Cosmopedia: 如何为预训练构建大规模合成数据集
本文概述了我们在生成含数十亿词元的合成数据集以复现 Phi-1.5 过程中所遇到的挑战及其解决方案,由此最终创建了 Cosmopedia 合成数据集。合成数据已成为机器学习社区的 C 位话题,其题中之义是用人工 (如使用大语言模型 (LLM)) 生成的数据模拟真实数据。
传统上,构建用于有监督微调和指令微调的数据集需要昂贵且耗时的人工标注。这种做法需要大量资源,因此注定只有少数玩家玩得起。然而,最近情况发生了变化。我们已经见证了数百个高质量的合成微调数据集,它们主要由 GPT-3.5 和 GPT-4 生成。大家还在社区发表了大量的材料以指导相关的各种流程并解决相应挑战 [1][2][3][4][5]。
图 1: Hugging Face Hub 上带有合成数据标签的数据集
然而,本文无意于成为另一篇如何生成合成指令微调数据集的文章,关于此社区已经有大量文章了。我们的专注点是如何将样本从 几千 扩展到 数百万,从而使其可用于 从头开始预训练 LLM。到达成这一愿景,需要解决一系列独特的挑战。
何以 Cosmopedia?
微软通过 Phi 系列模型 [6][7][8] 推动了合成数据领域的发展,这些模型主要由合成数据的训练而得。Phi 系列模型的表现超越了基于网络数据集的、训练时长更长的大模型。Phi-2 过去一个月的下载量超过 61.7 万次,是 Hugging Face Hub 上最受欢迎的 20 个模型之一。
虽然 Phi 模型的技术报告 (如 Textbooks Are All You Need ) 已详述了模型的卓越性能及训练过程,但其跳过了有关如何获得合成训练数据集的重要细节。此外,数据集本身也并未发布。这引发了狂热派和怀疑派之间的争论: 一些人给模型能力点赞,而批评者则认为它们可能只是过拟合了基准罢了; 甚至还有一些人认为在合成数据上预训练模型是 “垃圾入,垃圾出”。抛开这些不谈,完全控制数据生成过程并复现 Phi 模型的高性能的想法本身就很有趣且值得探索。
以上就是开发 Cosmopedia 的动机,其目的是重现 Phi-1.5 所使用的训练数据。在本文中,我们会分享我们的初步发现,并讨论一些改进当前数据集的计划。我们深入研究了创建数据集的方法、提示整编的方法及相应的技术栈。 Cosmopedia 完全开放: 我们发布了端到端流水线 代码,数据集,以及一个在其上训练的 1B 模型,即 cosmo-1b。因此,社区可以重现我们的结果并在此基础上继续研究。
Cosmopedia 的幕后花絮
