

Spark中RDD阶段划分
分析源码步骤:
第一步程序入口:

第二步一直查看runjob方法,可以看出collect()是RDD行动算子,与Job运行提交相关
rdd.scala

sparkcontext.scala

sparkcontext.scala
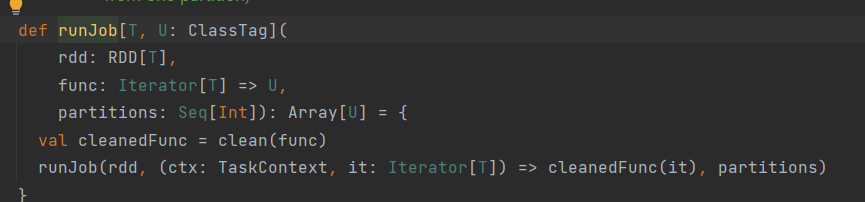
sparkcontext.scala

第三步runJob()与DAG调度有关
sparkcontext.scala

第四步runJob()核心代码 - -查看其中提交作业submitJob()的代码
DAGScheduler.scala

第五步:搜索handleJobSubmitted,handleJobSubmitted中createResultStage()方法会创建ResultStage,即为最后一个阶段finalStage。补充:每一个行动算子都会调用runJob(),最后会new ActiveJob
DAGScheduler.scala
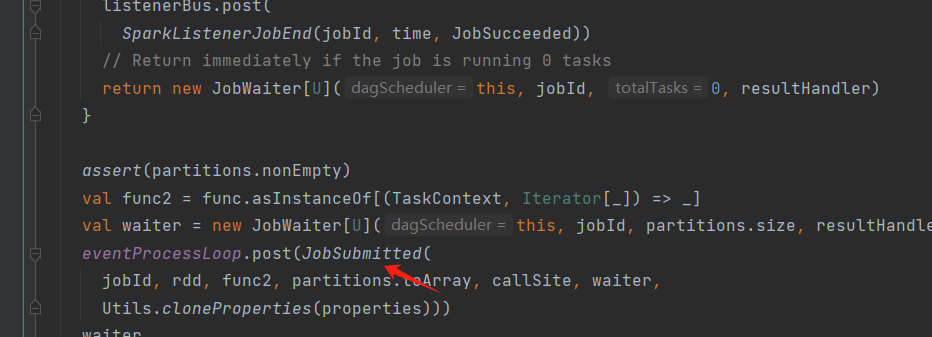
DAGScheduler.scala
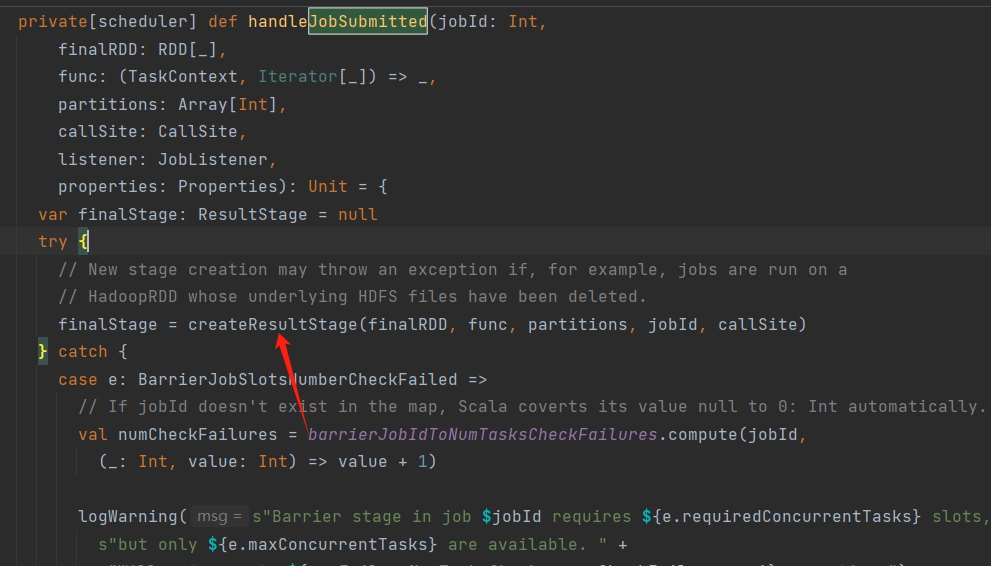
DAGScheduler.scala
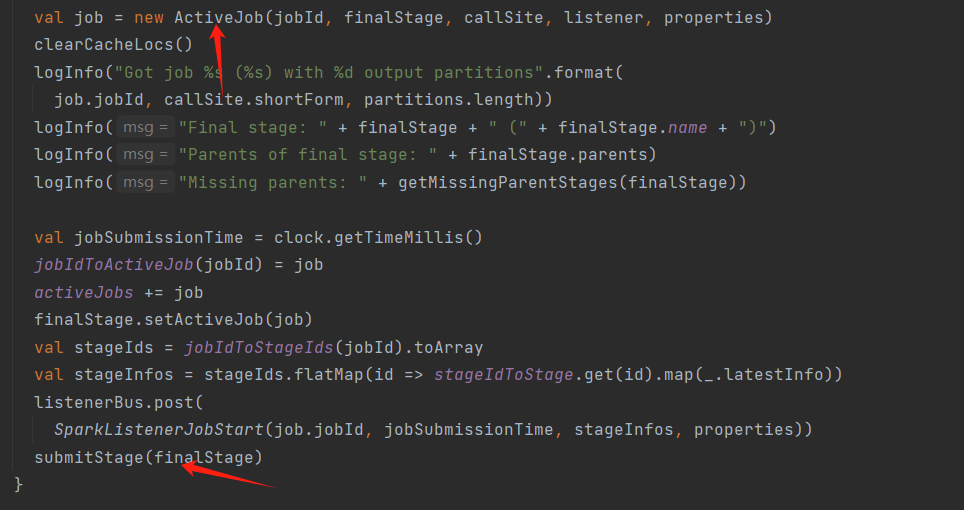
第六步createResultStage()方法中,先调用getOrCreateParentStages(),获得或创建父阶段,因为只有父阶段先执行完,才会执行当前的阶段。然后再创建ResultStage
DAGScheduler.scala

