分布式事务(一)--理论基础
一、写在开始:
除了极个别系统模块,如支付、订单这种,其余都不推荐使用分布式事务框架来解决问题,会使系统复杂度增加,可能会导致更多的问题。
一般的业务系统,通常考虑消息补偿、job处理、系统监控报警、人工等解决方式,毕竟你的系统没那么多一致性问题。
就是大厂也是一样,使用分布式事务框架的系统也不多,而且大多是自研不开源的框架,如阿里的txc。
PS:本人没有生产环境实操经验,分布式事务相关内容看看就行。
真的要用了,做好调研,内部做技术方案评审,因为免不了踩坑,所以要做好保命开关,随时切换保住自己的狗命。
二、微服务、分布式、集群的区别:
这是最近看到的一个问题,感觉挺有意思,就写到这里了。
对于电商系统,会有很多业务模块,用户系统、营销系统、商品系统、支付系统、订单系统、履约系统等。
微服务:我们采用SOA(面向服务的架构)模型,把这些功能模块拆分出来,做成一个个服务,user-center,marketing-center等,这个就是微服务。
分布式:当微服务之间通过良好的接口和协议联系起来。就要考虑如何部署这些微服务了,可以部署到一个或多个服务器上。分布式指的是这些服务部署在不同的机器上。
微服务和分布式的区别:多个微服务可以选择部署在单台或多台机器,而分布式必须部署在多台机器。
集群:电商系统可以是一个单体应用/多个业务模块。可以把这个单体应用或者某个微服务部署到多个服务器上,这样多个服务器提供了相同的服务,这就是所谓的集群。
三、背景:
在单体项目中,不需要使用分布式事务,一个系统对应一个数据库,事务在本地数据库的事务就可以了。
但是微服务环境下,服务之间的调用,数据库是分开的,无法通过本地数据库事务保证了。
当然不只是数据库,可能还操作Redis、ES等,可以认为是在分布式环境下对数据的操作无法回滚。
四、分布式环境下,存在的一致性问题
1、背景:
一个微服务系统,每个服务都有自己的数据库,MySQL、Redis、MongoDB等。
2、异常分析:
A服务 --> B服务 --> C服务
假如前面的流程都成功了,最后C服务出现了异常,前面如何进行回滚。
五、柔性事务--CAP
CAP是研究分布式的一个比较经典的理论。
CAP是Consistency、Availability、Partition Tolerence的简称。
也就是一致性,可用性,分区容忍性。
1、一致性
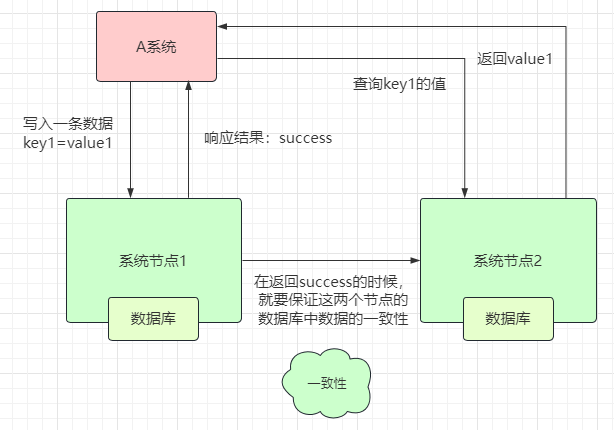
1.1、一致性分类:
1、强一致性:就是图中的那种。
2、弱一致性:节点数据如果同步了,你就能查到,没同步,就查不到,结果具有不确定性。
3、最终一致性:过一段时间,等节点之间数据同步之后,就可以查到。
2、可用性
客户端往分布式系统的各个节点发送请求,都可以获取成功的响应。
2.1、可用性级别:
99%,一年中只能有80小时左右是可以允许访问失败的
99.9%,一年中大概有8小时左右是可以访问失败
