Reformer 模型 - 突破语言建模的极限
Reformer 如何在不到 8GB 的内存上训练 50 万个词元
Kitaev、Kaiser 等人于 20202 年引入的 Reformer 模型 是迄今为止长序列建模领域内存效率最高的 transformer 模型之一。
最近,人们对长序列建模的兴趣激增,仅今年一年,就涌现出了大量的工作,如 Beltagy 等人的工作 (2020) 、Roy 等人的工作 (2020) 、Tay 等人的工作 以及 Wang 等人的工作 等等。长序列建模背后的动机是,NLP 中的许多任务 (例如 摘要、问答 ) 要求模型处理更长的序列,这些序列长度超出了 BERT 等模型的处理能力。在需要模型处理长输入序列的任务中,长序列模型无需对输入序列进行裁剪以避免内存溢出,因此已被证明优于标准的 BERT 类模型 ( 见 Beltagy 等人 2020 年的工作)。
Reformer 能够一次处理多达 50 万个词元,从而突破了长序列建模的极限 (具体可参见本 笔记本)。相形之下,传统的 bert-base-uncased 模型最长仅支持 512 个词元。在 Reformer 中,标准 transformer 架构的每个部分都经过重新设计,以最小化内存需求,并避免显著降低性能。
内存的改进来自于 Reformer 作者向 transformer 世界引入的 4 大特性:
- Reformer 自注意力层 - 如何在不受限于本地上下文的情况下高效地实现自注意力机制?
- 分块前馈层 - 如何更好地对大型前馈层的时间和内存进行权衡?
- 可逆残差层 - 如何聪明地设计残差架构以大幅减少训练中的内存消耗?
- 轴向位置编码 (Axial Positional Encodings) - 如何使位置编码可用于超长输入序列?
本文的目的是 深入 阐述 Reformer 的上述四大特性。虽然这四个特性目前是用在 Reformer 上的,但其方法是通用的。因此,读者不应被此束缚,而应该多思考在哪些情况下可以把这四个特性中的某一个或某几个应用于其他的 transformer 模型,以解决其问题。
下文四个部分之间的联系很松散,因此可以单独阅读。
Reformer 已集成入 🤗Transformers 库。对于想使用 Reformer 的用户,建议大家阅读本文,以更好地了解该模型的工作原理以及如何正确配置它。文中所有公式都附有其在 transformers 中对应的 Reformer 配置项 ( 例如 config.<param_name> ),以便读者可以快速关联到官方文档和配置文件。
注意: 轴向位置编码 在官方 Reformer 论文中没有解释,但在官方代码库中广泛使用。本文首次深入阐释了轴向位置编码。
1. Reformer 自注意力层
Reformer 使用了两种特殊的自注意力层: 局部 自注意力层和 LSH (Locality Sensitive Hashing,局部敏感哈希, LSH ) 自注意力层。
在介绍新的自注意力层之前,我们先简要回顾一下传统的自注意力,其由 Vaswani 等人在其 2017 年的论文 中引入。
本文的符号及配色与 《图解 transformer》 一文一致,因此强烈建议读者在阅读本文之前,先阅读《图解 transformer》一文。
重要: 虽然 Reformer 最初是为了因果自注意力而引入的,但它也可以很好地用于双向自注意力。本文在解释 Reformer 的自注意力时,将其用于 双向 自注意力。
全局自注意力回顾
Transformer 模型的核心是 自注意力 层。现在,我们回顾一下传统的自注意力层,这里称为 全局自注意力 层。首先我们假设对嵌入向量序列 \(\mathbf{X} = \mathbf{x}_1, \ldots, \mathbf{x}_n\) 执行一个 transformer 层,该序列中的每个向量 \(\mathbf{x}_{i}\) 的维度为 config.hidden_size , 即 \(d_h\)。
简而言之,全局自注意力层将 \(\mathbf{X}\) 投影到查询矩阵、键矩阵和值矩阵: \(\mathbf{Q}\)、\(\mathbf{K}\)、\(\mathbf{V}\) 并使用 softmax 计算最终输出 \(\mathbf{Z}\),如下所示:
\(\mathbf{Z} = \text{SelfAttn}(\mathbf{X}) = \text{softmax}(\mathbf{Q}\mathbf{K}^T) \mathbf{V}\),其中 \(\mathbf{Z}\) 的维度为 \(d_h \times n\) (为简单起见,此处省略了键归一化因子和输出映射权重 \(\mathbf{W}^{O}\))。有关完整 transformer 操作的更多详细信息,请参阅 《图解 transformer》 一文。
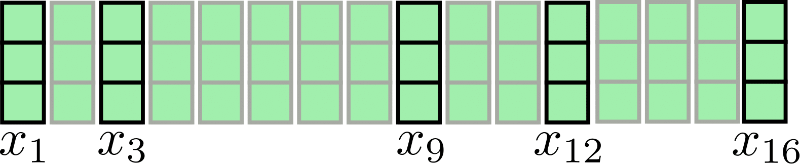
下图给出了 \(n=16,d_h=3\) 情况下的操作:

请注意,本文所有示意图都假设 batch_size 和 config.num_attention_heads 为 1。为了便于稍后更好地解释 LSH 自注意力 ,我们还在图中标记出了一些向量, 如 \(\mathbf{x_3}\) 及其相应的输出向量 \(\mathbf{z_3}\)。图中的逻辑可以轻易扩展至多头自注意力 ( config.num_attention_heads > 1)。如需了解多头注意力,建议读者参阅 《图解 transformer》。
敲个重点,对于每个输出向量 \(\mathbf{z}_{i}\),整个输入序列 \(\mathbf{X}\) 都需要参与其计算。内积张量 \(\mathbf{Q}\mathbf{K}^T\) 的内存复杂度为 \(\mathcal{O}(n^2)\),这事实上使得 transformer 模型的瓶颈在内存。
这也是为什么 bert-base-cased 的 config.max_position_embedding_size 只有 512 的原因。
局部自注意力
局部自注意力 是缓解 \(\mathcal{O}(n^2)\) 内存瓶颈的一个显然的解决方案,它使我们能够以更低的计算成本建模更长的序列。在局部自注意力中,输入 \(\mathbf{X} = \mathbf{X}_{1:n} = \mathbf{x}_{1}, \ldots, \mathbf{x}_{n}\) 被切成 \(n_{c}\) 个块: \(\mathbf{X} = \left[\mathbf{X}_{1:l_{c}}, \ldots, \mathbf{X} _{(n_{c} - 1) * l_{c} : n_{c} * l_{c}}\right]\),每块长度为 config.local_chunk_length , 即 \(l_{c}\),随后,对每个块分别应用全局自注意力。
继续以 \(n=16,d_h=3\) 为例:
假设 \(l_{c} = 4,n_{c} = 4\),此时,我们将分块注意力图示如下:

可以看出,我们对每个块分别执行了注意力操作 \(\mathbf{X} _{1:4},\mathbf{X}_ {5:8},\mathbf{X} _{9:12 },\mathbf{X}_ {13:16}\)。
该架构的一个明显的缺点是: 一些输入向量无法访问其直接上下文, 例如 ,我们的例子中的 \(\mathbf{x} _9\) 无法访问 \(\mathbf{x}_ {8}\),反之亦然。这是有问题的,因为这些词元无法在学习其向量表征时将其直接上下文的纳入考量。
一个简单的补救措施是用 config.local_num_chunks_before ( 即 \(n_{p}\)) 以及 config.local_num_chunks_after ( 即 \(n_{a}\)) 来扩充每个块,以便每个输入向量至少可以访问 \(n_{p}\) 个先前输入块及 \(n_{a}\) 个后续输入块。我们可将其理解为重叠分块,其中 \(n_{p}\) 和 \(n_{a}\) 定义了每个块与其先前块和后续块的重叠量。我们将这种扩展的局部自注意力表示如下:
其中
好吧,这个公式看起来有点复杂,我们稍微分析一下。在 Reformer 的自注意力层中,\(n_{a}\) 通常设为 0,\(n_{p}\) 设为 1,我们据此重写 \(i = 1\) 时的公式:
我们注意到这里有一个循环关系,因此第一个块也可以关注最后一个块。我们再次图解一下这种增强的局部关注算法。我们先按块找到其对应的窗口,并在其上应用自注意力,然后仅保留中心输出段作为本块的输出。
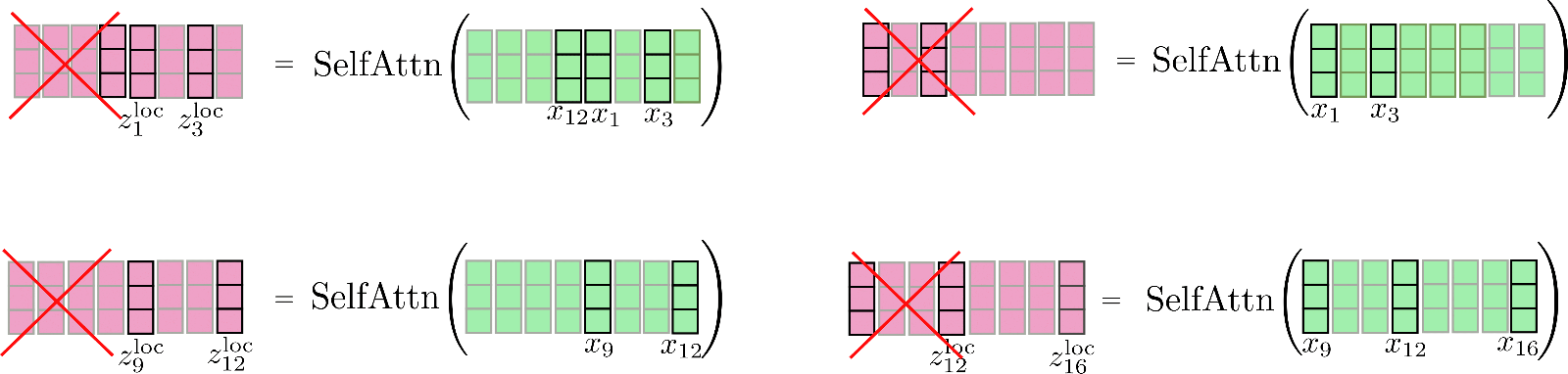
最后,将相应的输出串接到 \(\mathbf{Z}^{\text{loc}}\) 中,如下所示:

请注意,在实现局部自注意力时,为了计算效率,我们并不会像图中一样先计算全部输出并随后 丢弃 一部分。图中红叉所示的地方仅用于说明,实际并不会产生计算行为。
这里需要注意的是,扩展每个分块自注意力函数的输入向量可以使得 每个 输出向量 \(\mathbf{z}_{i}\) 都能够学到更好的向量表征。以图中的向量为例,每个输出向量 \(\mathbf{z}_{5}^{\text{loc}},\mathbf{z}_{6}^{\text{loc}},\mathbf{z}_{7}^{\text{loc}},\mathbf{z}_{8}^{\text{loc}}\) 都可以将 \(\mathbf{X}_{1:8}\) 的所有输入向量纳入考量以学到更好的表征。
内存消耗上的降低也是显而易见的: \(\mathcal{O}(n^2)\) 的内存复杂度被分解到段,因此总内存复杂度减少为 \(\mathcal{O}(n_{c} * l_{c}^2) = \mathcal{O}(n * l_{c})\)。
这种增强的局部自注意力比普通的局部自注意力架构更好,但仍然存在一个主要缺陷,因为每个输入向量只能关注预定义大小的局部上下文。对于不需要 transformer 模型学习输入向量之间的远程依赖关系的 NLP 任务 ( 例如 语音识别、命名实体识别以及短句子的因果语言建模) 而言,可能不是一个大问题。但还有许多 NLP 任务需要模型学习远程依赖关系,因此局部自注意力在这些任务下可能会导致显著的性能下降, 如 :
- 问答 : 模型必须学习问题词元和相关答案词元之间的关系,这些词元很可能并不相邻;
- 多项选择 : 模型必须将多个答案词元段相互比较,这些答案词元段通常隔得比较远;
- 摘要 : 模型必须学习长序列的上下文词元和较短的摘要词元序列之间的关系,而上下文和摘要之间的相关关系很可能无法通过局部自注意力来捕获。
- ……
局部自注意力本身很可能不足以让 transformer 模型学习输入向量 (词元) 彼此之间的相关关系。
因此,Reformer 额外采用了一个近似全局自注意力的高效自注意力层,称为 LSH 自注意力 。
LSH 自注意力
鉴于我们已经了解了局部自注意力的工作原理,下面我们继续尝试一下可能是 Reformer 中最具创新性的算法改进: LSH 自注意力。
LSH 自注意力的设计目标是在效果上接近全局自注意力,而在速度与资源消耗上与局部自注意力一样高效。
LSH 自注意力因依赖于 Andoni 等人于 2015 年提出的 LSH 算法 而得名。
LSH 自注意力源于以下洞见: 如果 \(n\) 很大,则对每个查询向量而言,其对应的输出向量 \(\mathbf{z}_{i}\) 作为所有 \(\mathbf{V}\) 的线性组合,其中应只有极少数几个 \(\mathbf{v}_{i}\) 的权重比其他大得多。也就是说对 \(\mathbf{Q}\mathbf{K}^T\) 注意力点积作 softmax 产生的权重矩阵的每一行应仅有极少数的值远大于 0。
我们展开讲讲: 设 \(\mathbf{k}_{i} \in \mathbf{K} = \left[\mathbf{k}_1, \ldots, \mathbf{k}_n \right]^T\) 和 \(\mathbf{q}_{i} \in \mathbf{Q} = \left[\mathbf{q}_1, \ldots, \mathbf{q}_n\right]^T\) 分别为键向量和查询向量。对于每个 \(\mathbf{q}_{i}\),可以仅用那些与 \(\mathbf{q}_{i}\) 具有高余弦相似度的 \(\mathbf{k}_{j}\) 的键向量来近似计算 \(\text{softmax}(\mathbf{q}_{i}^T \mathbf{K}^T)\) 。这是因为 softmax 函数对较大输入值的输出会呈指数级增加。听起来没毛病,那么下一个问题就变成了如何高效地找到每个 \(\mathbf{q}_{i}\) 的高余弦相似度键向量集合。
首先,Reformer 的作者注意到共享查询投影和键投影: \(\mathbf{Q} = \mathbf{K}\) 并不会影响 transformer 模型 \({}^1\)。现在,不必为每个查询向量 \(q_i\) 找到其高余弦相似度的键向量,而只需计算查询向量彼此之间的余弦相似度。这一简化很重要,因为查询向量之间的余弦相似度满足传递性: 如果 \(\mathbf{q}_{i}\) 与 \(\mathbf{q}_{j}\) 和 \(\mathbf{q}_{k}\) 都具有较高的余弦相似度,则 \(\mathbf{q}_{j}\) 与 \(\mathbf{q}_{k}\) 也具有较高的余弦相似度。因此,可以将查询向量聚类至不同的桶中,使得同一桶中的所有查询向量彼此的余弦相似度较高。我们将 \(C_{m}\) 定义为第 m 组位置索引,其中装的是属于同一个桶的所有查询向量: \(C_{m} = { i | \mathbf{q}_{i} \in \text{第 m 簇}}\),同时我们定义桶的数量 config.num_buckets , 即 \(n_{b}\)。
对每个索引 \(C_{m}\) 对应的查询向量桶内的查询向量 \(\mathbf{q}_{i}\),我们可以用 softmax 函数 \(\text{softmax}(\mathbf{Q}_{i \in C_{m}} \mathbf{Q}^T_{i \in C_{m}})\) 通过共享查询和键投影来近似全局自注意力的 softmax 函数 \(\text{softmax}(\mathbf{q}_{i}^T \mathbf{Q}^T)\)。
其次,作者利用 LSH 算法将查询向量聚类到预定义的 \(n_{b}\) 个桶 中。这里,LSH 算法是理想之选,因为它非常高效,且可用于近似基于余弦相似度的最近邻算法。对 LSH 进行解释超出了本文的范围,我们只要记住,对向量 \(\mathbf{q}_{i}\),LSH 算法将其索引至 \(n_{b}\) 个预定义桶中的某个桶, 即 \(\text{LSH}(\mathbf{q}_{i}) = m\) 其中 \(i \in {1, \ldots, n}\),\(m \in {1, \ldots, n_{b}}\)。
还用前面的例子,我们有:

接着,可以注意到,将所有查询向量聚类至 \(n_{b}\) 个桶中后,我们可以将输入向量 \(\mathbf{x}_1, \ldots, \mathbf{x}_n\) 按其对应的索引 \(C_{m}\) 进行重排 \({}^2\),以便共享查询 - 键自注意力可以像局部注意力一样分段应用。
我们用例子再解释一下,假设在 config.num_buckets=4 , config.lsh_chunk_length=4 时重排输入向量 \(\mathbf{X} = \mathbf{x}_1, …, \mathbf{x}_{16}\)。上图已将每个查询向量 \(\mathbf{q}_1, \ldots, \mathbf{q}_{16}\) 分配给簇 \(\mathcal{C}_{1}、\mathcal{C}_{2}、\mathcal{C}_{3}、\mathcal{C}_{4}\) 中的某一个。现在,对其对应的输入向量 \(\mathbf{x}_1, \ldots, \mathbf{x}_{16}\) 进行重排,并将重排后的输入记为 \(\mathbf{X'}\):
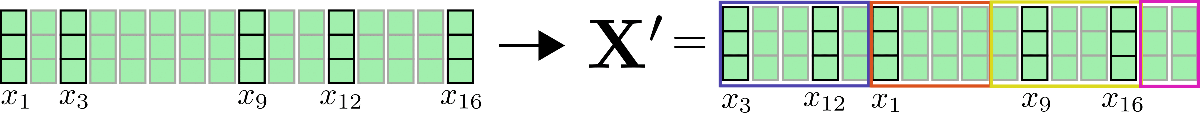
对每个输入向量,仅需在簇内进行自注意力计算即可,因此每个输入向量对应的输出向量可计算如下: \(\mathbf{Z}^{\text{LSH}}_{i \in \mathcal{C}_m} = \text{SelfAttn}_{\mathbf{Q}=\mathbf{K}}(\mathbf{X}_{i \in \mathcal{C}_m})\)。
我们再次图解一下该过程:
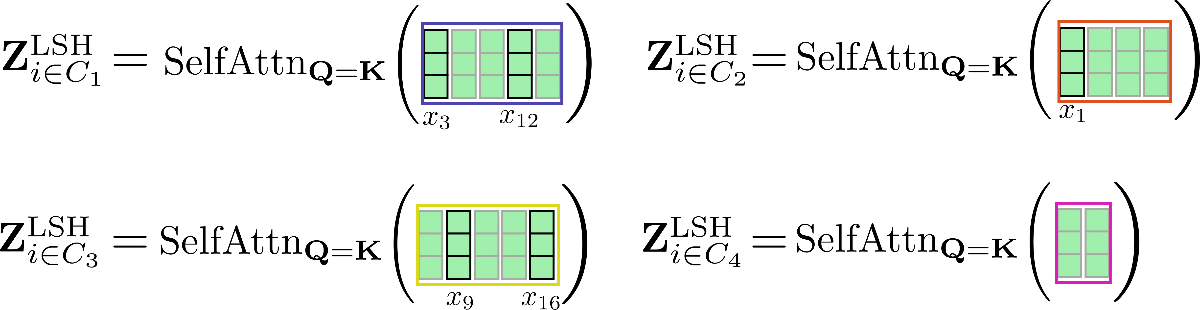
可以看出,自注意力函数的运算矩阵大小各不相同,这种情况比较麻烦,因为 GPU 和 TPU 无法高效并行处理不同尺寸的矩阵运算。
为了进一步解决高效计算的问题,可以借鉴局部注意力的方法,对重排后的输入进行分块,以使每个块的大小均为 config.lsh_chunk_length 。通过对重排后的输入进行分块,一个桶可能会被分成两个不同的块。为了解决这个问题,与局部自注意力一样,在 LSH 自注意力中,每个块除了自身之外还关注其前一个块 config.lsh_num_chunks_before=1 ( config.lsh_num_chunks_after 通常设置为 0)。这样,我们就可以大概率确保桶中的所有向量相互关注 \({}^3\)。
总而言之,对于所有块 \(k \in {1, \ldots, n_{c}}\),LSH 自注意力可以如下表示:
其中 \(\mathbf{X'}\) 和 \(\mathbf{Z'}\) 是按照 LSH 分桶进行重排后的输入和输出向量。公式有点复杂,我们还是画个图以帮助大家理解。
这里,我们对上图中的重排向量 \(\mathbf{X'}\) 进行分块,并分别计算每块的共享查询 - 键自注意力。
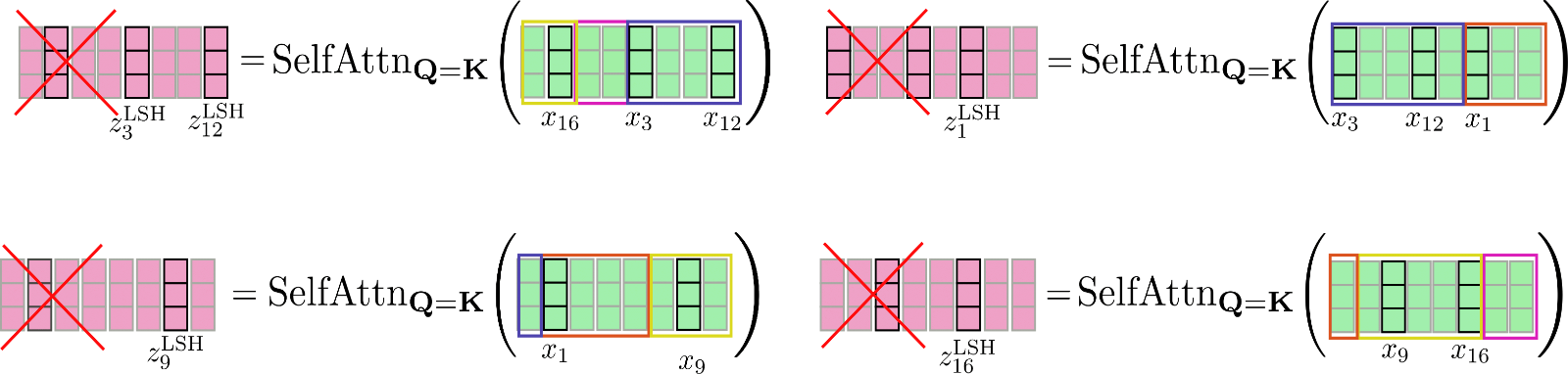
最后,将输出 \(\mathbf{Z'}^{\text{LSH}}\) 重排回原顺序。
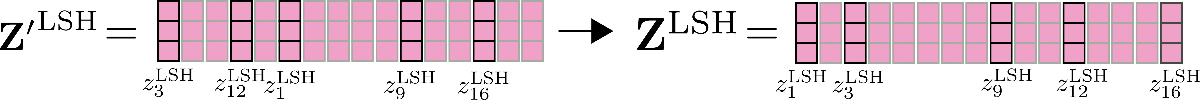
这里还要提到的一个重要特征是,可以通过并行运行 LSH 自注意力 config.num_hashes (即 \(n_{h}\)) 次来提高 LSH 自注意力的准确性,其中每次使用不同的随机 LSH 哈希。通过设置 config.num_hashes > 1 ,对于每个 \(i\),会计算多个输出向量 \(\mathbf{z}^{\text{LSH}, 1}_{i}, \ldots , \mathbf{z}^{\text{LSH}, n_{h}}_{i}\)。随后,可以对它们进行加权求和: \(\mathbf{z}^{\text{LSH}}_{i} = \sum_k^{n_{h}} \mathbf{Z}^{\text{LSH}, k}_{i} * \text{weight}^k_i\),这里 \(\text{weight}^k_i\) 表示第 \(k\) 轮哈希的输出向量 \(\mathbf{z}^{\text{LSH}, k}_{i}\) 与其他哈希轮次相比的重要度,其应与其对应输出的 softmax 归一化系数呈指数正比关系。这一设计背后的直觉是,如果查询向量 \(\mathbf{q}_{i}^{k}\) 与其对应块中的所有其他查询向量具有较高的余弦相似度,则该块的 softmax 归一化系数往往很大,因此相应的输出向量 \(\mathbf{q}_{i}^{k}\) 应该能更好地近似全局注意力,因此其理应比 softmax 归一化系数较小的哈希轮次所产生的输出向量获得更高的权重。更多详细信息,请参阅 该论文 的附录 A。在我们的例子中,多轮 LSH 自注意力示意图如下。
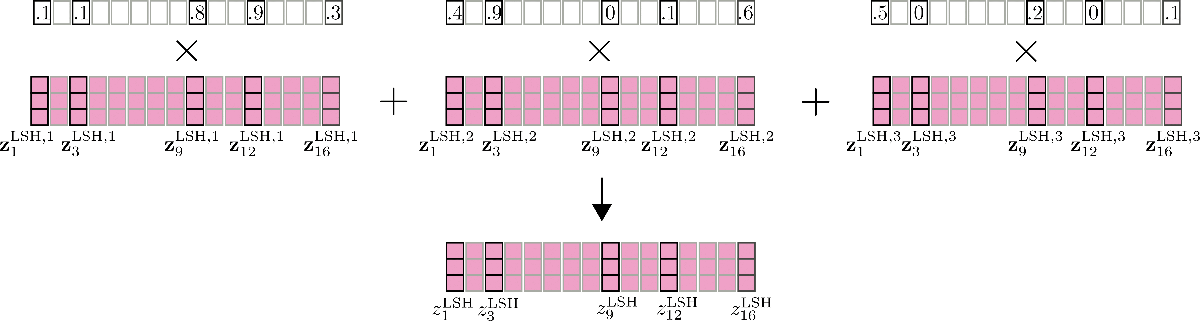
打完收工!至此,我们了解了 LSH 自注意力在 Reformer 中是如何工作的。
说回内存复杂度,该方法有两个可能的瓶颈点: 点积所需的内存: \(\mathcal{O}(n_{h} * n_{c} * l_{c}^2) = \mathcal{O}(n * n_{h} * l_{c})\) 以及 LSH 分桶所需的内存: \(\mathcal{O}(n * n_{h} * \frac{n_{b}}{2})\) 其中 \(l_{c}\) 是块长度。因为对于大的 \(n\) 而言,桶的数量 \(\frac{n_{b}}{2}\) 的增长速度远远快于块长度 \(l_{c}\),因此用户可以继续对存储桶的数量 config.num_buckets 进行分解,详见 此处。
我们快速总结一下:
- 我们希望利用 softmax 运算仅对极少数键向量赋予重要权重的先验知识来对全局注意力进行近似。
- 如果键向量等于查询向量,这意味着 对于每个 查询向量 \(\mathbf{q}_{i}\),softmax 只需给与其余弦相似度高的其他查询向量赋予重要权重就行了。
- 这种关系是对称的,也就是说,如果 \(\mathbf{q}_{j}\) 与 \(\mathbf{q}_{i}\) 相似,则 \(\mathbf{q}_{j}\) 也与 \(\mathbf{q}_{i}\) 相似,因此我们可以在计算自注意力之前对输入进行全局聚类。
- 我们对输入按簇进行重排,并对重排后的输入计算局部自注意力,最后将输出重新恢复为原顺序。
\({}^{1}\) 作者进行了一些初步实验,确认共享查询 - 键自注意力的表现与标准自注意力大体一致。
\({}^{2}\) 更准确地说,对存储桶中的查询向量根据其原始顺序进行排序。举个例子, 假如 向量 \(\mathbf{q}_1, \mathbf{q}_3, \mathbf{q}_7\) 全部散列到存储桶 2,则存储桶 2 中向量的顺序仍应是先 \(\mathbf{q}_1\),后跟 \(\mathbf{q}_3\) 和 \(\mathbf{q}_7\)。
\({}^3\) 顺带说明一下,作者在查询向量 \(\mathbf{q}_{i}\) 上放了一个掩码,以防止向量关注本身。因为向量与其自身的余弦相似度总是大于等于其与其他向量的余弦相似度,所以强烈不建议共享查询 - 键自注意力中的查询向量关注自身。
基准测试
Transformers 最近增加了基准测试相关的代码,你可参阅 此处 以获取更详细的说明。
为了展示局部 LSH 自注意力可以节省多少内存,我们在不同的 local_attn_chunk_length 和 lsh_attn_chunk_length 上对 Reformer 模型 google/reformer-enwik8 上进行了基准测试。你可以从 此处 找到更详细的有关 google/reformer-enwik8 模型的默认配置和用法信息。
我们先进行一些必要的导入和安装。
#@title Installs and Imports
# pip installs
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, PyTorchBenchmark, PyTorchBenchmarkArguments
首先,我们测试一下在 Reformer 模型上使用 全局 自注意力的内存使用情况。这可以通过设置 lsh_attn_chunk_length = local_attn_chunk_length = 8192 来达成,此时,对于所有小于或等于 8192 的输入序列,模型事实上就回退成全局自注意力了。
config = ReformerConfig.from_pretrained("google/reformer-enwik8", lsh_attn_chunk_length=16386, local_attn_chunk_length=16386, lsh_num_chunks_before=0, local_num_chunks_before=0)
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[2048, 4096, 8192, 16386], batch_sizes=[1], models=["Reformer"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config], args=benchmark_args)
result = benchmark.run()
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=1279.0, style=ProgressStyle(description…
1 / 1
Doesn't fit on GPU. CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 11.17 GiB total capacity; 8.87 GiB already allocated; 1.92 GiB free; 8.88 GiB reserved in total by PyTorch)
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer 1 2048 1465
Reformer 1 4096 2757
Reformer 1 8192 7893
Reformer 1 16386 N/A
--------------------------------------------------------------------------------
输入序列越长,输入序列和峰值内存使用之间的平方关系 \(\mathcal{O}(n^2)\) 越明显。可以看出,实际上,需要更长的输入序列才能清楚地观察到输入序列翻倍会导致峰值内存使用量增加四倍。
对使用全局注意力的 google/reformer-enwik8 模型而言,序列长度超过 16K 内存就溢出了。
现在,我们使用模型的默认参数以使能 局部 LSH 自注意力。
config = ReformerConfig.from_pretrained("google/reformer-enwik8")
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[2048, 4096, 8192, 16384, 32768, 65436], batch_sizes=[1], models=["Reformer"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config], args=benchmark_args)
result = benchmark.run()
1 / 1
Doesn't fit on GPU. CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 11.17 GiB total capacity; 7.85 GiB already allocated; 1.74 GiB free; 9.06 GiB reserved in total by PyTorch)
Doesn't fit on GPU. CUDA out of memory. Tried to allocate 4.00 GiB (GPU 0; 11.17 GiB total capacity; 6.56 GiB already allocated; 3.99 GiB free; 6.81 GiB reserved in total by PyTorch)
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer 1 2048 1785
Reformer 1 4096 2621
Reformer 1 8192 4281
Reformer 1 16384 7607
Reformer 1 32768 N/A
Reformer 1 65436 N/A
--------------------------------------------------------------------------------
不出所料,对于较长的输入序列,使用局部 LSH 自注意力机制的内存效率更高,对于本文使用的 11GB 显存 GPU 而言,模型直到序列长度为 32K 时,内存才耗尽。
2. 分块前馈层
基于 transformer 的模型通常在自注意力层之后会有一个非常大的前馈层。该层可能会占用大量内存,有时甚至成为模型主要的内存瓶颈。Reformer 论文中首次引入了前馈分块技术,以用时间换取内存。
Reformer 中的分块前馈层
在 Reformer 中, LSH 自注意力层或局部自注意力层通常后面跟着一个残差连接,我们可将其定义为 transformer 块 的第一部分。更多相关知识,可参阅此 博文。
Transformer 块 第一部分的输出,称为 归范化自注意力 输出,可以记为 \(\mathbf{\overline{Z}} = \mathbf{Z} + \mathbf{X}\)。在 Reformer 模型中,\(\mathbf{Z}\) 为 \(\mathbf{Z}^{\text{LSH}}\) 或 \(\mathbf{Z}^\text{loc}\)。
在我们的例子中,输入 \(\mathbf{x}_1, \ldots, \mathbf{x}_{16}\) 的规范化自注意力输出图示如下:

Transformer 块 的第二部分通常由两个前馈层 \(^{1}\) 组成,其中 \(\text{Linear}_{\text{int}}(\ldots)\) 用于将 \(\mathbf{\overline{Z}}\) 映射到中间输出 \(\mathbf{Y}_{\text{int}}\),\(\text{Linear}_{\text{out}}(\ldots)\) 用于将中间输出映射为最终输出 \(\mathbf{Y}_{\text{out}}\)。我们将两个前馈层定义如下:
敲重点!在数学上,前馈层在位置 \(i\) 处的输出 \(\mathbf{y}_{\text{out}, i}\) 仅取决于该位置的输入 \(\mathbf{\overline{y}}_{i}\)。与自注意力层相反,每个输出 \(\mathbf{y}_{\text{out}, i}\) 与其他位置的输入 \(\mathbf{\overline{y}}_{j \ne i}\) 完全独立。
\(\mathbf{\overline{z}}_1, \ldots, \mathbf{\overline{z}}_{16}\) 的前馈层图示如下:
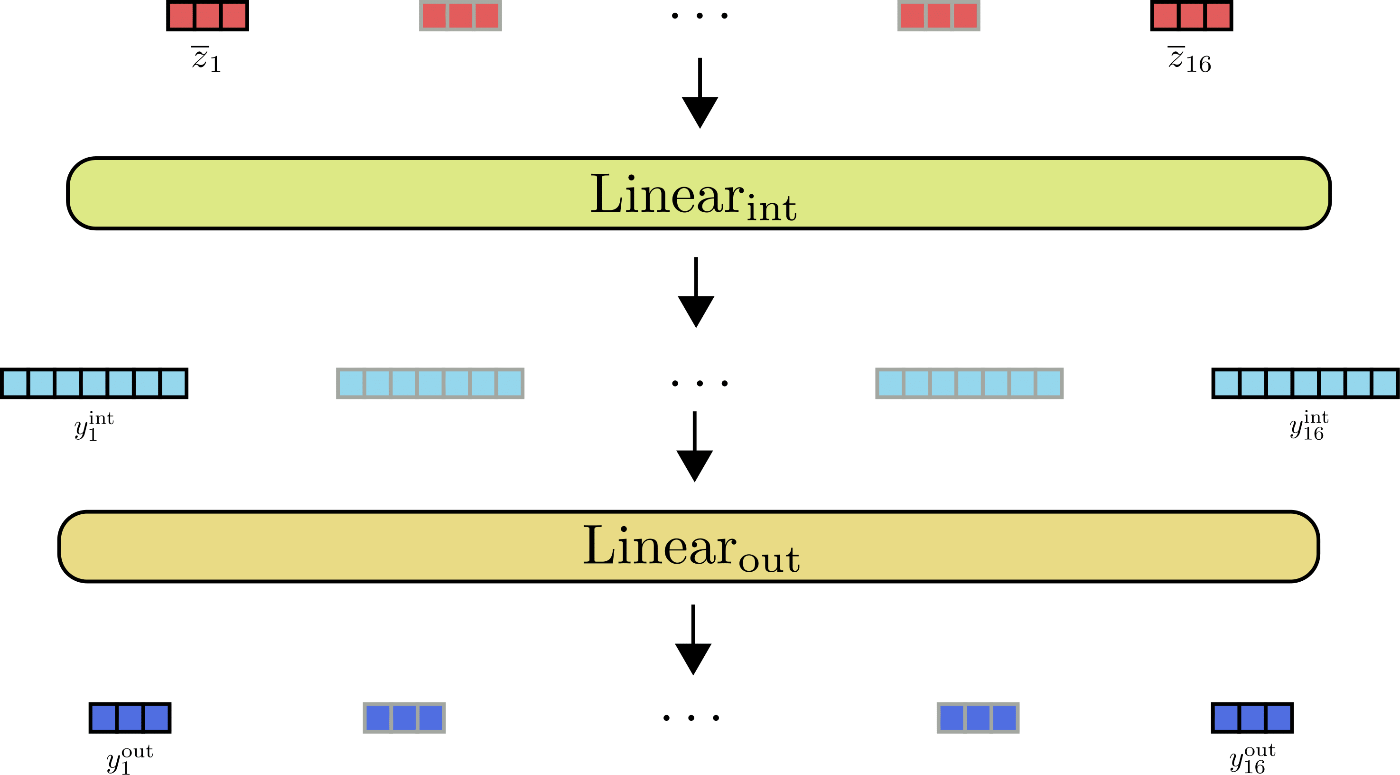
从图中可以看出,所有输入向量 \(\mathbf{\overline{z}}_{i}\) 均由同一前馈层并行处理。
我们再观察一下前馈层的输出维度,看看有没有啥有意思的事情。在 Reformer 中,\(\text{Linear}_{\text{int}}\) 的输出维度为 config.feed_forward_size , 即 \(d_ {f}\); 而 \(\text{Linear}_{\text{out}}\) 的输出维度为 config.hidden_size , 即 \(d_ {h}\)。
Reformer 作者观察到 \(^{2}\),在 transformer 模型中,中间维度 \(d_{f}\) 通常往往比输出维度 \(d_{h}\) 大许多。这意味着尺寸为 \(d_{f} \times n\) 的张量 \(\mathbf{\mathbf{Y}}_\text{int}\) 占据了大量的内存,甚至可能成为内存瓶颈。
为了更好地感受维度的差异,我们将本文例子中的矩阵 \(\mathbf{Y}_\text{int}\) 和 \(\mathbf{Y}_\text{out}\) 图示如下:
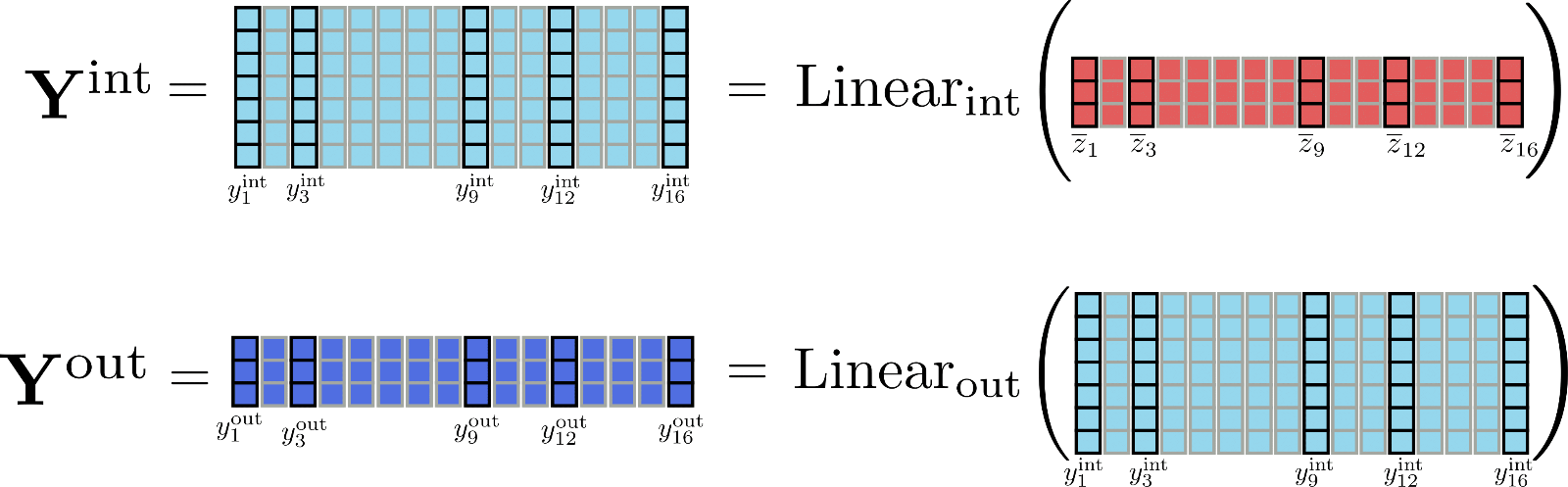
很明显,张量 \(\mathbf{Y} _\text{int}\) 比 \(\mathbf{Y}_{\text{out}}\) 占用了更多的内存 (准确地说,多占 \(\frac{d_{f}}{d_{h}} \times n\) 字节的内存)。但是,是否有必要存储完整的中间矩阵 \(\mathbf{Y}_\text{int}\) ?并非如此,因为我们关心的实际上只有输出矩阵 \(\mathbf{Y}_ \text{out}\)。为了以速度换内存,我们可以对线性层计算进行分块,一次只处理一个块。定义 config.chunk_size_feed_forward 为 \(c_{f}\),则分块线性层定义为 \(\mathbf{Y}_{\text{out}} = \left[\mathbf{Y}_{\text{out}, 1: c_{f}}, \ldots, \mathbf{Y}_{\text{out}, (n - c_{f}): n}\right]\) 即 \(\mathbf{Y}_{\text{out}, (c_{f} * i):(i * c_{f} + i)} = \text{Linear}_{\text{out}}( \text{Linear}_{\text{int}}(\mathbf{\overline{Z}}_{(c_{f} * i):(i * c_{f} + i)}))\)。这么做意味着我们可以增量计算输出最后再串接在一起,这样可以避免将整个中间张量 \(\mathbf{Y}_{\text{int}}\) 存储在内存中。
