基于 Habana Gaudi 的 Transformers 入门
几周前,我们很高兴地 宣布 Habana Labs 和 Hugging Face 将开展加速 transformer 模型的训练方面的合作。
与最新的基于 GPU 的 Amazon Web Services (AWS) EC2 实例相比,Habana Gaudi 加速卡在训练机器学习模型方面的性价比提高了 40%。我们非常高兴将这种性价比优势引入 Transformers 🚀。
本文,我将手把手向你展示如何在 AWS 上快速设置 Habana Gaudi 实例,并用其微调一个用于文本分类的 BERT 模型。与往常一样,我们提供了所有代码,以便你可以在自己的项目中重用它们。
我们开始吧!
在 AWS 上设置 Habana Gaudi 实例
使用 Habana Gaudi 加速卡的最简单方法是启动一个 AWS EC2 DL1 实例。该实例配备 8 张 Habana Gaudi 加速卡,借助 Habana 深度学习镜像 (Amazon Machine Image,AMI) ,我们可以轻松把它用起来。该 AMI 预装了 Habana SynapseAI® SDK 以及运行 Gaudi 加速的 Docker 容器所需的工具。如果你想使用其他 AMI 或容器,请参阅 Habana 文档 中的说明。
我首先登陆 us-east-1 区域的 EC2 控制台,然后单击 启动实例 并给实例起个名字 (我用的是 “habana-demo-julsimon”)。
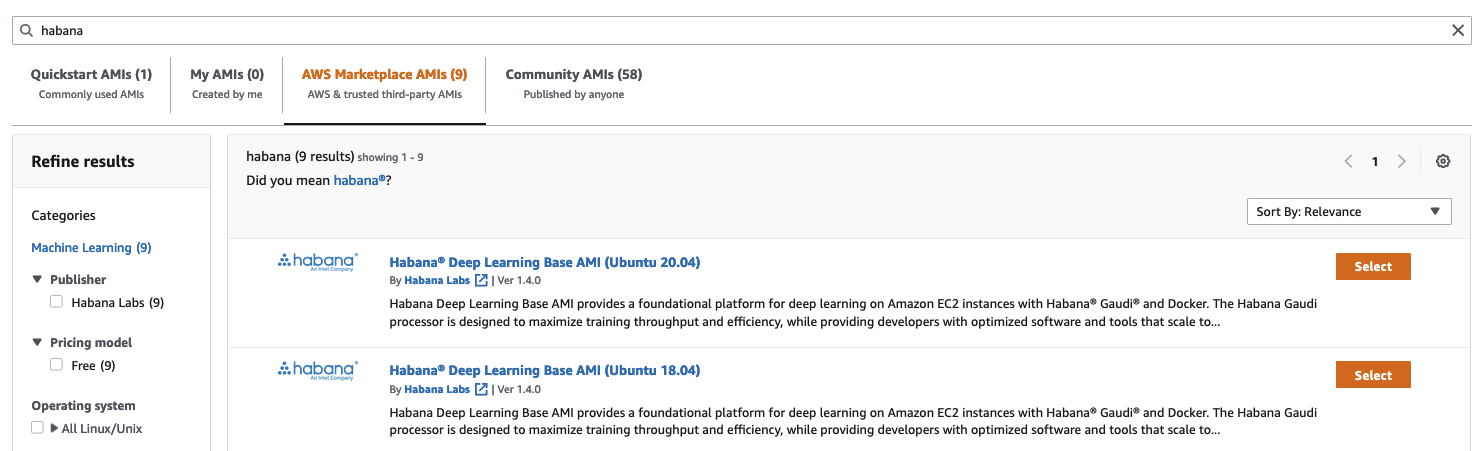
然后,我在 Amazon Marketplace 中搜索 Habana AMI。
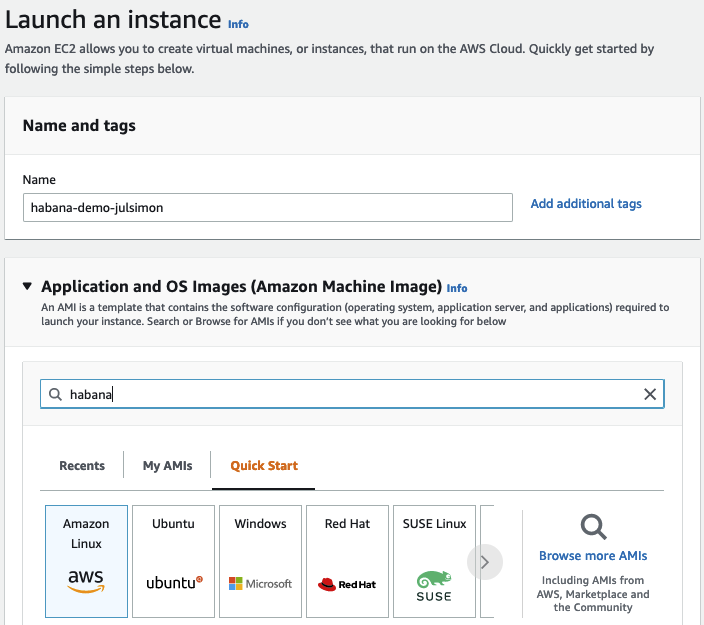
这里,我选择了 Habana Deep Learning Base AMI (Ubuntu 20.04)。
接着,我选择了 dl1.24xlarge 实例 (实际上这是唯一可选的实例)。
接着是选择 ssh 密钥对。如果你没有密钥对,可以就地创建一个。
下一步,要确保该实例允许接受 ssh 传输。为简单起见,我并未限制源地址,但你绝对应该在你的帐户中设置一下,以防止被恶意攻击。

默认情况下,该 AMI 将启动一个具有 8GB Amazon EBS 存储的实例。但这对我来说可能不够,因此我将存储空间增加到 50GB。
