
集合
常用集合
✔ List (对付顺序的好帮⼿): 存储的元素是有序的、可重复的。
✔ Set (注重独⼀⽆⼆的性质): 存储的元素是⽆序的、不可重复的。
✔ Map (⽤ Key 来搜索的专家): 使⽤键值对(kye-value)存储,类似于数学上的函数 y=f(x),“x”代表 key,"y"代表 value,Key 是⽆序的、不可重复的,value 是⽆序的、可重复 的,每个键最多映射到⼀个值。
List集合
-
特点
- 允许重复项的有序集合
-
分类
-
list 集合又大致分为 ArrayList 和 LinkedList ,还有就是 Vector 集合。
名称 底层数据结构 添加 删除 查询 线程安全 扩容 Vector 数组 快 快 慢 安全 一倍 ArrayList 数组 慢 慢 快 不安全 一半 LinkedList 链表 快 快 慢 不安全 无需扩容
-
-
比较
- Vector集合 相比于 ArrayList 集合
- 其线程是安全的,但其效率不如 ArrayList 。
- 为什么不推荐使用 Vector 集合 ?
- 因为 Vector 是线程安全的,每个可能出现线程安全的方法上加了synchronized关键字,所以效率低。(ps:然而这样并没有很好的解决线程安全问题)
- 因为在判断是否包含某元素后,会释放锁,在不包含的情况下,执行add之前,锁很有可能会被抢占。
- 其线程是安全的,但其效率不如 ArrayList 。
- LinkedList集合 相比于 ArrayList 集合
- ArrayList基于动态数组实现的非线程安全的集合;LinkedList基于链表实现的非线程安全的集合。
- 对于随机index访问的get和set方法,一般ArrayList的速度要优于LinkedList。因为ArrayList直接通过数组下标直接找到元素;
- LinkedList要移动指针遍历每个元素直到找到为止。
- 新增和删除元素,一般LinkedList的速度要优于ArrayList。
- 因为ArrayList在新增和删除元素时,可能扩容和复制数组;LinkedList实例化对象需要时间外,只需要修改指针即可。
- LinkedList 集合不支持 高效的随机随机访问(RandomAccess)
- ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间。
- Vector集合 相比于 ArrayList 集合
Map集合
-
特点
- 键值对集合
- Map集合的key集合就是 Set 集合。所以Map集合中的key是不可重复的,而value是可重复。
-
分类
-
Map 集合大致分为 HashMap 、HashTable 和 TreeMap 。
-
HashMap
- 底层数据结构
- JDK1.8 之前是 数组和链表,JDK1.8 之后 是 数组和链表+红黑树
- 基于
- HashMap实现了Map接口,继承AbstractMap类,它是基于哈希表的 Map 接口的实现(保证键的唯一性)
- 键值对
- 允许存在一个为null的key和任意个为null的value。
- 扩容
- 初始容量为 16,hashMap扩容时 新容量 = 旧容量 * 2
- 底层数据结构
-
HashTable
- 底层数据结构
- 数组+链表
- 基于
- 出现于 JDK1.0,HashTable基于 Dictionary 类。
- 键值对
- key和value都不允许为null
- 扩容
- 初始容量为11,hashtable扩容时 新容量 = 旧容 * 2+1
- 线程安全
- Hashtable是同步的,所有的读写操作都进行了锁保护,是线程安全的。
- 底层数据结构
-
TreeMap
-
底层数据结构
- 红黑树
-
基于
- 基于红黑树(Red-Black tree)的 NavigableMap实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator进行排序,具体取决于使用的构造方法。
-
键值对
- 当未实现 Comparator 接口时,key 不可以为null,否则抛 NullPointerException 异常;
- 当实现 Comparator 接口时,若未对 null 情况进行判断,则可能抛 NullPointerException 异常。如果针对null情况实现了,可以存入,但是却不能正常使用 get() 访问,只能通过遍历去访问。
-
扩容
- 无需扩容
-
-
Set集合
-
特点
- 一个不包含重复项的集合(官方解释)
- 有序与无序取决于其底层数据结构
- 一个不包含重复项的集合(官方解释)
