分布式锁(一)--基础
一、背景:
如果系统就是一个单体系统,不需要考虑这些问题,最多使用synchronized相关的锁解决并发问题。
但是一个分布式系统,肯定会遇到并发竞争共享资源的问题,这时通常就需要使用分布式锁解决。
二、举个栗子:
举个老生常谈的例子,商品库存的锁定。
用户购买iPhone,肯定需要锁定/扣减对应商品的库存。
1、不使用分布式锁:
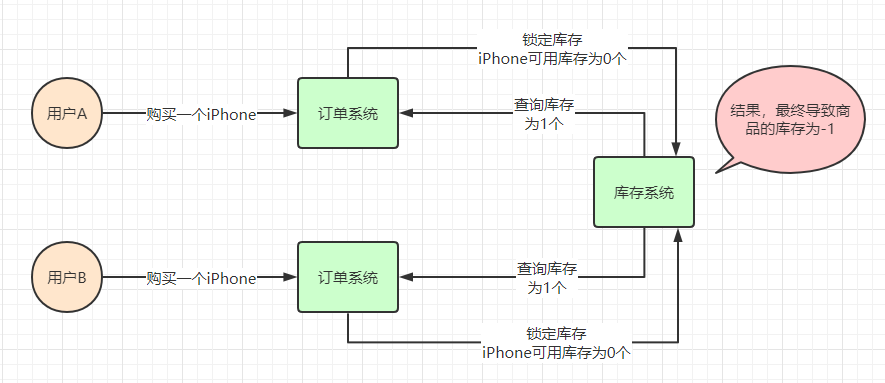
2、使用分布式锁:
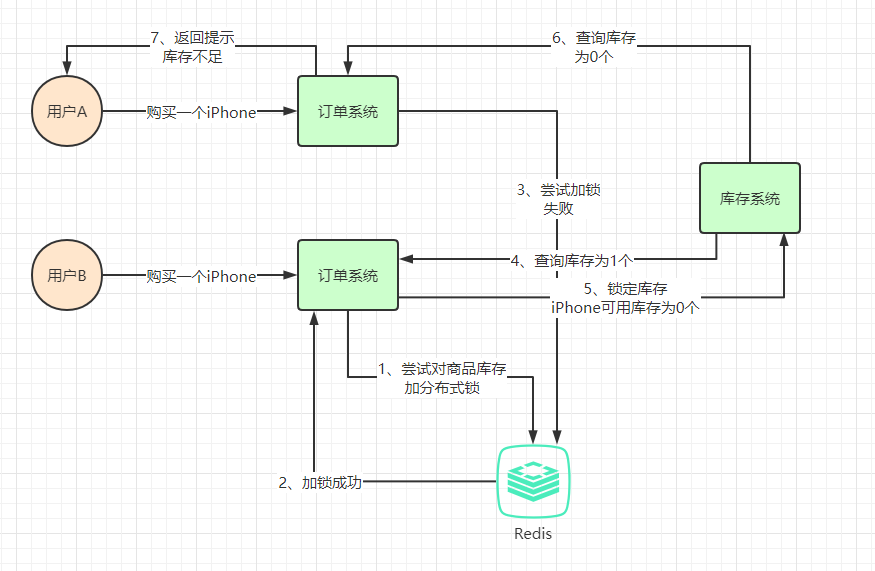
3、总结:
通过分布式锁,让多进程的多线程操作变成串行操作,能够保证并发操作公共资源正常。
当然这里只是举个栗子,单纯这个问题,也可以直接通过MySQL乐观锁解决,就不需要使用分布式锁了。
update table set stock = stock - ? where id = ? and stock > 0;
三、实现方式:
分布式锁实现方式通常基于Redis或者Zookeeper实现,当然也可以通过DB的唯一索引实现。
如果是个人或者是很小的研发团队。
Redis:推荐使用Redisson三方包来实现Redis分布式锁,本身有比较成熟的支持,解决了Redis分布式锁存在的一些缺陷。
ZK:推荐使用Curator三方包实现ZK分布式锁。
当然,一般公司内部,可以业务团队或者中间件团队对分布式锁做统一封装,方便使用。
四、Redis和ZK实现对比:
1、消耗:
Redis分布式锁:需要不断尝试获取锁,比较消耗性能。
ZK分布式锁:如果获取不到锁,可以注册一个监听器,会自动回调通知,不需要不断主动尝试获取锁。
2、实现复杂度:
Redis分布式锁:代码实现相对繁琐,需要遍历上锁,计算时间等。
ZK分布式锁:实现简单。
3、安全性:
Redis分布式锁:如果获取锁的客户端挂了,只能等待超时时间到了才能释放锁。
ZK分布式锁:因为创建的是临时ZNode,如果客户端挂了,ZNode就没了,此时就自动释放锁。
4、性能:
Redis分布式锁:Redis性能很高,所以Redis实现分布式锁的性能也很高,通常企业开发也更倾向使用Redis实现分布式锁。
ZK分布式锁:如果业务场景有一定并发,频繁创建和删除节点,对ZK压力会很大,因为ZK本身在项目中也会做其他应用的(如注册中心),所以作为分布式锁相对并发能力较弱。
5、总结:
使用ZK实现分布式锁前提,项目本身已经引入了ZK集群,不可能因为要使用分布式锁,引入ZK,那样成本也太大了。
如果本身项目性质就不会有多少并发,推荐使用ZK实现,实现简单,不会有什么漏洞,ZK本身就是做分布式协调的。
如果对性能有一定要求,且能够容忍Redis实现分布式锁在极端场景下可能存在的隐患,可以使用Redis实现。
个人认为Redis实现不太需要考虑极端场景下可能存在的问题,首先出现概率很小,然后即使出现了,直接人工补偿或者代码补偿就行了。
五、业务场景:
了解技术,但是不知道应用到哪些业务场景,都是白搭。
中心思想就是,如果这个流程不串行化执行,就会导致数据问题,那就可以考虑是不是可以通过分布式锁解决这种隐患。
1、无法通过唯一索引保证幂等性的插入:
向外提供一个dubbo接口,作用就是插入一行业务数据,幂等性是必须保证的,而主要的业务字段又没办法设置为唯一索引(如后续某个操作,导致修改这行数据的同时,又多新增一行数据),也就是无法通过数据库唯一索引进行去重来保证幂等性。
通常逻辑就是先判断是否存在,如果存在就直接返回成功。
这时候可以考虑使用分布式锁就可以保证幂等性,下面是伪代码实现。
@Override
public Integer create(TestDTO dto) {
String lockKey = this.getClass().getSimpleName() + {核心业务字段};
return redis.lock(lockKey,
() -> {
List<TestDTO > list = testMapperEx.queryByOrderId(dto.getOrderId());
if (CollectionUtils.isEmpty(list)) {
return testMapperEx.insertSelective(dataModelConverter.convert(dto));
}
return 1;
});
}
2、不需要并发调用的接口访问:
什么时候我们需要调用三方接口,三方接口可能接入什么系统会调用它们,有一定并发压力,所以他们不让同一个业务ID请求并发调用(例如:这个接口被刷了,会疯狂调用)。
亦或者也是先判断是否已经有数据,如果没有再调用。
这时候,也是通过分布式锁保证串行。
3、总结:
分布式锁主要使用的场景,都是先做各种业务数据判断,如果满足这些条件,再操作业务数据。
否则,并发的情况下,很多请求过来,可能前面的业务判断都会通过,然后操作数据,导致数据变得错乱。

