

redis故障总结
rehash原理
HashTable:Redis中有一个「全局哈希表」,该哈希表中保存所有的键值对。对于Hash表的查找操作时间复杂度为O(1)
Bucket:哈希表中的每一个元素称为哈希桶(Bucket),哈希桶中保存了键值对数据
Entry:保存键值对数据,如上图:其实Entry中保存的是Key,Value的指针值,通过对应的指针能够对Key,Value进行查找
举个例子:假设你现在要往Redis中写入一个String类型的数据,其中Key=username_1 ,Value=小明,那么Redis将调用Hash函数计算Key的哈希值,根据哈希值选择哈希表中对应的哈希桶,然后将Key,Value进行存储。并将Key,Value的指针存入哈希桶的Enrty中。
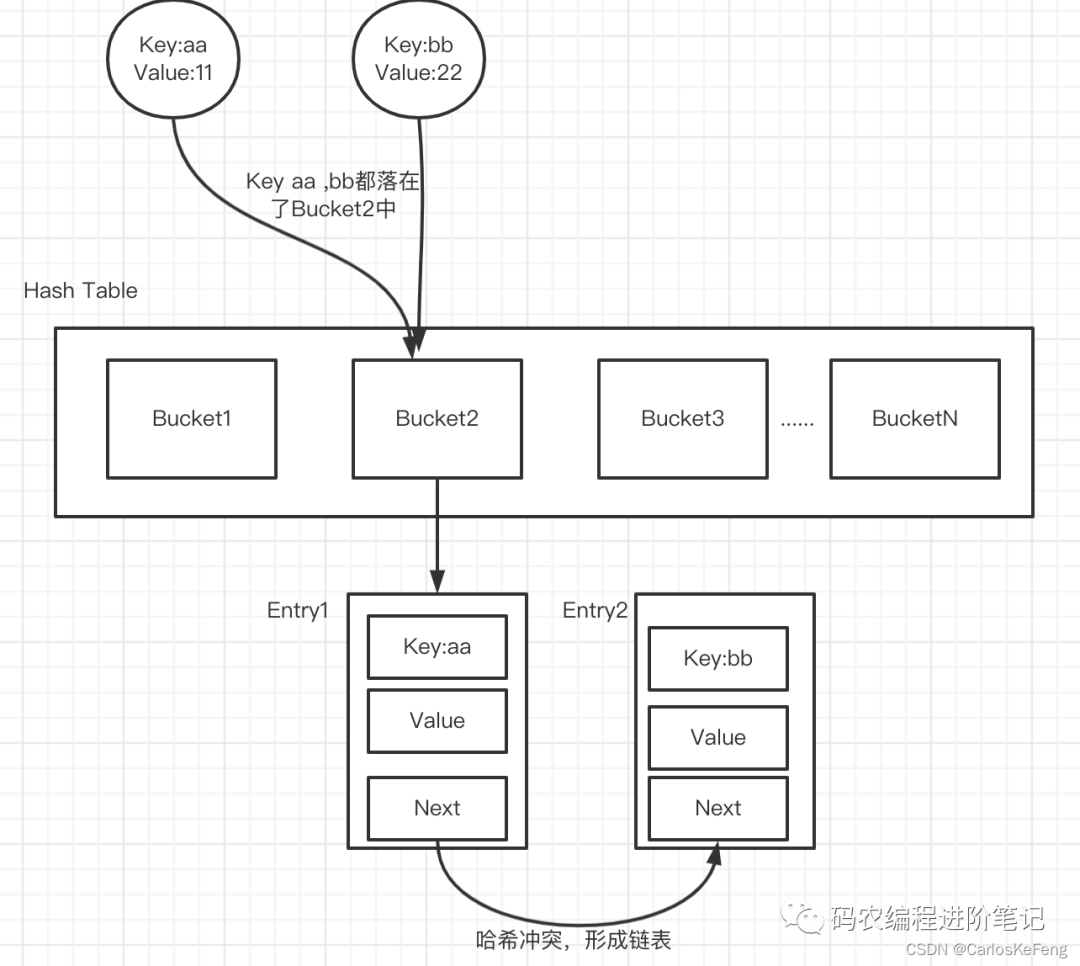
哈希表中桶的数量是有限的,当Key的数量较大时自然避免不了哈希冲突(多个Key落在了同一个哈希桶中)。当哈希桶中存在哈希冲突时那么多个Entry就形成了链表,每个链表中有一个Next指针指向了下一个元素。当哈希桶中的链表过长时,那么查询性能会显著降低(链表的查找时间复杂度为O(N)),Redis为了避免类似的问题从而会进行Rehash操作。

