode *curr = head;
while (curr != NULL) {
ListNode *inner = curr;
while (inner->next != NULL) {
if (inner->next->val == curr->val) {
inner->next = inner->next->next;
} else {
inner = inner->next;
}
}
curr = curr->next;
}
return head;
}
};
题解2 - 万能的 hashtable
使用辅助空间哈希表,节点值作为键,布尔值作为相应的值(是否为布尔值其实无所谓,关键是键)。
ListNode *deleteDuplicates(ListNode *head) {
if (head == NULL) return NULL;
// C++ 11 use unordered_map
// unordered_map<int, bool> hash;
map<int, bool> hash;
hash[head->val] = true;
ListNode *curr = head;
while (curr->next != NULL) {
if (hash.find(curr->next->val) != hash.end()) {//找到了相同的点
ListNode *temp = curr->next;
curr->next = curr->next->next;
delete temp;
} else {//没找到
hash[curr->next->val] = true;
curr = curr->next;
}
}
return head;
}
4.Partition List | LeetCode OJ
题解
依据题意,是要根据值x对链表进行分割操作,具体是指将所有小于x的节点放到不小于x的节点之前,咋一看和快速排序的分割有些类似,但是这个题的不同之处在于只要求将小于x的节点放到前面,而并不要求对元素进行排序。
这种分割的题使用两路指针即可轻松解决。左边指针指向小于x的节点,右边指针指向不小于x的节点。由于左右头节点的不确定(我们首先不知道哪个会在前或者后),我们可以使用两个dummy节点。
ListNode* partition(ListNode* head, int x) {
if (head == NULL) return NULL;
ListNode *leftDummy = new ListNode(0);
ListNode *left = leftDummy;
ListNode *rightDummy = new ListNode(0);
ListNode *right = rightDummy;
ListNode *node = head;
while (node != NULL) {
if (node->val < x) {
left->next = node;
left = left->next;
} else {
right->next = node;
right = right->next;
}
node = node->next;
}
// post-processing
right->next = NULL;
left->next = rightDummy->next;
return leftDummy->next;
}
- 异常处理
- 引入左右两个dummy节点及left和right左右尾指针
- 遍历原链表
- 处理右链表,置
right->next为空(否则如果不为尾节点则会报错,处理链表时 以 null 为判断),将右链表的头部链接到左链表尾指针的next,返回左链表的头部


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· DeepSeek 开源周回顾「GitHub 热点速览」
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了