围绕在 Phi 数据集上的谜团除了我们对其如何创建的不甚了了之外,还有一个问题是其数据集的生成使用的是私有模型。为了解决这些问题,我们引入了 Cosmopedia,这是由 Mixtral-8x7B-Instruct-v0.1 生成的包含教科书、博文、故事、帖子以及 WikiHow 文章等各种体裁的合成数据集。其中有超过 3000 万个文件、250 亿个词元,是迄今为止最大的开放合成数据集。
请注意: 如果你期待读到一个如何在数百个 H100 GPU 上部署大规模生成任务的故事,那么你可能要失望了,因为实际上 Cosmopedia 的大部分时间都花在了细致的提示词工程上了。
提示策划
生成合成数据看起来可能很简单,但当要扩大数据规模时,保持多样性 (这对于获得最佳模型性能至关重要) 迅速成为一大挑战。因此,有必要策划主题广泛的多样化提示并最大程度地减少重复输出,因为我们不想花大量算力生成了数十亿本教科书,却因为它们彼此非常相似而需要丢弃掉大多数。在我们在数百个 GPU 上启动这一生成任务前,我们花了很多时间使用 HuggingChat 等工具来对提示进行迭代。在本节中,我们将回顾为 Cosmopedia 创建超过 3000 万条提示的过程,这些提示涵盖数百个主题且重复率低于 1%。
Cosmopedia 旨在生成大量主题广泛的高质量合成数据。据 Phi-1.5 技术报告 透露,他们策划了 2 万个主题,以生成总计 200 亿词元的合成教科书,同时他们还使用网络数据集中的样本来保证多样性,报告指出:
我们精心挑选了 2 万个主题来生成新的合成数据。在我们生成提示时,我们还使用了网络数据集中的样本来保证多样性。
假设文件的平均长度为 1000 词元,可以估计他们使用了大约 2000 万个不同的提示。然而,如何将主题和网络样本结合起来以增强多样性,报告并未透露。
我们结合了两种方法来构建 Cosmopedia 的提示: 根据精选来源构建以及根据网络数据构建。我们将我们依赖的这些数据源称为“种子数据”。
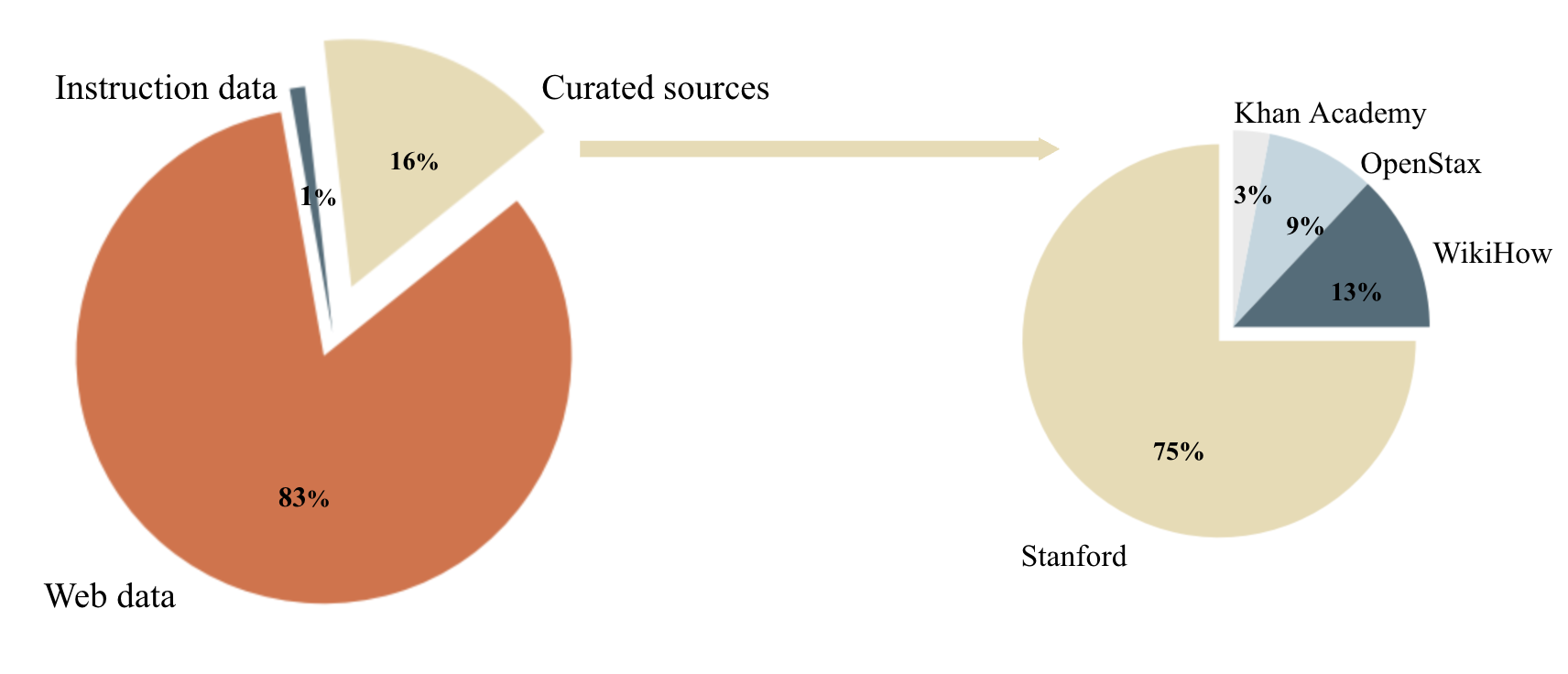
图 2: 用于构建 Cosmopedia 提示的数据源分布 (左图) 以及“精选源”子集中的源分布 (右图)
精选源
我们使用的主题主要来自知名教育源,例如斯坦福课程、可汗学院、OpenStax 和 WikiHow。这些资源涵盖了许多有价值的主题可供 LLM 学习。例如,我们提取了斯坦福大学各种课程的大纲,并据此构建了提示,要求模型为这些课程的各个单元生成教科书。图 3 展示了此类提示的示例。
尽管这种方法可以生成高质量的内容,但其可扩展性不是很好。我们受限于每个来源中的可用资源数量及主题类型。例如,从 OpenStax 中我们只能提取 16,000 个不同的单元,从斯坦福大学中只能提取 250,000 个。考虑到目标是生成 200 亿个词元,我们至少需要 2000 万个提示!
