

编程范式总结
笔记:
第一部分:泛型编程,
讨论了从 C 到 C++ 的泛型编程方法,并系统地总结了编程语言中的类型系统和泛型编程的本质。
我们可以看到,无论是传统世界,还是编程世界,我们都在干一件事情,什么事呢?那就是通过使用一种更为通用的方式,用另外的话说就是抽象和隔离,让复杂的“世界”变得简单一些。
然而,要做到抽象,对于 C 语言这样的类型语言来说,首当其冲的就是抽象类型,这就是所谓的——泛型编程。
程序 = 算法 + 数据
理想情况下,算法应是和数据结构以及类型无关的,各种特殊的数据类型理应做好自己分内的工作。算法只关心一个标准的实现。
类型系统
类型带来的问题就是我们作用于不同类型的代码,虽然长得非常相似,但是由于类型的问题需要根据不同版本写出不同的算法,如果要做到泛型,就需要涉及比较底层的玩法。
我们需要清楚地知道,无论哪种程序语言,都逃避免不了一个特定的类型系统。哪怕是可随意改变变量类型的动态类型的语言,我们在读代码的过程中也需要脑补某个变量在运行时的类型。
所以,每个语言都需要一个类型检查系统。
-
静态类型检查是在编译器进行语义分析时进行的。如果一个语言强制实行类型规则(即通常只允许以不丢失信息为前提的自动类型转换),那么称此处理为强类型,反之称为弱类型。
-
动态类型检查系统更多的是在运行时期做动态类型标记和相关检查。所以,动态类型的语言必然要给出一堆诸如:
is_array(),is_int(),is_string()或是typeof()这样的运行时类型检查函数。
范型的本质
我理解其本质就是 —— 屏蔽掉数据和操作数据的细节,让算法更为通用,让编程者更多地关注算法的结构,而不是在算法中处理不同的数据类型。

第二部分:函数式编程,
讲述了函数式编程用到的技术,及其思维方式,并通过 Python 和 Go 修饰器的例子,展示了函数式编程下的代码扩展能力,以及函数的相互和随意拼装带来的好处。
函数式编程有以下特点。
特征
- stateless:函数不维护任何状态。函数式编程的核心精神是 stateless,简而言之就是它不能存在状态,你给我数据我处理完扔出来,里面的数据是不变的。
- immutable:输入数据是不能动的,动了输入数据就有危险,所以要返回新的数据集。
优势
- 没有状态就没有伤害。
- 并行执行无伤害。
- Copy-Paste 重构代码无伤害。
- 函数的执行没有顺序上的问题。
因为没有状态,所以代码在并行上根本不需要锁(不需要对状态修改的锁),所以可以拼命地并发,反而可以让性能很不错。比如:Erlang 就是其中的代表。
下面是函数式编程用到的一些技术。
-
first class function(头等函数) :这个技术可以让你的函数就像变量一样来使用。也就是说,你的函数可以像变量一样被创建、修改,并当成变量一样传递、返回,或是在函数中嵌套函数。
-
