俄罗斯套娃 (Matryoshka) 嵌入模型概述
在这篇博客中,我们将向你介绍俄罗斯套娃嵌入的概念,并解释为什么它们很有用。我们将讨论这些模型在理论上是如何训练的,以及你如何使用 Sentence Transformers 来训练它们。
除此之外,我们还会告诉你怎么用这种像套娃一样的俄罗斯套娃嵌入模型,并且我们会比较一下这种模型和普通嵌入模型的不同。最后,我们邀请你来玩一下我们的互动演示,看看这些模型有多厉害。
理解嵌入 (embedding)
嵌入是自然语言处理中最通用的工具之一,使从业者能够解决大量任务。本质上,嵌入是一个更复杂数字对象的数值表示,如文本、图像、音频等。
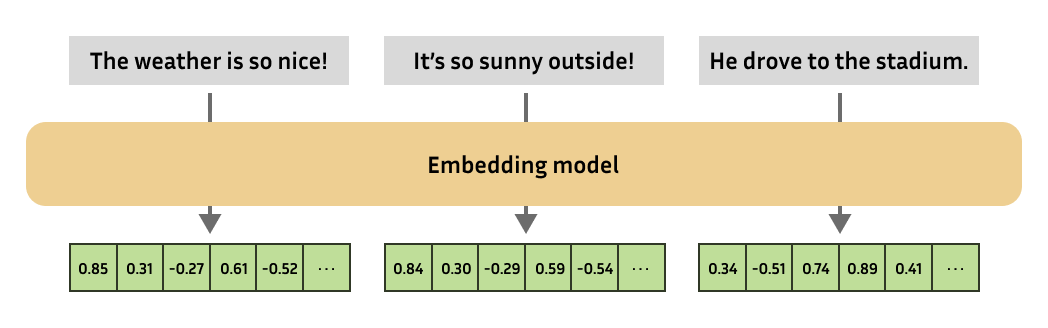
嵌入模型总是会产生相同固定大小的嵌入。然后,你可以通过计算相应嵌入的相似性来计算复杂数字对象的相似性!
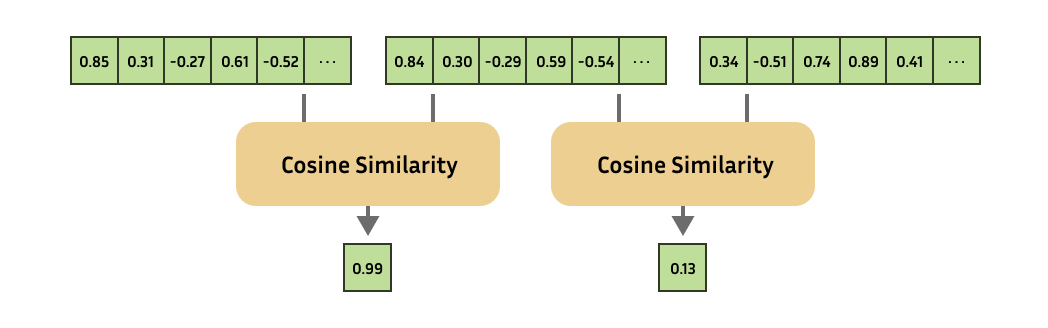
这种技术 (嵌入) 在许多领域都有应用,它是推荐系统、信息检索、零样本学习或少量样本学习、异常检测、相似性搜索、释义检测、聚类、分类等领域的基础。
🪆 俄罗斯套娃 (Matryoshka) 嵌入
随着研究的进展,新的最先进的 (文本) 嵌入模型开始产生具有越来越高的输出维度,即每个输入文本都使用更多的值来表示。尽管这提高了性能,但以下游任务 (如搜索或分类) 的效率为代价。
因此,Kusupati 等人 (2022) 受到启发,创造了即使嵌入尺寸合理缩小也不会在性能上遭受太大损失的嵌入模型。
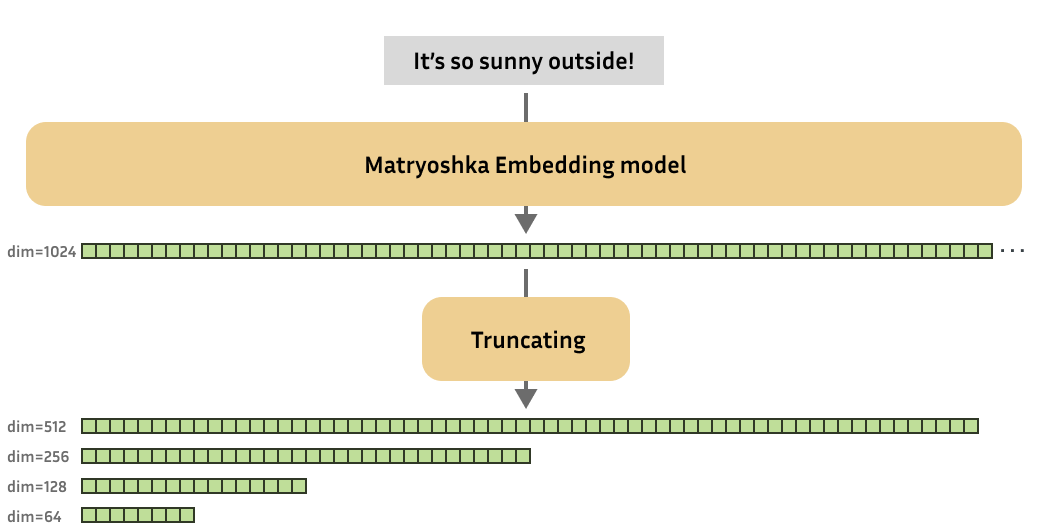
这些俄罗斯套娃嵌入模型经过训练,使得这些小的截断嵌入仍然有用。简而言之,俄罗斯套娃嵌入模型可以产生各种尺寸的有用嵌入。
🪆 俄罗斯套娃
对于不熟悉的人来说,“Matryoshka 娃娃”,也称为“俄罗斯套娃”,是一组大小递减的木制娃娃,相互嵌套。类似地,俄罗斯套娃嵌入模型旨在将更重要的信息存储在早期的维度中,将不太重要的信息存储在后面的维度中。俄罗斯套娃嵌入模型的这一特点允许我们截断模型产生的原始 (大) 嵌入,同时仍保留足够的信息以在下游任务上表现良好。
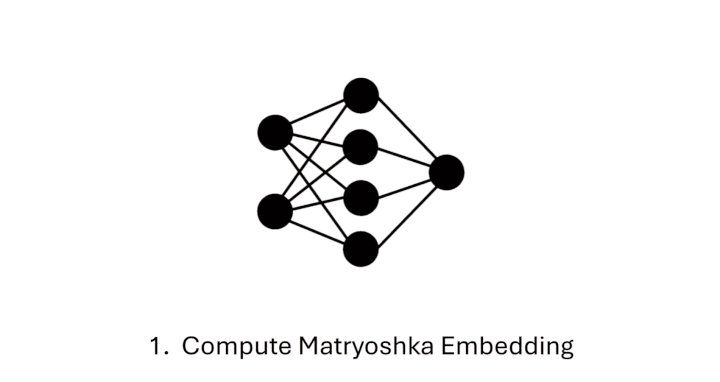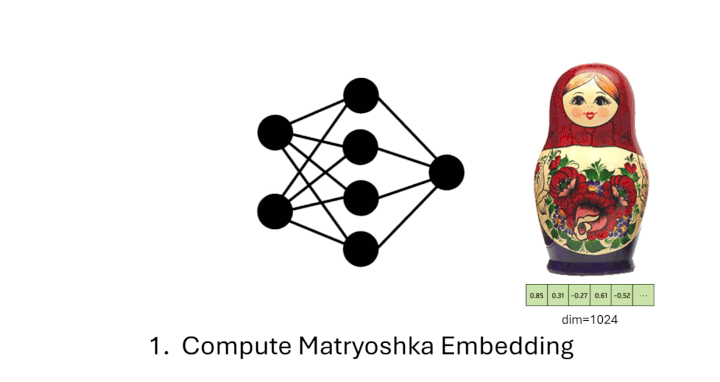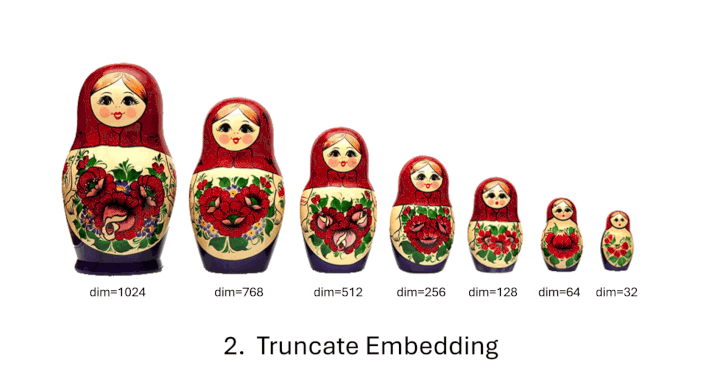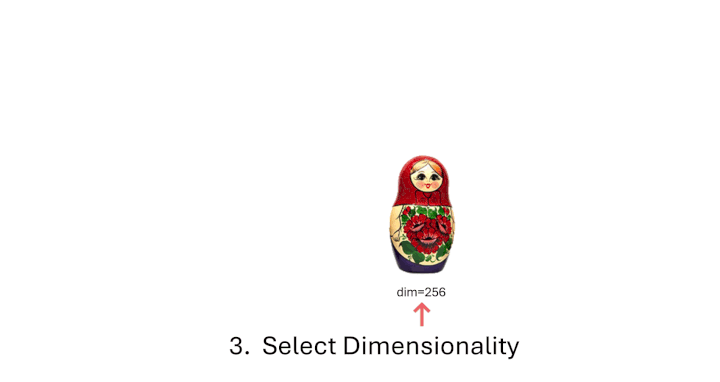