利用受众和风格的多样性
提高生成样本多样性的一种策略是利用受众和风格的多样性: 通过改变目标受众 (如,少儿/大学生) 及生成风格 (如,学术教科书/博文),来实现对一个主题的多次利用。然而,我们发现仅把 “为关于‘为什么进入太空?’的大学教科书编写详细的课程单元?” 的提示改成 “写一篇关于‘为什么去太空?’的详细博文” 或 “为少年儿童写一本关于‘为什么去太空?’的教科书” 并不足以降低内容重复率。为了缓解这种情况,我们在提示中强调了受众和风格的变化,并对格式和内容应如何不同进行了具体说明。
图 3 展示了我们是如何对同一主题针对不同受众调整提示的。

图 3: 为少儿、专业人士和研究人员以及高中生生成相同主题的教科书的提示
通过针对四种不同的受众 (少儿、高中生、大学生、研究人员) 以及三种生成风格 (教科书、博文、wikiHow 文章),我们可以获得最多 12 倍的提示。然而,我们可能希望在训练数据集中包含这些资源未涵盖的其他主题,再者这些资源的数量还是有点小,即使用了我们提出的提示扩增的方法,距离我们目标的 2 千多万条提示还很远。这时候网络数据就派上用场了,那如果我们要生成涵盖所有网络主题的教科书怎么办?在下一节中,我们将解释如何选择主题并使用网络数据来构建数百万提示。
网络数据
我们的实践表明,使用网络数据构建提示扩展性最好,Cosmopedia 使用的 80% 以上的提示来自于此。我们使用 RefinedWeb 等数据集将数百万个 Web 样本聚为 145 个簇,并从每个簇中提取 10 个随机样本的内容并要求 Mixtral 找到它们的共同主题以最终识别该簇的主题。有关聚类环节的更多详细信息,请参阅技术栈部分。
我们检查了这些簇并排除了任何我们认为教育价值较低的簇,剔除的内容如露骨的成人材料、名人八卦和讣告等。你可于 此处 获取保留和剔除的 112 个主题的完整列表。
然后,我们构建提示以指示模型根据网络示例所在簇的主题生成相应的教科书。图 4 展示了基于网络数据的提示的示例。为了提高多样性并解决主题标签的不完整性,我们仅以 50% 的概率在提示内说明主题,并更改受众和生成风格,如上一节所述。最终,我们使用这种方法构建了 2300 万条提示。图 5 展示了 Cosmopedia 中种子数据、生成格式和受众的最终分布。

