利用 🤗 Optimum Intel 和 fastRAG 在 CPU 上优化文本嵌入
嵌入模型在很多场合都有广泛应用,如检索、重排、聚类以及分类。近年来,研究界在嵌入模型领域取得了很大的进展,这些进展大大提高了基于语义的应用的竞争力。BGE、GTE 以及 E5 等模型在 MTEB 基准上长期霸榜,在某些情况下甚至优于私有的嵌入服务。 Hugging Face 模型 hub 提供了多种尺寸的嵌入模型,从轻量级 (100-350M 参数) 到 7B (如 Salesforce/SFR-Embedding-Mistral ) 一应俱全。不少基于语义搜索的应用会选用基于编码器架构的轻量级模型作为其嵌入模型,此时,CPU 就成为运行这些轻量级模型的有力候选,一个典型的场景就是 检索增强生成 (Retrieval Augmented Generation,RAG)。
使用嵌入模型进行信息检索
嵌入模型把文本数据编码为稠密向量,这些稠密向量中浓缩了文本的语义及上下文信息。这种上下文相关的单词和文档表征方式使得我们有可能实现更准确的信息检索。通常,我们可以用嵌入向量之间的余弦相似度来度量文本间的语义相似度。
在信息检索中是否仅依赖稠密向量就可以了?这需要一定的权衡:
- 稀疏检索通过把文本集建模成 n- 元组、短语或元数据的集合,并通过在集合上进行高效、大规模的搜索来实现信息检索。然而,由于查询和文档在用词上可能存在差异,这种方法有可能会漏掉一些相关的文档。
- 语义检索将文本编码为稠密向量,相比于词袋,其能更好地捕获上下文及词义。此时,即使用词上不能精确匹配,这种方法仍然可以检索出语义相关的文档。然而,与 BM25 等词匹配方法相比,语义检索的计算量更大,延迟更高,并且需要用到复杂的编码模型。
嵌入模型与 RAG
嵌入模型在 RAG 应用的多个环节中均起到了关键的作用:
- 离线处理: 在生成或更新文档数据库的索引时,要用嵌入模型将文档编码为稠密向量。
- 查询编码: 在查询时,要用嵌入模型将输入查询编码为稠密向量以供后续检索。
- 重排: 首轮检索出初始候选文档列表后,要用嵌入模型将检索到的文档编码为稠密向量并与查询向量进行比较,以完成重排。
可见,为了让整个应用更高效,优化 RAG 流水线中的嵌入模型这一环节非常必要,具体来说:
- 文档索引/更新: 追求高吞吐,这样就能更快地对大型文档集进行编码和索引,从而大大缩短建库和更新耗时。
- 查询编码: 较低的查询编码延迟对于检索的实时性至关重要。更高的吞吐可以支持更高查询并发度,从而实现高扩展度。