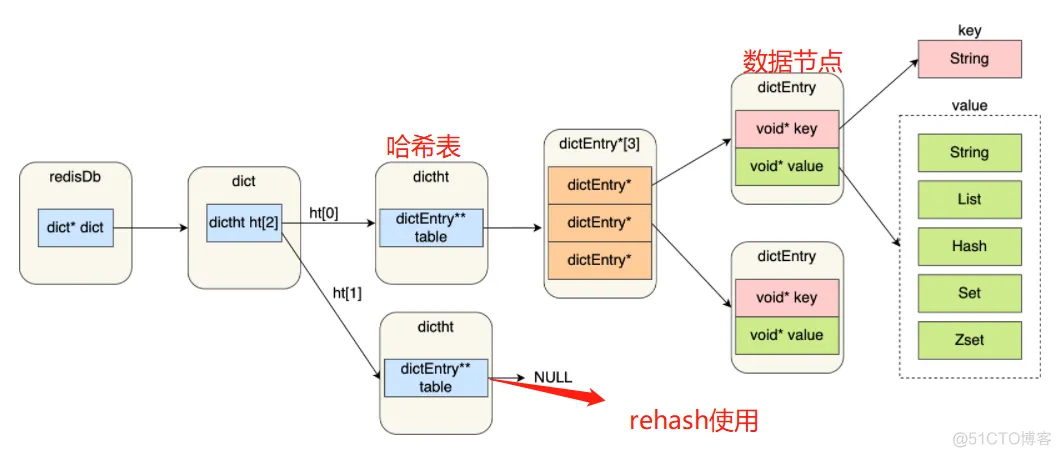

利用了两个哈希表进行的 , 有点类似数据库的迁移 , 读的时候先读旧库 , 读不到读新库 , 写的时候只写新库 ; 其他旧数据一点点的往新库上搬
当触发扩容的时候,Redis会首先为ht[1] 分配一块内存空间。如果当前字典是一个比较大的字典,那么整个扩容过程的时间复杂度为O(n),直接完整进行扩容机制可能会导致Redis一段时间内停止服务。为了避免停止服务的情况,Redis的设计团队采用了渐进式rehash的策略,每次只对原哈希表中的一小部分进行搬迁,这样渐进式的进行,直到全部键值对都迁移到新的哈希表中。
首先,对于key的查询,我们需要到原来的哈希表中进行查找,如果找到对应的value,直接返回就可以了。如果没有找到,那么只有两种可能,一个是这个键值对已经搬迁到新的哈希表了,另外一种可能是根本就不存在这个键值对,无论是哪种可能,我们都需要再去新哈希表中对他进行查找,如果找到了就返回,如果找不到说明这个键值对不存在。
渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
- [被动式触发] :每次外部调用的 CRUD 都会触发一次数据迁移,每次迁移一份数据
- [主动式触发] :定时任务,每次扫描一点数据进行迁移
hz参数调优
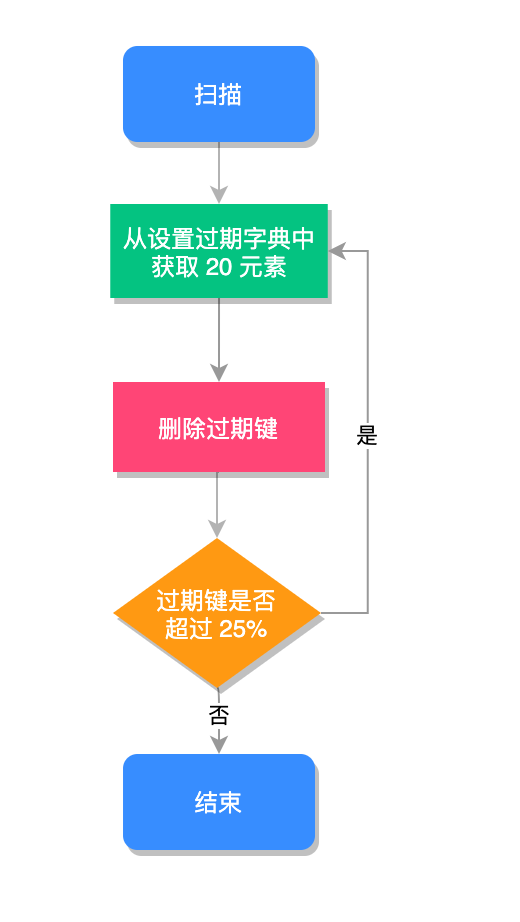
在 Redis 中,对于过期 key 是通过以下两种方式来删除的:
惰性删除
客户端在访问时,会检查对应的 key 是否过期。如果过期,才删除。
需要注意的是,如果过期 key 的访问频率很低,那么它们可能会一直存储在 Redis 中,占用内存资源。
定期删除
Redis 默认每隔 100ms (执行的频率由 hz 决定,默认为 10)检查一次过期 key,并删除部分过期 key。
-- -- --
https://blog.csdn.net/lxw1844912514/article/details/128928482
https://blog.51cto.com/u_16099215/6674132
https://cloud.tencent.com/developer/article/1763530
https://blog.csdn.net/SnailMann/article/details/118528644
https://www.cnblogs.com/wzh2010/p/17205436.html
https://www.cnblogs.com/wzh2010/p/17205492.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix