
稳定性治理
认识 :
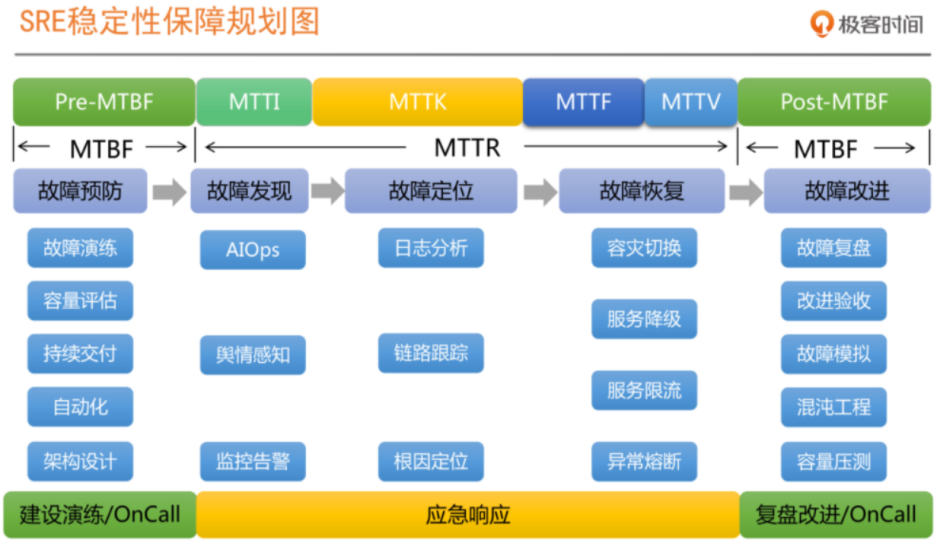
比如Pre-MTBF时,我们可以做好架构设计提供限流、降级、熔断等Design-for-Failure的服务治理手段,提供快速隔离的条件
而Post-MTBF时,我们需要做好故障复盘,总结不足以及进行改进措施落地。

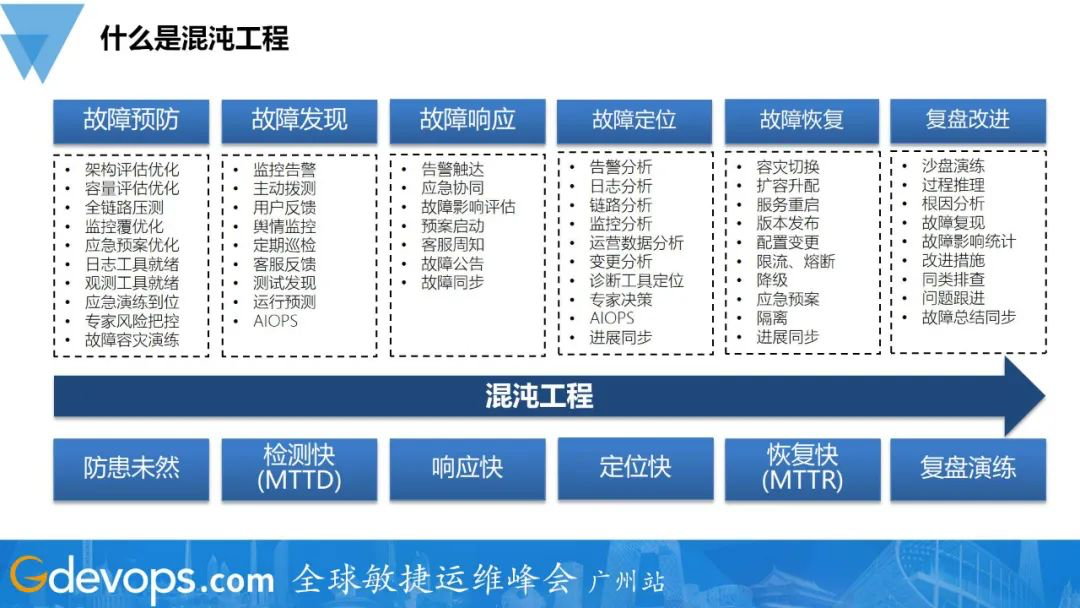
-
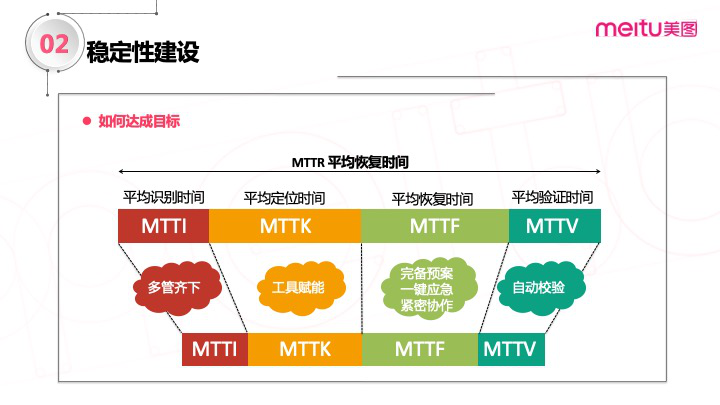
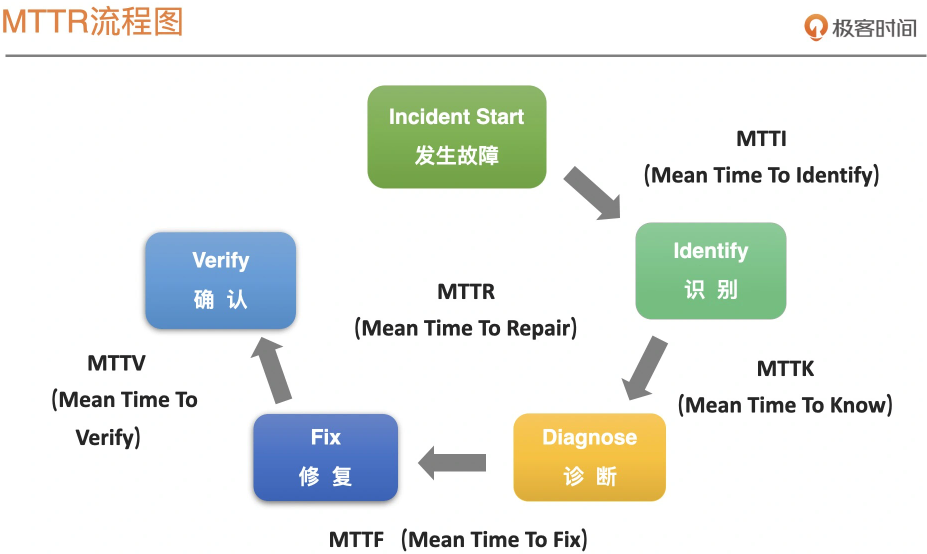
MTTI阶段:多管齐下;尽可能用更多的手段来覆盖可以发现、暴露问题的通道,包括完善监控的覆盖,建设体系化的监控系统。
-
MTTK阶段:工具赋能;这个过程中需要更多的借助工具、平台的能力,建设健全运维系统,比如监控平台、日志平台、链路跟踪平台等,如果能力允许也可以去尝试建设“根因自动定位”系统。
-
MTTF阶段:完备预案、一键应急、紧密协作;这个是在故障处理过程中最核心的部分,是真正可以让服务恢复正常的阶段;这个过程有比较多的前置依赖,也就是需要我们在平时做好储备的,比如建立健全预案体系,将预案的执行手段尽可能沉淀到工具平台中,尽可能做到一键直达,缩短预案执行的路径。其次这个过程中可能还会涉及到部门内部、部门之间的协作,尤其是在处理重大故障的场景;这时候就需要有一套可以让大家紧密协作的流程或共识,让大家可以信息互通、各司其职、有条不紊。
