
摘要:  一句话总结: SmolVLM 现已具备更强的视觉理解能力📺 SmolVLM2 标志着视频理解技术的根本性转变——从依赖海量计算资源的巨型模型,转向可在任何设备运行的轻量级模型。我们的目标很简单: 让视频理解技术从手机到服务器都能轻松部署。 我们同步发布三种规模的模型 (22 亿/5 亿/2.56 阅读全文
一句话总结: SmolVLM 现已具备更强的视觉理解能力📺 SmolVLM2 标志着视频理解技术的根本性转变——从依赖海量计算资源的巨型模型,转向可在任何设备运行的轻量级模型。我们的目标很简单: 让视频理解技术从手机到服务器都能轻松部署。 我们同步发布三种规模的模型 (22 亿/5 亿/2.56 阅读全文
一句话总结: SmolVLM 现已具备更强的视觉理解能力📺 SmolVLM2 标志着视频理解技术的根本性转变——从依赖海量计算资源的巨型模型,转向可在任何设备运行的轻量级模型。我们的目标很简单: 让视频理解技术从手机到服务器都能轻松部署。 我们同步发布三种规模的模型 (22 亿/5 亿/2.56 阅读全文
posted @ 2025-03-24 22:15
HuggingFace
阅读(1500)
评论(0)
推荐(0)
摘要: 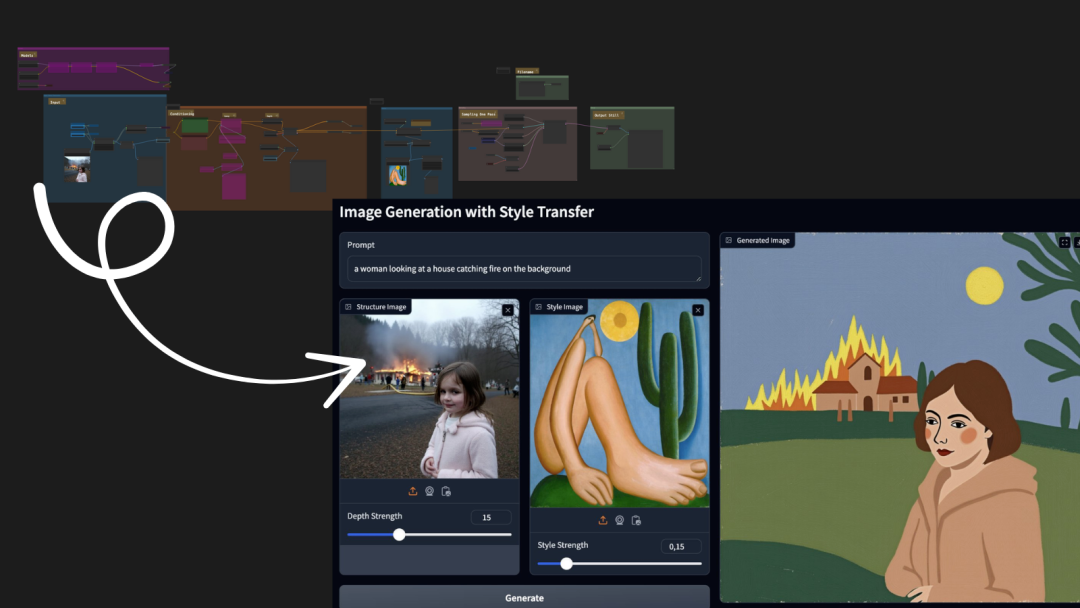 简介 在本教程中,我将逐步指导如何将一个复杂的 ComfyUI 工作流转换为一个简单的 Gradio 应用程序,并讲解如何将其部署在 Hugging Face Spaces 的 ZeroGPU 无服务器架构上,这样可以让它以无服务器的方式免费部署和运行。在本教程中,我们将使用 Nathan Ship 阅读全文
简介 在本教程中,我将逐步指导如何将一个复杂的 ComfyUI 工作流转换为一个简单的 Gradio 应用程序,并讲解如何将其部署在 Hugging Face Spaces 的 ZeroGPU 无服务器架构上,这样可以让它以无服务器的方式免费部署和运行。在本教程中,我们将使用 Nathan Ship 阅读全文
简介 在本教程中,我将逐步指导如何将一个复杂的 ComfyUI 工作流转换为一个简单的 Gradio 应用程序,并讲解如何将其部署在 Hugging Face Spaces 的 ZeroGPU 无服务器架构上,这样可以让它以无服务器的方式免费部署和运行。在本教程中,我们将使用 Nathan Ship 阅读全文
posted @ 2025-03-24 17:22
HuggingFace
阅读(1135)
评论(0)
推荐(1)
 介绍 S2S (语音到语音) 是 Hugging Face 社区内存在的一个令人兴奋的新项目,它结合了多种先进的模型,创造出几乎天衣无缝的体验: 你输入语音,系统会用合成的声音进行回复。 该项目利用 Hugging Face 社区中的 Transformers 库提供的模型实现了流水话处理。该流程处
介绍 S2S (语音到语音) 是 Hugging Face 社区内存在的一个令人兴奋的新项目,它结合了多种先进的模型,创造出几乎天衣无缝的体验: 你输入语音,系统会用合成的声音进行回复。 该项目利用 Hugging Face 社区中的 Transformers 库提供的模型实现了流水话处理。该流程处  自推测解码是一种新颖的文本生成方法,它结合了推测解码 (Speculative Decoding) 的优势和大语言模型 (LLM) 的提前退出 (Early Exit) 机制。该方法出自论文 LayerSkip: Enabling Early-Exit Inference and Self-Spec
自推测解码是一种新颖的文本生成方法,它结合了推测解码 (Speculative Decoding) 的优势和大语言模型 (LLM) 的提前退出 (Early Exit) 机制。该方法出自论文 LayerSkip: Enabling Early-Exit Inference and Self-Spec  奖励模型相关内容 这是 让 LLM 来评判 系列文章的第五篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 什么是奖励模型? 奖励模型通过学习人工标注的成对 prompt 数据来预测分数,优化目标是对齐人类偏好。
奖励模型相关内容 这是 让 LLM 来评判 系列文章的第五篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 什么是奖励模型? 奖励模型通过学习人工标注的成对 prompt 数据来预测分数,优化目标是对齐人类偏好。  评估你的评估结果 这是 让 LLM 来评判 系列文章的第三篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 在生产中或大规模使用 LLM 评估模型之前,你需要先评估它在目标任务的表现效果如何,确保它的评分跟期望的
评估你的评估结果 这是 让 LLM 来评判 系列文章的第三篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 在生产中或大规模使用 LLM 评估模型之前,你需要先评估它在目标任务的表现效果如何,确保它的评分跟期望的  浙公网安备 33010602011771号
浙公网安备 33010602011771号