【Hadoop】Seondary NameNode不是备份NameNode!!
昨天和舍友聊天时无意中提起Secondary NameNode,他说这是备用NameNode。我当时就有点疑惑。。之后查阅了相关资料和博客,算是基本理解了什么是Secondary NameNode。
1. HDFS为什么要加入Secondary NameNode?
翻看《Hadoop权威指南》,书上明确写道NameNode存在单点损坏问题,Hadoop为了提高NameNode的容错,提供了以下两种机制:
- 备份组成文件系统元数据的文件
- 运行一个辅助NameNode
这里提到的辅助NameNode也就是我们要分析的Secondary NameNode
2. Secondary NameNode的真正作用
(1)首先,我们先了解以下NameNode的相关概念:HDFS集群中有两种节点,DataNode(工作节点)和NameNode(管理结点),NameNode主要功能如下:
- 管理文件系统的命名空间(NameSpace);
- 维护文件系统树(FileSystem Tree)以及整棵树内所有的文件和目录(这些信息称为NameNode的MetaData)
- 记录每个文件中各个块所在的数据结点信息(不永久保存,启动时重建)
(2)NameNode的 MetaData 以两种形式永久保存在本地磁盘上:
- 命名空间镜像文件(fsimage):保存HDFS的最新状态(截止到 fsimage 文件创建时的最新状态)
- 编辑日志文件(edits):自fsimage创建后NameSpace的操作日志
(3)当NameNode 启动时,需要合并fsimage和edits文件,按照edits文件内容将fsimage进行更行,从而得到HDFS的最新状态。实际应用中,NameNode很少重新启动。假如存在一个庞大的集群,且关于HDFS的操作相当频繁与复杂,那么就会产生一个非常大的edits文件用于记录操作,这就带来了以下问题:
- edits文件过大会带来管理问题;
- 一旦需要重启HDFS时,就需要花费很长一段时间对edits和fsimage进行合并,这就导致HDFS长时间内无法启动;
- 如果NameNode挂掉了,会丢失部分操作记录(这部分记录存储在内存中,还未写入edits);
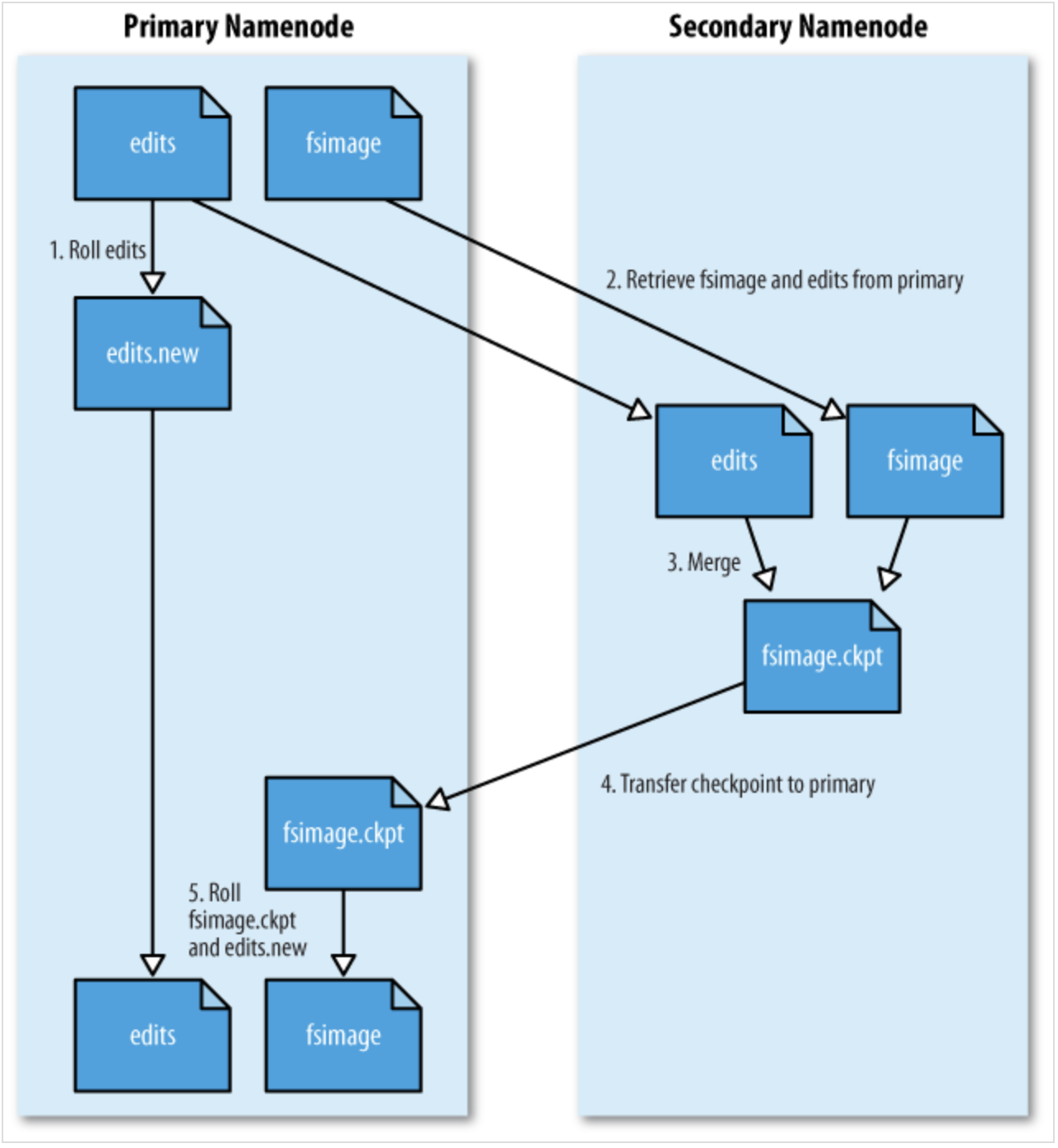
(4)此时,Secondary NameNode(SN)就要发挥它的作用了:合并edits文件,防止edits文件持续增长。具体步骤如下:
- SN向NameNode发送请求;
- NamoNode收到请求,暂停写入edits;
- log记录产生一个edits.new的文件;
- SN从NameNode获取元数据,然后对edits和fsimage进行合并(将edits内容更新到fsimage),产生一个新的fsimage,将其发送给NameNode;
- NameNode收到后,将之前的fsimage文件进行覆盖;
- NameNode删除之前的edits文件,将edits.new重命名为edits;
这样就可以避免edits文件的持续增长,也就解决上述几个问题。
3. Secondary NameNode何时读取元数据(checkpoint)
(1)达到最大时间间隔
参数 fs.checkpoint.period:规定两次checkpoint的最大时间间隔
(2)edits文件的最大尺寸
参数 fs.checkpoint.size:当NameNode上的edits文件超过该尺寸,无论是否达到最大时间间隔,都强制执行checkpoint
4. CheckNode的诞生
由于Secondary NameNode总是让人“望文生义”,带来理解上的偏差,Hadoop 1.0.4之后推荐不再使用Secondary NameNod,而是其替代版CheckNode。二者功能、配置完全相同,只是执行命令有所不同
总结:
1. Secondary NameNode用于定期合并与编辑edits和fsimage文件,防止NameNode的edits文件增长过大;
2. Secondary nameNode一般运行在另一台物理机,因为其内存大小需求与NameNode一致;
3. Secondary NameNode更像是NameNode的辅助工具,而不是备用NameNode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号