tail recursion optimization(尾递归优化) : 我们知道递归的害处,那就是如果递归很深的话,stack 受不了,并会导致性能大幅度下降。因此,我们使用尾递归优化技术——每次递归时都会重用 stack,这样能够提升性能。当然,这需要语言或编译器的支持。Python 就不支持。
-
map & reduce :这个技术不用多说了,函数式编程最常见的技术就是对一个集合做 Map 和 Reduce 操作。这比起过程式的语言来说,在代码上要更容易阅读。(传统过程式的语言需要使用 for/while 循环,然后在各种变量中把数据倒过来倒过去的)这个很像 C++ STL 中 foreach、find_if、count_if 等函数的玩法。
-
pipeline(管道):这个技术的意思是,将函数实例成一个一个的 action,然后将一组 action 放到一个数组或是列表中,再把数据传给这个 action list,数据就像一个 pipeline 一样顺序地被各个函数所操作,最终得到我们想要的结果。
-
recursing(递归) :递归最大的好处就简化代码,它可以把一个复杂的问题用很简单的代码描述出来。注意:递归的精髓是描述问题,而这正是函数式编程的精髓。
-
currying(柯里化) :将一个函数的多个参数分解成多个函数, 然后将函数多层封装起来,每层函数都返回一个函数去接收下一个参数,这可以简化函数的多个参数。在 C++ 中,这很像 STL 中的 bind1st 或是 bind2nd。
-
higher order function(高阶函数):所谓高阶函数就是函数当参数,把传入的函数做一个封装,然后返回这个封装函数。现象上就是函数传进传出,就像面向对象对象满天飞一样。这个技术用来做 Decorator 很不错。
函数式编程关注的是:describe what to do, rather than how to do it。于是,我们把以前的过程式编程范式叫做 Imperative Programming – 指令式编程,而把函数式编程范式叫做 Declarative Programming – 声明式编程。
函数式语言有三套件,Map、Reduce 和 Filter
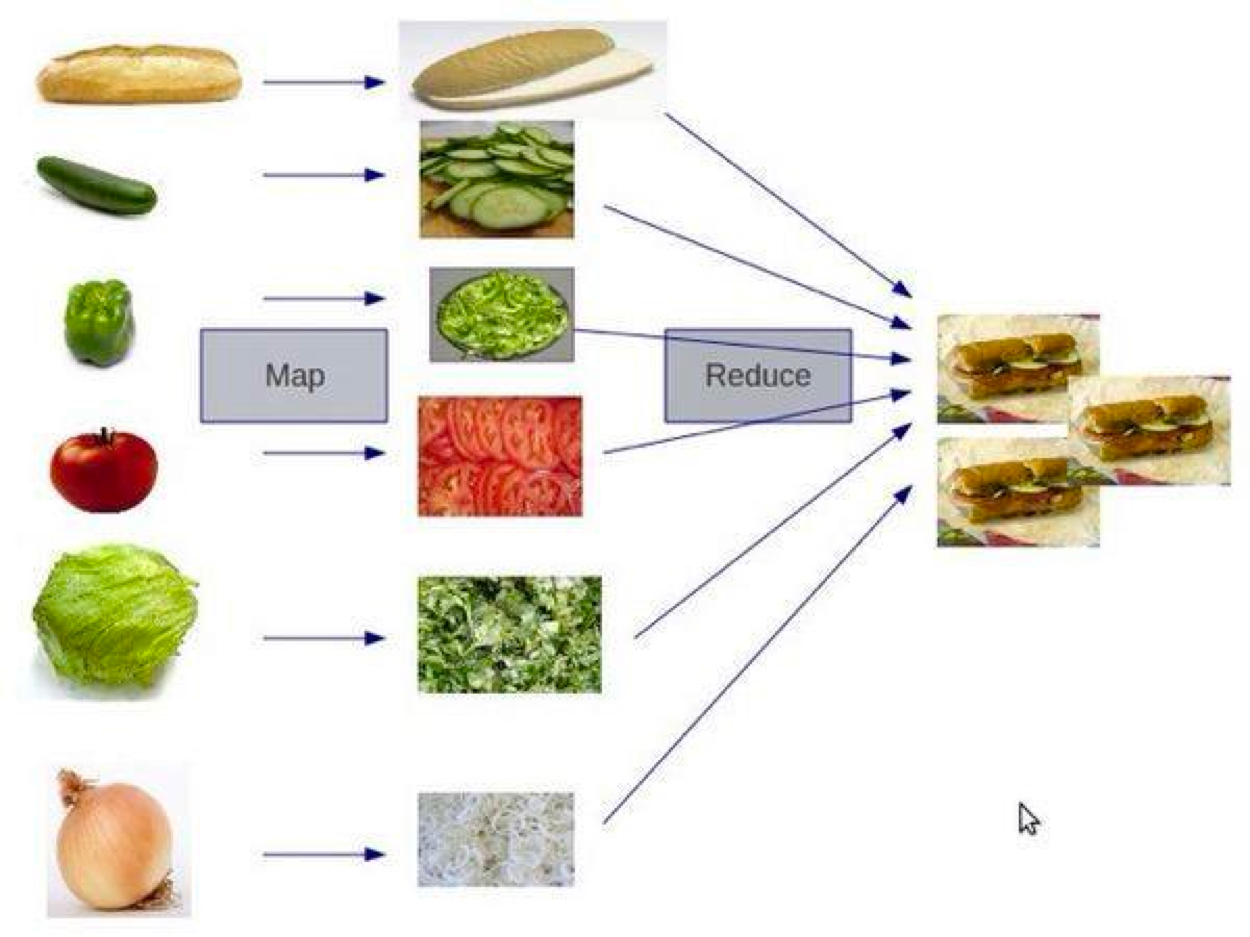
第三部分:面向对象编程,
讲述与传统的编程思想相反,面向对象设计中的每一个对象都应该能够接受数据、处理数据并将数据传达给其它对象,列举了面向对象编程的优缺点,基于原型的编程范式,以及 Go 语言的委托模式。
两个面向对象的核心理念。
- "Program to an ‘interface’, not an ‘implementation’."
- 使用者不需要知道数据类型、结构、算法的细节。
- 使用者不需要知道实现细节,只需要知道提供的接口。
- 利于抽象、封装、动态绑定、多态。
- 符合面向对象的特质和理念。
- "Favor ‘object composition’ over ‘class inheritance’."