- 对检索到的文档进行重排: 首轮检索后,嵌入模型需要快速对检索到的候选文档进行编码以支持重排。较低的编码延迟意味着重排的速度会更快,从而更能满足时间敏感型应用的要求。同时,更高的吞吐意味着可以并行对更大的候选集进行重排,从而使得更全面的重排成为可能。
使用 Optimum Intel 和 IPEX 优化嵌入模型
Optimum Intel 是一个开源库,其针对英特尔硬件对使用 Hugging Face 库构建的端到端流水线进行加速和优化。 Optimum Intel 实现了多种模型加速技术,如低比特量化、模型权重修剪、蒸馏以及运行时优化。
Optimum Intel 在优化时充分利用了英特尔® 先进矢量扩展 512 (英特尔® AVX-512) 、矢量神经网络指令 (Vector Neural Network Instructions,VNNI) 以及英特尔® 高级矩阵扩展 (英特尔® AMX) 等特性以加速模型的运行。具体来说,每个 CPU 核中都内置了 BFloat16 ( bf16 ) 和 int8 GEMM 加速器,以加速深度学习训练和推理工作负载。除了针对各种常见运算的优化之外,PyTorch 2.0 和 Intel Extension for PyTorch (IPEX) 中还充分利用了 AMX 以加速推理。
使用 Optimum Intel 可以轻松优化预训练模型的推理任务。你可在 此处 找到很多简单的例子。
示例: 优化 BGE 嵌入模型
本文,我们主要关注 北京人工智能研究院 的研究人员最近发布的嵌入模型,它们在广为人知的 MTEB 排行榜上取得了亮眼的排名。
BGE 技术细节
双编码器模型基于 Transformer 编码器架构,其训练目标是最大化两个语义相似的文本的嵌入向量之间的相似度,常见的指标是余弦相似度。举个常见的例子,我们可以使用 BERT 模型作为基础预训练模型,并对其进行微调以生成嵌入模型从而为文档生成嵌入向量。有多种方法可用于根据模型输出构造出文本的嵌入向量,例如,可以直接取 [CLS] 词元的嵌入向量,也可以对所有输入词元的嵌入向量取平均值。
双编码器模型是个相对比较简单的嵌入编码架构,其仅针对单个文档上下文进行编码,因此它们无法对诸如 查询 - 文档 及 文档 - 文档 这样的交叉上下文进行编码。然而,最先进的双编码器嵌入模型已能表现出相当有竞争力的性能,再加上因其架构简单带来的极快的速度,因此该架构的模型成为了当红炸子鸡。
