(9) MySQL主主复制架构使用方法
一. 回忆主从复制的一些缺点
上节说到主从复制的一些问题
我们再来回忆一下
主从复制,增加了一个数据库副本,从数据库和主数据库的数据最终会是一致的
之所以说是最终一致,因为mysql复制是异步的,正常情况下主从复制数据之间会有一个微小的延迟
通过这个数据库副本看似解决了数据库单点问题,但并不完美
因为这种架构下,如果主服务器宕机,需要手动切换从服务器,业务中断不能忍受,不能满足应用高可用的要求
如果才能解决当master服务器宕机后,前端应用自动切换链接呢?
二. 引入vip后的数据库架构
最简单的方式就是给数据库复制集群上增加一个虚拟ip
虚拟IP(vip):
就是一个未分配给真实主机的ip,也就是说对外提供服务器的主机除了有一个真实IP外还有一个虚拟IP
而前端应用程序使用虚拟ip来链接数据库服务器,当master宕机后,虚拟ip由masterDB迁移到slaveDB上,这样就不用人为的修改前端应用的配置了
设置虚拟IP有很多种方法
除了脚本来实现这些功能,还可以通过MHA,MMM这样的集群管理工具来实现
此处采用keepalived来配置虚拟ip
首先,keepalived可以提供vip,并对主从数据库的健康状态进行监控
当主DB宕机时,迁移VIP到主备数据库服务器上,这样就解决了当masterDB宕机时,要手动修改应用服务器的配置,从新连接到主备服务器上的问题
但是目前还存在一个问题,当master恢复后,由于当前的写操作迁移到了从上,所以如果要使用到老的master对新的master(也就是老的slave)进行同步,就不得不重新配置主从复制了,特别是在基于日志点的复制情况下,这时候如果我们数据库的数据量非常大,在这种情况下,重新初始化数据也是比较耗时的
所以我们要对主从复制的架构进行一些更改,改变原来的主从复制为主主复制,但一定要保证同一个时间只有一个主提供服务,而另一个主(也就是主备)是处于只读状态的,只对外提供读服务,而不提供写服务
以前说过InnoDB表的主键最好采用自增ID的列,而在主主复制中,为了避免两个主中同时写带来的主键冲突,我们需要修改自增主键的一些配置,使两个主上的自增主键按照不同的步长进行增长 ,这只是为了以防万一采取的一个配置,当我们使用主主复制时,还是要保证在任意时间,均只有一个主可以对外提供服务 ,而另一个主只提供只读的服务
三. 主主复制配置调整
master 数据库配置修改
auto_increment_increment = 2 # 控制自增ID增长的步长,默认为1
auto_increment_offset = 1 # 控制自增ID从哪个值开始
这样修改后,id将会变成1,3,7,9...的形式
主备数据库配置修改
auto_increment_increment = 2 # 控制自增ID增长的步长,默认为1
auto_increment_offset = 2 # 控制自增ID从哪个值开始
这样修改后,id将会变成2,4,6,8...的形式
Keepalived简介
Keepalived基于ARRP网络协议,ARRP可以将2台设备虚拟成一个设备,可对外提供一个虚拟IP,也就是我们架构中的vip,在服务器内部实际上是拥有虚拟IP的设备如果正常工作的话就是MASTER设备,同一组内其他服务器不能用这个虚拟IP,状态是属于BACKUP状态,处于BACKUP状态的设备,除了接收MASTER的ARRP状态通告之外,不执行任何对外的服务,当主机失效时,backup将接管原先的master的虚拟IP以及对外提供的各项服务
安装
yum install keepalived -y
keepalived配置
在主和主备服务器上都要安装和配置keepalived
配置文件所在位置
/etc/keepalived/keepalived.conf
配置文件中是按模块划分的
! Configuration File for keepalived
global_defs {
router_id mysql_ha
}
vrrp_script check_run {
script "/etc/keepalived/check_mysql.sh"
interval 2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 200
priority 99
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1200
}
track_script {
check_run
}
virtual_ipaddress {
192.168.3.99/24
}
}
vrrp_script模块中:
定义用于检查mysql是否运行正常的脚本,以及检查的时间间隔
vrrp_instance 模块中:
定义了keepalived服务所处的状态,这个状态只有BACKUP和MASTER两个值
interface :定义了绑定 虚拟ip的网络接口,一定要是服务器上可用的网络接口
virtual_router_id :定义了虚拟服务的id,要取0到255之间的数字
priority :定义了优先级,值越高,优先级越大,备份的备设备的值要比主设备低
nopreempt:此值代表不抢占资源,意思是原来的主宕机后,即使再恢复后也不会把虚拟IP抢回来,对于数据库来说,这样可以避免主从切换的二次伤害的可能
authentication :配置验证信息,这个在两个节点必须是一致的
virtual_ipaddress :定义了使用的虚拟ip信息
四. 演示使用
1. 修改主、主备服务器配置
[client]
port = 3306 # 客户端端口号为3306
socket = /home/mysql/data/mysql.sock
[mysqld]
# skip #
skip_name_resolve = 1