图 4: 网络数据种子样本及其对应提示的示例
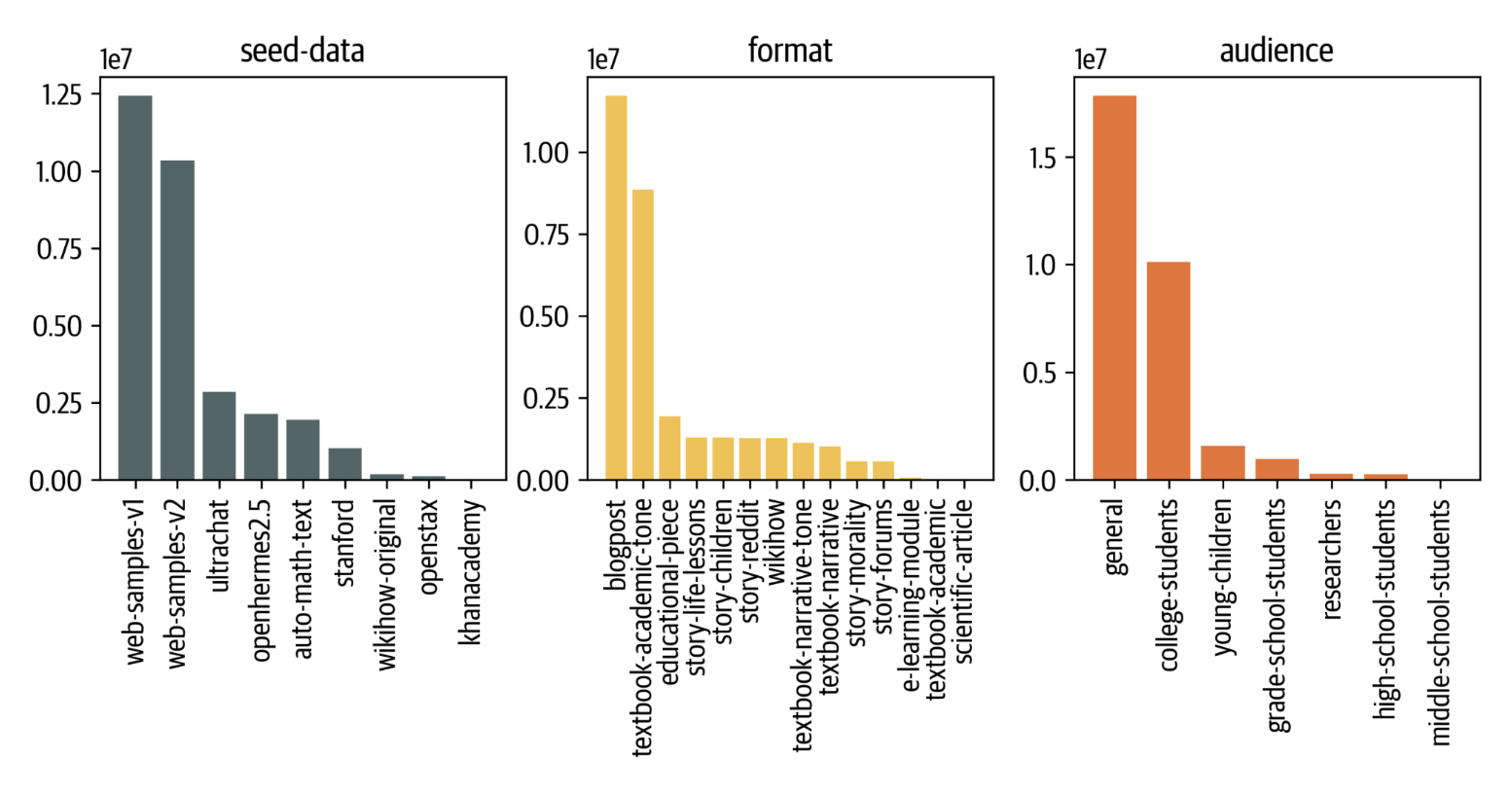
图 5: Cosmopedia 数据集中种子数据、生成格式和目标受众的分布
除了随机网络数据之外,为了包含更多科学内容,我们还使用了 AutoMathText 中的样本,其是一个精心设计的数学文本数据集。
指令数据集与故事
在我们对生成的合成数据集训得的模型进行初步评估时,我们发现其缺乏小学教育阶段所需的典型常识和基础知识。为了解决这一问题,我们增加了 UltraChat 和 OpenHermes2.5 指令微调数据集作为提示的种子数据。这些数据集涵盖了广泛的主题,如在 UltraChat 中,我们使用了“关于世界的问题”子集,其中涵盖了 30 个关于世界的元概念; 而对另一个多样化且高质量的指令调优数据集 OpenHermes2.5 ,我们跳过了不适合讲故事的来源和类别,例如用于编程的 glaive-code-assist 和用于高级化学的 camala 。图 6 展示了我们用来生成这些故事的提示示例。

图 6: 从 UltraChat 和 OpenHermes 样本中构建的用于生成故事的提示 (分别针对少儿、普通受众及 Reddit 论坛)
我们的提示工程故事就至此就告一段落了,我们构建了 3000 多万个不同的提示,这些提示的内容几乎没有重复。下图展示了 Cosmopedia 中的数据簇,这种分布与网络数据中的簇分布类似。你还可以从 Nomic 中找到可互动的 可视化数据地图。
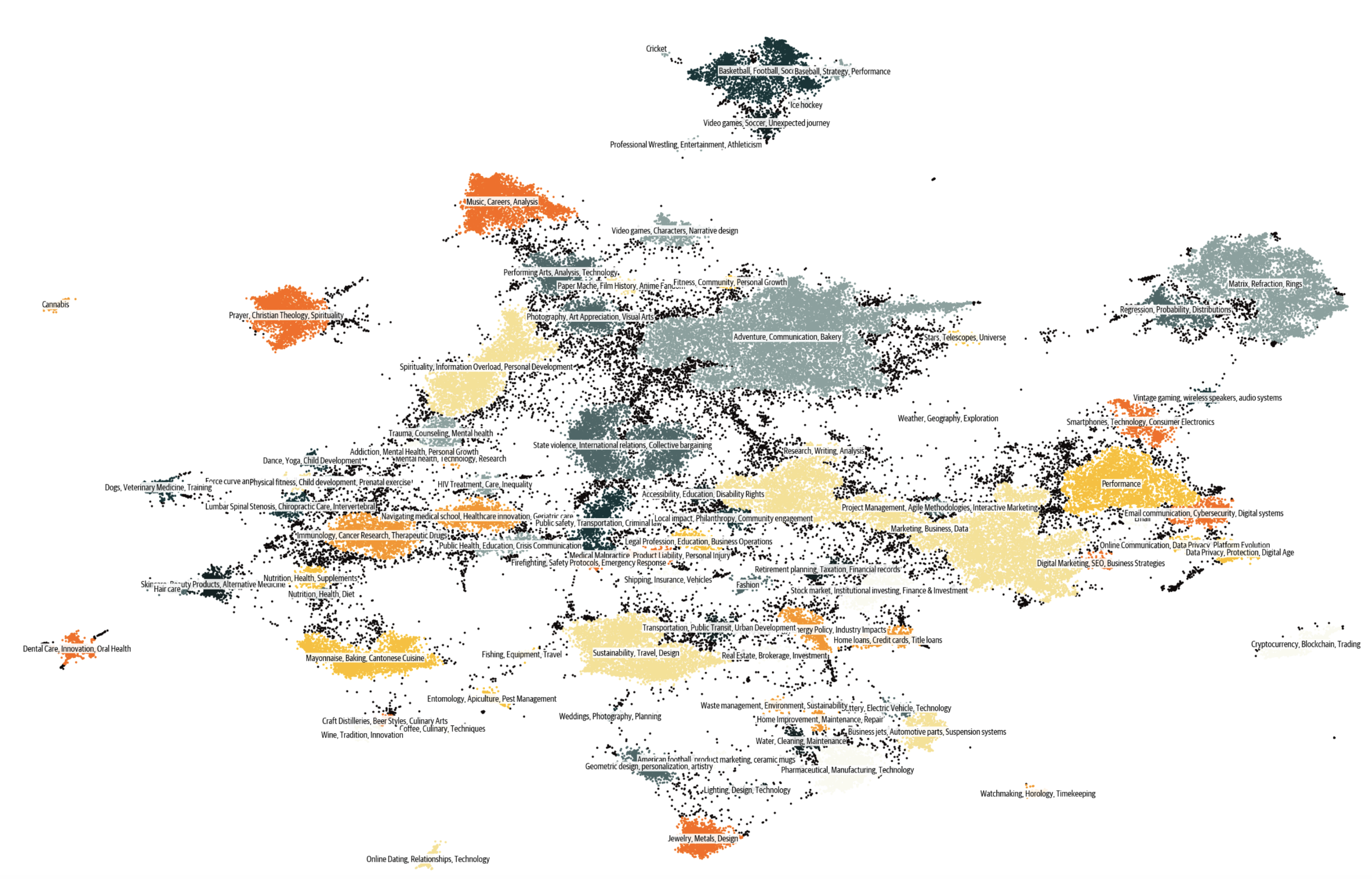
图 7: Cosmopedia 的簇,主题由 Mixtral 生成
你还可以使用 数据集查看器 自行探索数据集:
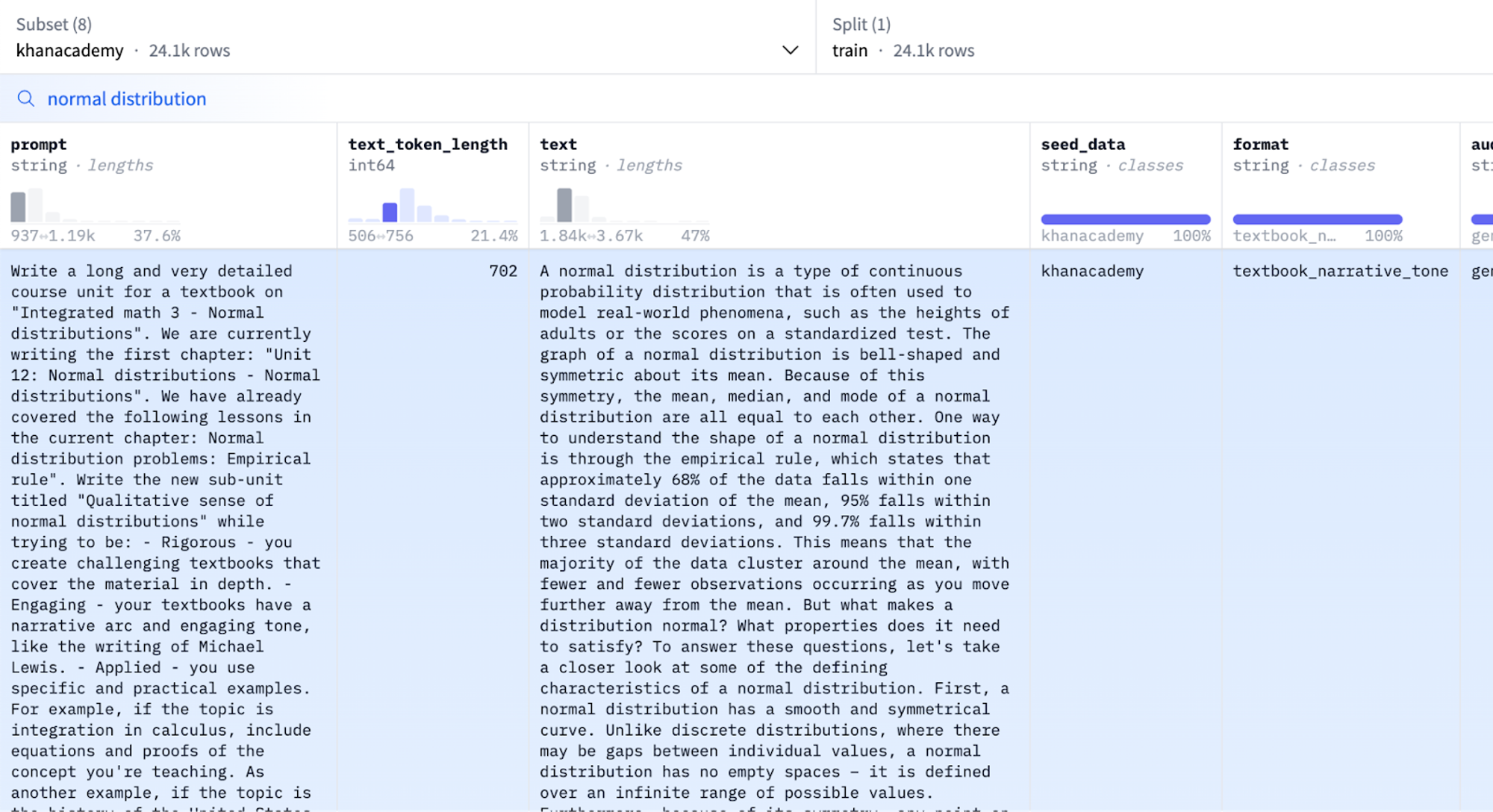
图 8: Cosmopedia 的数据集查看器
