

CQRS模式介绍
CQRS(Command Query Responsibility Segration)架构
本质上,CQRS也是一种读写分离的机制
2种实现方式:
- CQ两端数据库共享,CQ两端只是在上层代码上分离;这种做法,带来的好处是可以让我们的代码读写分离,更好维护,且没有CQ两端的数据一致性问题,因为是共享一个数据库的。我个人认为,这种架构很实用,既兼顾了数据的强一致性,又能让代码好维护。
- CQ两端数据库和上层代码都分离,然后Q的数据由C端同步过来,一般是通过Domain Event进行同步。同步方式有两种,同步或异步,如果需要CQ两端的强一致性,则需要用同步;如果能接受CQ两端数据的最终一致性,则可以使用异步。采用这种方式的架构,个人觉得,C端应该采用Event Sourcing(简称ES)模式才有意义,否则就是自己给自己找麻烦。因为这样做你会发现会出现冗余数据,同样的数据,在C端的db中有,而在Q端的db中也有。和上面第一种做法相比,我想不到什么好处。而采用ES,则所有C端的最新数据全部用Domain Event表达即可;而要查询显示用的数据,则从Q端的ReadDB(关系型数据库)查询即可。
架构图
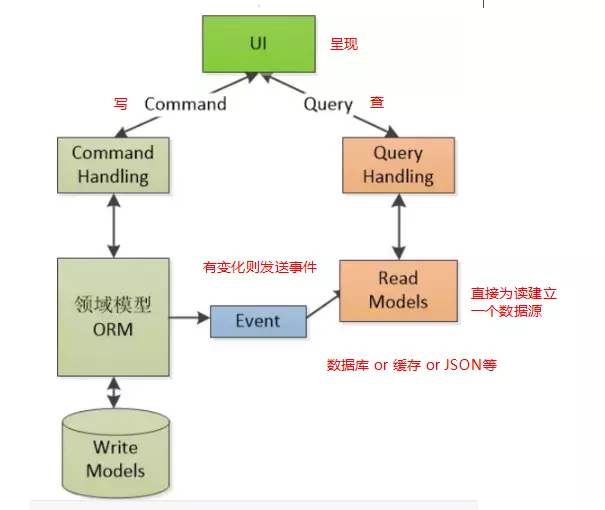
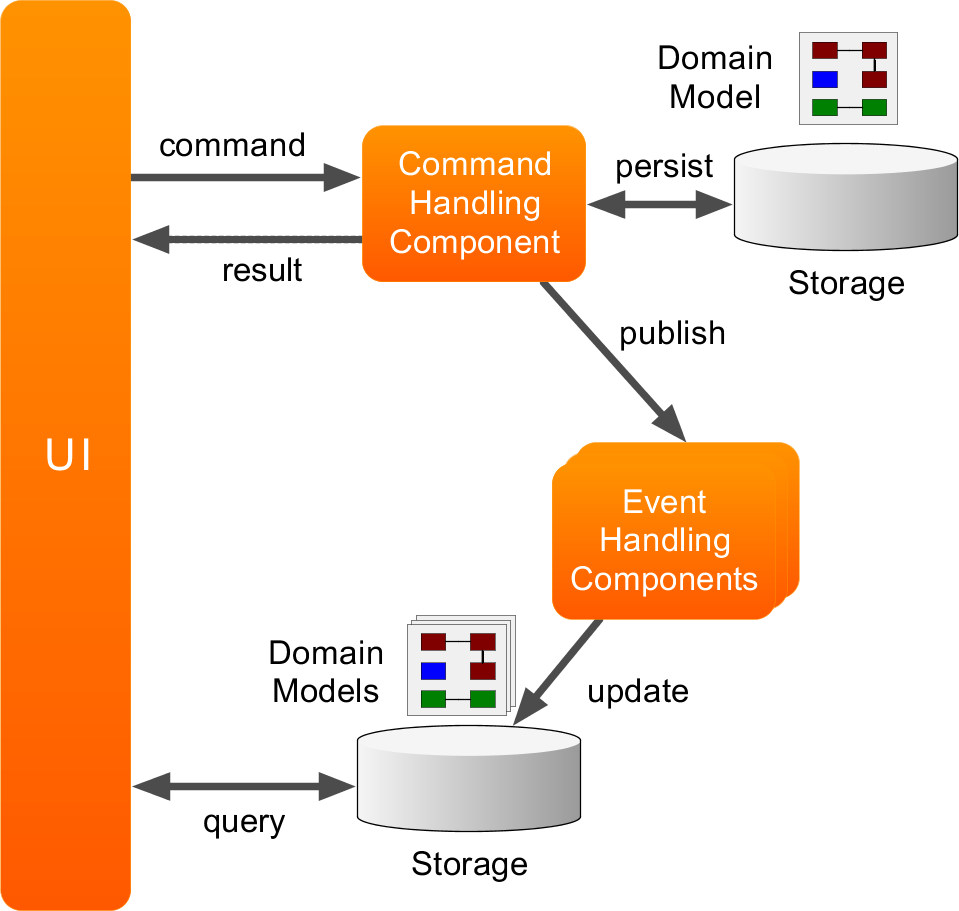
关于DDD的一些话:
我们将架构设计活动精简为以下三个层面:
-
业务架构——根据业务需求设计业务模块及其关系
-
系统架构——设计系统和子系统的模块
-
技术架构——决定采用的技术及框架
以上三种活动在实际开发中是有先后顺序的,但不一定孰先孰后。
跳过业务架构设计出来的架构关注点不在业务响应上,可能就是个大泥球,在面临需求迭代或响应市场变化时就很痛苦。
设计领域模型的一般步骤如下:
-
根据需求划分出初步的领域和限界上下文,以及上下文之间的关系;
-
进一步分析每个上下文内部,识别出哪些是实体,哪些是值对象;
-
对实体、值对象进行关联和聚合,划分出聚合的范畴和聚合根;
-
为聚合根设计仓储,并思考实体或值对象的创建方式;
-
在工程中实践领域模型,并在实践中检验模型的合理性,倒推模型中不足的地方并重构。
ref
https://www.cnblogs.com/yangecnu/p/Introduction-CQRS.html
https://www.cnblogs.com/shijingxiang/articles/5465495.html
https://www.jianshu.com/p/1b82a1f6a586
https://zhuanlan.zhihu.com/p/38968012
http://edisonxu.com/2017/03/23/hello-cqrs.html
https://www.future-processing.pl/blog/cqrs-simple-architecture/

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步