skip-external-locking =1
# GENERAL #
user = mysql # MySQL启动用户
default_storage_engine = InnoDB # 新数据表的默认数据表类型
character-set-server = utf8 # #服务端默认编码(数据库级别)
socket = /home/mysql/data/mysql.sock
pid_file = /home/mysql/data/mysqld.pid
basedir = /home/mysql #使用该目录作为根目录(Mysql安装目录);
port = 3306
bind-address = 0.0.0.0
log_error_verbosity = 3
explicit_defaults_for_timestamp = off
#sql_mode = NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
#sql_mode = NO_ENGINE_SUBSTITUTION
# undo log
# innodb_undo_directory = /home.mysql/undo
# innodb_undo_tablespaces = 32
# MyISAM #
key_buffer_size =32M
# SAFETY #
max_allowed_packet = 100M
max_connect_errors = 1000000
sysdate_is_now =1
#innodb = FORCE
#innodb_strict_mode = 1
# Replice #
server-id = 100
relay_log = /home/mysql/sql_log/mysqld-relay-bin
#plugin-load = semisync_master.so
log_slave_updates = on
master_info_repository = TABLE
relay_log_info_repository =TABLE
#######主主复制新增的配置###########
auto_increment_increment = 2 # 控制自增ID增长的步长,默认为1
auto_increment_offset = 1 # 控制自增ID从哪个值开始
#####################
# gtid_mode = on
# enforce_gtid_consistency =on
# skip-slave-start =1
#rpl_semi_sync_master_enabled = 1
#rpl_semi_sync_master_timeout=200 # 0.2 second
master_info_respository = TABLE
# gtid_mode= on
# enforce_gtid_consistency = on
# skip-slave-start = 1
# DATA STORAGE #
datadir = /home/mysql/data #mysql 数据文件存放的目录
tmpdir = /tmp # MySQL存放临时文件的目录
# BINARY LOGGING #
log_bin = /home/mysql/sql_log/mysql-bin
max_binlog_size = 1000M
binlog_format = row
expire_log_days = 7
sync_binlog = 1
# CACHES AND LIMITS #
tmp_table_size = 32M
max_heap_table_size = 32M
query_cache_type = 0
auto_increment_increment ,auto_increment_offset 这两个参数是动态参数,我们可以直接通过命令进行修改,不需要重启
查看并修改
命令如下
mysql> show variables like 'auto%';
mysql> set global auto_increment_increment=2;
mysql> set global auto_increment_offset =1;
从服务器配置进行类似修改即可
从服务器配置
[client]
port = 3306 # 客户端端口号为3306
socket = /home/mysql/data/mysql.sock
[mysqld]
# skip #
skip_name_resolve = 1
skip-external-locking =1
# GENERAL #
user = mysql # MySQL启动用户
default_storage_engine = InnoDB # 新数据表的默认数据表类型
character-set-server = utf8 # #服务端默认编码(数据库级别)
socket = /home/mysql/data/mysql.sock
pid_file = /home/mysql/data/mysqld.pid
basedir = /home/mysql #使用该目录作为根目录(Mysql安装目录);
port = 3306
bind-address = 0.0.0.0
log_error_verbosity = 3
explicit_defaults_for_timestamp = off
#sql_mode = NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
#sql_mode = NO_ENGINE_SUBSTITUTION
read_only = on