技术栈
我们在 此 发布了用于构建 Cosmopedia 的所有代码。
本节,我们将重点介绍用于文本聚类、大规模文本生成和训练 cosmo-1b 模型的技术栈。
主题聚类
我们使用 text-clustering 代码库来对 Cosmopedia 提示中使用的网络数据进行主题聚类。下图说明了聚类及对生成的簇进行标注的流程。我们还要求 Mixtral 在标注时为簇打一个教育性得分 (满分 10 分) ; 这有助于后面我们进行主题检查。你可以在此 演示 中找到网络数据的每个簇及其得分。
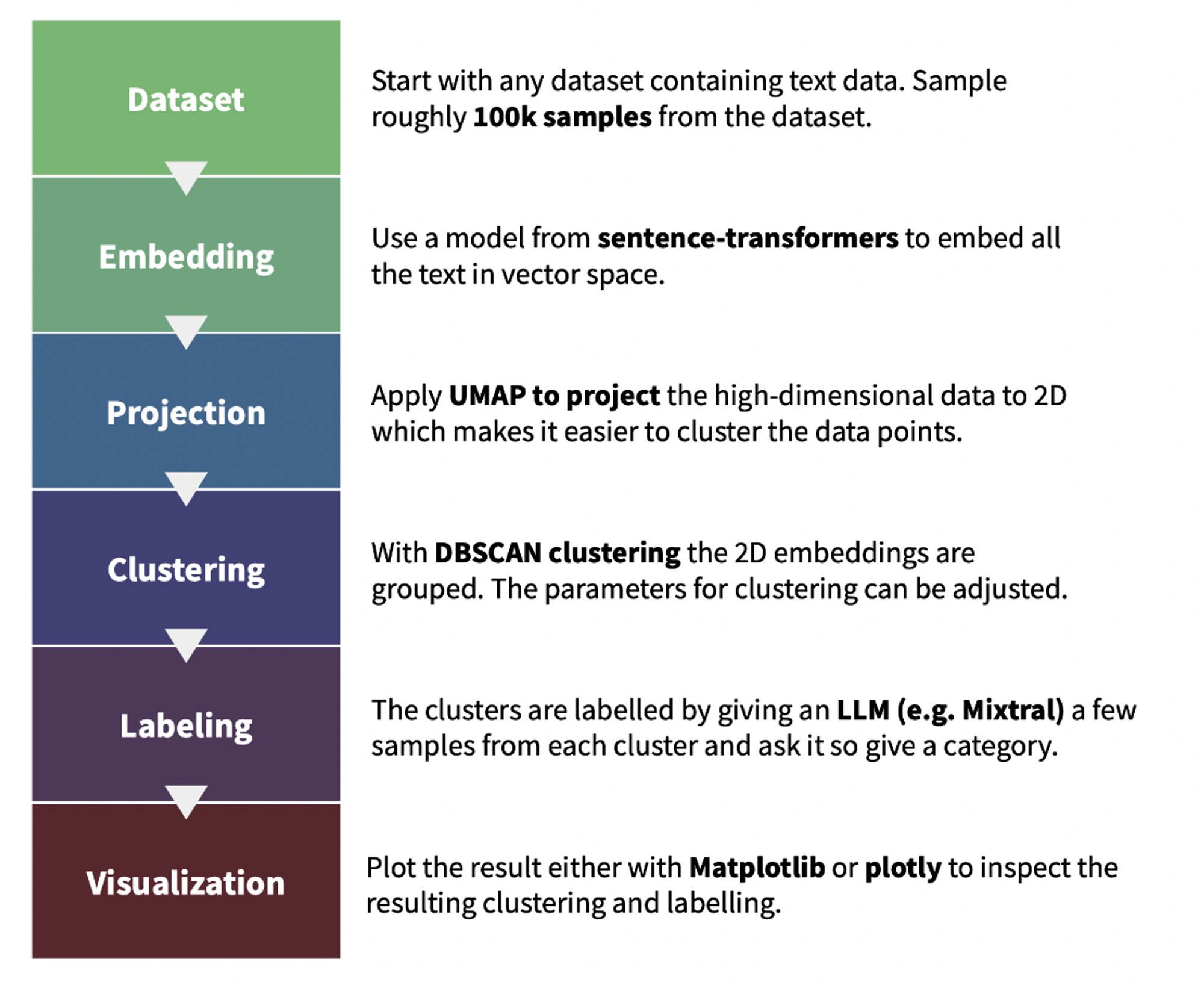
图 9: 文本聚类的流程
大规模教科书生成
我们用 llm-swarm 库使用 Mixtral-8x7B-Instruct-v0.1 生成 250 亿个合成内容词元。这是一个可扩展的合成数据生成工具,支持本地 LLM 以及 Hugging Face Hub 上的推理终端。它还支持 TGI 和 vLLM 推理库。我们使用 TGI 在 Hugging Face Science 集群的 H100 GPU 上本地部署 Mixtral-8x7B。生成 Cosmopedia 的总计算时间超过 1 万 GPU 时。
以下是在 Slurm 集群上使用 2 个 TGI 实例在 100k Cosmopedia 提示上使用 Mixtral 生成教科书的示例:
# clone the repo and follow installation requirements
cd llm-swarm
python ./examples/textbooks/generate_synthetic_textbooks.py \
--model mistralai/Mixtral-8x7B-Instruct-v0.1 \
--instances 2 \
--prompts_dataset "HuggingFaceTB/cosmopedia-100k" \
--prompt_column prompt \
--max_samples -1 \