第七步:核心代码:进入getOrCreateParentStages(),调用getShuffleDependencies()返回值是HashSet,存放是的依赖关系,再对每一个shuffleDep,调用getOrCreateShuffleMapStage()创建shuffle阶段。即一个shuffle依赖就会创建一个shuffle阶段
DAGScheduler.scala

DAGScheduler.scala中 getShuffleDependencies此方法是获取依赖关系

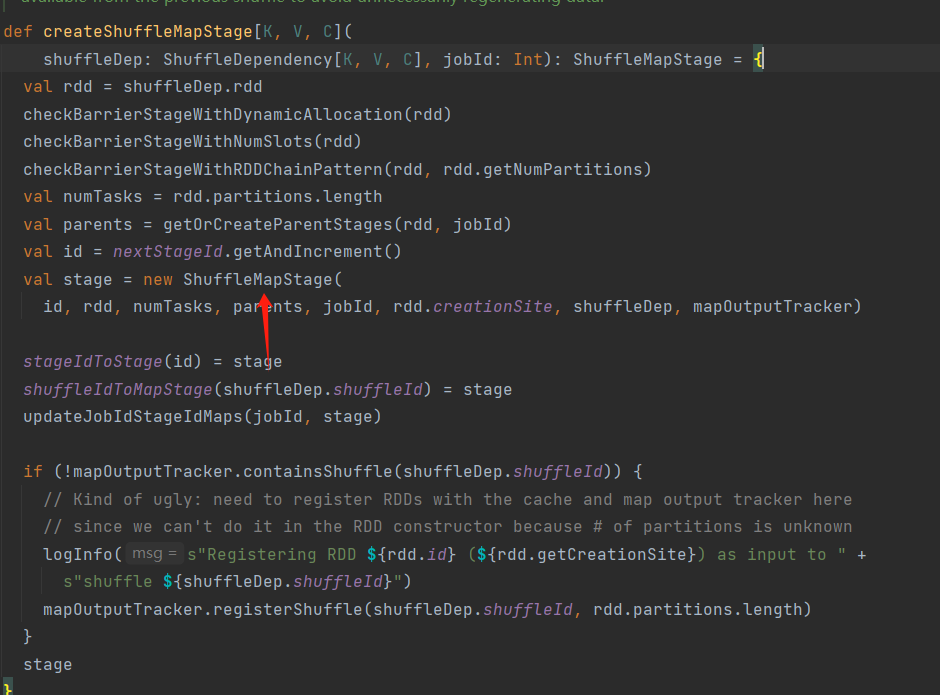
第八步:进入getOrCreateShuffleMapStage(),调用createShuffleMapStage(),创建shuffle阶段new ShuffleMapStage
DAGScheduler.scala
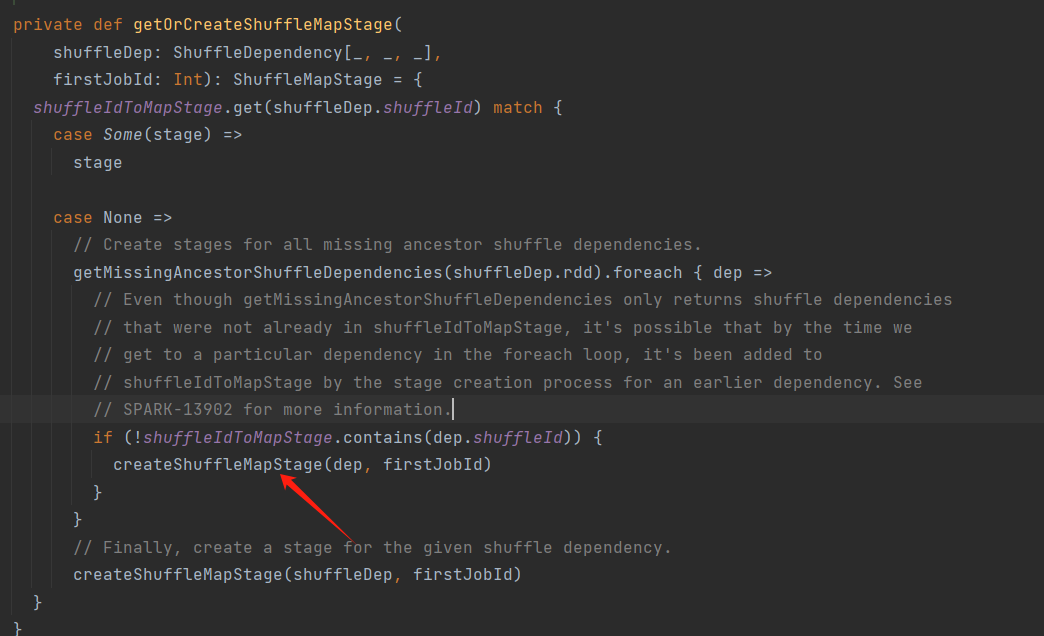
DAGScheduler.scala


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~