这里,我们主要关注 3 个 BGE 模型: small、base 以及 large,它们的参数量分别为 45M、110M 以及 355M,嵌入向量维度分别为 384、768 以及 1024。
请注意,下文展示的优化过程是通用的,你可以将它们应用于任何其他嵌入模型 (包括双编码器模型、交叉编码器模型等)。
模型量化分步指南
下面,我们展示如何提高嵌入模型在 CPU 上的性能,我们的优化重点是降低延迟 (batch size 为 1) 以及提高吞吐量 (以每秒编码的文档数来衡量)。我们用 optimum-intel 和 INC (Intel Neural Compressor) 对模型进行量化,并用 IPEX 来优化模型在 Intel 的硬件上的运行时间。
第 1 步: 安装软件包
请运行以下命令安装 optimum-intel 和 intel-extension-for-transformers :
pip install -U optimum[neural-compressor] intel-extension-for-transformers
第 2 步: 训后静态量化
训后静态量化需要一个校准集以确定权重和激活的动态范围。校准时,模型会运行一组有代表性的数据样本,收集统计数据,然后根据收集到的信息量化模型以最大程度地降低准确率损失。
以下展示了对模型进行量化的代码片段:
def quantize(model_name: str, output_path: str, calibration_set: "datasets.Dataset"):
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
def preprocess_function(examples):
return tokenizer(examples["text"], padding="max_length", max_length=512, truncation=True)
vectorized_ds = calibration_set.map(preprocess_function, num_proc=10)
vectorized_ds = vectorized_ds.remove_columns(["text"])
quantizer = INCQuantizer.from_pretrained(model)
quantization_config = PostTrainingQuantConfig(approach="static", backend="ipex", domain="nlp")