-
分类
-
set 集合大致分为 HashSet 和 TreeSet
-
HashSet
- 底层数据结构
- HashSet的底层通过 HashMap 实现的,而 HashMap 在1.7之前使用的是数组+链表实现,在1.8+使用的数组+链表+红黑树实现。
- 基于
- 通过 HashMap 实现
- 值
- 允许有一个为 null 的元素
- 扩容
- 初始容量为 16,hashMap扩容时 新容量 = 旧容量 * 2
- 底层数据结构
-
TreeSet
- 底层数据结构
- 和 TreeMap 数据结构都是红黑树
- 基于
- 通过 TreeMap 实现
- 值
- 不允许为null的元素
- 扩容
- 无需扩容
- 底层数据结构
-
集合扩展
1. CurrentHashMap类
-
数据结构
- 取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
-
保证线程安全机制
- JDK1.7 采用 segment 的分段锁机制实现线程安全,其中 segment 继承自 ReentrantLock 。
- JDK1.8 采用 CAS + Synchronized 保证线程安全。
-
锁的粒度
- 原来是对需要进行数据操作的 Segment 加锁,现调整为对每个数组元素加锁(Node)。
-
链表转化为红黑树
- 定位结点的 hash 算法简化会带来弊端, Hash 冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
-
查询时间复杂度
- 从原来的遍历链表O(n),变成遍历红黑树O(logN)。
分段锁原理
-
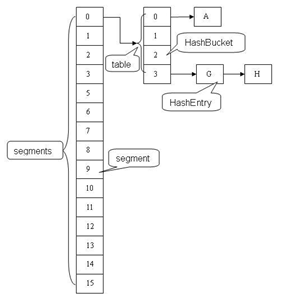
底层采用:Segments 数组 + HashEntry 数组 + 链表
-
原理
-
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
-
Segment 是一种可重入锁 ReentrantLock ,在 ConcurrentHashMap 里扮演锁的角色,HashEntry 则用于存储键值对数据。
-