# undo log
# innodb_undo_directory = /home.mysql/undo
# innodb_undo_tablespaces = 32
# MyISAM #
key_buffer_size =32M
# SAFETY #
max_allowed_packet = 100M
max_connect_errors = 1000000
sysdate_is_now =1
#innodb = FORCE
#innodb_strict_mode = 1
# Replice #
server-id = 101
relay_log = /home/mysql/sql_log/mysqld-relay-bin
#plugin-load = semisync_master.so
log_slave_updates = on
master_info_repository = TABLE
relay_log_info_repository =TABLE
#######主主复制新增的配置###########
auto_increment_increment = 2 # 控制自增ID增长的步长,默认为1
auto_increment_offset = 2 # 控制自增ID从哪个值开始
#####################
# gtid_mode = on
# enforce_gtid_consistency =on
# skip-slave-start =1
#rpl_semi_sync_master_enabled = 1
#rpl_semi_sync_master_timeout=200 # 0.2 second
master_info_respository = TABLE
# gtid_mode= on
# enforce_gtid_consistency = on
# skip-slave-start = 1
# DATA STORAGE #
datadir = /home/mysql/data #mysql 数据文件存放的目录
tmpdir = /tmp # MySQL存放临时文件的目录
# BINARY LOGGING #
log_bin = /home/mysql/sql_log/mysql-bin
max_binlog_size = 1000M
binlog_format = row
expire_log_days = 7
sync_binlog = 1
# CACHES AND LIMITS #
tmp_table_size = 32M
max_heap_table_size = 32M
query_cache_type = 0
mysql> show variables like 'auto%';
mysql> set global auto_increment_increment=2;
mysql> set global auto_increment_offset =2;
从服务器查看二进制日志信息
命令
mysql> show master status \G
可以查看当前使用的日志文件
File:mysql-bin:000003
和日志点
Position:25423894
然后去主服务器上使用change master命令
由于从到主的复制链路之前已开启过,现在只需要配置主到从的
2. 配置启动主到从的复制链路
由于是主主复制 是把当前的主当作从,把当前的从当作主,在主上配置的master_host的值是从的ip,
命令如下:
mysql> change master to master_host='192.168.2.100',
-> master_user='dba_repl',
-> master_password='123456',
->MASTER_LOG_FILE='mysql-bin.000003',MASTER_LOG_POS=25423894;
mysql> start slave;
3. 在主DB、主备DB的服务器上分别安装keepalived
yum install keepalived -y
[root@localhost ~]# cd /etc/keepalived/
[root@localhost keepalived]# ls
check_mysql.sh keepalived.bak keepalived.conf
check_mysql.sh 一定要有执行权限
chmod a+x check_mysql.sh
4. 主从服务器分别启动keepalived
[root@localhost keepalived]# /etc/init.d/keepalived start
启动成功后,可以通过ip addr命令查看虚拟ip
可以通过手动关闭mysql模式宕机,查看主的ip addr中的虚拟Ip已不存在,此时已虚拟Ip在从服务器上
五. 目前架构存在的问题
目前架构:
一台主服务器,一台从服务器,加入了keepalived服务来监控主从服务器的运行健康状态,并通过keepalived服务器生成了一个虚拟IP,前端应用是通过虚拟IP来进行数据库的访问,并且为了使主库宕机后能尽快恢复,把原来的主从复制改为了主主复制
存在的问题:
但是目前的读写操作还只是全部通过虚拟IP使用同一台数据库服务器(主服务器或主备服务器)来进行访问的,所以这个架构也没有解决单台数据库服务器读写压力大的问题
对于数据库服务器来说,读负载和写负载是两个不同的问题
- 写操作只能在Master数据库上执行
- 读操作既可以在Master库上执行,也可以在Slave库上执行
相对于写负载,解决读负载要更容易,因为我们可以很容易的得到多个slave服务器,并且在正常的业务环境中数据库所执行的读操作次数要远远高于写操作的次数
同时那些有性能问题的慢查询,也都是读操作产生的
六. 如何解决读压力大的问题?