quantizer.quantize(
quantization_config=quantization_config,
calibration_dataset=vectorized_ds,
save_directory=output_path,
batch_size=1,
)
tokenizer.save_pretrained(output_path)
本例中,我们使用 qasper 数据集的一个子集作为校准集。
第 2 步: 加载模型,运行推理
仅需运行以下命令,即可加载量化模型:
from optimum.intel import IPEXModel
model = IPEXModel.from_pretrained("Intel/bge-small-en-v1.5-rag-int8-static")
随后,我们使用 transformers 的 API 将句子编码为向量:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Intel/bge-small-en-v1.5-rag-int8-static")
inputs = tokenizer(sentences, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# get the [CLS] token
embeddings = outputs[0][:, 0]
我们将在随后的模型评估部分详细说明如何正确配置 CPU 以获得最佳性能。
使用 MTEB 进行模型评估
将模型的权重量化到较低的精度会导致准确度的损失,因为在权重从 fp32 转换到 int8 的过程中会损失精度。所以,我们在如下两个 MTEB 任务上对量化模型与原始模型进行比较以验证量化模型的准确度到底如何:
- 检索 - 对语料库进行编码,并生成索引库,然后在索引库中搜索给定查询,以找出与给定查询相似的文本并排序。
- 重排 - 对检索结果进行重排,以细化与给定查询的相关性排名。
下表展示了每个任务在多个数据集上的平均准确度 (其中,MAP 用于重排,NDCG@10 用于检索),表中 int8 表示量化模型, fp32 表示原始模型 (原始模型结果取自官方 MTEB 排行榜)。与原始模型相比,量化模型在重排任务上的准确度损失低于 1%,在检索任务中的准确度损失低于 1.55%。