假设 \(c_{f}=1\),我们把增量计算 \(i=9\) 的过程图示如下:
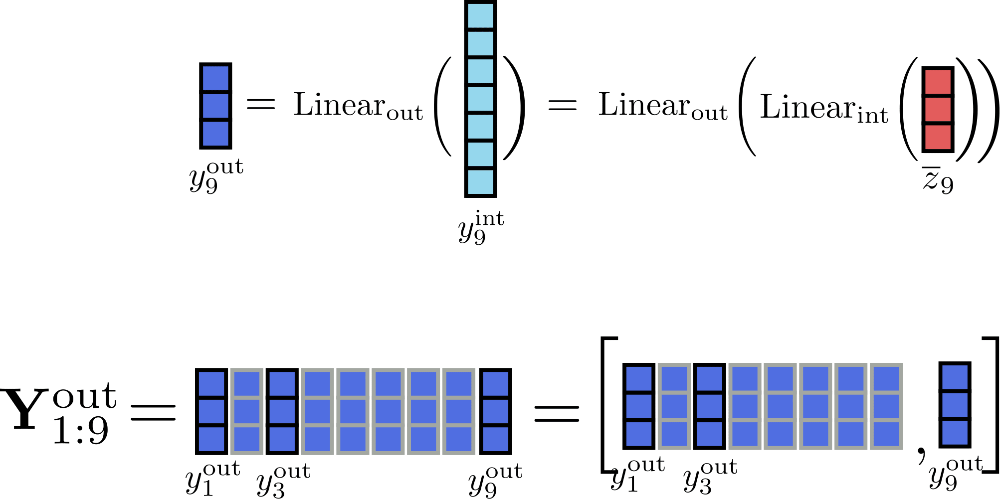
当块大小为 1 时,必须完整存储在内存中的唯一张量是大小为 \(16 \times d_{h}\) 的输入张量 \(\mathbf{\overline{Z}}\),其中 \(d_{h}\) 为 config.hidden_size 。而中间张量只需要存储大小为 \(d_{f}\) 的 \(\mathbf{y}_{\text{int}, i}\) 就可以了 \(^{3}\)。
最后,重要的是要记住, 分块线性层 与传统的完整线性层相比,其输出在数学上是等效的,因此可以应用于所有 transformer 线性层。因此,在某些场景下,可以考虑使用 config.chunk_size_feed_forward 在内存和速度之间进行更好的权衡。
\({}^1\) 为了简单起见,我们省略了前馈层之前的层归一化操作。
\({}^2\) 以 bert-base-uncased 为例,其中间维度 \(d_{f}\) 是 3072,为输出维度 \(d_{h}\) 的 4 倍。
\({}^3\) 提醒一下,为清晰说明起见,本文假设输出 config.num_attention_heads 为 1,因此假设自注意力层的输出大小为 config.hidden_size 。
读者也可以在 🤗Transformers 的 相应文档 中找到有关分块线性/前馈层的更多信息。
基准测试
我们测试一下使用分块前馈层可以节省多少内存。
#@title Installs and Imports
# pip installs
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, PyTorchBenchmark, PyTorchBenchmarkArguments
Building wheel for transformers (setup.py) ... [?25l[?25hdone
首先,我们将没有分块前馈层的默认 google/reformer-enwik8 模型与有分块前馈层的模型进行比较。
config_no_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8") # no chunk
config_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8", chunk_size_feed_forward=1) # feed forward chunk
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[1024, 2048, 4096], batch_sizes=[8], models=["Reformer-No-Chunk", "Reformer-Chunk"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_no_chunk, config_chunk], args=benchmark_args)
result = benchmark.run()
1 / 2
Doesn't fit on GPU. CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 11.17 GiB total capacity; 7.85 GiB already allocated; 1.74 GiB free; 9.06 GiB reserved in total by PyTorch)
2 / 2
Doesn't fit on GPU. CUDA out of memory. Tried to allocate 2.00 GiB (GPU 0; 11.17 GiB total capacity; 7.85 GiB already allocated; 1.24 GiB free; 9.56 GiB reserved in total by PyTorch)
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer-No-Chunk 8 1024 4281
Reformer-No-Chunk 8 2048 7607
Reformer-No-Chunk 8 4096 N/A
Reformer-Chunk 8 1024 4309
Reformer-Chunk 8 2048 7669
Reformer-Chunk 8 4096 N/A
--------------------------------------------------------------------------------
有趣的是,分块前馈层似乎在这里根本没有帮助。原因是 config.feed_forward_size 不够大,所以效果不明显。仅当序列长度较长 (4096) 时,才能看到内存使用量略有下降。
我们再看看如果将前馈层的大小增加 4 倍,并将注意力头的数量同时减少 4 倍,从而使前馈层成为内存瓶颈,此时峰值内存情形如何。
config_no_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8", chunk_size_feed_forward=0, num_attention_{h}eads=2, feed_forward_size=16384) # no chuck
config_chunk = ReformerConfig.from_pretrained("google/reformer-enwik8", chunk_size_feed_forward=1, num_attention_{h}eads=2, feed_forward_size=16384) # feed forward chunk
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[1024, 2048, 4096], batch_sizes=[8], models=["Reformer-No-Chunk", "Reformer-Chunk"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_no_chunk, config_chunk], args=benchmark_args)
result = benchmark.run()
1 / 2
2 / 2
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer-No-Chunk 8 1024 3743
Reformer-No-Chunk 8 2048 5539
Reformer-No-Chunk 8 4096 9087
Reformer-Chunk 8 1024 2973
Reformer-Chunk 8 2048 3999
Reformer-Chunk 8 4096 6011
--------------------------------------------------------------------------------
现在,对于较长的输入序列,可以看到峰值内存使用量明显减少。总之,应该注意的是,分块前馈层仅对于具有很少注意力头和较大前馈层的模型才有意义。
3. 可逆残差层
可逆残差层由 N. Gomez 等人 首先提出并应用在 ResNet 模型的训练上以减少内存消耗。从数学上讲,可逆残差层与 真正的 残差层略有不同,其不需要在前向传播期间保存激活,因此可以大大减少训练的内存消耗。
Reformer 中的可逆残差层
我们首先研究为什么模型训练比推理需要更多的内存。