99.99%,一年中有大概不到1小时是可以访问失败的
99.999%,一年中有大概不到5分钟是可以访问失败的
99.9999%,一年中只能有大概不到1分钟可以访问失败
很多B端系统99%可用性都没到,面向C端的要求比较高,但是99.9%的可用性也是不容易,比如我司,隔几个月就要挂一次。
3、分区容忍性
3.1、分区partition/network partition
分布式系统之间的网络环境出了故障,分布式系统的各个节点之间现在已经无法进行通信了。
遇到网络分区故障,类似于脑裂,然后系统还是可以正常对外提供服务的。
3.2、不具备分区容忍性
一旦网络故障,整套系统崩溃。
4、CAP => CP or AP
一个分布式系统不可能同时兼备一致性、可用性、分区容忍性,要么是CP(一致性 + 分区容忍性),要么就是AP(可用性 + 分区容忍性)。
基于这套理论,redis、mongodb、hbase等分布式系统,都是参照着CAP理论来设计的,保证AP的肯定更多。
5、保证CP
1、现在网络发生故障,client向节点A发送一个插入请求,节点A将数据插入。
2、节点A发现节点B之间网络不通了,无法进行数据同步。
3、client向节点B查询数据,由于当前节点之间网络不通,直接给client返回:当前系统处于不一致状态,不能查询。
这样就保证了一致性,不会让client看到不一致的状态,同时不能保证Available。
6、AP
同样的场景下,要保证两个节点都要可用的,所以client如果在节点A能够查询这条数据,但是如果请求到了节点B就查不到了。
6.1、场景:
电商、12306,这种业务类系统,一般都是AP。
查询的商品或者火车票库存可能都是旧数据,但是当你买的时候,肯定就是要查询库存,不影响使用。
六、柔性事务--BASE
Basicly Available、Soft State、Eventual Consistency,也就是基本可用、软状态、最终一致性,大概是AP的补充理解。
1、基本可用:
正常情况下查询,负载均衡到各个节点去查的,多节点抗高并发,如果发生网络故障,可以选择降级。
如果流量太大了,直接出发限流,直接返回一个空,让你稍后再来查询。
2、软状态:
多个节点都是可用的,但是可能一会能查到,一会就查不到了。
3、最终一致性:
一旦故障或者延迟解决了,数据过了一段时间最终一定是可以同步到其他节点的,数据最终一定是可以处于一致性的。
七、刚性事务--XA规范:
针对分布式的事务问题,X/Open组织定义了分布式事务的模型,包含多个角色。
- AP:Application,应用程序,就是我们的系统应用。
- TM:Transaction Manager,事务管理器,专门用来管理系统夸数据库事务的组件。
- RM:Resource Manager,资源管理器,就是数据库MySQL。
- CRM:Communication Resource Manager,通信资源管理器,消息中间件,但也可以不用。