一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的结构和 HashMap 类似,是一种数组和链表结构, 一个 Segment 里包含一个HashEntry 数组,每个 HashEntry 是一个链表结构的元素, 每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得它对应的 Segment 锁。
-
get操作:
- Segment的 get操作 实现非常简单和高效,
- 先经过一次再散列
- 然后使用这个散列值通过散列运算定位到 Segment
- 再通过散列算法定位到元素。
- get操作的高效之处在于整个get过程都不需要加锁,除非读到空的值才会加锁重读。(原因就是将使用的共享变量定义成 volatile 类型)。
-
put操作:
- 当执行put操作时,会经历两个步骤:
- 判断是否需要扩容;
- 定位到添加元素的位置,将其放入 HashEntry 数组中。
CAS + Synchronized 原理
-
底层采用:Node数据+链表+红黑树
-
原理
-
读操作无锁 :
- Node的 val 和 next 使用 volatile 修饰,读写线程对该变量互相可见
- 数组用 volatile 修饰,保证扩容时被读线程感知
-
get() 操作:
-
get 操作全程无锁。get 操作可以无锁是由于 Node 元素的 val 和指针 next 是用 volatile 修饰的。
-
在多线程环境下线程A修改节点的 val 或者新增节点的时候是对线程B可见的。
-
流程
-
计算hash值,定位到Node数组中的位置
-
如果该位置为null,则直接返回null
-
如果该位置不为null,再判断该节点是红黑树节点还是链表节点
-
如果是红黑树节点,使用红黑树的查找方式来进行查找
-
如果是链表节点,遍历链表进行查找
-
-
-
-
put() 操作:
-
先判断Node数组有没有初始化,如果没有初始化先初始化initTable();
-
根据key的进行hash操作,找到Node数组中的位置,如果不存在hash冲突,即该位置是null,直接用CAS插入
-
如果存在hash冲突,就先对链表的头节点或者红黑树的头节点加synchronized锁
-
如果是链表,就遍历链表,如果key相同就执行覆盖操作,如果不同就将元素插入到链表的尾部, 并且在链表长度大于8, Node数组的长度超过64时,会将链表的转化为红黑树。
