系统高可用需要考虑哪些方面
一、背景:
在大部分系统中,特别是面向C端的应用,都会遇到一个问题,就是如保证系统的高可用,总不能经常挂,那用户肯定不愿意用了,在这个过程,就需要考虑很多方面。
PS:这里假设系统架构及部署是合理的。
二、限流:
限流通常是第一步,假如系统能够承载的并发是1k,但是突然打过来的流量有3k,不做限流的话,系统肯定直接打挂了。
那么,就需要通过压测知道系统的并发负载能力。
1、压测:
在公司内部,通常由测试人员使用压测平台或工具(或者使用类似jmeter这样的压测工具)进行压测,测试会写一些测试脚本。
大促之前的压测通常由测试、研发、运维、DBA、中间件组等共同支持,对核心接口同时进行压测,观察CPU、线程等机器运行情况,以及数据库和中间件的情况。
在保证各方面参数正常的情况下,最终得到并发负载的阈值。
举个栗子:

我们主要关注TPS、TP99、错误率这些核心参数。
互联网业务的接口,TP99通常在200ms以内较好。
2、压测最主要解决的问题:
很明显,能通过扩容机器解决的问题几乎都不是问题,加机器谁不会呢。
压测最主要目的是找到扩容机器无法解决的问题,例如数据库连接不足。
3、压测之后:
压测之后,需要根据这些参数进行分析,错误率太高什么原因,并发太低又是因为什么?
我们发现这个接口的并发很低,怎么查看原因呢,可以通过skywalking查看整个调用链路,到底是哪个环节比较慢。
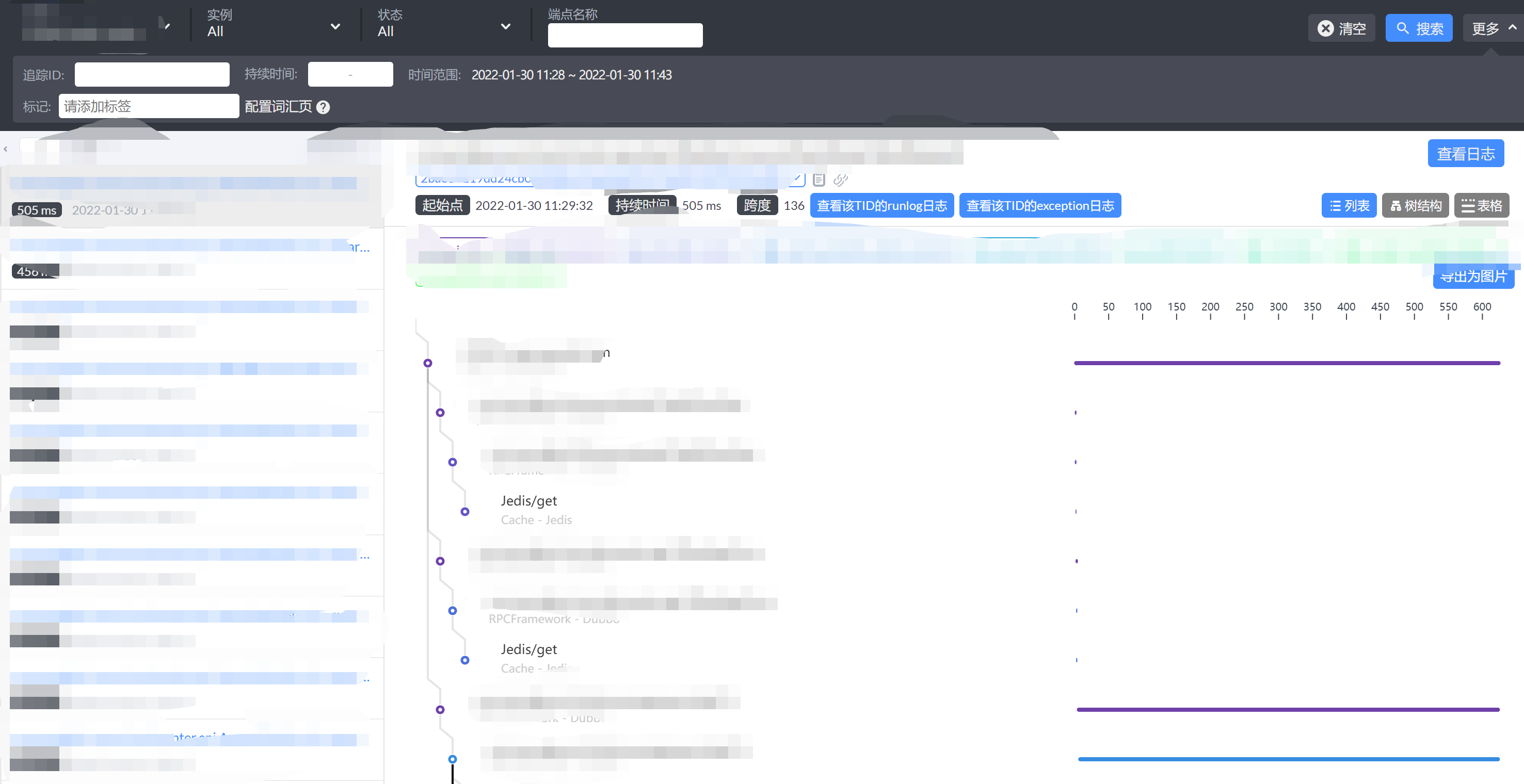
从整个追踪链路可以查看哪个环节最耗时,是否可以优化,怎么优化。
4、如何限流:
通常公司会有自己的服务治理平台,无论是自研还是三方开源(如:阿里Sentinel),也可以在网关层做限流。
