

day38
GIL GIOBAL Interpreter Lock
全局解释器锁
锁就是线程里面那个锁
锁是为了避免资源竞争造成数据的错乱
Python程序的执行过程
1.启动解释器进程 Python.exe
2.解析你的py文件并执行它
每一个py程序中都必须有就是一堆代码其他的解释器参与 解释器
相当于多个线程要调用同一个解释器代码 共享以免竞争 竞争就要出事
给解释器加互斥锁
Python 中 内存管理依赖于 GC (一段用于回收内存的代码)也需要一个线程
除了你自己开的线程 系统还有一些内置线程 就算你的代码不会去竞争解释器 内置线程有可能会竞争
所以必须加锁
当一个线程遇到了io 同时解释器也会自动解锁 去执行其他线程 CPU会切换到其他程序
x = obj +1 a = obj +1 2 x = None -1 a = None -1 0
1.关于GIL性能的讨论:
解释器加锁以后
将导致所有线程只能并发 不能达到真正的并行 意味着同一时间只有一个CPU在处理你的线程
给你的感觉序列低
代码执行有两种状态
阻塞i/o失去CPU的执行权 (CPU等待io完成)
非阻塞 代码注册执行 比如循环一千万次 中途CPU可能切换 很快回来 (CPU在计算)
假如有32核CPU 要处理一个下载任务 网络速度慢 100/s 文件大小为1024kb
如果你的代码中io操作非常多 CPU性能不能直接决定你的任务处理速度
案例:
目前有三个任务 每个任务处理需要一秒 获取元数据需要一小时
3个CPU 需要一小时1秒
1个CPU 需要 一小时3秒
在io密集的程序中 CPU性能无法直接决定程序的执行速度 Python就应该干这种活
在计算密集的程序中 CPU性能可以直接决定程序的执行速度
计算密集测试:
计算密集任务 def task1(): sum = 1 for i in range(10000000): sum *= i def task2(): sum = 1 for i in range(10000000): sum *= i def task3(): sum = 1 for i in range(10000000): sum *= i def task4(): sum = 1 for i in range(10000000): sum *= i def task5(): sum = 1 for i in range(10000000): sum *= i def task6(): sum = 1 for i in range(10000000): sum *= i if __name__ == '__main__': 开始时间 st_time = time.time() 多线程情况下 t1 = Thread(target=task1) t2 = Thread(target=task2) t3 = Thread(target=task3) t4 = Thread(target=task4) t5 = Thread(target=task5) t6 = Thread(target=task6) t1 = Process(target=task1) t2 = Process(target=task2) t3 = Process(target=task3) t4 = Process(target=task4) t5 = Process(target=task5) t6 = Process(target=task6) t1.start() t2.start() t3.start() t4.start() t5.start() t6.start() t1.join() t2.join() t3.join() t4.join() t5.join() t6.join() print(time.time() - st_time)
io密集测试:
from threading import Thread from multiprocessing import Process import time # 计算密集任务 def task1(): time.sleep(3) def task2(): time.sleep(3) def task3(): time.sleep(3) def task4(): time.sleep(3) def task5(): time.sleep(3) def task6(): time.sleep(3) if __name__ == '__main__': 开始时间 st_time = time.time() 多线程情况下 t1 = Thread(target=task1) t2 = Thread(target=task2) t3 = Thread(target=task3) t4 = Thread(target=task4) t5 = Thread(target=task5) t6 = Thread(target=task6) t1 = Process(target=task1) t2 = Process(target=task2) t3 = Process(target=task3) t4 = Process(target=task4) t5 = Process(target=task5) t6 = Process(target=task6) t1.start() t2.start() t3.start() t4.start() t5.start() t6.start() t1.join() t2.join() t3.join() t4.join() t5.join() t6.join() print(time.time() - st_time)
GIL与互斥锁:
t1 = Thread(target=task,) t2 = Thread(target=task,) t1.start() t2.start() t1.join() t2.join() print(num)
GIL 和自定义互斥锁的区别
全局锁不能保证自己开启的线程安全 但是不叫解释器中的数据安全的
GIL 在线程用解释器时 自动加锁 在io阻塞时或线程代码执行完毕时 自动解锁
TCP客户端:
import socket c = socket.socket() c.connect(("127.0.0.1", 65535)) while True: msg = input(">>>:") c.send(msg.encode("utf-8")) data = c.recv(1024) print(data.decode("utf-8"))
进程池:
进程池就是一个装进程的容器
为什么出现
当进程很多的时候方便管理进程
什么时候用?