| 重排 | 检索 | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
速度与延迟
我们用量化模型进行推理,并将其与如下两种常见的模型推理方法进行性能比较:
- 使用 PyTorch 和 Hugging Face 的
transformers库以bf16精度运行模型。 - 使用 IPEX 以
bf16精度运行模型,并使用 torchscript 对模型进行图化。
实验环境配置:
- 硬件 (CPU): 第四代 Intel 至强 8480+,整机有 2 路 CPU,每路 56 个核。
- 对 PyTorch 模型进行评估时仅使用单路 CPU 上的 56 个核。
- IPEX/Optimum 测例使用 ipexrun、单路 CPU、使用的核数在 22-56 之间。
- 所有测例 TCMalloc,我们安装并妥善设置了相应的环境变量以保证用到它。
如何运行评估?
我们写了一个基于模型的词汇表生成随机样本的脚本。然后分别加载原始模型和量化模型,并比较了它们在上述两种场景中的编码时间: 使用单 batch size 度量编码延迟,使用大 batch size 度量编码吞吐。
- 基线 - 用 PyTorch 及 Hugging Face 运行
bf16模型:
import torch
from transformers import AutoModel
model = AutoModel.from_pretrained("BAAI/bge-small-en-v1.5")
@torch.inference_mode()
def encode_text():
outputs = model(inputs)
with torch.cpu.amp.autocast(dtype=torch.bfloat16):
encode_text()
- 用 IPEX torchscript 运行
bf16模型:
import torch
from transformers import AutoModel
import intel_extension_for_pytorch as ipex
model = AutoModel.from_pretrained("BAAI/bge-small-en-v1.5")
model = ipex.optimize(model, dtype=torch.bfloat16)
vocab_size = model.config.vocab_size
batch_size = 1
seq_length = 512