--checkpoint_path "./tests_data" \
--repo_id "HuggingFaceTB/generations_cosmopedia_100k" \
--checkpoint_interval 500
你甚至可以使用 wandb 跟踪生成过程,以监控吞吐量和生成的词元数。
图 10: llm-swarm 的 wandb 图
注意:
我们使用 HuggingChat 对提示进行初始迭代。我们使用 llm-swarm 为每个提示生成数百个样本以检查生成的样本是否有异常及其异常模式。比如说,模型在为多个教科书生成了非常相似的介绍性短语,并且经常以相同的短语开头,如“很久很久以前”以及“太阳低垂在天空中”。我们在迭代后的提示中明确要求模型避免这些介绍性陈述并要求其创造性解决问题,基于这些提示,虽然仍会出现上述情况,但概率很低。
基准去污
鉴于种子样本或模型的训练数据中可能存在基准污染,我们实现了一个净化流水线,以确保我们的数据集不含测试基准中的任何样本。
与 Phi-1 类似,我们使用 10- 词元重叠率来识别潜在污染的样本。从数据集中检索到候选样本后,我们使用 difflib.SequenceMatcher 将其与基准样本进行比较。如果 len(matched_substrings) 与 len(benchmark_sample) 的比率超过 0.5,我们将丢弃该样本。我们对 Cosmo-1B 模型所有评估基准都实施了此净化,包括 MMLU、HellaSwag、PIQA、SIQA、Winogrande、OpenBookQA、ARC-Easy 以及 ARC-Challenge。
下表汇总了我们从每个数据子集中删除的受污染样本的数量,以及它们对应的基准样本数 (见括号):
| 数据集 | ARC | BoolQ | HellaSwag | PIQA |
|---|---|---|---|---|
| 网络数据 + 斯坦福 + openstax | 49 (16) | 386 (41) | 6 (5) | 5 (3) |