当并发量特别大的时候 例如双十一
很多时候进程是空闲的 就让他进入进程池 让有任务处理时才从进程池取出来使用
进程池使用
ProcessPooIExecutor类
创建时指定最大进程数 自动创建进程
调用submit函数将任务提交到进程池中
创建进程是在调用submit后发生的
总结:
进程池可以自动创建进程
进程限制最大数
自动选择一个空闲的进程帮你错了任务
进程什么时候算空闲
代码执行完是空闲
IO密集时 用线程池
计算密集时 用进程池
import socket from multiprocessing import Process from concurrent.futures import ProcessPoolExecutor 收发数据 def task(c, addr): while True: try: data = c.recv(1024) print(data.decode("utf-8")) if not data: c.close() break c.send(data.upper()) except Exception: print("连接断开") c.close() break if __name__ == '__main__': server = socket.socket() server.bind(("127.0.0.1",65535)) server.listen(5) 创建一个进程池 默认为CPU个数 pool = ProcessPoolExecutor() while True: c,addr = server.accept() p = Process(target=task,args=(c,addr)) p.start() pool.submit(task,c,addr)
进程什么时候算是空闲:
from concurrent.futures import ProcessPoolExecutor import os,time,random def task(): time.sleep(random.randint(1,2)) print(os.getpid()) def run(): pool = ProcessPoolExecutor(2) for i in range(30): pool.submit(task) if __name__ == '__main__': run()
线程池:
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor from threading import current_thread import os,time,random def task(): time.sleep(random.randint(1,2)) print(current_thread()) def run(): # 默认为cpu核心数 * 5 pool = ThreadPoolExecutor(3) for i in range(30): pool.submit(task) if __name__ == '__main__': run()
GIL图
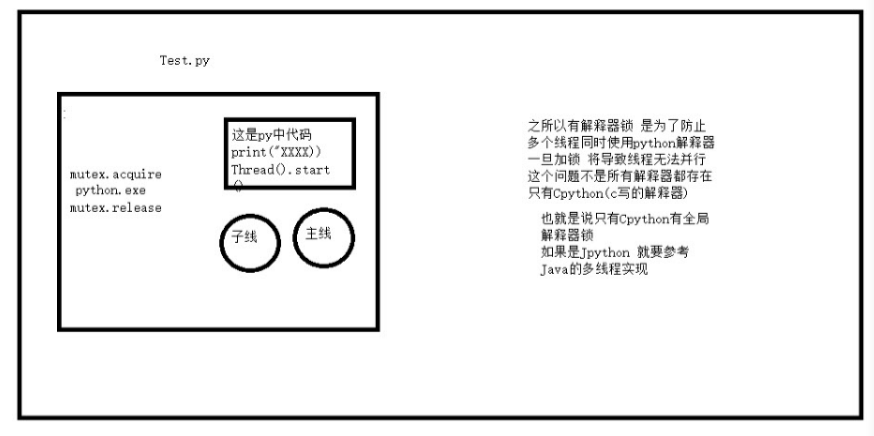
test:
import time,os print(os.getpid()) time.sleep(100)
test2:
from threading import Thread,Lock def task(): print("咨子线程") Thread(target=task).start() Thread(target=task).start() Thread(target=task).start() 当一个py启动后 会先执行主线程中的代码 在以上代码中又开启了子线程 子线程的任务还是执行代码 解释器在一个进程中只有一个(解释器也是一堆代码) 主线和子线都要去调用解释器的代码 那就产生了竞争关系 my_GIL = Lock() 我的解释器 def my_inerpreter(code_str): my_GIL.acquire() print("执行代码!!!!") print(code_str) my_GIL.release() Thread(target=my_inerpreter,args=("print('1')",)).start() Thread(target=my_inerpreter,args=("print('2')",)).start() Thread(target=my_inerpreter,args=("print('3')",)).start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号