
C#|.net core 高级 - 高级知识点,内存对齐,原理与示例
最近几年一直从事物联网开发,与硬件打交道越来越多,发现越接近底层开发对性能的追求越高,毕竟硬件资源相对上层应用来实在是太缺乏了。今天想和大家一起分享关于C#中的内存对齐,希望通过理解和优化内存对齐,可以帮助大家更好的提高程序性能以及资源利用效率。
什么是内存对齐
内存对齐指把数据存储在内存中时,需要按照某种特定规则进行存储,使其内存存储在符合特定边界要求的内存地址上。而内存对齐主要目的则是减少CPU内存操作次数,提高内存操作效率,并提升CPU缓存命中率,从而提升整体性能。
内存对齐原则
内存对齐原则包含两部分:内存对齐边界和内存对齐规则。
① 内存对齐边界:数据存储在内存中的起始内存地址必须满足条件。例如,8字节对齐则要求数据的起始内存地址必须是8的倍数;
② 内存对齐规则:不同的硬件平台内存对齐规则也各有差异,比如:x86、x64架构在内存对齐方面比较宽松,而ARM、RISC-V架构则相对比较严格;一般32位处理器要求4字节对齐,而64位处理器要求8字节对齐;
因此不同的CPU架构和平台则内存对齐规则也各有不同,而这些差异也都是为了使数据在内存中的布局更加符合CPU操作方式,从而提高程序执行效率。
C#中的内存对齐
1、“托管代码”和“非托管代码”
托管代码:执行过程交给运行时CLR管理的代码,运行时CLR负责提取托管代码并编译成机器代码最后执行,同时运行时CLR还负责自动内存管理、安全边界和类型安全等重要服务。
“非托管代码”:即不被运行时CLR管理的代码,比如运行C/C++语言编写的代码,而此时开发任意就需要亲自处理很多事情,比如内存管理、垃圾回收、安全问题等等。
因此一般对于托管代码来说,内存的分配以及对齐策略都被运行时CLR一手包办了,无需我们过多关注,而如果需要通过P/Invoke和COM互操作来调用非托管代码则需要开发者自己处理内存对齐策略了。
当然也不是说纯托管代码就没有对内存对齐操作空间了,只是相对来说与非托管代码交互时使用内存对齐操作空间更大。
2、StructLayoutAttribute特性
无论托管内存还是非托管内存,都可以用StructLayoutAttribute特性来对其进行内存布局控制,简单来说对于托管代码可以使用LayoutKind枚举值Explicit进行显示控制,而对于非托管代码LayoutKind枚举值都可以控制。
示例-字段顺序影响内存占用大小
我们用StructLayout(LayoutKind.Sequential标记OriginalLayout结构体,看看每个字段的布局情况及其与占用内存总大小之间的关系,先来看下面一段代码:

using System.Runtime.InteropServices; namespace CSharp { public class MemoryLayout { [StructLayout(LayoutKind.Sequential)] public struct OriginalLayout { public long LongField1; public short ShortField; public byte ByteField1; } public static void Run() { Console.WriteLine($"OriginalLayout LongField1 偏移量: {Marshal.OffsetOf(typeof(OriginalLayout), "LongField1")} "); Console.WriteLine($"OriginalLayout ShortField 偏移量: {Marshal.OffsetOf(typeof(OriginalLayout), "ShortField")} "); Console.WriteLine($"OriginalLayout ByteField1 偏移量: {Marshal.OffsetOf(typeof(OriginalLayout), "ByteField1")} "); Console.WriteLine($"OriginalLayout 总大小: {Marshal.SizeOf(typeof(OriginalLayout))} bytes"); Console.ReadKey(); } } }
我们使用Marshal.OffsetOf计算每个字段偏移量,即第一个字段偏移量表示其内存地址为0,则第二个字段偏移量表示为其相对第一个字段内存地址值的相对值,使用Marshal.SizeOf计算类型所占内存总大小。
如下图是上面代码运行结果:
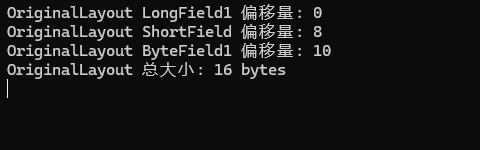
首先说下long类型为8字节、short类型为2字节、byte类型为1字节,再来详细说下每个值怎么来的。
首先因为LongField1是第一个字段所以为0,并且因为long类型为8字节,所以LongField1使用了0-7内存地址段,所有第二个字段ShortField偏移量为8,因此ShortField使用了8-9内存地址段,所以第三个字段ByteField1偏移量为10。
那为什么总大小不是8+2+1=11字节,而16字节呢?这是因为对于类型的对齐方式默认会以其最大的元素对齐方式为准,并且整个类型大小是最大元素大小的整数倍,因此这里的总大小是8的倍数,因为2+1并没有占满8字节,因此ByteField1后面被自动填充了5个字节,以此达到对齐要求。所以最后就是8+2+1+5(自动填充)=16字节。
然后我们把LongField1和ShortField两个字段调整一下位置,再来看看运行结果:
public class MemoryLayout { [StructLayout(LayoutKind.Sequential)] public struct OriginalLayout { public short ShortField; public long LongField1; public byte ByteField1; } public static void Run() { Console.WriteLine($"OriginalLayout ShortField 偏移量: {Marshal.OffsetOf(typeof(OriginalLayout), "ShortField")} "); Console.WriteLine($"OriginalLayout LongField1 偏移量: {Marshal.OffsetOf(typeof(OriginalLayout), "LongField1")} "); Console.WriteLine($"OriginalLayout ByteField1 偏移量: {Marshal.OffsetOf(typeof(OriginalLayout), "ByteField1")} "); Console.WriteLine($"OriginalLayout 总大小: {Marshal.SizeOf(typeof(OriginalLayout))} bytes"); Console.ReadKey(); } }
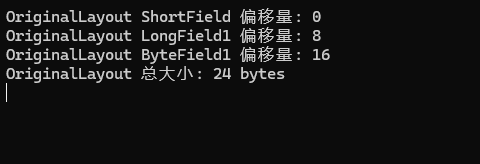
这里为什么又是24字节呢?
首先虽然ShortField只占了2字节,使用了0-1内存地址段,但是LongField1并不能从2内存地址值开始排版,因为每个字段必须与其自身大小的字段或类型的对齐方式对齐,也就是说LongField1占8字节,那么其内存地址起始值也要是8的整数倍,因此LongFiled1使用了8-15内存地址段,而ShortField和LongFiled1之间会被自动填充6个字节,同样的ByteField1后面也被自动填充7个字节,因此总大小为24字节。
这里只是举了个小例子来展示字段顺序不同,对最终类型所占内存总大小的,这也给我们设计低内存消耗程序设计提供了空间。
当然这里只是简单使用了StructLayout,还Pack属性,以及Explicit和FieldOffset,还有CharSet、MarshalAs等复杂的功能都没有介绍,有兴趣的可以深入研究研究。本文只是简单内存对齐的原理原则以及简单的内存优化,后面有机会再给大家深入介绍。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库