| auto_math_text + 可汗学院 | 17 (6) | 34 (7) | 1 (1) | 0 (0) |
| 故事 | 53 (32) | 27 (21) | 3 (3) | 6 (4) |
我们发现与 MMLU、OpenBookQA 和 WinoGrande 重合的受污染样本少于 4 个。
训练软件栈
我们在 Cosmopedia 上使用 Llama2 架构训练了一个 1B LLM,以评估 Cosmopedia 的质量。
我们用 datatrove 进行数据去重及分词,用 nanotron 进行模型训练,用 lighteval 进行评估。
该模型在 ARC-easy、ARC-challenge、OpenBookQA 和 MMLU 上的性能优于 TinyLlama 1.1B,在 ARC-challenge 和 OpenBookQA 上与 Qwen-1.5-1B 相当。然而,我们注意到其与 Phi-1.5 的性能相比仍存在一些差距,这表明我们仍有空间改善合成数据的质量,这可能与用于生成的 LLM、主题覆盖度或提示有关。
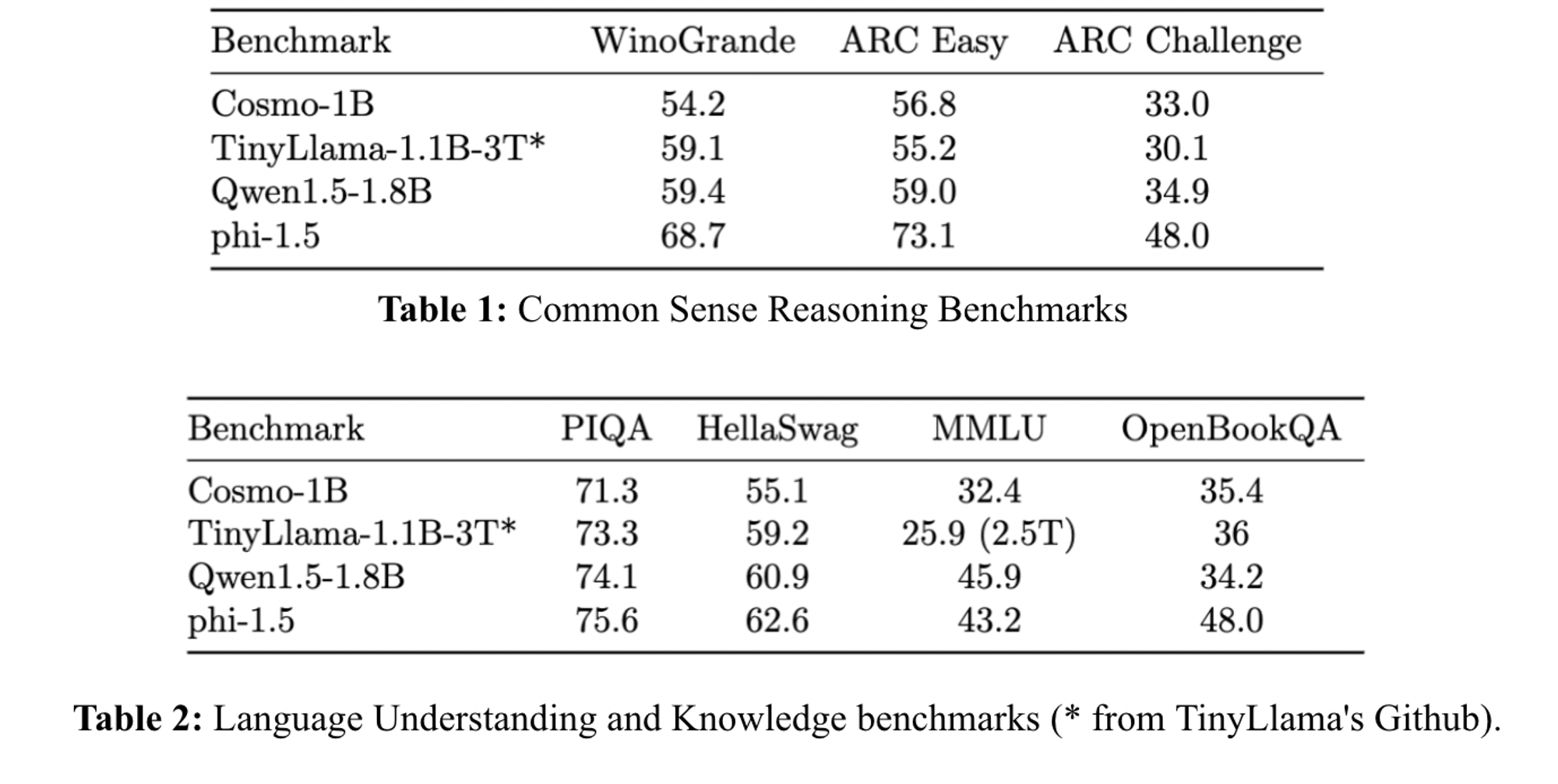
图 10: Cosmo-1B 的评估结果
结论及下一步
本文,我们概述了创建 Cosmopedia 的方法,Cosmopedia 是一个专为模型预训练而设计的大型合成数据集,其目标对 Phi 模型进行复现。我们强调了精心制作提示以涵盖广泛主题、确保生成多样化内容的重要性。此外,我们还共享并开源了我们的技术栈,从而可将该生成过程扩展至数百个 GPU。
然而,这只是 Cosmopedia 的初始版本,我们正在积极努力提高生成内容的质量。生成的准确性和可靠性很大程度上取决于生成时使用的模型。举个例子,Mixtral 有时可能会产生幻觉并产生不正确的信息,例如,当涉及 AutoMathText 和可汗学院数据集中的历史事实或数学推理相关主题时,Mixtral 就会产生幻觉。缓解幻觉的一种策略是使用检索增强生成 (RAG),这包含检索与种子样本相关的信息 (如从维基百科),并将其合并至上下文中。幻觉度量还可以帮助评估哪些主题或领域受幻觉的影响最大 [9]。将 Mixtral 的生成内容与其他开放模型进行比较也很有趣。
合成数据潜力巨大,我们渴望看到社区在 Cosmopedia 之玩些花头出来。
参考文献
[1] Ding et al. Enhancing Chat Language Models by Scaling High-quality Instructional Conversations
[2] Wei et al. Magicoder: Source Code Is All You Need
[3] Toshniwal et al. OpenMathInstruct-1: A 1.8 Million Math Instruction Tuning Dataset
[4] Xu et al. WizardLM: Empowering Large Language Models to Follow Complex Instructions
[5] Moritz Laurer Synthetic data: save money, time and carbon with open source
[6] Gunasekar et al. Textbooks Are All You Need
[7] Li et al. Textbooks are all you need ii: phi-1.5 technical report
[8] Phi-2 博文
[9] Manakul, Potsawee and Liusie, Adian and Gales, Mark JF Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models
英文原文:
https://hf.co/blog/cosmopedia 原文作者: Loubna Ben Allal,Anton Lozhkov,Daniel van Strien
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号