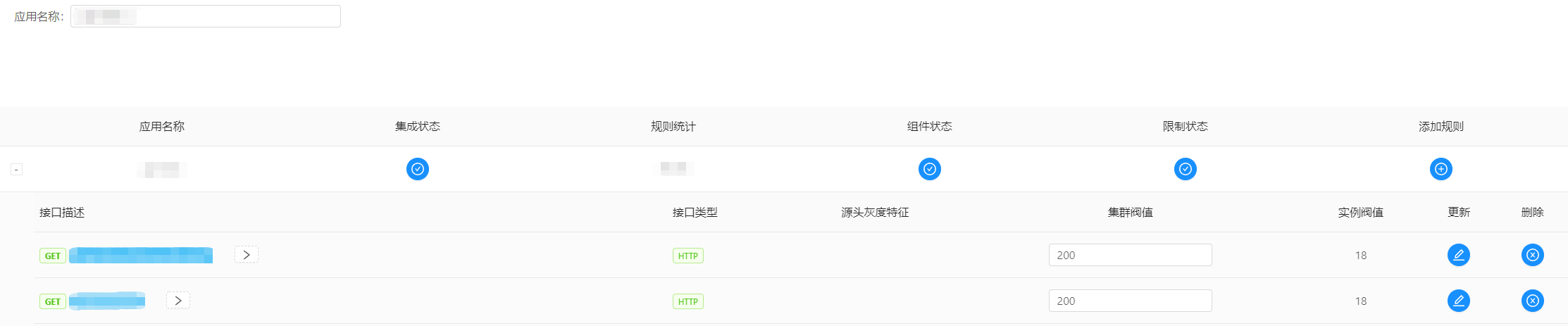
上图是我司的限流配置,给sentinel套了个壳子,支持集群限流。
三、熔断:
通常就是后端的依赖出了问题,如依赖的服务、MySQL或者Redis很慢甚至挂了等类似的场景,这时候整个接口响应就很慢。
在一定时间内错误达到阈值,这时候开启熔断,对应时间窗口直接拒绝请求,之后再尝试处理请求。
1、为什么需要熔断:
RPC接口调用肯定会设置timeout时间,正常情况下,很少有超时的,用来保证接口响应,不可能一直阻塞等待。
如果没有熔断,可能会出现大量线程阻塞等待,最终把服务拖垮。
亦或者是被依赖的服务,这时候负载比较大,开启熔断,说不定就缓过来了。
2、使用场景:
出于安全和性能考虑,并发高的接口都可以设置熔断。
3、实现:
通过类似Hystrix的三方工具就可以实现熔断。(Resilience4j)
四、降级:
降级是在熔断的后面,如果熔断器开启,就谈不上主动降级。
降级主要分为两种大方向:
1、系统向外提供服务,肯定区分核心接口(功能)和非核心接口,当我们服务器负载过大,超过预设的阈值,可以通过在网关层设置开关将非核心接口暂停提供服务,从而尽量保证核心接口一定可用。
2、例如一个查询接口,本来要查询MySQL的,但是MySQL挂了,触发降级,从本地缓存中读取少量数据或历史数据,然后将结果返回。
1、实现降级:
1、在网关层开发规则开关,能够实时生效,快速处理紧急的问题。
2、如果是第二种场景,可以通过Hystrix实现。
五、资源隔离:
隔离就想轮船一样,会有很多货舱,相互隔离,即使某个货舱出了问题,也不会影响整个轮船。
解决的问题:当系统某个接口调用别的服务出现问题,请求一直阻塞在这里。如果并发高的话,会导致越来越多的线程资源被占用阻塞,最终可能就拖垮整个服务了。
通过设置资源隔离,例如这个接口设置最多占用20个线程。
1、对比:
资源隔离和熔断有一部分功能是重合的。例如依赖的服务负载很高,响应超级慢。
无论是哪一种解决方式都可以解决,亦或者两种都用上,只是哪个先生效的问题。
在调用MySQL或者Redis等中间件时候,这时候更倾向于用熔断器,例如查询MySQL一直报错,这时候开启熔断,直接返回了,减少资源浪费,等待MySQL恢复。
六、报警:
监控报警特别重要,即使前面的各种措施都做了(何况大部分系统也可能都做了),系统还是可能出问题,如果没有监控报警,可能需要用户报障或者系统炸了你才知道。