为什么使用🪆 俄罗斯套娃嵌入模型?
这种可变尺寸的嵌入模型对从业者来说非常有价值,例如:
- 筛选和重新排序: 不必在完整嵌入上执行你的下游任务 (例如,最近邻搜索),你可以缩小嵌入到更小的尺寸,并非常高效地“筛选”你的嵌入。之后,你可以使用它们的完整维度处理剩余的嵌入。
- 权衡: 俄罗斯套娃模型将允许你根据所需的存储成本、处理速度和性能来扩展你的嵌入解决方案。
🪆 俄罗斯套娃嵌入模型是如何训练的?
理论上
俄罗斯套娃表示学习 (MRL) 方法几乎可以适用于所有嵌入模型训练框架。通常,嵌入模型的一个训练步骤涉及为你的训练批次 (例如文本) 产生嵌入,然后使用一些损失函数创建一个代表产生嵌入质量的损失值。优化器会在训练过程中调整模型权重以减少损失值。
对于俄罗斯套娃嵌入模型,一个训练步骤还涉及为你的训练批次产生嵌入,但是然后你使用一些损失函数来确定不仅仅是全尺寸嵌入的质量,还有各种不同维度性下的嵌入质量。例如,输出维度性为 768、512、256、128 和 64。每个维度性的损失值加在一起,得到最终的损失值。然后,优化器将尝试调整模型权重以降低这个损失值。
实际上,这鼓励模型在嵌入的开始部分前置最重要的信息,这样如果嵌入被截断,这些信息将得以保留。
在 Sentence Transformers 中
Sentence Tranformers 是一个常用于训练嵌入模型的框架,它最近实现了对俄罗斯套娃模型的支持。使用 Sentence Transformers 训练俄罗斯套娃嵌入模型非常基础: 不是仅在全尺寸嵌入上应用一些损失函数,我们也在嵌入的截断部分应用同样的损失函数。
例如,如果一个模型的原始嵌入维度为 768,现在它可以被训练为 768、512、256、128 和 64。这些损失值将加在一起,可以选择性地给予一些权重:
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, MatryoshkaLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = MatryoshkaLoss(
model=model,
loss=base_loss,
matryoshka_dims=[768, 512, 256, 128, 64],
