关于编码
因为浏览器和操作系统各自不同,导致字符串的默认编码方式各有不同。表单、URL、ajax中含汉语或者其他语言时出现乱码的原因就是不同的编码导致。
解决该问题的最简单的方法是用JavaScript先对URL进行编码在提交到服务器,这样浏览器不会对此再次编码。
下面将介绍JavaScript和asp.net的编码和解码。
JavaScript:
Window.escape(str); 字符串编码成Unicode编码。
Window.unescape(str); Unicode编码解码成字符。
规则是:除了ASCII字母、数字、标点符号"@*_+-./"意外的字符进行编码。因为它不对"+"进行编码,所以不建议用该编码方式。
格式: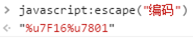

Window.encodeURI(str); 字符串编码成utf-8编码。
Window.decodeURI(str); utf-8编码解码成字符。
规则是:除了ASCII字母、数字、标点符号";/?:@&=+$,#"意外的字符进行编码。
格式:

Window.encodeURIComponent(str); 字符串编码成utf-8编码。
Window.decodeURIComponent(str); utf-8编码解码成字符串。
规则是:跟encodeURI一样,但它会对";/?:@&=+$,#"等符号进行编码。
格式:

ASP.NET:
HttpUtility.UrlEncode(str); 字符串编码成utf-8编码。
HttpUtility.UrlDecode(str); utf-8编码解码成字符串。
规则是:js的encodeURIComponent(str)/decodeURIComponent(str)编码/解码函数规则一样,并会把空格编码成"+"符号。
编码种类:
ASCII:从00000000到01111111的八个二进制,共有128种不同状态,被称为字节(byte),最前面一位规定0。
GB2312:简体中文常见的编码方式,两个字节表示一个汉字,最多可以表示65536个符号。
Unicode:他有UCS-2和UCS-4规范。UCS-2是用两个字节表示,共有65536个状态。UCS-4是用4个字节表示,共有4,294,967,296个状态。目前普遍采用的市UCS-2。
Utf-8:是Unicode的一种实现方式,还包括utf-16和utf-32。特点:他是一种变长的编码方式。
Utf-8规则:
单字节第一位规定0,后面7位是Unicode码,随意utf-8和ASCII码是相同的。
一个字符有n字节,则在第一个字节前n位设为1,n+1设为0,其后字节的前两位设为'10'。假设一个字符有4个字节,则这四个字节的"壳"是1111 0xxx,10xx xxxx,10xx xxxx,10xx xxxx。再把该字符转换成二进制,补到x位置,从后往前补。所以utf-8一个字符最大可占7个byte(字节)。最后这四个字节转换成十六进制(8个字符)。
decodeURIComponent(str)就是每个字节前加了"%"符号的16进制。
Unicode:文件开头FF FE 表明little endian格式编码,字符从后往前编码,FF FE 4E 25 实际上是25 4E。
Unicode big endian:文件开头FE FF,从前往后编码。
Utf-8:文件开头EF BB BF,从前往后编码。
注:文件开头说明该文件的编码类型!
如果有错别地方请大师指出来哦, O(∩_∩)O谢谢!
本文章参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号