常见的监控报警大概分为几方面:应用告警、业务告警、微服务指标告警、慢SQL告警、中间件告警等。
1、应用告警:
应用报警包含了服务级别、日志告警、接口级别告警等。
告警参数及标准在对应平台设置好。

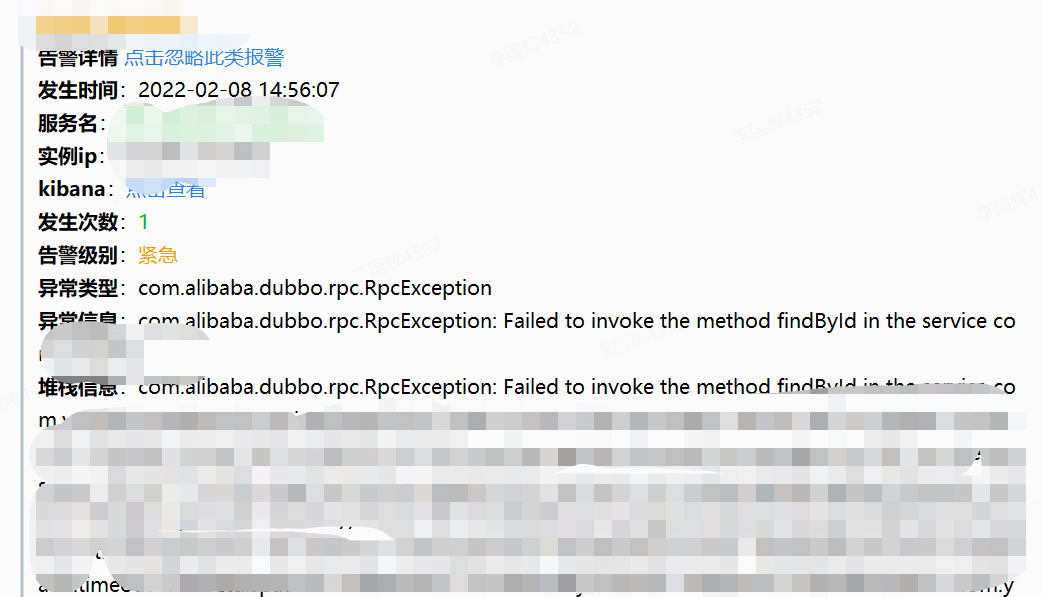
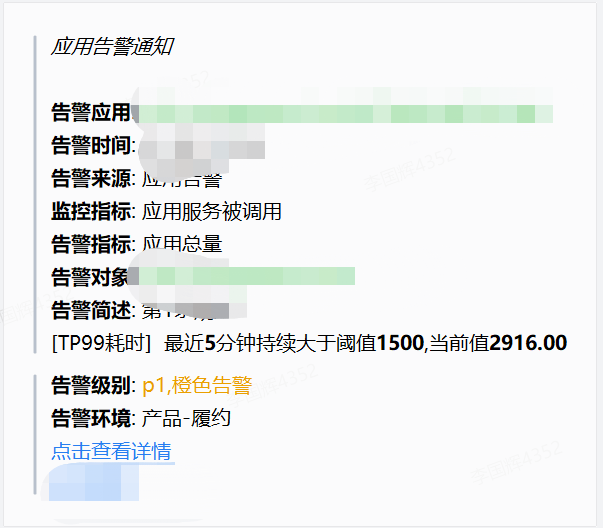
2、业务告警:
主要推送业务方面的告警信息,例如是核心接口,某些数据校验未通过这种。
3、微服务指标告警:
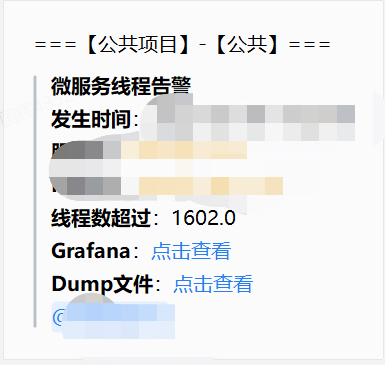
微服务级别的告警是很重要的,通常都是线程数、CPU使用率太高等类似问题,可能就需要研发人员排查解决问题的。
系统直接将机器情况、jvm(jstack、jstat)等情况打印到文件中,直接可以下载定位问题。