在模型推理时,所需的内存差不多等于计算模型中 单个 最大张量所需的内存。而在训练模型时,所需的内存差不多等于所有可微张量的 总和。
如果读者已经理解了深度学习框架中的自动微分的工作原理,对此就比较容易理解了。多伦多大学 Roger Grosse 的这些 幻灯片 对大家理解自动微分很有帮助。
简而言之,为了计算可微函数 ( 如 一层) 的梯度,自动微分需要函数输出的梯度以及函数的输入、输出张量。虽然梯度是可以动态计算并随后丢弃的,但函数的输入和输出张量 ( 又名 激活) 需要在前向传播过程中被保存下来,以供反向传播时使用。
我们具体看下 transformer 模型中的情况。Transformer 模型是由多个 transformer 层堆叠起来的。每多一个 transformer 层都会迫使模型在前向传播过程中保存更多的激活,从而增加训练所需的内存。
我们细看一下 transformer 层。Transformer 层本质上由两个残差层组成。第一个残差层是第 1) 节中解释的 自注意力 机制,第二个残差层是第 2) 节中解释的 线性层 (或前馈层)。
使用与之前相同的符号,transformer 层的输入 即 \(\mathbf{X}\) 首先被归一化 \(^{1}\),然后经过自注意力层获得输出 \(\mathbf{Z} = \text{SelfAttn}(\text{LayerNorm}(\mathbf{X}))\)。为方便讨论,我们将这两层缩写为 \(G\),即 \(\mathbf{Z} = G(\mathbf{X})\)。
接下来,将残差 \(\mathbf{Z}\) 与输入相加 \(\mathbf{\overline{Z}} = \mathbf{Z} + \mathbf{X}\),得到张量输入到第二个残差层 —— 两个线性层。\(\mathbf{\overline{Z}}\) 经过第二个归一化层处理后,再经过两个线性层,得到 \(\mathbf{Y} = \text{Linear}(\text{LayerNorm}(\mathbf{Z} + \mathbf{X}))\)。我们将第二个归一化层和两个线性层缩写为 \(F\) ,得到 \(\mathbf{Y} = F(\mathbf{\overline{Z}})\)。最后,将残差 \(\mathbf{Y}\) 加到 \(\mathbf{\overline{Z}}\) 上得到 transformer 层的输出 \(\mathbf{\overline{Y}} = \mathbf{Y} + \mathbf{\overline{Z}}\)。
我们仍以 \(\mathbf{x}_1, \ldots, \mathbf{x}_{16}\) 为例对完整的 transformer 层进行图解。
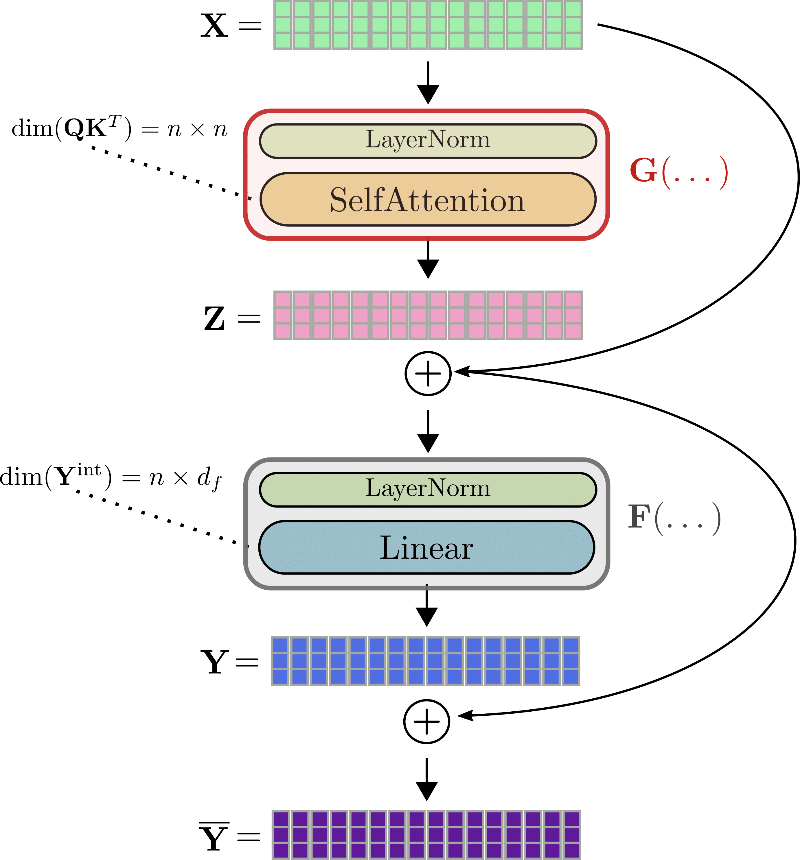
比如 ,要计算自注意力块 \(G\) 的梯度,必须事先知道三个张量: 梯度 \(\partial \mathbf{Z}\)、输出 \(\mathbf{Z}\) 以及输入 \(\mathbf{X}\)。虽然 \(\partial \mathbf{Z}\) 可以即时计算并随后丢弃,但 \(\mathbf{Z}\) 和 \(\mathbf{X}\) 必须在前向传播期间计算并保存下来,因为在反向传播期间比较难轻松地即时重新计算它们。因此,在前向传播过程中,大张量输出 (如查询 - 键点积矩阵 \(\mathbf{Q}\mathbf{K}^T\) 或线性层的中间输出 \(\mathbf{Y}^{\text{int}}\)) 必须保存在内存中 \(^{2}\)。
此时,可逆残差层就有用了。它的想法相对简单: 残差块的设计方式使得不必保存函数的输入和输出张量,而在反向传播期间就轻松地对二者进行重新计算,这样的话在前向传播期间就无需将这些张量保存在内存中了。
这是通过两个输入流 \(\mathbf{X}^{(1)}、\mathbf{X}^{(2)}\) 及两个输出流 \(\mathbf{\overline {Y}}^{(1)}、\mathbf{\overline{Y}}^{(2)}\) 来实现的。第一个残差 \(\mathbf{Z}\) 由第一个输出流 \(\mathbf{Z} = G(\mathbf{X}^{(1)})\) 算得,然后其加到第二个输入流的输入上,即 \(\mathbf{\overline{Z}} = \mathbf{Z} + \mathbf{X}^{(2)}\)。类似地,再将残差 \(\mathbf{Y} = F(\mathbf{\overline{Z}})\) 与第一个输入流相加。最终,两个输出流即为 \(\mathbf{Y}^{(1)} = \mathbf{Y} + \mathbf{X}^{(1)}\)、\(\mathbf{Y}^{(2)} = \mathbf{ X}^{(2)} + \mathbf{Z} = \mathbf{\overline{Z}}\)。
以 \(\mathbf{x}_1, \ldots, \mathbf{x}_{16}\) 为例来图示可逆 transformer 层,如下:
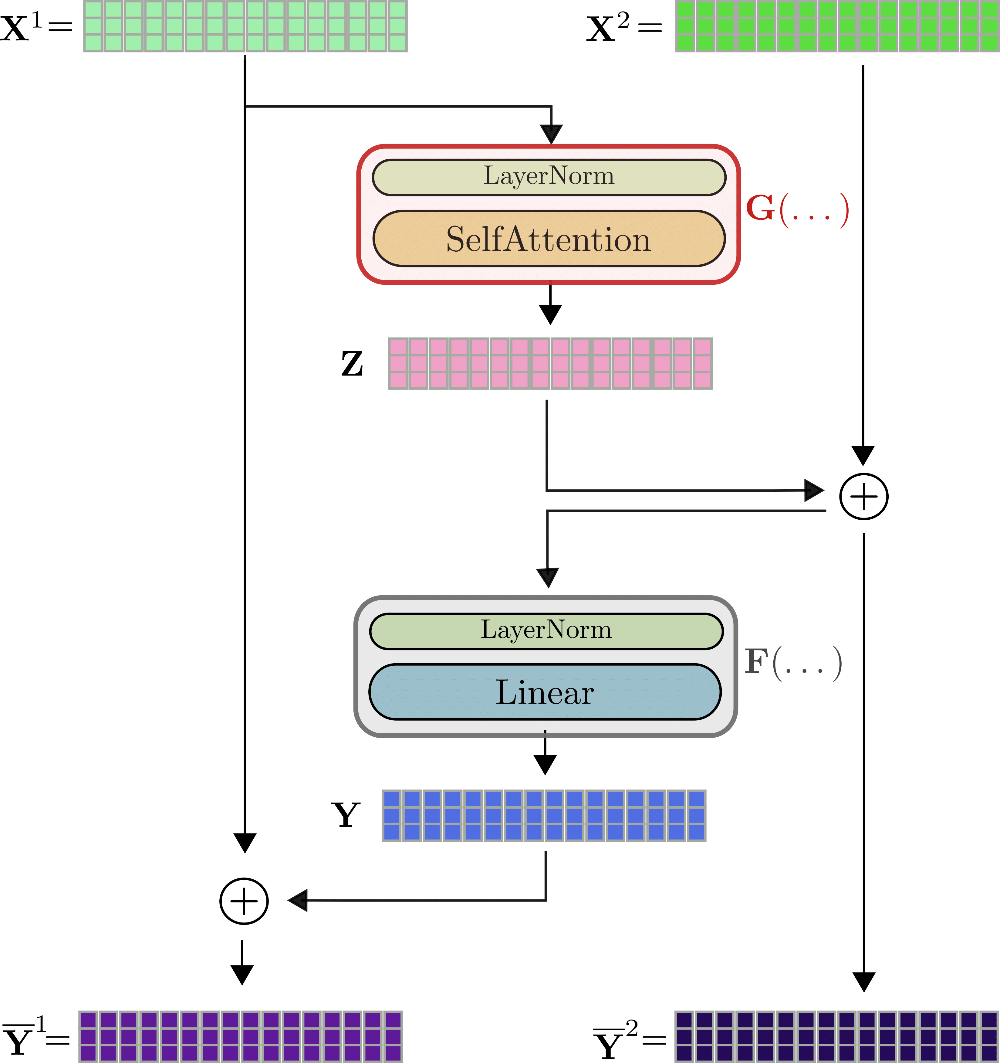
可以看出,输出 \(\mathbf{\overline{Y}}^{(1)}、\mathbf{\overline{Y}}^{(2)}\) 的计算方式与不可逆层 \(\mathbf{\overline{Y}}\) 的计算方式非常相似,但在数学上又不同。Reformer 的作者在一些初步实验中观察到,可逆 transformer 模型的性能与标准 transformer 模型的性能相当。与标准 transformer 层的一个明显区别是有两个输入流和输出流 \(^{3}\),这一开始反而稍微增加了前向传播所需的内存。但即使如此,我们还是强调双流架构至关重要,因为其在前向传播过程中无需保存任何激活。我们解释一下: 对于反向传播,可逆 treansformer 层必须计算梯度 \(\partial G\) 和 \(\partial F\)。除了可即时计算的梯度 \(\partial \mathbf{Y}\) 和 \(\partial \mathbf{Z}\) 之外,为了计算 \(\partial F\) 必须已知张量值 \(\mathbf{Y}\)、\(\mathbf{\overline{Z}}\),为了计算 \(\partial G\) 必须已知 \(\mathbf{Z}\) 和 \(\mathbf{X}^{(1)}\)。
假设我们知道 \(\mathbf{\overline{Y}}^{(1)},\mathbf{\overline{Y}}^{(2)}\),则从图中可以很容易看出,我们可以如下计算出 \(\mathbf{X}^{(1)},\mathbf{X}^{(2)}\) 。\(\mathbf{X}^{(1)} = F(\mathbf{\overline{Y}}^{(1)}) - \mathbf{\overline{Y}}^{(1)}\)。\(\mathbf{X}^{(1)}\) 计算出来了!然后,\(\mathbf{X}^{(2)}\) 可以通过 \(\mathbf {X}^{(2)} = \mathbf{\overline{Y}}^{(1)} - G(\mathbf{X}^{(1)})\) 算出。之后,\(\mathbf{Z}\) 和 \(\mathbf{Y}\) 的计算就简单了,可以通过 \(\mathbf{Y} = \mathbf{\overline{Y}}^{(1)} - \mathbf{X}^{(1)}\) 和 \(\mathbf{Z} = \mathbf{\overline{Y}}^{(2)} - \mathbf{X }^{(2)} 算出\)。总结一下,仅需在前向传播期间存储 最后一个 可逆 transformer 层的输出 \(\mathbf{\overline{Y}}^{(1)},\mathbf{\overline{Y}}^{(2)}\),所有其他层的激活就可以通过在反向传播期间使用 \(G\) 和 \(F\) 以及 \(\mathbf {X}^{(1)}\) 和 \(\mathbf{X}^{(2)}\) 推导而得。在反向传播期间,每个可逆 transformer 层用两次前向传播 \(G\) 和 \(F\) 的计算开销换取前向传播时不必保存任何激活。好买卖!