- 继承需要给子类暴露一些父类的设计和实现细节。
- 父类实现的改变会造成子类也需要改变。
- 我们以为继承主要是为了代码重用,但实际上在子类中需要重新实现很多父类的方法。
- 继承更多的应该是为了多态。
第四部分:编程本质和逻辑编程
- Programs = Algorithms + Data Structures
- Algorithm = Logic + Control
Program = Logic + Control + Data Structure
-
Control 是可以标准化的。比如:遍历数据、查找数据、多线程、并发、异步等,都是可以标准化的。
-
因为 Control 需要处理数据,所以标准化 Control,需要标准化 Data Structure,我们可以通过泛型编程来解决这个事。
-
而 Control 还要处理用户的业务逻辑,即 Logic。所以,我们可以通过标准化接口 / 协议来实现,我们的 Control 模式可以适配于任何的 Logic。
上述三点,就是编程范式的本质。
有效地分离 Logic、Control 和 Data 是写出好程序的关键所在!
先探讨了编程的本质:逻辑部分才是真正有意义的,控制部分只能影响逻辑部分的效率,然后结合 Prolog 语言介绍了逻辑编程范式,最后对程序世界里的编程范式进行了总结,对比了它们之间的不同。
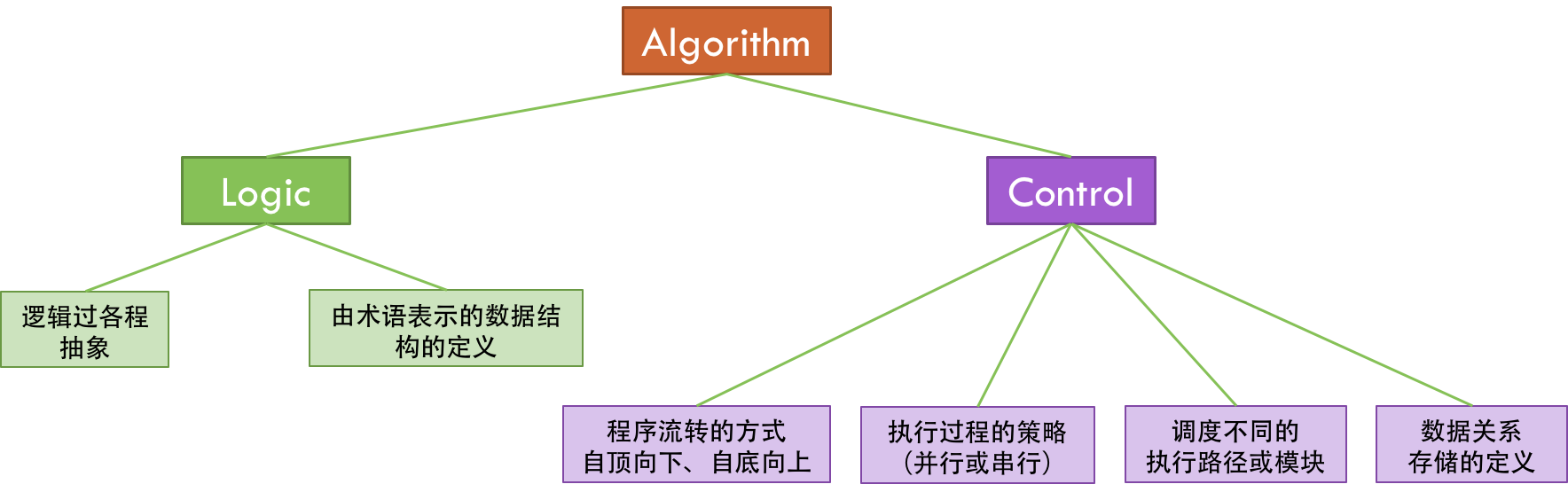
- Logic 部分才是真正有意义的(What)
- Control 部分只是影响 Logic 部分的效率(How)
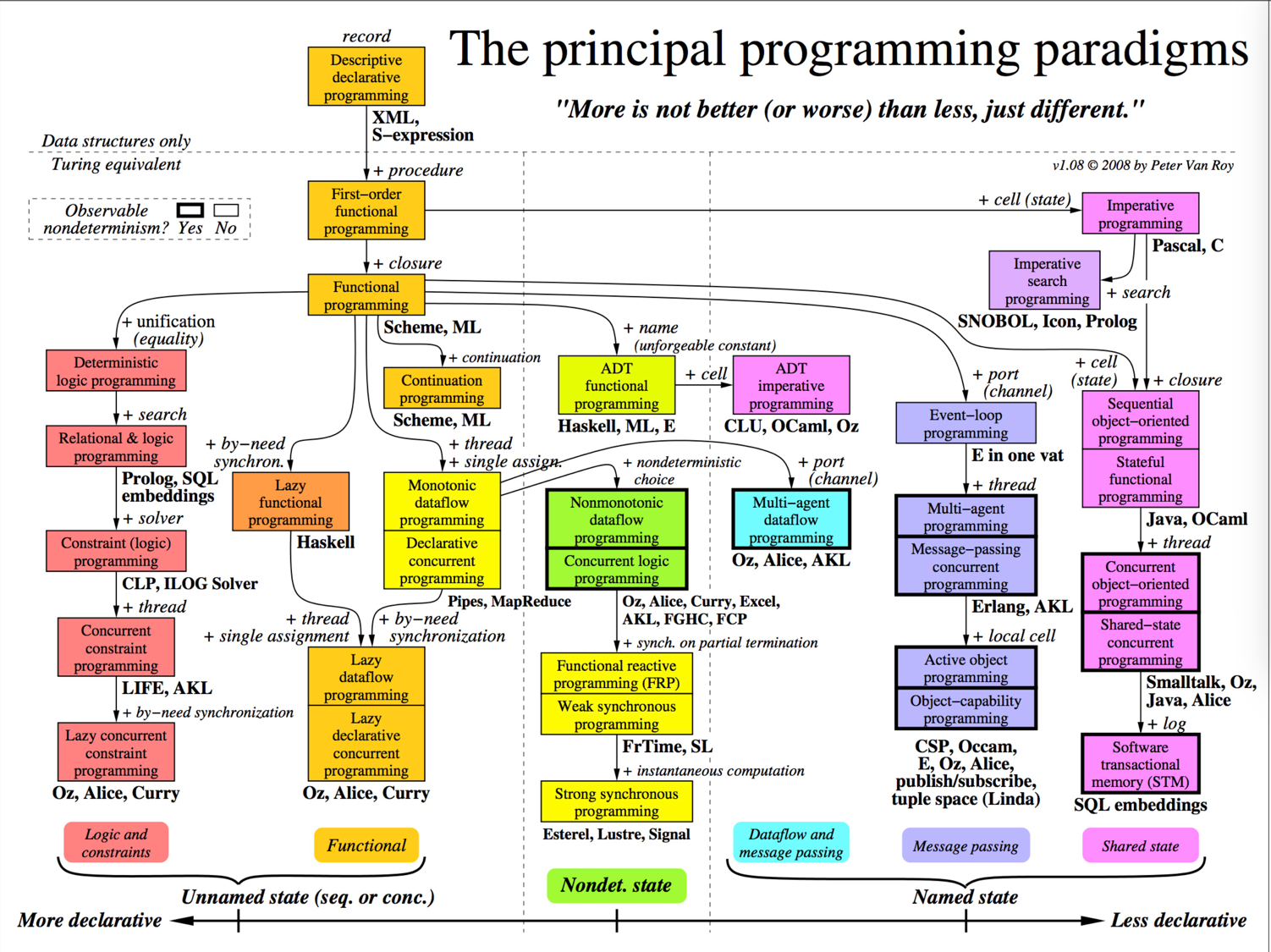
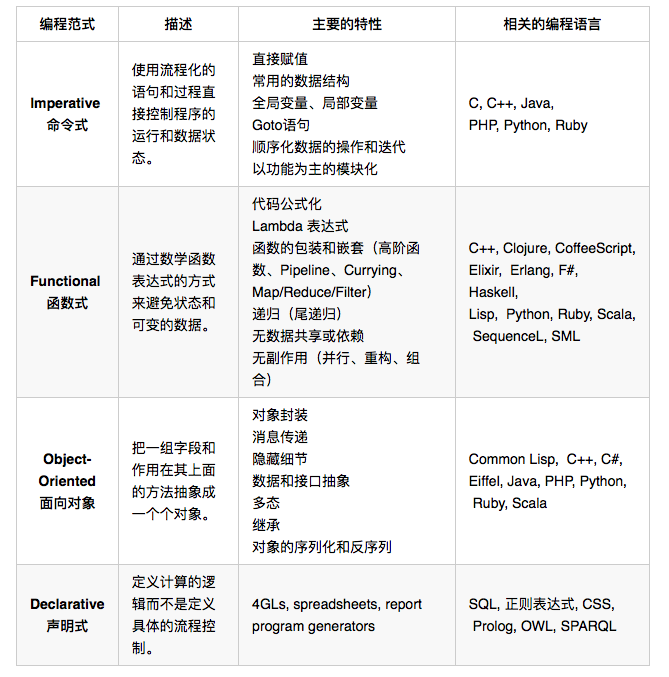
程序世界里的编程范式:

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步