[性能优化] perf 高级用法:完整记录程序性能指标,并按照时间段对程序进行有针对性的性能分析
如题:
假设你已经熟悉了基本用法,知道perf是干嘛的,以及会用 perf top
[性能优化] perf
背景:目标程序在运行的某时间段内会出现性能下降,需要了解这个时间内,程序发生了什么。
方法:
1. 按时间轴记录下性能变化数据。
2. 同时记录下当时的perf数据,使用perf record
3. 按照时间轴进行对比,对特定时间段内的perf数据进行分析。使用perf report。
1. 因为perf data内目前不能记录wall clock time。所以需要保证同时启动(关闭)性能变化的记录程序和perf record。之后才能对应时间轴。
编译的时候最好加编译选项“” -O0 -ggdb“”
记录性能变化的脚本:(这个脚本是用来抽样检测性能数据的)
[root@vm perf-4]# ../forward/forward.sh |tee perf.log
#! /bin/bash date old_value=`/root/cli-client getPortStatus 0 |awk -F '[=,]' '{if($12=="'\''all'\''") print $22}'` old_date_value=`date +%s` while true : do sleep 5 value=`/root/cli-client getPortStatus 0 |awk -F '[=,]' '{if($12=="'\''all'\''") print $22}'` date_value=`date +%s` conn_count=`/root/cli-client nlb_conn_count` x_value=`expr $value - $old_value` x_date_value=`expr $date_value - $old_date_value` old_value=$value old_date_value=$date_value output=`echo "scale=2; $x_value / $x_date_value" | bc -l` echo -e "$date_value\t$output\t$conn_count" done
perf record的用法:
对于多线程程序,找到要调试的线程id
[root@vm perf-4]# top -n 1 -H -p 24981
运行perf:
T:保留时间戳。g:记录调用树。
[root@vmnlb perf-4]# perf record -Tgs -t 25006,25007,25008,25009
perf record会在当前目录生成文件perf.data
查看时间轴: 可见: 时间为:79627到80301
[root@vm perf-4]# perf script -i perf.data |head lcore-slave-1 25006 79627.186181: 1 cycles: 7fff8105ad5a native_write_msr_safe ([kernel.kallsyms]) 7fff81032bfc intel_pmu_enable_all ([kernel.kallsyms]) 7fff8102d284 x86_pmu_enable ([kernel.kallsyms]) 7fff8115d4b7 perf_pmu_enable ([kernel.kallsyms]) 7fff8102b459 x86_pmu_commit_txn ([kernel.kallsyms]) 7fff8115e620 group_sched_in ([kernel.kallsyms]) 7fff8115eabf __perf_event_enable ([kernel.kallsyms]) 7fff81159be0 remote_function ([kernel.kallsyms]) 7fff810e8a1d flush_smp_call_function_queue ([kernel.kallsyms]) [root@vmnlb perf-4]# perf script -i perf.data |tail -n 100 lcore-slave-4 25009 80301.104199: 622239 cycles: 7fff8163ec99 _raw_spin_lock_irq ([kernel.kallsyms]) 7fff810f236c acct_collect ([kernel.kallsyms]) 7fff8108345f do_exit ([kernel.kallsyms])
分析对应了时间轴之后的,性能日志:(根据前文中的forward.sh作出的抽样数据,可以生成如下的频率图。)
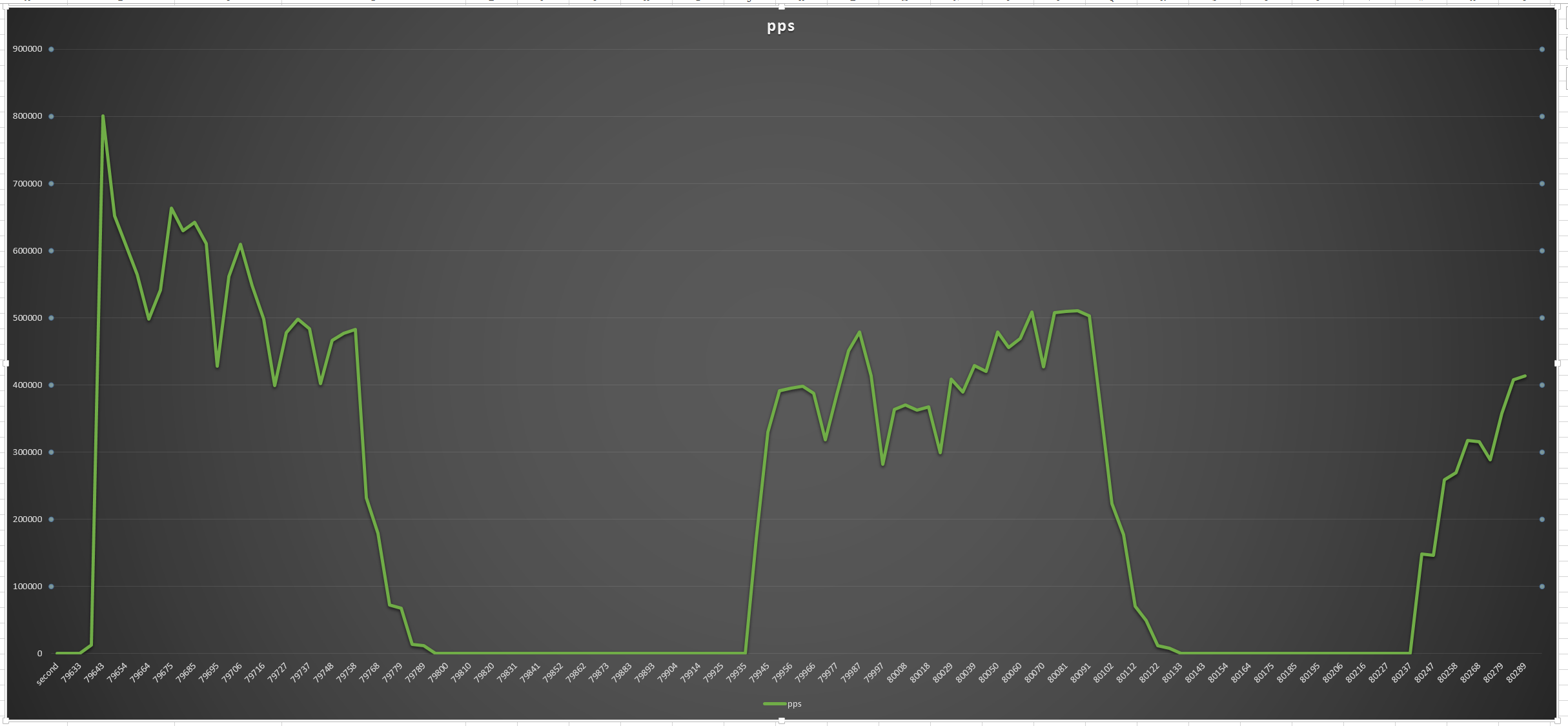
使用 perf report:
--sort参数很重要,用来指定不同的统计维度,维度不同的时候,累计值也不同,所以如果选择了错误的维度,很可能忽略问题。
--no-children与--children是一对互逆的配置,可以影响统计排序,也很重要。参考:https://stackoverflow.com/questions/31567272/sorting-by-self-column-in-perf-report?utm_medium=organic&utm_source=google_rich_qa&utm_campaign=google_rich_qa
[root@vm perf-4]# perf report --time 79830,79940
[root@vm perf-4]# perf report --time 79830,79940 -s sym [root@vm perf-4]# perf report --time 79830,79940 -s sym --no-children

 浙公网安备 33010602011771号
浙公网安备 33010602011771号