matryoshka_weight=[1, 1, 1, 1, 1],
)
model.fit(
train_objectives=[(train_dataset, loss)],
...,
)
使用 MatryoshkaLoss 进行训练并不会显著增加训练时间。
参考文献:
MatryoshkaLossCoSENTLossSentenceTransformerSentenceTransformer.fit- Matryoshka Embeddings - Training
请查看以下完整脚本,了解如何在实际应用中使用 MatryoshkaLoss :
- matryoshka_nli.py: 此示例使用
MultipleNegativesRankingLoss与MatryoshkaLoss结合,利用自然语言推理 (NLI) 数据训练一个强大的嵌入模型。这是对 NLI 文档的改编。 - matryoshka_nli_reduced_dim.py: 此示例使用
MultipleNegativesRankingLoss与MatryoshkaLoss结合,训练一个最大输出维度为 256 的小型嵌入模型。它使用自然语言推理 (NLI) 数据进行训练,这是对 NLI 文档的改编。 - matryoshka_sts.py: 此示例使用
CoSENTLoss与MatryoshkaLoss结合,在STSBenchmark数据集的训练集上训练一个嵌入模型。这是对 STS 文档的改编。
如何使用 🪆俄罗斯套娃嵌入模型?
理论上
实际上,从俄罗斯套娃嵌入模型获取嵌入的方式与从普通嵌入模型获取嵌入的方式相同。唯一的区别在于,在接收到嵌入后,我们可以选择将它们截断为更小的维度。请注意,如果嵌入已经归一化,那么在截断后它们将不再归一化,因此你可能需要重新归一化。
截断后,你可以直接将它们应用于你的用例,或者存储它们以便稍后使用。毕竟,在你的向量数据库中使用较小的嵌入应该会带来相当大的速度提升!
请记住,尽管处理较小嵌入以进行下游任务 (检索、聚类等) 会更快,但从模型获取较小嵌入的速度与获取较大嵌入的速度一样快。
在 Sentence Transformers 中
在 Sentence Transformers 中,你可以像加载普通模型一样加载俄罗斯套娃嵌入模型,并使用 SentenceTransformers.encode 进行推理。获取嵌入后,我们可以将它们截断到我们所需的尺寸,如果需要,我们还可以对它们进行归一化。
