


spark架构原理
一、spark基础架构
spark和Hadoop的基础架构类似,采用了分布式计算中的Master-Slave模型。
Master是对应集群中的含有Master进程的节点,Slave是集群中含有Worker进程的节点。
1、物理节点逻辑
Master:作为整个集群的控制器,负责整个集群的正常运行,负责接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor;
Worker:相当于是计算节点,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor。
Client:作为用户的客户端负责提交应用。
2、管理程序逻辑
Driver: 一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。运行在worker,或客户端。并不是运行在master。
Executor:即真正执行作业的地方,一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task。
clusterManager:指的是在集群上获取资源的外部服务。目前有三种类型:1、Standalon,spark原生的资源管理,由Master负责资源的分配,2、Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架,3、Hadoop Yarn: 主要是指Yarn中的ResourceManager。
如图
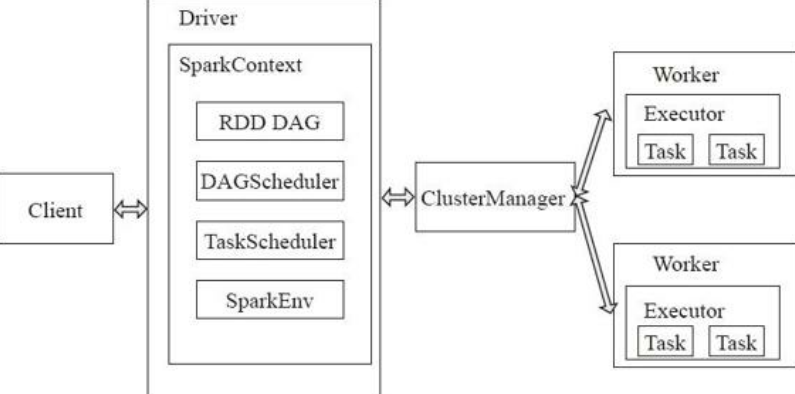
二、spark作业
1、作业逻辑概念
Application: Appliction都是指用户编写的Spark应用程序,其中包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码。
Job: 包含多个Task组成的并行计算,往往由rdd的行动操作(非转化操作)触发生成, 一个Application中往往会产生多个Job。
Stage: 每个Job会被拆分成多组Task, 作为一个TaskSet, 其名称为Stage。Stage的划分和调度是有DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方。
Task: 被送到某个Executor上的工作单元,和hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责。
DAGScheduler: 根据Job构建基于Stage的DAG,并提交Stage给TASkScheduler。 其划分Stage的依据是RDD之间的依赖的关系找出开销最小的调度方法。
TASKSedulter: 将TaskSET提交给worker运行,每个Executor运行什么Task就是在此处分配的. TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行标签,重试失败的Task。
总的作业流程逻辑图如下:

2、作业物理逻辑框架
2.1、Driver运行在Worker上的时候,作业流程具体如下:
客户端提交作业给Master。Master让一个Worker启动Driver,即SchedulerBackend。Worker创建一个DriverRunner线程,DriverRunner启动SchedulerBackend进程。 另外Master还会让其余Worker启动Exeuctor,即ExecutorBackend。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。 ExecutorBackend启动后会向Driver的SchedulerBackend注册。SchedulerBackend进程中包含DAGScheduler,它会根据用户程序,生成执行计划,并调度执行。对于每个stage的task,都会被存放到TaskScheduler中,ExecutorBackend向SchedulerBackend汇报的时候把TaskScheduler中的task调度到ExecutorBackend执行。 所有stage都完成后作业结束。
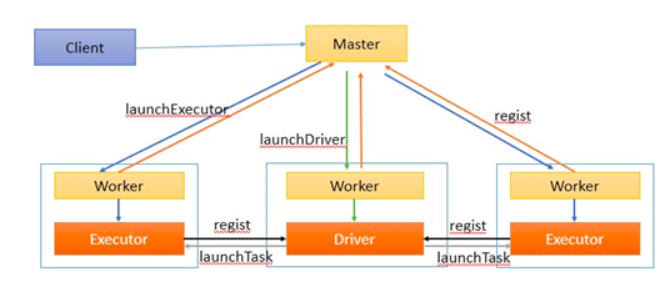
2.2、Driver运行在Client上的时候,作业流程具体如下:

三、spark架构原理和Hadoop的异同
spark和Hadoop物理架构原理类似,都使用Master-Slave模型,但是作业逻辑有较大差异。
两者都是用MapReduce模型来进行并行计算,Hadoop的一个作业称为job,job里面分为map task和reduce task,每个task都是在自己的进程中运行的,当task结束时,进程也会结束。但是,hadoop的job只有map和reduce操作,表达能力比较欠缺。而且在MapReduce过程中,中间结果会重复的读写hdfs,造成大量的io操作。同时,reducetask需要等待所有maptask都完成之后才可以开始。上述原因,导致Hadoop时延高,只适合batch数据处理,对于交互式数据处理,实时数据处理的支持不够。也由于中间结果的存盘,导致Hadoop对于迭代式数据处理能力比较差。再另外,job之间的依赖关系是有开发者自己管理的。
相对的,Spark的DAGScheduler相当于一个改进版的MapReduce,如果计算不涉及与其他节点进行数据交换,也就是在一个stage内部,Spark可以在内存中一次性完成这些操作,也就是中间结果无须落盘,减少了磁盘IO的操作。当然,如果计算过程中涉及数据交换,也就是stage之间,Spark也是会把shuffle的数据写磁盘的。同时,Spark支持将需要反复用到的数据缓存到内存中,减少数据加载耗时,所以Spark适合于迭代式数据处理,从而适合于跑机器学习算法。
四、spark运算模型
相对于Hadoop只有Map和Reduce的编程逻辑,spark抽象出一个更上层的,表达能力更丰富的编程概念RDD。RDD字面意思是弹性分布式数据集,其实就是分布式的元素集合。
RDD 可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的。逻辑上RDD 的每个分区叫一个Partition。在Spark 的执行过程中,RDD 经历一个个的Transfomation 算子之后,最后通过Action算子进行触发操作。逻辑上每经历一次变换,就会将RDD 转换为一个新的RDD,RDD 之间通过Lineage(血统)产生依赖关系,这个关系在容错中有很重要的作用。变换的输入和输出都是RDD。RDD 会被划分成很多的分区分布到集群的多个节点中。分区是个逻辑概念,变换前后的新旧分区在物理上可能是同一块内存存储。这是很重要的优化,以防止函数式数据不变性(immutable)导致的内存需求无限扩张。有些RDD 是计算的中间结果,其分区并不一定有相应的内存或磁盘数据与之对应,如果要迭代使用数据,可以调cache() 函数缓存数据。
1、RDD 的两种创建方式
1)从Hadoop文件系统(或与Hadoop 兼容的其他持久化存储系统,如Hive、Cassandra、Hbase)输入(如HDFS)创建。
2)从父RDD 转换得到新的RDD。
2、RDD 的两种操作算子
对于RDD 可以有两种计算操作算子:Transformation(变换)与Action(行动)。
1)Transformation(变换)。
Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个RDD 的转换操作不是马上执行,需要等到有Actions 操作时,才真正触发运算。
2)Action(行动)
Action 算子会触发Spark 提交作业(Job),并将数据输出到Spark 系统。
3、RDD 的重要内部属性
1)分区列表。
2)计算每个分片的函数。
3)对父RDD 的依赖列表。
4)对Key-Value 对数据类型RDD 的分区器,控制分区策略和分区数。
5)每个数据分区的地址列表(如HDFS 上的数据块的地址)。
4、Saprk RDD算子的作用
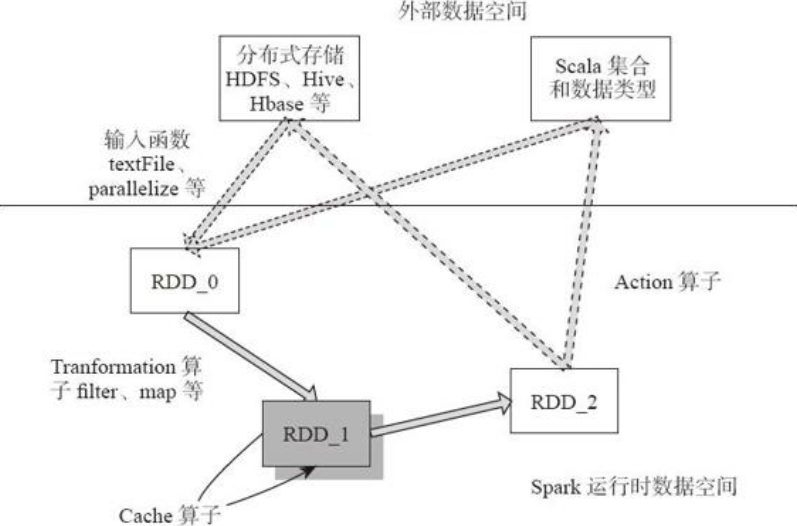
图描述了Spark 的输入、运行转换、输出。在运行转换中通过算子对RDD 进行转换。算子是RDD 中定义的函数,可以对RDD 中的数据进行转换和操作。
1)输入:在Spark 程序运行中,数据从外部数据空间(如分布式存储:textFile 读取HDFS 等,parallelize 方法输入Scala 集合或数据)输入Spark,数据进入Spark 运行时数据空间,转化为Spark 中的数据块,通过BlockManager 进行管理。
2)运行:在Spark 数据输入形成RDD 后便可以通过变换算子,如fliter 等,对数据进行操作并将RDD 转化为新的RDD,通过Action 算子,触发Spark 提交作业。如果数据需要复用,可以通过Cache 算子,将数据缓存到内存。
3)输出:程序运行结束数据会输出Spark 运行时空间,存储到分布式存储中(如saveAsTextFile 输出到HDFS),或Scala 数据或集合中(collect 输出到Scala 集合,count 返回Scala int 型数据)。Spark 的核心数据模型是RDD,但RDD 是个抽象类,具体由各子类实现, 如MappedRDD、ShuffledRDD 等子类。Spark 将常用的大数据操作都转化成为RDD 的子类。
参考:
https://www.cnblogs.com/sunrye/p/6504876.html