d = torch.randint(vocab_size, size=[batch_size, seq_length])
model = torch.jit.trace(model, (d,), check_trace=False, strict=False)
model = torch.jit.freeze(model)
@torch.inference_mode()
def encode_text():
outputs = model(inputs)
with torch.cpu.amp.autocast(dtype=torch.bfloat16):
encode_text()
- 用基于 IPEX 后端的 Optimum Intel 运行
int8模型:
import torch
from optimum.intel import IPEXModel
model = IPEXModel.from_pretrained("Intel/bge-small-en-v1.5-rag-int8-static")
@torch.inference_mode()
def encode_text():
outputs = model(inputs)
encode_text()
延迟性能
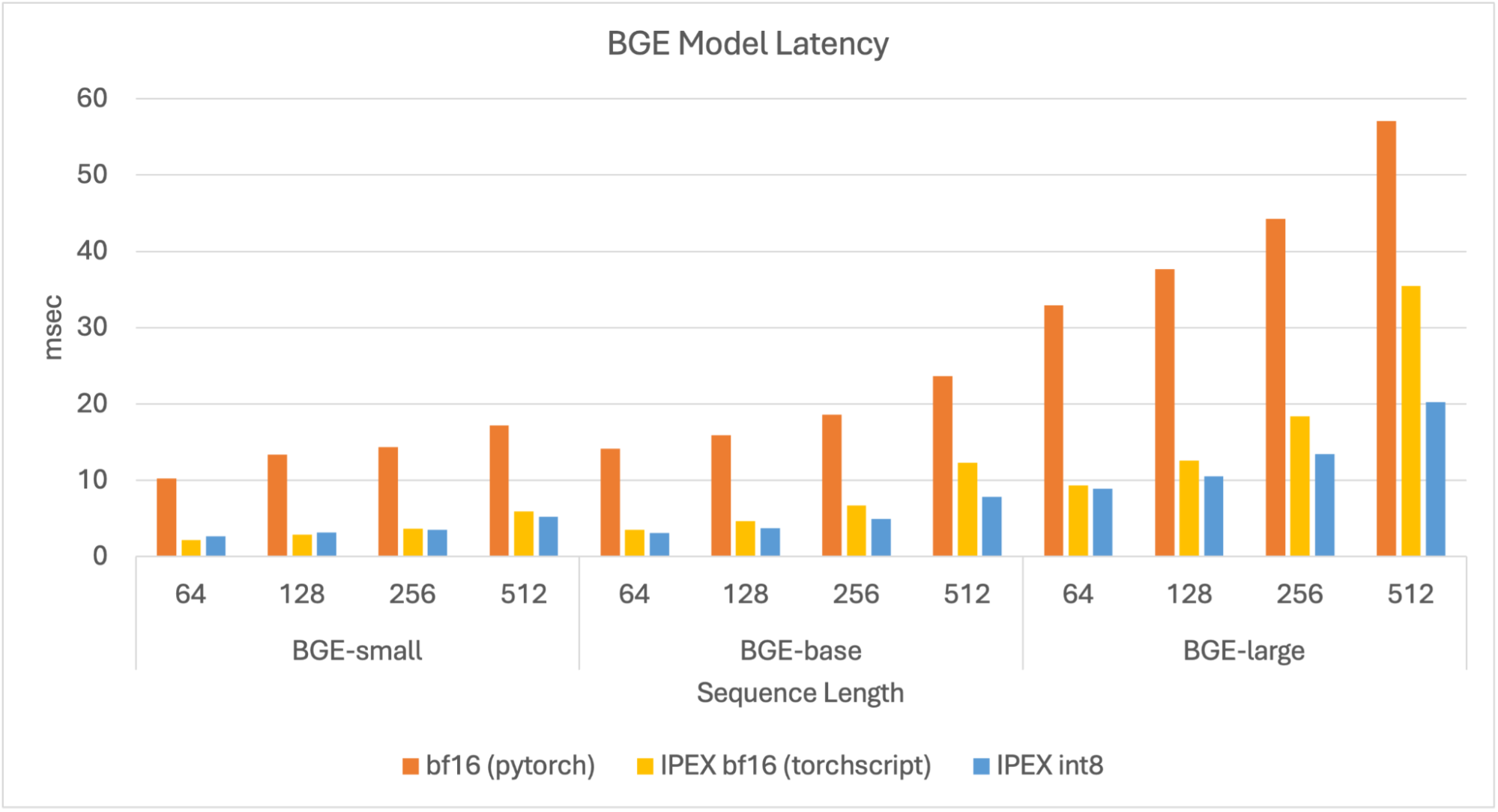
这里,我们主要测量模型的响应速度,这关系到 RAG 流水线中对查询进行编码的速度。此时,我们将 batch size 设为 1,并测量在各种文档长度下的延迟。
我们可以看到,总的来讲,量化模型延迟最小,其中 small 模型和 base 模型的延迟低于 10 毫秒, large 模型的延迟低于 20 毫秒。与原始模型相比,量化模型的延迟提高了 4.5 倍。
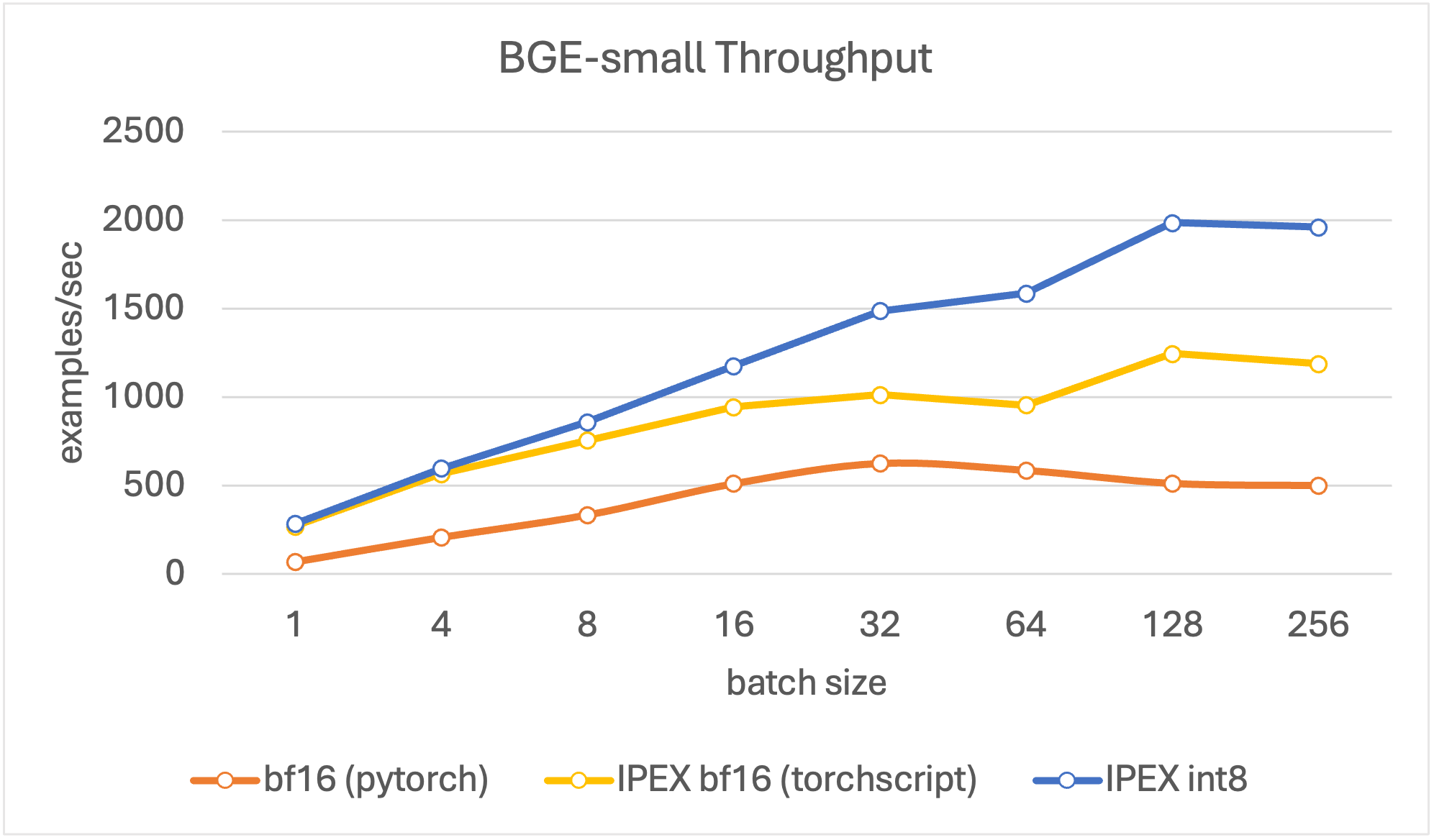
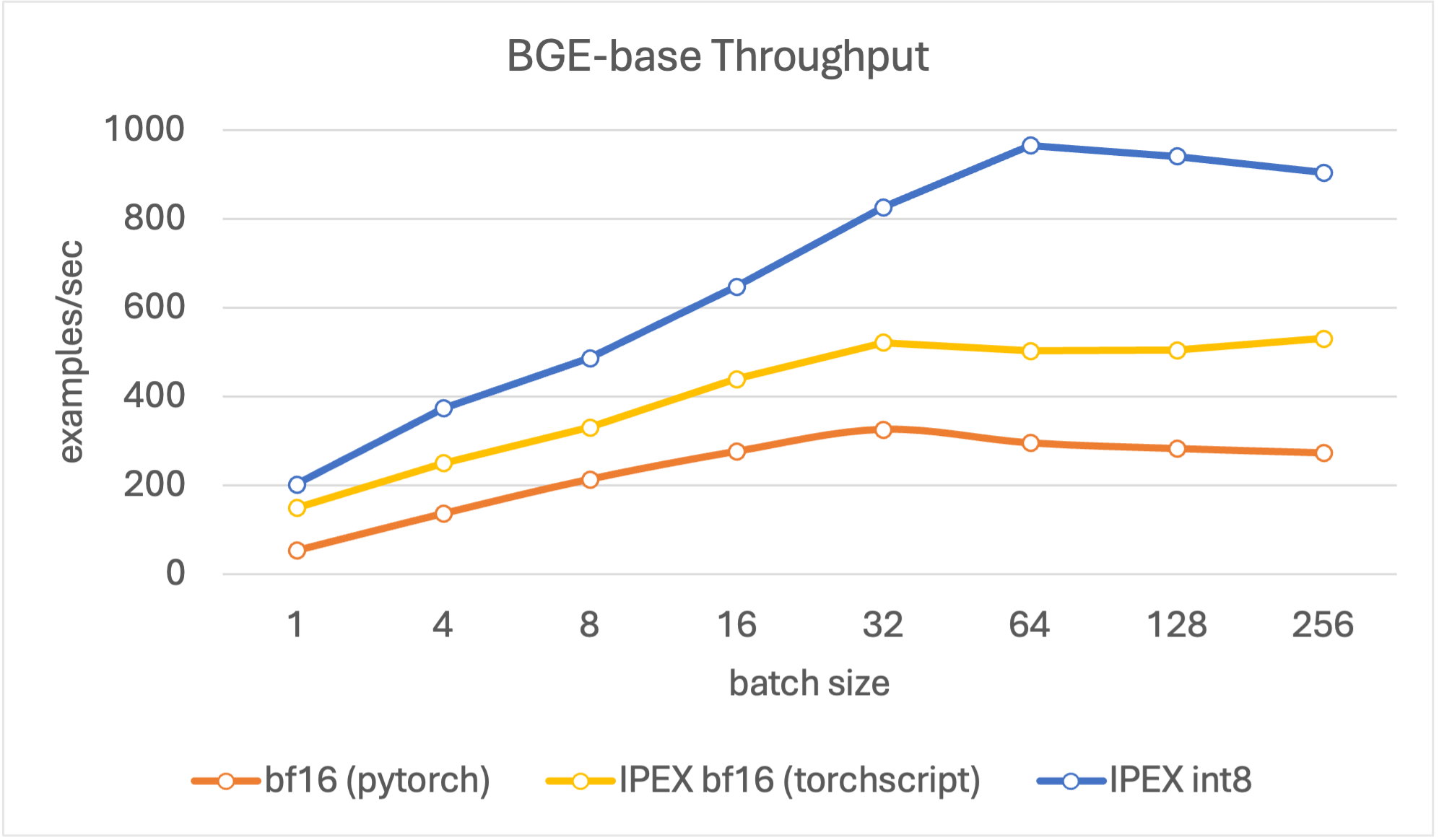
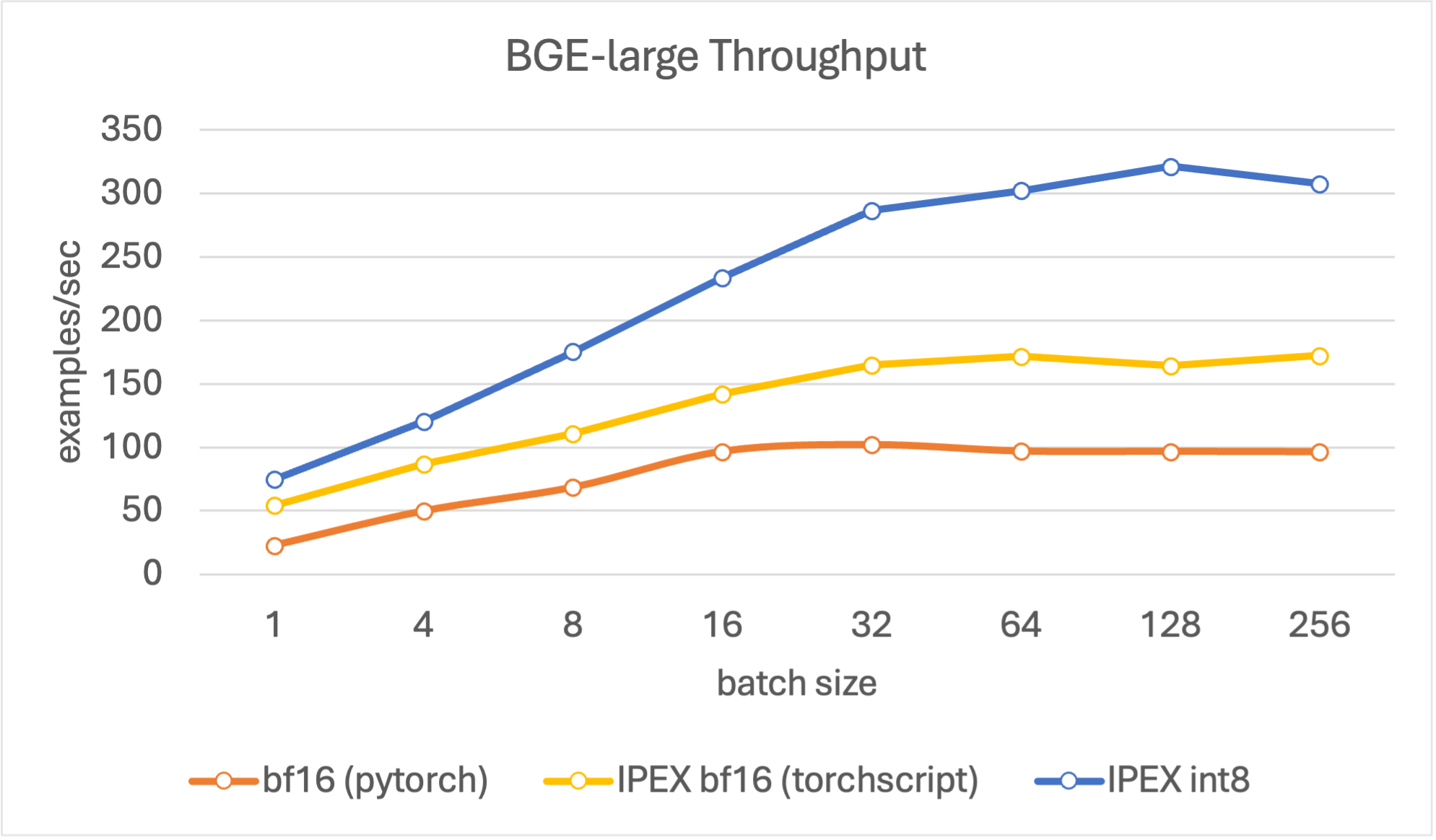
吞吐性能
在评估吞吐时,我们的目标是寻找峰值编码性能,其单位为每秒处理文档数。我们将文本长度设置为 256 个词元,这个长度能较好地代表 RAG 流水线中的平均文档长度,同时我们在不同的 batch size (4、8、16、32、64、128、256) 上进行评估。