让我们尝试使用我使用 matryoshka_nli.py 和 microsoft/mpnet-base 训练的模型:
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer("tomaarsen/mpnet-base-nli-matryoshka")
matryoshka_dim = 64
embeddings = model.encode(
[
"The weather is so nice!",
"It's so sunny outside!",
"He drove to the stadium.",
]
)
embeddings = embeddings[..., :matryoshka_dim] # Shrink the embedding dimensions
print(embeddings.shape)
# => (3, 64)
# Similarity of the first sentence to the other two:
similarities = cos_sim(embeddings[0], embeddings[1:])
print(similarities)
# => tensor([[0.8910, 0.1337]])
模型链接: tomaarsen/mpnet-base-nli-matryoshka
请随意尝试使用不同的 matryoshka_dim 值,并观察这对相似度的影响。你可以通过在本地运行这段代码,在云端运行 (例如使用 Google Colab),或者查看 演示 来进行实验。
参考文献:
点击这里查看如何使用 Nomic v1.5 Matryoshka 模型
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
import torch.nn.functional as F
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
matryoshka_dim = 64
embeddings = model.encode(
[
"search_query: What is TSNE?",
"search_document: t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map.",
"search_document: Amelia Mary Earhart was an American aviation pioneer and writer.",
],
convert_to_tensor=True,
)
# The Nomic team uses a custom architecture, making them recommend Layer Normalization before truncation
embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
embeddings[..., :matryoshka_dim] # Shrink the embedding dimensions
similarities = cos_sim(embeddings[0], embeddings[1:])
# => tensor([[0.7154, 0.4468]])
结果
现在我们已经介绍了俄罗斯套娃模型,让我们来看看我们可以从俄罗斯套娃嵌入模型与常规嵌入模型中实际期待的绩效表现。为了这个实验,我训练了两个模型:
- tomaarsen/mpnet-base-nli-matryoshka: 通过运行
matryoshka_nli.py与microsoft/mpnet-base进行训练。 - tomaarsen/mpnet-base-nli: 通过运行修改版的
matryoshka_nli.py进行训练,其中训练损失仅为MultipleNegativesRankingLoss,而不是在MultipleNegativesRankingLoss之上的MatryoshkaLoss。我也使用microsoft/mpnet-base作为基础模型。
这两个模型都在 AllNLI 数据集上进行了训练,该数据集是 SNLI 和 MultiNLI 数据集的拼接。我使用多种不同的嵌入维度在这些模型上评估了 STSBenchmark 测试集。结果绘制在下面的图表中:
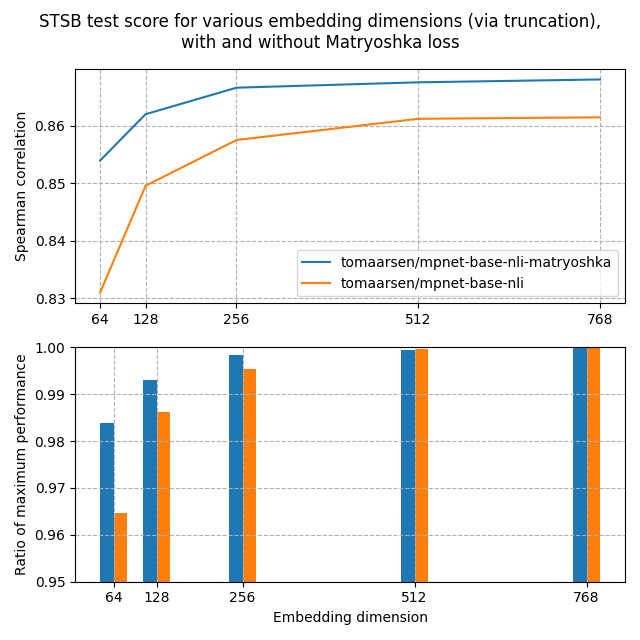
在上面的图表中,你可以看到俄罗斯套娃模型在所有维度上都达到了比标准模型更高的 Spearman 相似度,这表明俄罗斯套娃模型在此任务上是优越的。