-
MTTV阶段:自动校验;这个过程也是需要尽可能依赖自动化的手段去做。
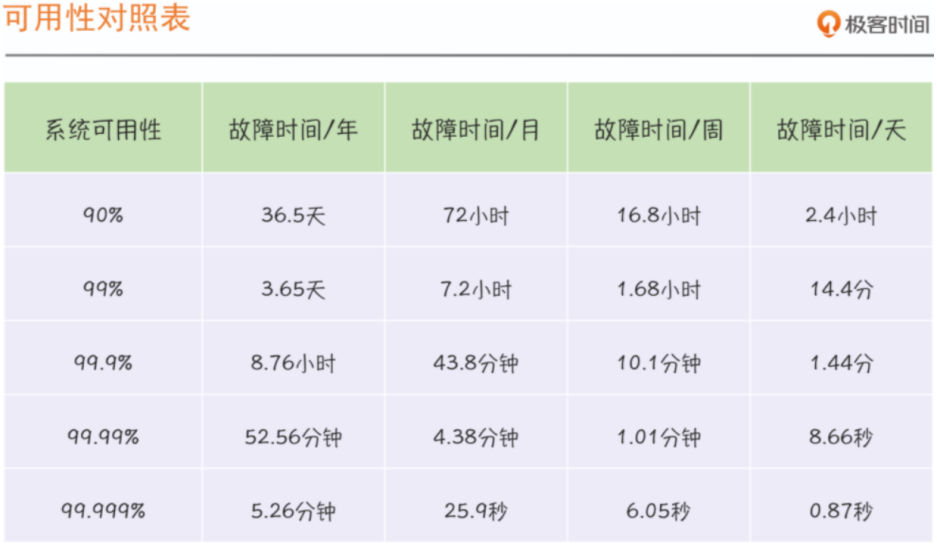
衡量可用性2种方式
一个是时间维度,一个是请求维度,计算公式如下:
时间维度:Availability=Uptime/(Uptime+Downtime):从故障角度出发对系统稳定性进行评估;
请求维度:Availability=Successful request/Total request:从成功请求占比角度出发,对系统稳定性进行评估;
切入 :
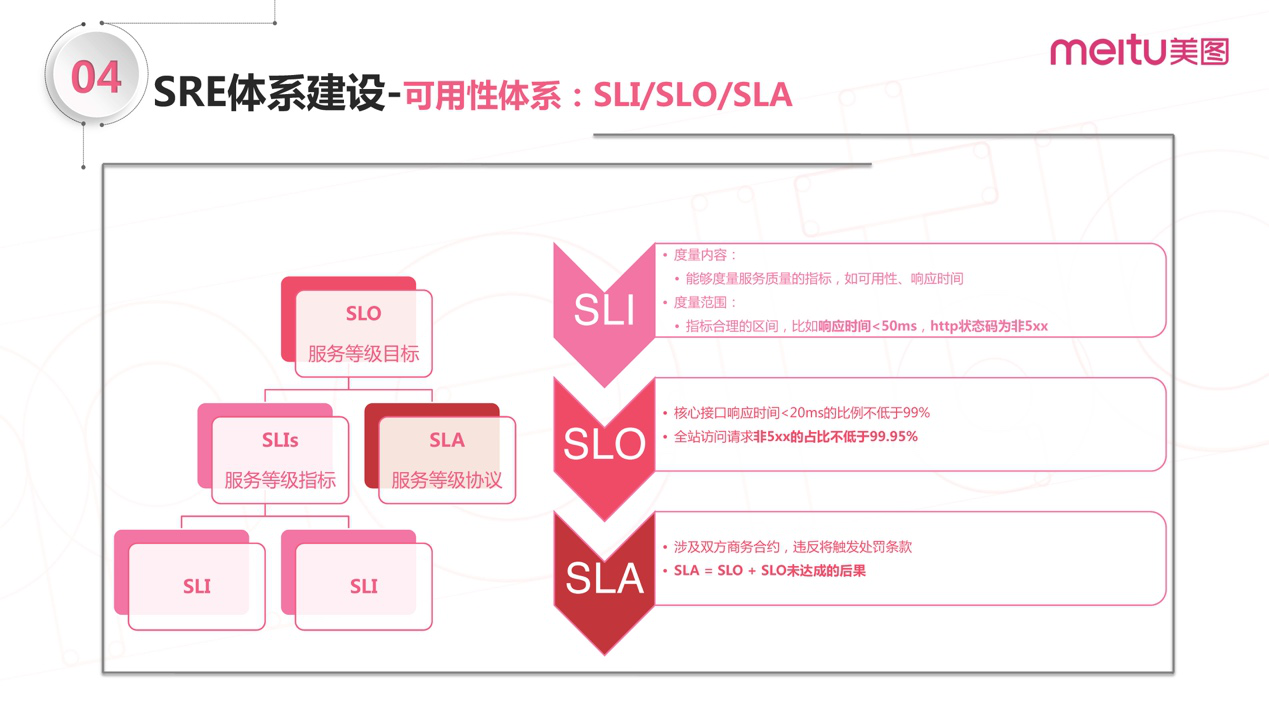
SLI : Service Level Indicator
服务等级指标,其实就是我们选择哪些指标来衡量我们的稳定性
SLO :Service Level Objective,
服务等级目标,指的就是我们设定的稳定性目标,比如“几个 9”这样的目标
SLO 就是对应 SLI 要实现的目标

所以SLI更能表达出“目标对象稳不稳定”。
- 能标识目标对象是否稳定
- 与用户体验强相关或用户可以明显感知的
VALET选择法
| 类别 | 解释 |
|---|---|
| Volume(容量) | 服务承诺的最大容量是多少。比如QPS、TPS、会话数、吞吐能力以及连接数等等 |
| Availablity(可用性) | 代表服务是否正常,比如请求调用的非5xx状态成功率、任务执行成功情况 |
| Latency(时延) | 响应是否足够快,比如时延,但时延的分布符合正态分布,需指定不同的置信区间,有针对性解决。 |
| Error(错误率) | 有多少错误率,比如5xx、4xx,也可以自定义状态码 |
| Ticket(人工介入) | 是否需要人工介入,比如任务失败需人工介入恢 |
SLO : SLI + 目标 + 时间维度就能更精确的表达稳定性现状 ,e.g. 1个小时内 90% 时延 <= 80ms
Availability = SLO1 & SLO2 & SLO3
错误预算
落地 :
参考
https://time.geekbang.org/column/intro/100048201 极客时间
https://www.cnblogs.com/imyalost/p/15894494.html
https://segmentfault.com/a/1190000022629410
https://cloud.google.com/architecture/defining-SLOs?hl=zh-cn#terminology

 浙公网安备 33010602011771号
浙公网安备 33010602011771号