流量治理核心策略
熔断、隔离、重试、降级、超时、限流
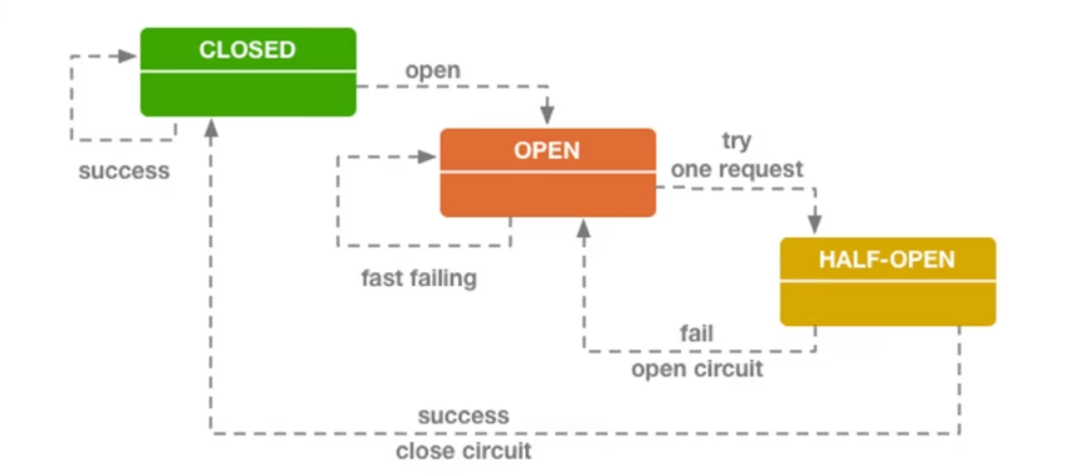
熔断
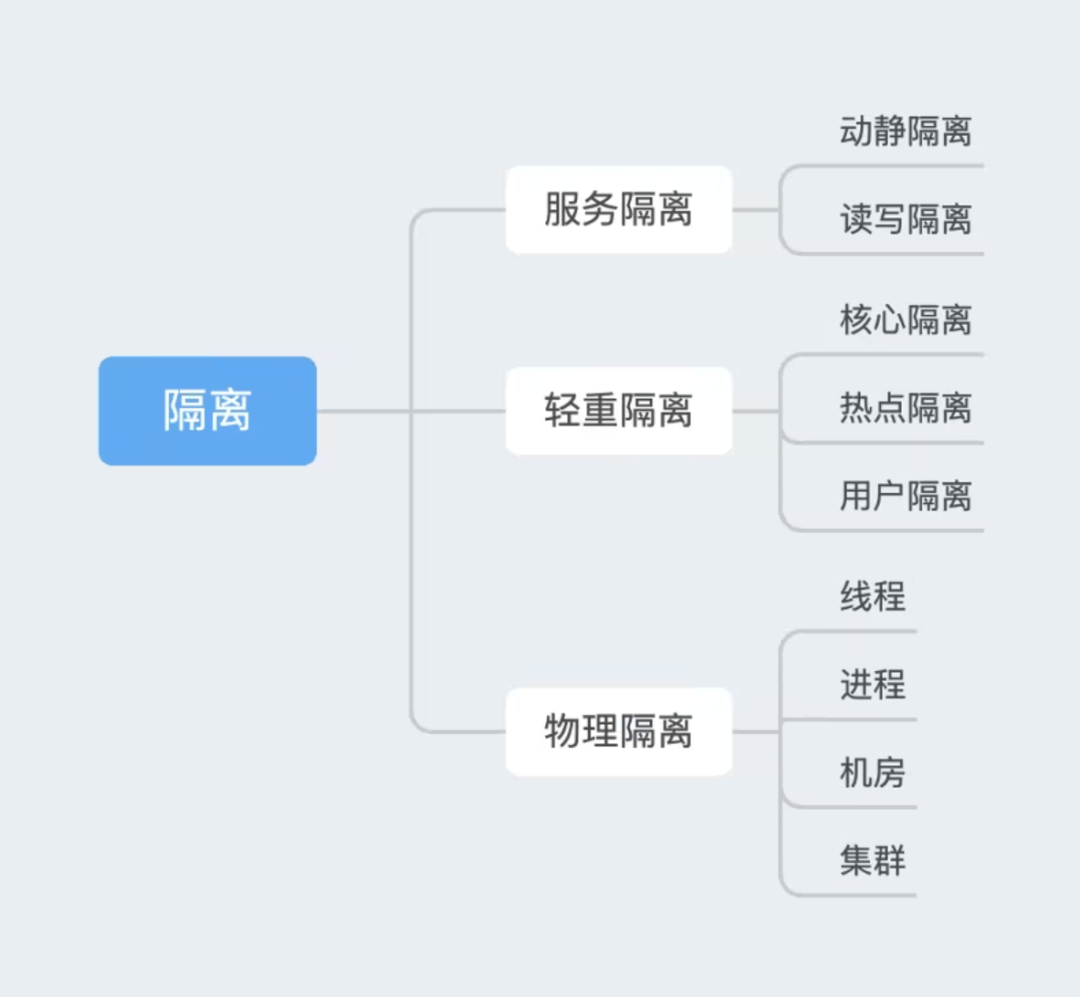
隔离
重试
-
感知错误:通过不同的错误码来识别不同的错误,在 HTTP 中 status code 可以用来识别不同类型的错误。
-
重试决策:这一步主要用来减少不必要的重试,比如 HTTP 的 4xx 的错误,通常 4xx 表示的是客户端的错误,这时候客户端不应该进行重试操作,或者在业务中自定义的一些错误也不应该被重试。根据这些规则的判断可以有效的减少不必要的重试次数,提升响应速度。
-
重试策略:重试策略就包含了重试间隔时间,重试次数等。如果次数不够,可能并不能有效的覆盖这个短时间故障的时间段,如果重试次数过多,或者重试间隔太小,又可能造成大量的资源(CPU、内存、线程、网络)浪费。
-
对冲策略:对冲是指在不等待响应的情况主动发送单次调用的多个请求,然后取首个返回的回包。
超时
如何选择合适的超时阈值?超时时间选择需要考虑的几个点:
-
被调服务的重要性;
-
被调服务的耗时 P99、P95、P50、平均值;
-
网络波动;
-
资源消耗;
-
用户体验。
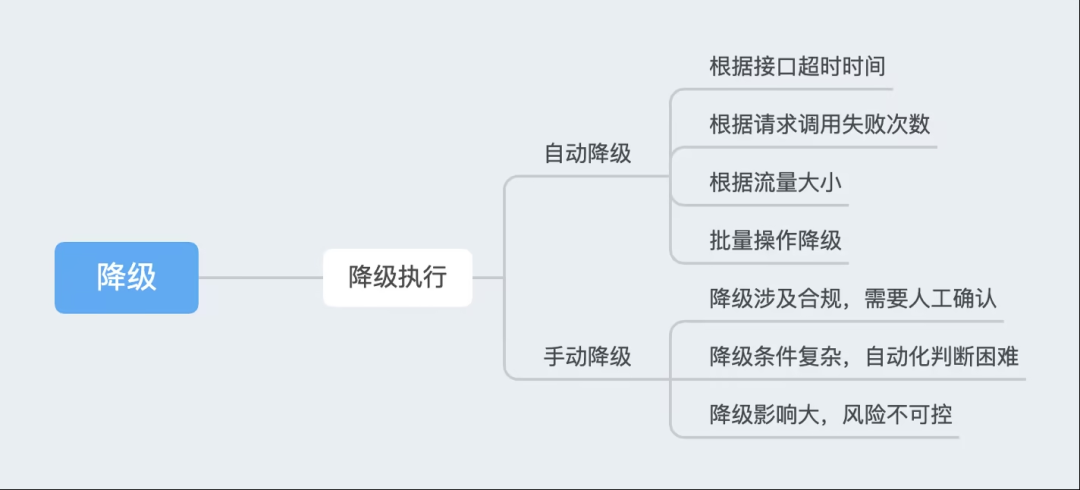
降级

限流

总结
-
熔断 机制,包括传统熔断器和 Google SRE 模型,作为防止系统过载的重要工具
-
隔离 策略,如动静隔离、读写隔离和机房隔离,通过物理或逻辑上分离资源和请求,减少单点故障的影响
-
重试 策略,包括同步和异步重试,以及各种退避机制,帮助在失败时优雅地恢复服务。
-
降级 操作,区分自动和手动降级,作为服务负载过重时的应急措施
-
超时 控制,通过精细的策略来避免长时间等待和资源浪费
-
限流 包括客户端和服务端限流,确保系统在高负载下仍能稳定运行
https://mp.weixin.qq.com/s/_3pht6cFdkuRfrE1z0dpKQ

 浙公网安备 33010602011771号
浙公网安备 33010602011771号