4、慢SQL告警:
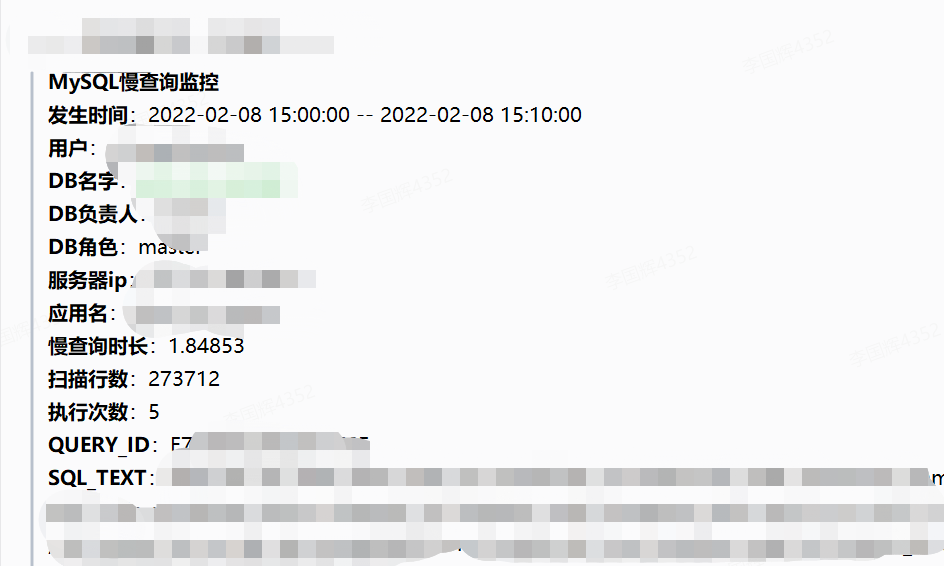
慢SQL告警的话,也是需要研发做优化,修改SQL,加索引,定时统计,大数据部门支持等处理方案。
七、监控:
1、业务数据看板:
有句话说得好,没有数据支持都是白扯,一切以数据为导向。
数据才能提现你做一个需求真正的价值。
我司通常都会将核心功能及流程做可视化数据看板展示,不仅仅为了让研发能够看到数据效果,还能及时发现是否有突发状况导致核心流程异常,特别是刚上线的时候,如果有bug,从看板上可以很快知道。
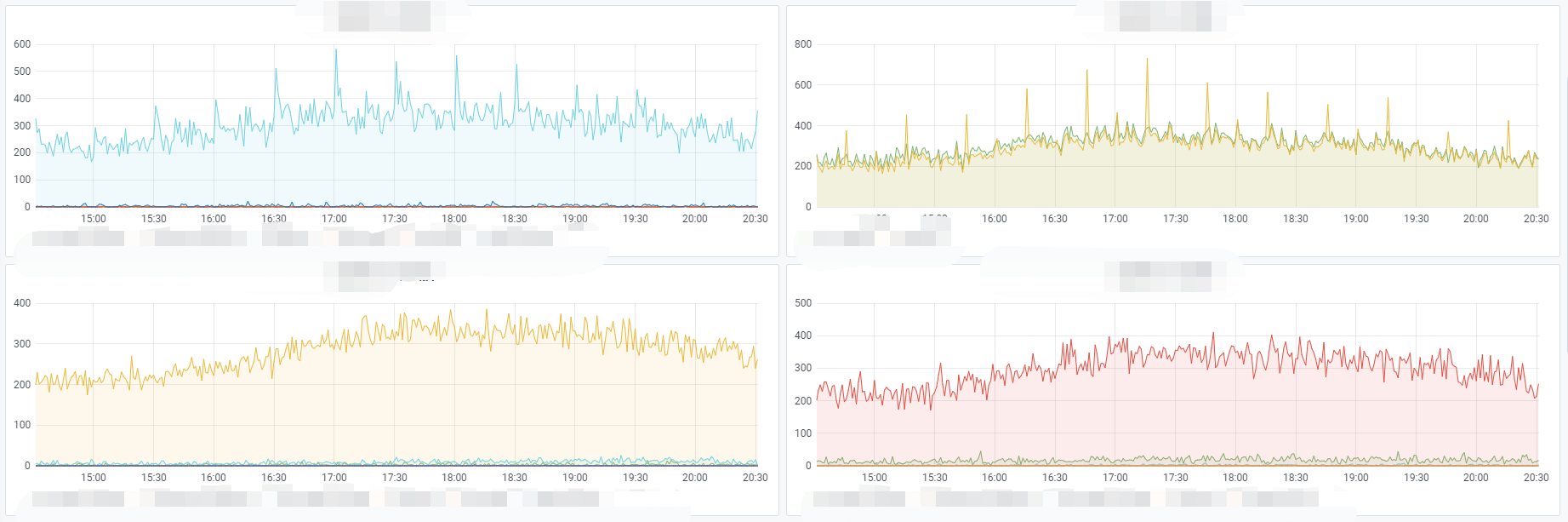
通过Grafana或者其他组件实现的数据统计及展示。
2、应用监控:
包含了提供的接口、依赖的接口、Redis、MQ等监控。

3、系统指标:
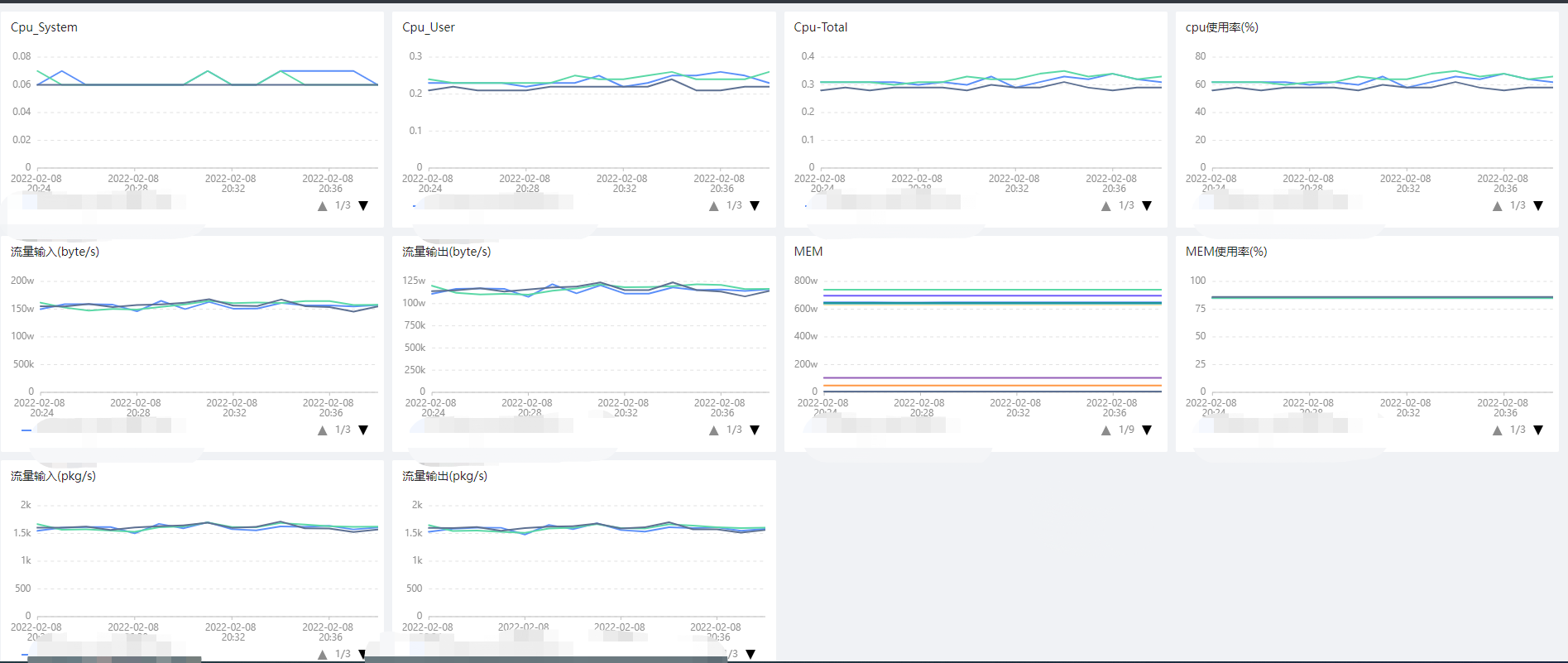
4、JVM指标:
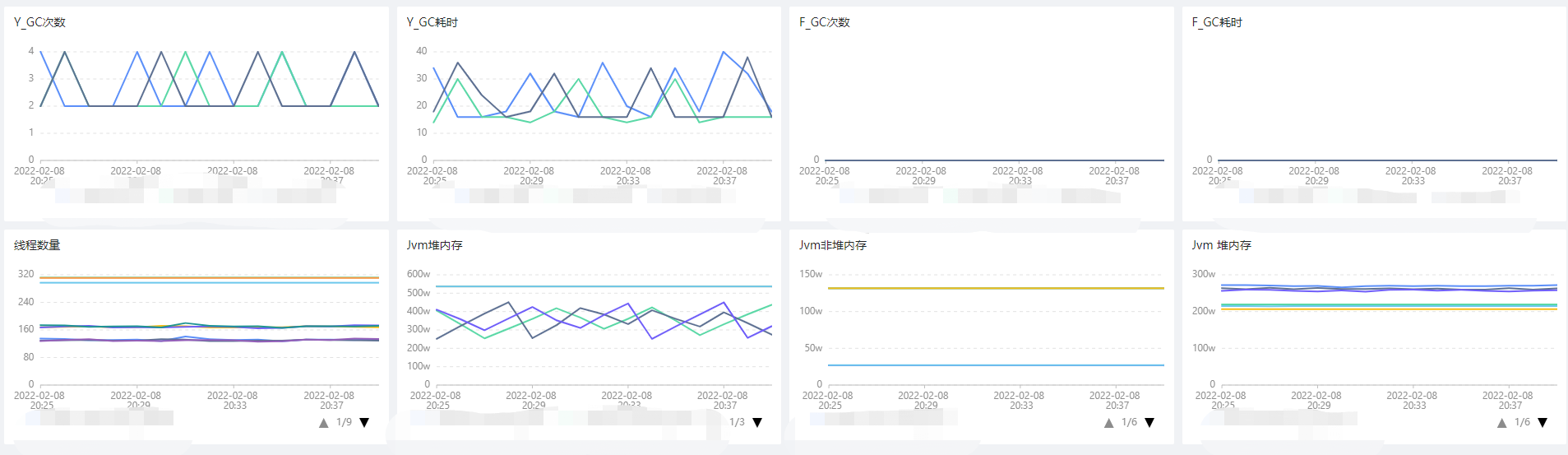
5、集成业务大盘:
前面的监控指标都比较分散,需要一个个点击加载查看,相对麻烦,可以直接将需要的指标做成一个大盘,包含机器运行、jvm、核心接口等监控。
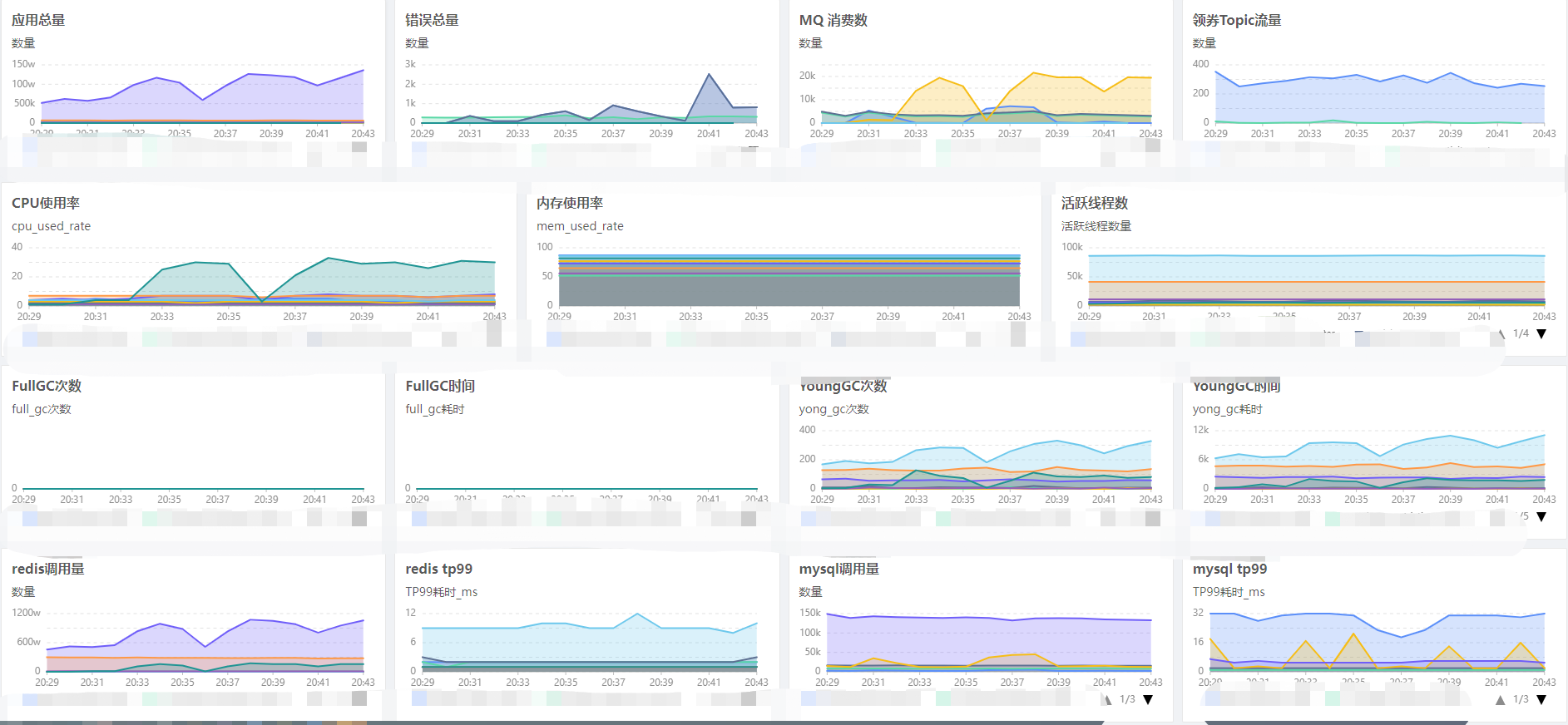
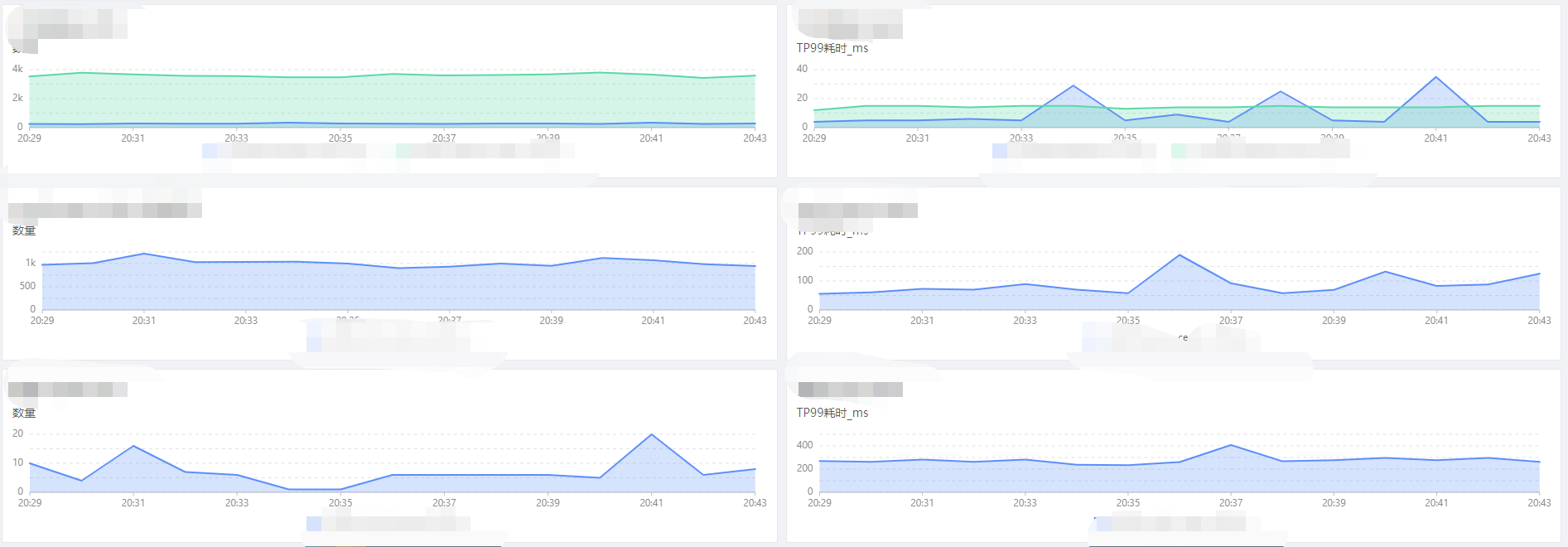
6、总结:
监控来说,主要是上面这些维度,当然也会有其他定制化的需求,总体就是这样的。
通过前面的监控 + 报警灯措施,尽可能保证系统的高可用,能够及时发现问题并且解决。