此外,俄罗斯套娃模型的性能下降速度比标准模型要慢得多。这在第二个图表中清晰显示,该图表显示了相对于最大性能的嵌入维度的性能。 即使嵌入大小只有 8.3%,俄罗斯套娃模型也保持了 98.37% 的性能,远高于标准模型的 96.46%。
这些发现表明,通过俄罗斯套娃模型截断嵌入可以:
- 显著加快下游任务 (如检索) 的速度;
- 显著节省存储空间,而且不会对性能产生显著影响。
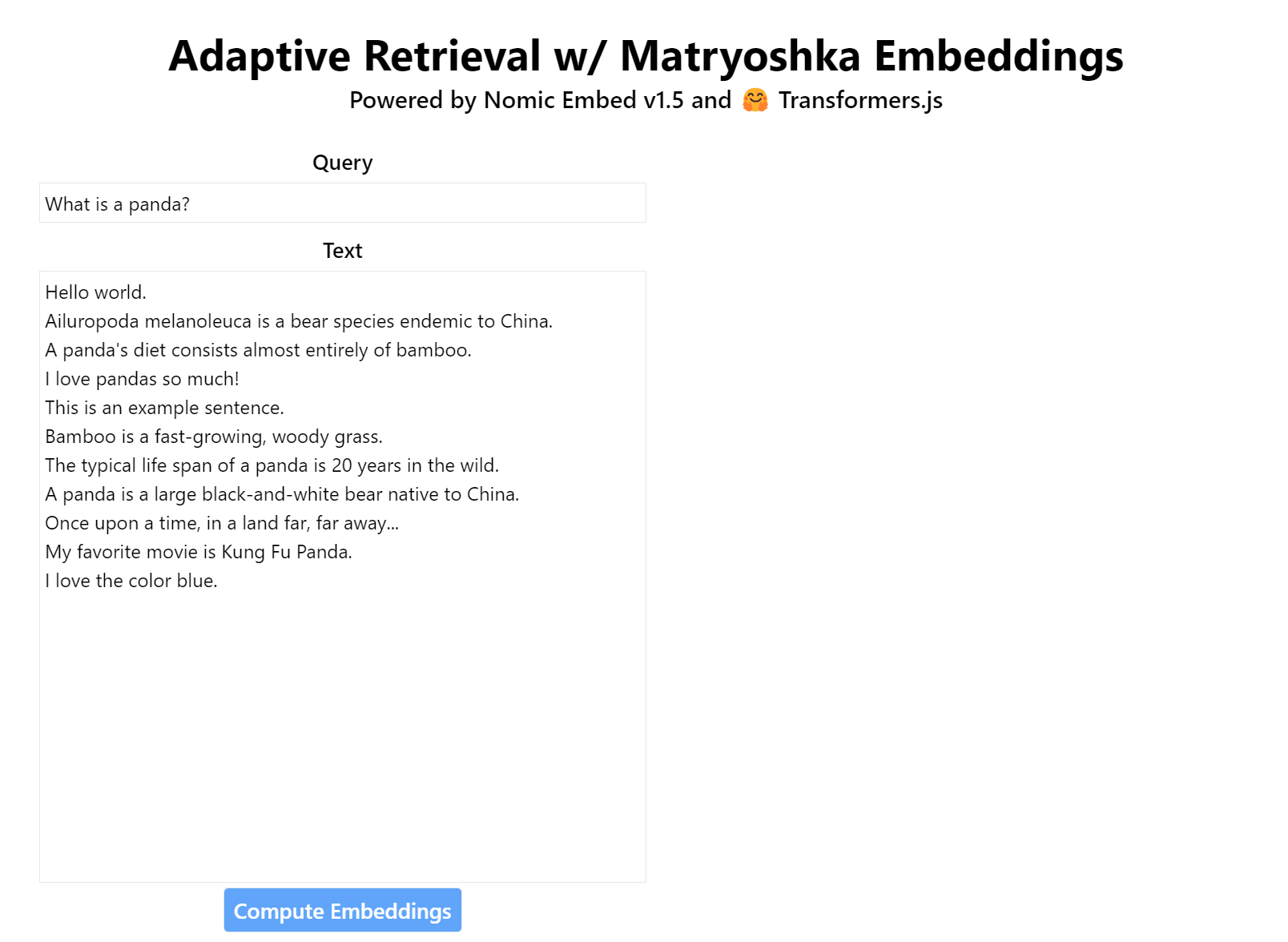
演示
在这个演示中,你可以动态缩小 nomic-ai/nomic-embed-text-v1.5 俄罗斯套娃嵌入模型的输出维度,并观察它如何影响检索性能。所有的嵌入都是在浏览器中使用 🤗 Transformers.js 进行计算的。
参考文献
- Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan, V., … & Farhadi, A. (2022). Matryoshka representation learning. Advances in Neural Information Processing Systems, 35, 30233-30249. https://arxiv.org/abs/2205.13147
- Matryoshka Embeddings — Sentence-Transformers documentation. (n.d.). https://sbert.net/examples/training/matryoshka/README.html
- UKPLab. (n.d.). GitHub. https://github.com/UKPLab/sentence-transformers
- Unboxing Nomic Embed v1.5: Resizable Production Embeddings with Matryoshka Representation Learning. (n.d.). https://blog.nomic.ai/posts/nomic-embed-matryoshka
英文原文: https://hf.co/blog/matryoshka
原文作者: Tom Aarsen, Joshua, Omar Sanseviero
译者: innovation64

 浙公网安备 33010602011771号
浙公网安备 33010602011771号