结果表明,与其他模型相比,量化模型吞吐更高,且在 batch size 为 128 时达到峰值。总体而言,对于所有尺寸的模型,量化模型的吞吐在各 batch size 上均比基线 bf16 模型高 4 倍左右。
在 fastRAG 中使用量化嵌入模型
我们通过一个例子来演示如何将优化后的检索/重排模型集成进 fastRAG 中 (你也可以很轻松地将其集成到其他 RAG 框架中,如 Langchain 及 LlamaIndex) 。
fastRAG 是一个高效且优化的检索增强生成流水线研究框架,其可与最先进的 LLM 和信息检索算法结合使用。fastRAG 与 Haystack 完全兼容,并实现了多种新的、高效的 RAG 模块,可高效部署在英特尔硬件上。
大家可以参考 此说明 安装 fastRAG,并阅读我们的 指南 以开始 fastRAG 之旅。
我们需要将优化的双编码器嵌入模型用于下述两个模块中:
QuantizedBiEncoderRetriever– 用于创建稠密向量索引库,以及从建好的向量库中检索文档QuantizedBiEncoderRanker– 在对文档列表进行重排的流水线中需要用到嵌入模型。
使用优化的检索器实现快速索引
我们用基于量化嵌入模型的稠密检索器来创建稠密索引。
首先,创建一个文档库:
from haystack.document_store import InMemoryDocumentStore
document_store = InMemoryDocumentStore(use_gpu=False, use_bm25=False, embedding_dim=384, return_embedding=True)
接着,向其中添加一些文档:
from haystack.schema import Document
# example documents to index
examples = [
"There is a blue house on Oxford Street.",
"Paris is the capital of France.",
"The first commit in fastRAG was in 2022"
]
documents = []
for i, d in enumerate(examples):
documents.append(Document(content=d, id=i))
document_store.write_documents(documents)
使用优化的双编码器嵌入模型初始化检索器,并对文档库中的所有文档进行编码:
from fastrag.retrievers import QuantizedBiEncoderRetriever
model_id = "Intel/bge-small-en-v1.5-rag-int8-static"
retriever = QuantizedBiEncoderRetriever(document_store=document_store, embedding_model=model_id)
document_store.update_embeddings(retriever=retriever)
使用优化的排名器进行重排
下面的代码片段展示了如何将量化模型加载到排序器中,该结点会对检索器检索到的所有文档进行编码和重排:
from haystack import Pipeline
from fastrag.rankers import QuantizedBiEncoderRanker
ranker = QuantizedBiEncoderRanker("Intel/bge-large-en-v1.5-rag-int8-static")
p = Pipeline()
p.add_node(component=retriever, name="retriever", inputs=["Query"])
p.add_node(component=ranker, name="ranker", inputs=["retriever"])
results = p.run(query="What is the capital of France?")
# print the documents retrieved
print(results)
搞定!我们创建的这个流水线首先从文档库中检索文档,并使用 (另一个) 嵌入模型对检索到的文档进行重排。你也可从这个 Notebook 中获取更完整的例子。
如欲了解更多 RAG 相关的方法、模型和示例,我们邀请大家通过 fastRAG/examples 尽情探索。
英文原文:
https://huggingface.co/blog/intel-fast-embedding
原文作者: Peter Izsak,Moshe Berchansky,Daniel Fleischer,Ella Charlaix,Morgan Funtowicz,Moshe Wasserblat
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号