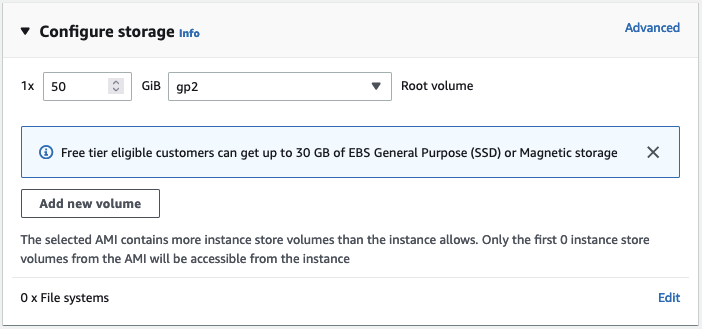
接下来,我需要为该实例分配一个 Amazon IAM 角色。在实际项目中,此角色应具有运行训练所需的最低权限组合,例如从 Amazon S3 存储桶中读取数据的权限。但在本例中,我们不需要这个角色,因为数据集是从 Hugging Face Hub 上下载的。如果您不熟悉 IAM,强烈建议阅读这个 入门 文档。
然后,我要求 EC2 将我的实例配置为 Spot 实例,这可以帮我降低每小时使用成本 (非 Spot 实例每小时要 13.11 美元)。
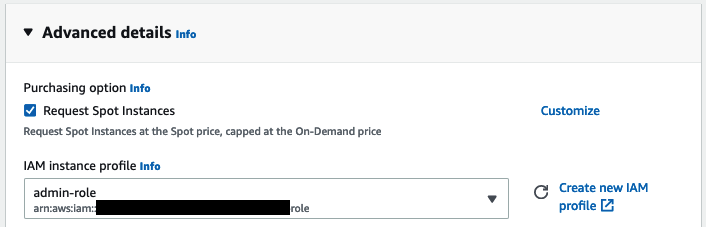
最后,启动实例。几分钟后,实例已准备就绪,我可以使用 ssh 连上它了。Windows 用户可以按照 文档 使用 PuTTY 来连接。
ssh -i ~/.ssh/julsimon-keypair.pem ubuntu@ec2-18-207-189-109.compute-1.amazonaws.com
在实例中,最后一步是拉取一个 Habana PyTorch 容器,我后面会用 PyTorch 来微调模型。你可以在 Habana 文档 中找到有关其他预构建容器以及如何构建自己的容器的信息。
docker pull \
vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
将 docker 镜像拉到实例后,我就可以用交互模式运行它。
docker run -it \
--runtime=habana \
-e HABANA_VISIBLE_DEVICES=all \
-e OMPI_MCA_btl_vader_single_copy_mechanism=none \
--cap-add=sys_nice \
--net=host \
--ipc=host vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
至此,我就准备好可以微调模型了。
在 Habana Gaudi 上微调文本分类模型
首先,在刚刚启动的容器内拉取 Optimum Habana 存储库。
git clone https://github.com/huggingface/optimum-habana.git
然后,从源代码安装 Optimum Habana 软件包。
cd optimum-habana
pip install .