TM:根据XA定义的接口规范,跟每个数据库进行通信和交互,通知所有数据库,要么一起提交事务,要么一起回滚。
XA:定义好TM与RM之间的接口规范,就是管理分布式事务的那个组件跟各个数据库之间通信的一个接口。
只是一个规范,具体的实现由数据库产商来提供的,比如说MySQL就会提供XA规范的接口函数和类库实现,等等。
当然,分布式事务不只是数据库的问题,需要保证的是行为的一致性,例如其中一个模块的逻辑是Redis的key对应value+1,事务失败了,就要把key-1。
八、刚性事务--2PC--Two-Phase-Commitment-Protocol
X/Open组织定义了分布式事务的理论模型,2PC就是基于XA规范的协议,让分布式事务可以落地。
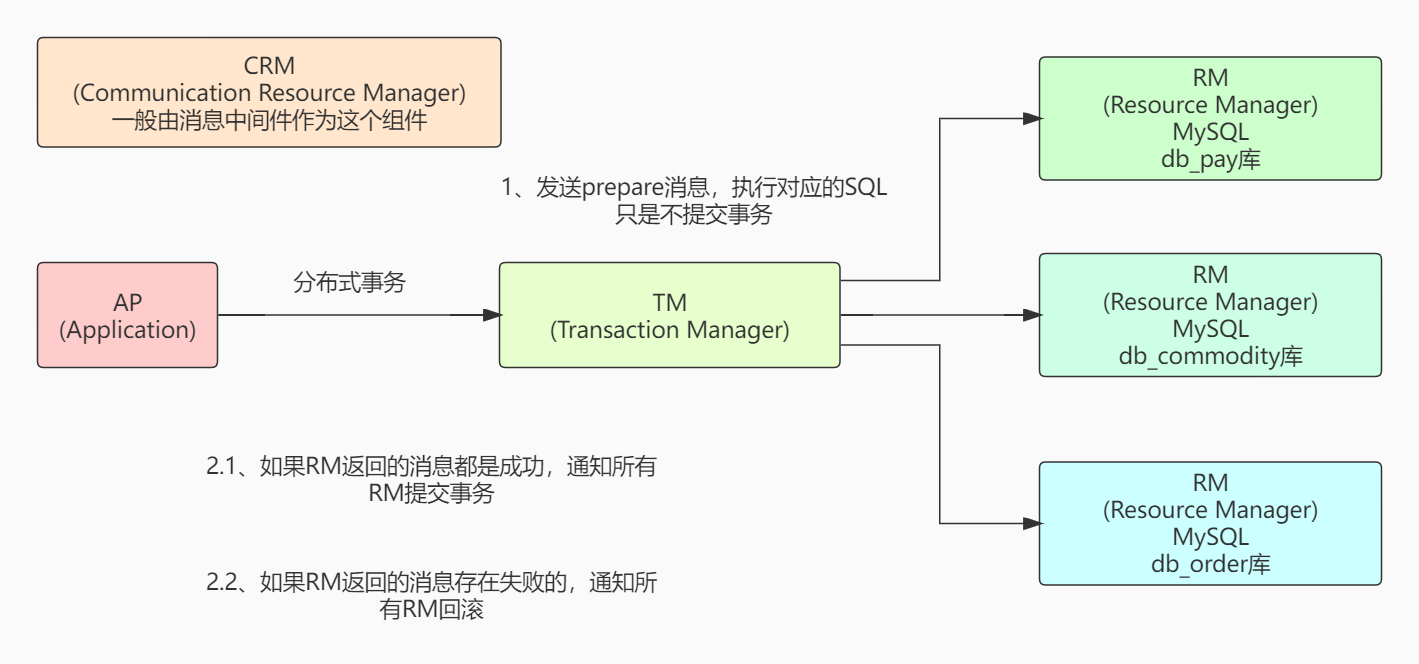
1、准备阶段:
TM先发送个prepare消息给各个数据库,让各个库先在本地开个事务,然后执行好SQL,各个数据库准备随时提交/回滚,事务操作会有对应的日志记录。
各个数据库都返回响应消息给事务管理器,如果都成功了就发送成功的消息,如果失败了就发送失败的消息。
2、提交阶段:
2.1、第一种情况:失败
- TM收到某个数据库的返回消息SQL执行失败。
- 一直无法收到某个数据库的返回消息确认,直接判定这个分布式事务失败,
然后TM通知所有的数据库全部回滚,各个库都回滚好了以后通知TM,TM认为整个分布式事务都回滚了。
2.2、第二种情况:成功
TM接收到所有的数据库返回的消息都是成功,直接发送个消息通知各个数据库说提交事务。
TM就认为整个分布式事务成功了。
3、2PC存在的问题
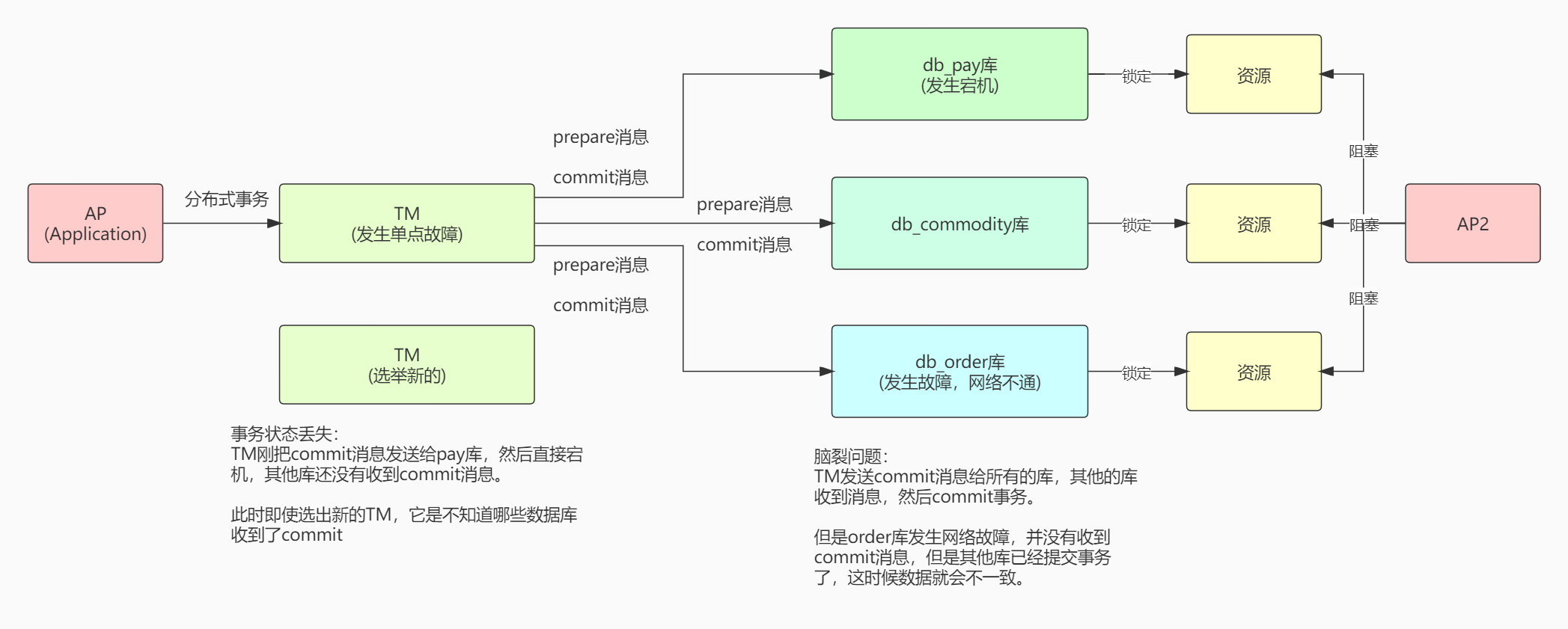
3.1、同步阻塞:
执行prepare操作会占用公共资源,因为第一阶段不会提交本地事务,直到整个分布式事务完成,才会释放资源。
3.2、单点故障:
TM是个单点,一旦挂掉就完蛋了。
3.3、事务状态丢失:
当前participant的状态只有自己和coordinator知道。
即使把TM做成一个双机热备,一个TM挂了自动选举其他的TM,唯一一个接收到commit消息的数据库也挂了。
新的TM根本不知道这个分布式事务当前的状态,哪个数据库接收到commit,哪个没接收到。
在新的TM启动之前,其他participant就会进入不能rollback和commit的阻塞状态。
3.4、脑裂问题:
如果发生了脑裂问题,就会导致某些数据库没有接收到commit消息,有些库没有收到,就会出现不一致的问题。
九、刚性事务--3PC:
1、3pc的流程如下:
1.1、CanCommit阶段:
TM发送CanCommit消息给各个数据库,然后各个库返回个结果。
此时不会执行实际的SQL语句,各个库看看自己网络环境是否正常。
1.2、PreCommit阶段:
如果各个库对CanCommit消息返回的都是成功,就进入PreCommit阶段。
TM发送PreCommit消息给各个库,相当于2PC里的阶段一,执行各个SQL语句,只是不提交;
如果有个库对CanCommit消息返回了失败,TM发送abort消息给各个库,结束这个分布式事务。
1.3、DoCommit阶段:
如果各个库对PreCommit阶段都返回了成功,那么发送DoCommit消息给各个库提交事务。
各个库如果都返回提交成功给TM,那么分布式事务成功;
如果有个库对PreCommit返回的是失败,或者超时一直没返回,那么TM认为分布式事务失败。
直接发abort消息给各个库通知回滚,各个库回滚成功之后通知TM,分布式事务回滚成功。
2、相比2PC的改进点:

2.1、引入了CanCommit阶段。
CanCommit阶段证明了每个数据库都是OK的。
2.2、在DoCommit阶段,各个库有超时机制
如果一个库收到了PreCommit还返回成功了。
超时时间到了,还没收到TM发送的DoCommit消息或者是abort消息,直接判定为TM可能出故障了,然后自己就执行DoCommit操作提交事务。
这样保证资源不会一直被锁定阻塞在这里。
3、3PC的缺陷:
TM在DoCommit阶段发送了abort消息给各个库,结果因为脑裂问题,某个库没接收到abort消息,其他的库提交了事务,还是存在事务不一致问题。
十、分布式事务选型调研:
ByteTCC,Himly,TCC-Transaction:
类似TCC事务的开源框架,由个人开发,star在3-6k,会有一些中小型公司生产环境用了类似的分布式事务框架,知名度和普及型相对低一些。
seata:
阿里开源的分布式事务框架,支持AT、TCC、Saga等事务模式,是经历过阿里生产环境考验的。支持dubbo、spring cloud两种服务框架,比较推荐seata。
基于RabbitMQ、Kafka实现可靠消息最终一致性方案。
RocketMQ:作为MQ中间件,提供了分布式事务支持,但是如果使用,性能影响较大。
十一、总结:
强一致方案:TCC、Seata等主要用于核心模块,例如交易/订单等等。
最终一致性方案:一般用于边缘模块例如库存,通过mq去通知,保证最终一致性,也可以业务解耦。
最终一致性也可以体现在后期进行数据补偿(系统、人工)。
十二、生产环境如何使用分布式事务的?
如果在事务里,有些操作特别的耗时,可以做成异步化。
同时还要将这个异步化的操作包裹到一个事务中去,此时就可以使用可靠消息最终一致性的方案。
在事务里,有些操作无关紧要,是否成功都行,而且还比较耗时,例如发送短信,发送邮件,发送一个通知等。
即使失败了是无关紧要的,可以使用最大努力通知方案,甚至什么方案都不用。
TCC/XA方案适合于多个服务的操作都比较快,例如:资金转账、创建订单、抽奖机会、积分、优惠券相关的服务调用的逻辑。
包裹在一个分布式事务内,用TCC来控制这个分布式事务。