注意: 最近,主要的深度学习框架都支持了梯度检查点技术,以允许仅保存某些激活并在反向传播期间重计算尺寸较大的激活 (Tensoflow 代码见 此处,PyTorch 代码见 此处)。对于标准可逆层,这仍然意味着必须为每个 transformer 层保存至少一个激活,但通过定义哪些激活可以动态重新计算,能够节省大量内存。
\(^{1}\) 在前两节中,我们省略了自注意力层和线性层之前的层归一化操作。读者应该知道 \(\mathbf{X}\) 和 \(\mathbf{\overline{Z}}\) 在输入自注意力层和线性层之前都分别经过层归一化处理。
\(^{2}\) 在原始自注意力中,\(\mathbf{Q}\mathbf{K}\) 的维度为 \(n \times n\); 而在 LSH 自注意力 或 局部自注意力 层的维度为 \(n \times l_{c} \times n_{h}\) 或 \(n \times l_{c}\) 其中 \(l_{c}\) 为块长度,\(n_{h}\) 为哈希数。
\(^{3}\) 第一个可逆 transformer 层的 \(\mathbf{X}^{(2)}\) 等于 \(\mathbf{X}^{(1)}\)。
测试基准
为了测量可逆残差层的效果,我们将增加模型层数的同时比较 BERT 和 Reformer 的内存消耗。
#@title Installs and Imports
# pip installs
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, BertConfig, PyTorchBenchmark, PyTorchBenchmarkArguments
我们把标准 bert-base-uncased BERT 模型的层数从 4 增加到 12 ,同时测量其所需内存。
config_4_layers_bert = BertConfig.from_pretrained("bert-base-uncased", num_hidden_layers=4)
config_8_layers_bert = BertConfig.from_pretrained("bert-base-uncased", num_hidden_layers=8)
config_12_layers_bert = BertConfig.from_pretrained("bert-base-uncased", num_hidden_layers=12)
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[512], batch_sizes=[8], models=["Bert-4-Layers", "Bert-8-Layers", "Bert-12-Layers"], training=True, no_inference=True, no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_4_layers_bert, config_8_layers_bert, config_12_layers_bert], args=benchmark_args)
result = benchmark.run()
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=433.0, style=ProgressStyle(description_…
1 / 3
2 / 3
3 / 3
==================== TRAIN - MEMORY - RESULTS ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Bert-4-Layers 8 512 4103
Bert-8-Layers 8 512 5759
Bert-12-Layers 8 512 7415
--------------------------------------------------------------------------------
可以看出,BERT 层数每增加 1,其所需内存就会有超 400MB 的线性增长。
config_4_layers_reformer = ReformerConfig.from_pretrained("google/reformer-enwik8", num_hidden_layers=4, num_hashes=1)
config_8_layers_reformer = ReformerConfig.from_pretrained("google/reformer-enwik8", num_hidden_layers=8, num_hashes=1)
config_12_layers_reformer = ReformerConfig.from_pretrained("google/reformer-enwik8", num_hidden_layers=12, num_hashes=1)
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[512], batch_sizes=[8], models=["Reformer-4-Layers", "Reformer-8-Layers", "Reformer-12-Layers"], training=True, no_inference=True, no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_4_layers_reformer, config_8_layers_reformer, config_12_layers_reformer], args=benchmark_args)
result = benchmark.run()
1 / 3
2 / 3
3 / 3
==================== TRAIN - MEMORY - RESULTS ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer-4-Layers 8 512 4607
Reformer-8-Layers 8 512 4987
Reformer-12-Layers 8 512 5367
--------------------------------------------------------------------------------
另一方面,对于 Reformer 而言,每增加一层所带来的内存增量会显著减少,平均不到 100MB。因此 12 层的 reformer-enwik8 模型比 12 层的 bert-base-uncased 模型的内存需求更少。
4. 轴向位置编码
Reformer 使得处理超长输入序列成为可能。然而,对于如此长的输入序列,仅存储标准位置编码权重矩阵就需要超过 1GB 内存。为了避免如此大的位置编码矩阵,官方 Reformer 代码引入了 轴向位置编码 。
重要: 官方论文中没有解释轴向位置编码,但通过阅读代码以及与作者讨论我们很好地理解了它。
Reformer 中的轴向位置编码
Transformer 需要位置编码来对输入序列中的单词顺序进行编码,因为自注意力层 没有顺序的概念 。位置编码通常由一个简单的查找矩阵 \(\mathbf{E} = \left[\mathbf{e}_1, \ldots, \mathbf{e}_{n_\text{max}}\right]\) 来定义,然后将位置编码向量 \(\mathbf{e}_{i}\) 简单地加到 第 i 个 输入向量上,即 \(\mathbf{x}_{i} + \mathbf{e}_{i}\),以便模型可以区分输入向量 ( 即 词元) 位于位置 \(i\) 还是位置\(j\)。对于每个输入位置,模型需要能够查找到相应的位置编码向量,因此 \(\mathbf{E}\) 的维度由模型可以处理的最大输入序列长度 config.max_position_embeddings ( 即 \(n_\text{max}\)) 以及输入向量的维度 config.hidden_size ( 即 \(d_{h}\)) 共同决定。
假设 \(d_{h}=4\),\(n_\text{max}=49\),其位置编码矩阵如下图所示:

此处,我们仅展示位置编码 \(\mathbf{e}_{1}\)、\(\mathbf{e}_{2}\) 及 \(\mathbf{e}_{49}\),其维度 ( 即 高度) 为 4。
想象一下,我们想要在长度最长为 0.5M 个词元,输入向量维度 config.hidden_size 为 1024 的序列上训练 Reformer 模型 (请参阅 此笔记本)。其对应的位置嵌入的参数量为 \(0.5M \times 1024 \sim 512M\),大小为 2GB。
在将模型加载到内存中或将其保存在硬盘上时,所需要的内存是很大且很没必要的。
Reformer 作者通过将 config.hidden_size 维度一分为二,并巧妙地对 \(n_\text{max}\) 维进行分解,从而成功地大幅缩小了位置编码的大小。在 transformers 中,用户可以将 config.axis_pos_shape 设置为一个含有两个值的列表: \(n_\text{max}^ 1\)、\(n_\text{max}^2\),其中 \(n_\text{max}^1 \times n_\text{max}^2 = n_\text{max}\),从而对 \(n_\text{max}\) 维度进行分解。同时,用户可以把 config.axis_pos_embds_dim 设置为一个含有两个值 \(d_{h}^{1}\) 和 \(d_{h}^2\) 的列表,其中 \(d_{h} ^1 + d_{h}^2 = d_{h}\),从而决定隐藏维度应该如何切割。下面用图示来直观解释一下。
大家可以将对 \(n_{\text{max}}\) 的分解视为将其维度折叠到第三个轴,下图所示为 config.axis_pos_shape = [7, 7] 分解:
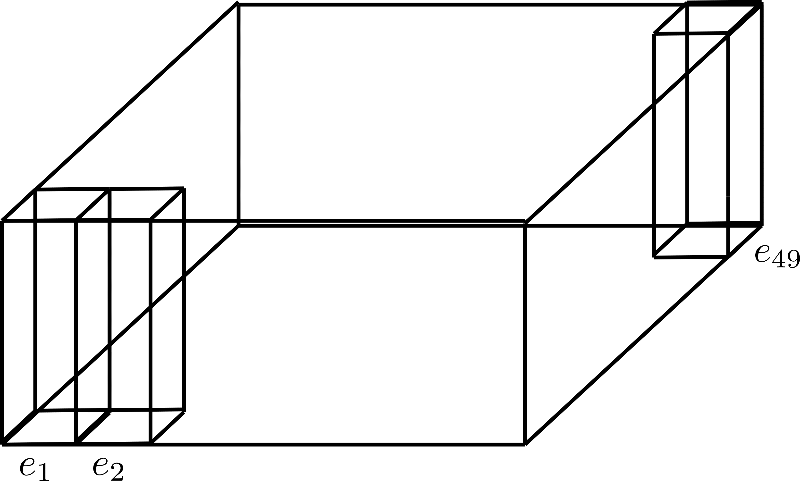