- 进行读写分离,主服务器主要执行写操作
- 读操作的压力平均分摊到不同的SLAVE服务器上
- 增加前端缓存服务器如Redis,memcache等
推荐使用redis缓存服务器,redis优点:可持久化,可主从复制,可集群
解决方式见:如何解决MySQL读压力大的问题
七. 如何解决写压力大的问题
MySQL复制无法缓解写压力
利用缓存,合并多次写为一次写
缓解写压力需要对MasterDB进行拆分
前面数据库操作规范中说过,程序所使用的数据库账号只能在同一个数据库下进行操作,不允许跨库查询数据库
对MasterDB进行拆分的步骤
MasterDB中有mc_userdb、mc_productdb、mc_orderdb三个数据库
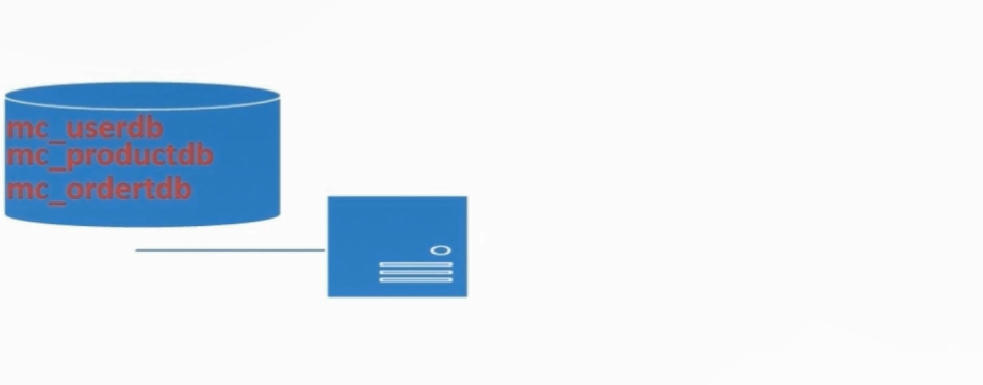
步骤1:按需求建立新的DB集群
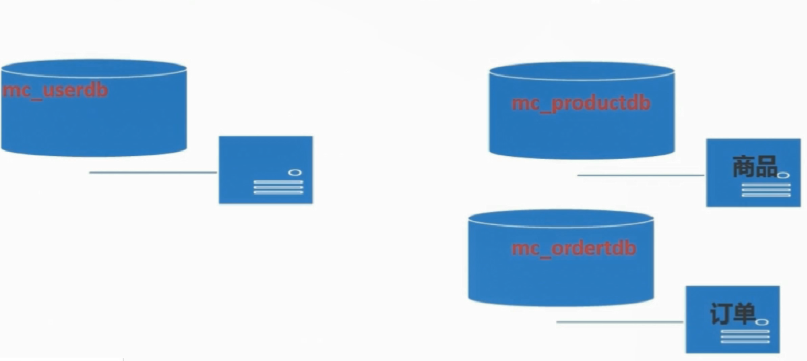
建立好新的数据库集群后,就可以在新老集群之间建立主从同步关系,把要拆分的DB同步到新的集群中
即 把mc_productdb同步到商品集群中 ,mc_orderdb同步到订单集群中
步骤2:同步要拆分的DB到新的集群中
当数据库同步成功后,找一个业务的低峰时间段,比如凌晨3、4点时,把老集群上数据库的账号,迁移到新的数据库集群中
步骤3:迁移数据库账号到对应的新集群
迁移成功后,修改老集群的应用在老集群数据库上的链接,把
对mc_productdb和mc_orderdb上的链接修改到新的集群上
步骤4:修改前台应用的数据库链接
步骤5:删除之前建立的老数据库集群到新数据库集群的数据库同步链接,将老集群上的mc_productdb和mc_orderdb备份后进行删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号