接着,切到包含文本分类示例的子目录并安装所需的 Python 包。
cd examples/text-classification
pip install -r requirements.txt
现在可以启动训练了,训练脚本首先从 Hugging Face Hub 下载 bert-large-uncased-whole-word-masking 模型,然后在 GLUE 基准的 MRPC 任务上对其进行微调。
请注意,我用于训练的 BERT 配置是从 Hugging Face Hub 获取的,你也可以使用自己的配置。此外,Gaudi1 还支持其他流行的模型,你可以在 Habana 的网页上 中找到它们的配置文件。
python run_glue.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--gaudi_config_name Habana/bert-large-uncased-whole-word-masking \
--task_name mrpc \
--do_train \
--do_eval \
--per_device_train_batch_size 32 \
--learning_rate 3e-5 \
--num_train_epochs 3 \
--max_seq_length 128 \
--use_habana \
--use_lazy_mode \
--output_dir ./output/mrpc/
2 分 12 秒后,训练完成,并获得了 0.9181 的 F1 分数,相当不错。你还可以增加 epoch 数,F1 分数肯定会随之继续提高。
***** train metrics *****
epoch = 3.0
train_loss = 0.371
train_runtime = 0:02:12.85
train_samples = 3668
train_samples_per_second = 82.824
train_steps_per_second = 2.597
***** eval metrics *****
epoch = 3.0
eval_accuracy = 0.8505
eval_combined_score = 0.8736
eval_f1 = 0.8968
eval_loss = 0.385
eval_runtime = 0:00:06.45
eval_samples = 408
eval_samples_per_second = 63.206
eval_steps_per_second = 7.901
最后一步但也是相当重要的一步,用完后别忘了终止 EC2 实例以避免不必要的费用。查看 EC2 控制台中的 Saving Summary,我发现由于使用 Spot 实例,我节省了 70% 的成本,每小时支付的钱从原先的 13.11 美元降到了 3.93 美元。
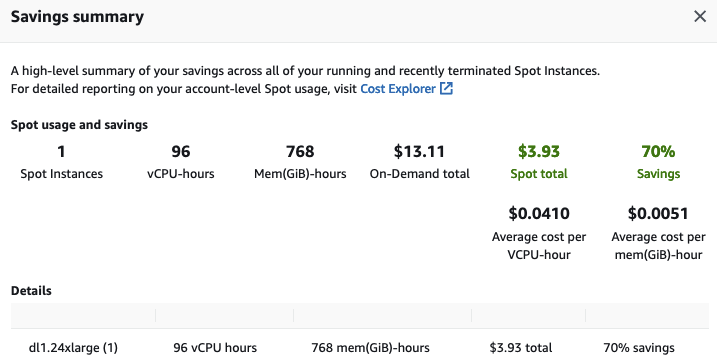
如你所见,Transformers、Habana Gaudi 和 AWS 实例的组合功能强大、简单且经济高效。欢迎大家尝试,如果有任何想法,欢迎大家在 Hugging Face 论坛 上提出问题和反馈。
如果你想了解更多有关在 Gaudi 上训练 Hugging Face 模型的信息,请 联系 Habana。
英文原文: https://hf.co/blog/getting-started-habana
原文作者: Julien Simon
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号