三个直立矩形棱柱分别对应于编码向量 \(\mathbf{e}_{1}, \mathbf{e}_{2}, \mathbf{e}_{49}\),我们可以看到 49 个编码向量被分为 7 行,每行 7 个向量。现在的想法是仅使用 7 个编码向量中的一行,并将这些向量扩展到其他 6 行。本质上是想让七行重用一行的值,但是又不能让不同位置的编码向量的值相同,所以要将每个维度 ( 或称 高度) 为 config.hidden_size=4 的向量切割成两个部分: 大小为 \(1\) 的低区编码向量 \(\mathbf{e}_\text{down}\) 以及大小为 \(3\) 的高区编码向量 \(\mathbf{e}_\text{up}\),这样低区就可以沿行扩展而高区可以沿列扩展。为了讲清楚,我们还是画个图。
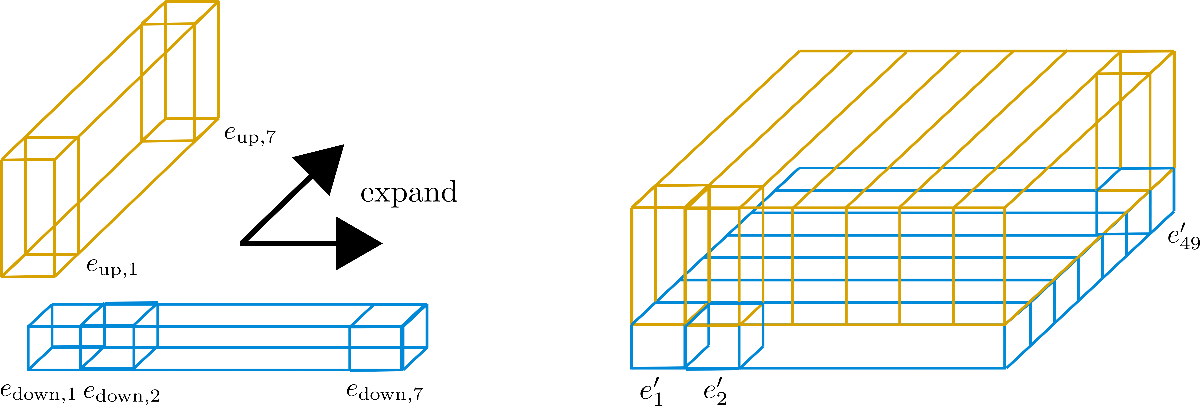
可以看到,我们已将嵌入向量切为 \(\mathbf{e}_\text{down}\) ( 蓝色 ) 和 \(\mathbf{e}_\text{up}\) ( 黄色 ) 两个部分。现在对 子 向量 \(\mathbf{E} _\text{down} = \left[\mathbf{e}_ {\text{down},1}, \ldots, \mathbf{e} _{\text{down},49}\right]\) 仅保留第一行的 7 个子向量, 即 图中宽度,并将其沿列 ( 又名 深度) 扩展。相反,对 子 向量 \(\mathbf{E}_\text{up} = \left[\mathbf{e}_{\text{up},1}, \ldots, \mathbf{e }_{\text{up},49}\right]\) 仅保留第一列的 \(7\) 个子向量并沿行扩展。此时,得到的嵌入向量 \(\mathbf{e'}_{i}\) 如下:
本例中,\(n_\text{max}^1 = 7\),\(n_\text{max}^2 = 7\) 。这些新编码 \(\mathbf{E'} = \left[\mathbf{e'}_{1}, \ldots, \mathbf{e'}_{n_\text{max}}\right]\) 称为 轴向位置编码。
下图针对我们的例子对轴向位置编码进行了更详细的说明。
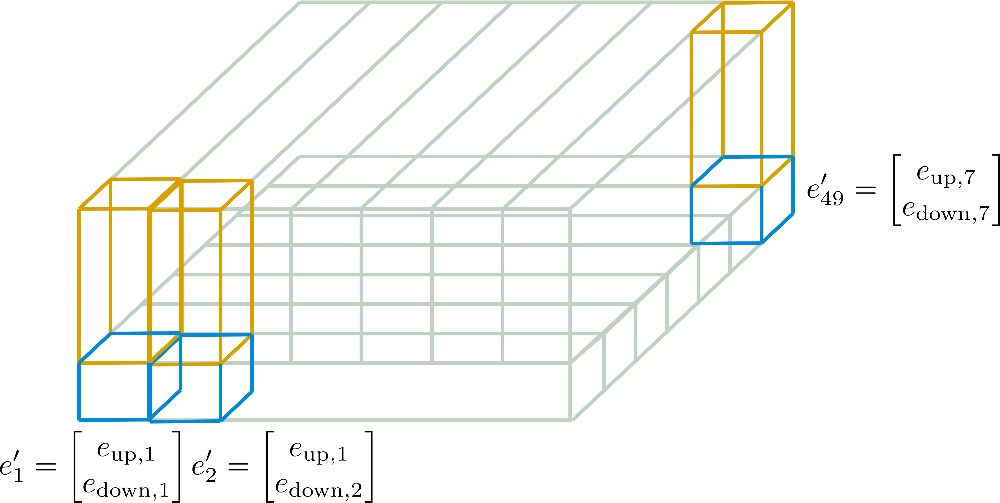
现在应该很清楚如何仅根据维度为 \(d_{h}^1 \times n_{\text{max}^1}\) 的 \(\mathbf{E}_{\text{down}}\) 及维度为 \(d_{h}^2 \times n_{\text{max}}^2\) 的 \(\mathbf{E}_{\text{up}}\) 计算最终位置编码向量 \(\mathbf{E'}\) 了。
这里的关键是,轴向位置编码能够从设计上确保向量 \(\left[\mathbf{e'}_1, \ldots, \mathbf{e'}_{n_{\text{max} }}\right]\) 之间各不相等,并且使编码矩阵的大小从 \(n_{\text{max}} \times d_{h}\) 减小到 \(n_{\text{max}}^1 \times d_{h}^1 + n_\text{max}^2 \times d_{h}^2\)。因为设计上允许每个轴向位置编码向量不同,所以一旦模型中的轴向位置编码训出来后,模型就可以灵活高效地获取位置编码。
为了证明位置编码矩阵的尺寸得到了大幅减小,假设我们为 Reformer 模型设置了参数 config.axis_pos_shape = [1024, 512] 以及 config.axis_pos_embds_dim = [512, 512] ,且该模型支持的最长输入序列长度为 0.5M 词元。此时,生成的轴向位置编码矩阵的参数量仅为 \(1024 \times 512 + 512 \times 512 \sim 800K\),即大约 3MB。这个数字与标准位置编码矩阵所需的 2GB 相比,简直是小巫见大巫。
如需更简洁、更数学化的解释,请参阅 此处 的 🤗Transformers 文档。
基准测试
最后,我们对传统位置嵌入与 轴向位置嵌入 的峰值内存消耗进行比较。
#@title Installs and Imports
# pip installs
!pip -qq install git+https://github.com/huggingface/transformers.git
!pip install -qq py3nvml
from transformers import ReformerConfig, PyTorchBenchmark, PyTorchBenchmarkArguments, ReformerModel
位置嵌入仅取决于两个配置参数: 输入序列允许的最大长度 config.max_position_embeddings 以及 config.hidden_size 。我们使用一个模型,其支持的输入序列的最大允许长度为 50 万个词元,即 google/reformer-crime-and-punishment ,来看看使用轴向位置嵌入后的效果。
首先,我们比较轴向位置编码与标准位置编码的参数形状,及其相应模型的总参数量。
config_no_pos_axial_embeds = ReformerConfig.from_pretrained("google/reformer-crime-and-punishment", axial_pos_embds=False) # disable axial positional embeddings
config_pos_axial_embeds = ReformerConfig.from_pretrained("google/reformer-crime-and-punishment", axial_pos_embds=True, axial_pos_embds_dim=(64, 192), axial_pos_shape=(512, 1024)) # enable axial positional embeddings
print("Default Positional Encodings")
print(20 *'-')
model = ReformerModel(config_no_pos_axial_embeds)
print(f"Positional embeddings shape: {model.embeddings.position_embeddings}")
print(f"Num parameters of model: {model.num_parameters()}")
print(20 *'-' + '\n\n')
print("Axial Positional Encodings")
print(20 *'-')
model = ReformerModel(config_pos_axial_embeds)
print(f"Positional embeddings shape: {model.embeddings.position_embeddings}")
print(f"Num parameters of model: {model.num_parameters()}")
print(20 *'-' + '\n\n')
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=1151.0, style=ProgressStyle(description…
Default Positional Encodings
--------------------
Positional embeddings shape: PositionEmbeddings(
(embedding): Embedding(524288, 256)
)
Num parameters of model: 136572416
--------------------
Axial Positional Encodings
--------------------
Positional embeddings shape: AxialPositionEmbeddings(
(weights): ParameterList(
(0): Parameter containing: [torch.FloatTensor of size 512x1x64]
(1): Parameter containing: [torch.FloatTensor of size 1x1024x192]
)
)
Num parameters of model: 2584064
--------------------
理解了相应的理论后,读者应该不会对轴向位置编码权重的形状感到惊讶。
从结果中可以看出,对于需要处理如此长输入序列的模型,使用标准位置编码是不切实际的。以 google/reformer-crime-and-punishment 为例,仅标准位置编码自身参数量就超过 100M。轴向位置编码可以将这个数字减少到略高于 200K。
最后,我们比较一下推理所需内存。
benchmark_args = PyTorchBenchmarkArguments(sequence_lengths=[512], batch_sizes=[8], models=["Reformer-No-Axial-Pos-Embeddings", "Reformer-Axial-Pos-Embeddings"], no_speed=True, no_env_print=True)
benchmark = PyTorchBenchmark(configs=[config_no_pos_axial_embeds, config_pos_axial_embeds], args=benchmark_args)
result = benchmark.run()
1 / 2
2 / 2
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
Reformer-No-Axial-Pos-Embeddin 8 512 959
Reformer-Axial-Pos-Embeddings 8 512 447
--------------------------------------------------------------------------------
可以看出,在 google/reformer-crime-and-punishment 模型上,使用轴向位置嵌入可减少大约一半的内存需求。
英文原文: https://hf.co/blog/reformer
原文作者: Patrick von Platen
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号