-
如果是红黑树,就按照红黑树的结构进行插入。
-
-
2. Map原理
-
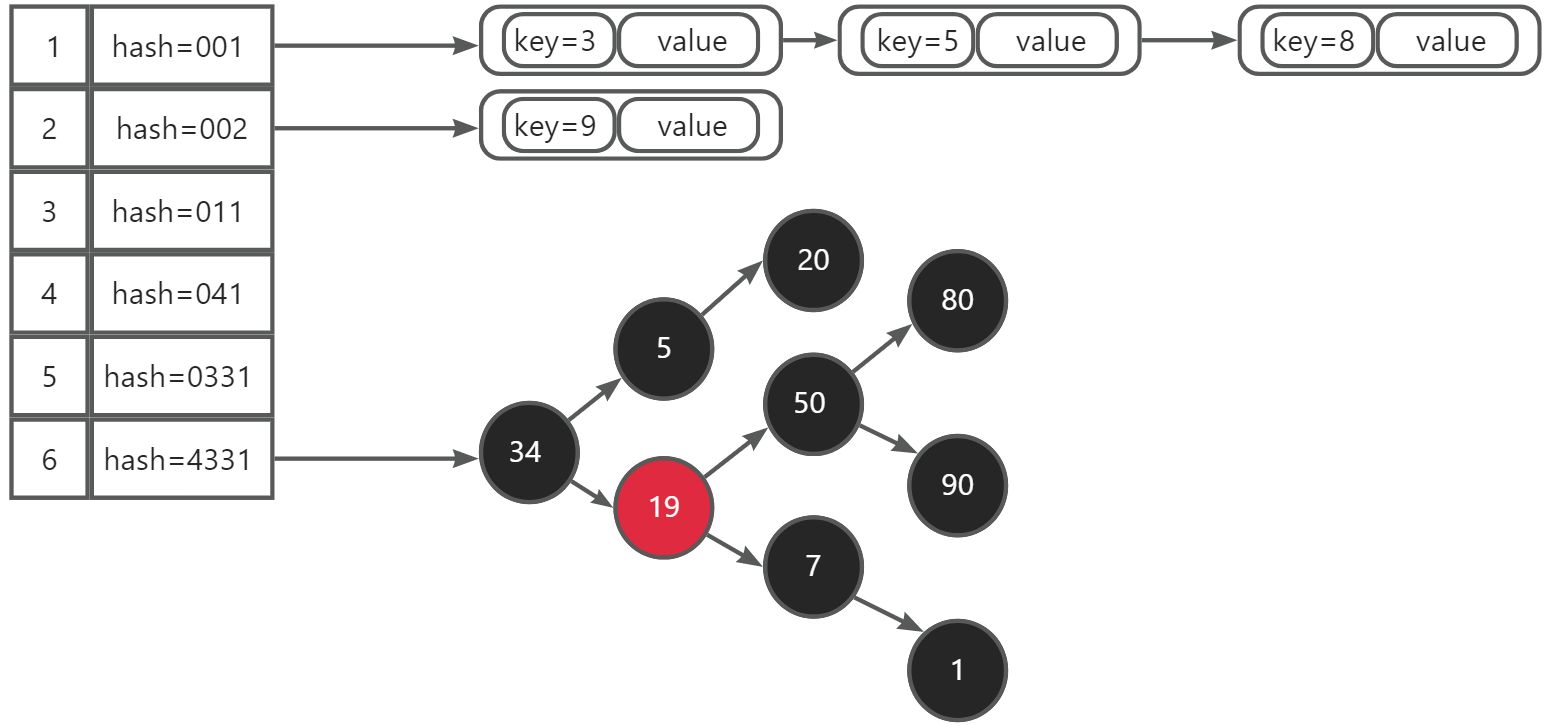
-
会根据key获取到hashcode,再通过桶算法获取到对应的下标。
-
链表的每个节点由key和value组成节点,红黑树的每个节点也是由key和value组成的。
-
链表长度超过8以后,就会转换为红黑树。
- 趋*于*衡二叉树,其次采用红黑树的特点,减低了左旋和右旋操作。
PUT操作
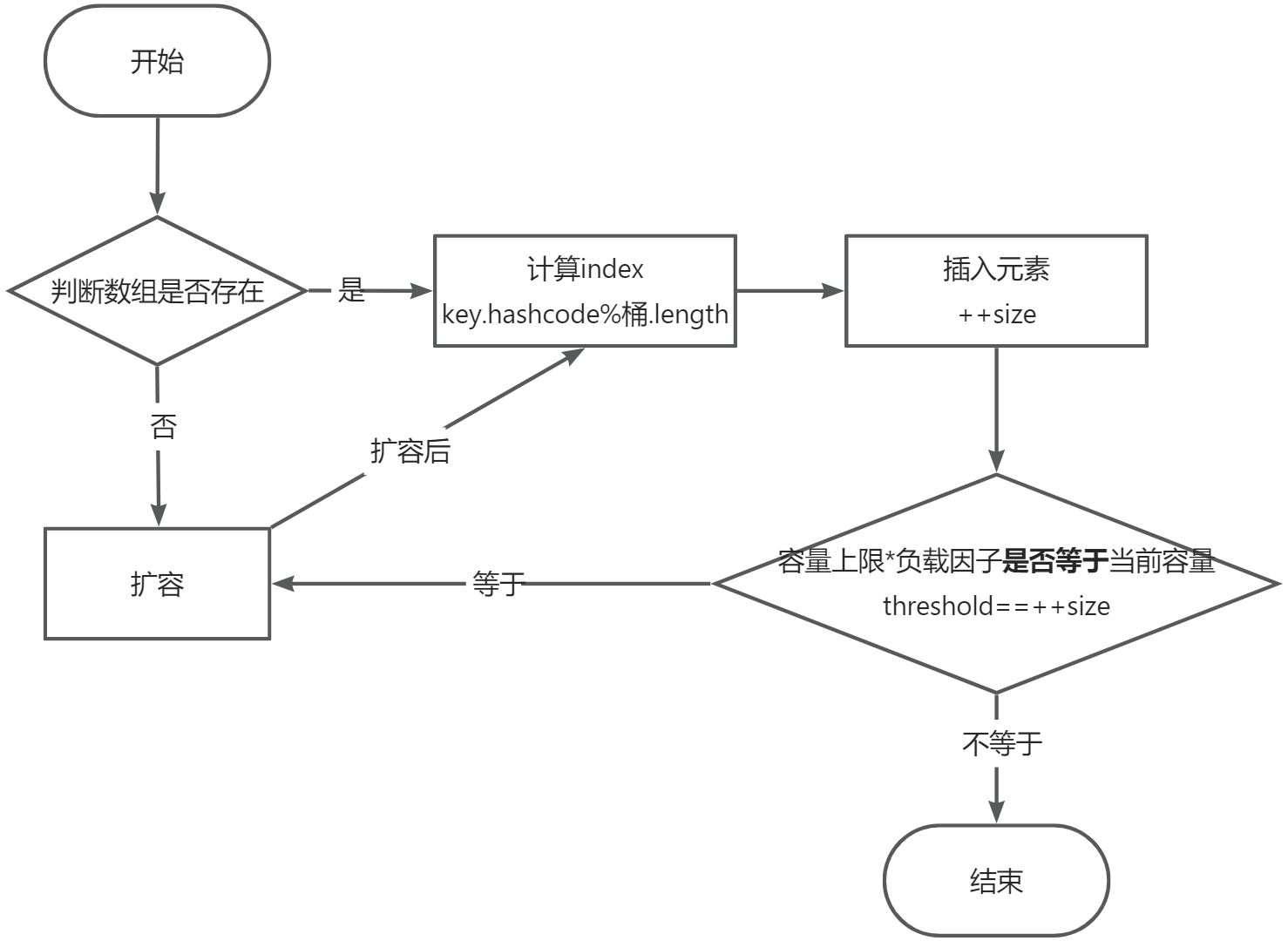
- HashMap的容量size乘以负载因子[默认0.75] = threshold; // threshold即为开始扩容的临界值
基本流程
- 判断数组是否存在,不存在就调用resize方法(扩容方法),建立一个数组。
- 存在,根据key计算index值,然后插入元素。
- 插入元素后,需要判断容量是否等于临界值(也就是当前容量上限乘以负载因子)。
- 等于临界值时,则会触发扩容。
插入流程
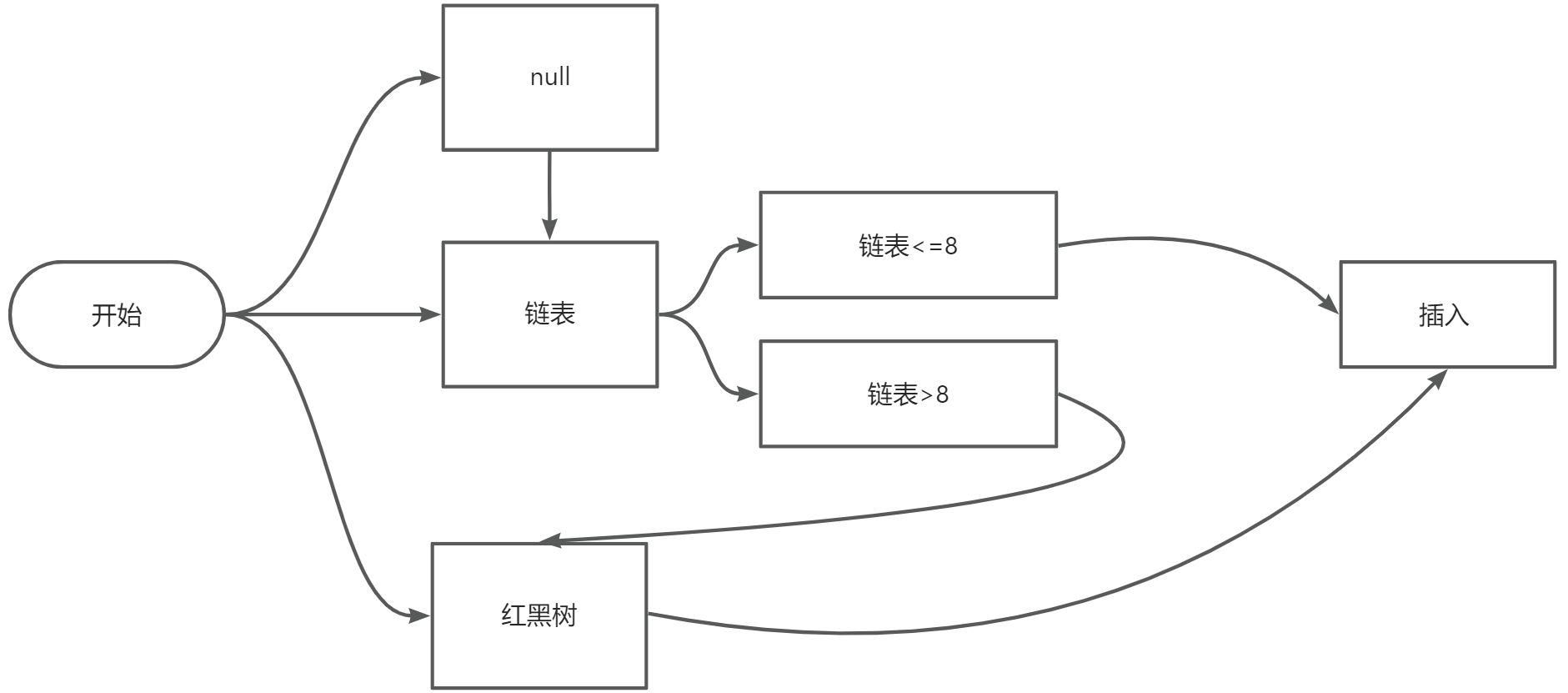
扩容
- 扩容条件
- 第一次创建数组,也会调用扩容方法。
- 容量上限乘以负载因子[默认0.75] = threshold; map的size等于临界值时就会触发扩容方法。
- 扩容上限
- 2^ {31}-1(Integer.MAX_VALUE)
3. LinkedHashMap 与 LinkedHashSet类
-
LinkedHashMap
- LinkedHashMap实现了Map接口,即允许放入
key为null的元素,也允许插入value为null的元素。从名字上可以看出该容器是linked list和HashMap的混合体,也就是说它同时满足HashMap和linked list的某些特性。可将*LinkedHashMap*看作使用*Linked list*增强的*HashMap*
- LinkedHashMap实现了Map接口,即允许放入
-
LinkedHashSet
- LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法

