(5) 电商场景下的常见业务SQL处理
1. 如何对评论进行分页展示
一般情况下都是这样写
我们来看看它的执行计划

可以看到possible_keys、key、key_len的值均为NULL,说明这条SQL在product_comment 表上是没有可用的索引的,取出9593行过滤度为1%
1. 建立索引,优化评论分页查询
根据我们索引规范可以考虑在where条件上建立索引
where条件有两个字段,我们可以通过以下语句计算一下两列数据在表中的区分度
计算字段数据区分度,建立索引
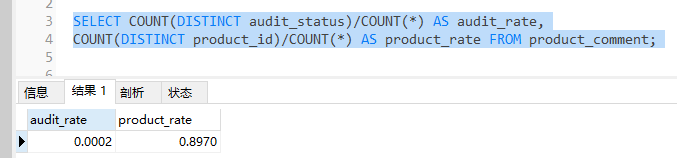
比值越接近1,代表区分度越好,我们应该把区分度好的列放到联合索引的左侧
我们现在建立索引后,再来看看执行计划

可以看到查询时运用到了联合索引,只查询出一条数据,就能返回我们需要的数据了,过滤程度是百分之百,我们完成了第一步优化
缺点
这种SQL语句查询的缺点是,越往后翻页,比如几千页之后,效率会越来越差,查询时间也会越来越长,尤其表数据量大的时候更是如此
适用场景
它的适用场景是表的结果集很小,比如一万行以下时,或查询条件非常复杂,比如涉及到多个不同的查询判断,或是表关联时使用
2. 进一步优化评论分页查询,SQL语句改写
改写后的SQL语句:
改写前的SQL和改写后的SQL查询出来的结果集是一样的,但是效率要高于改写前的SQL
使用前提
使用这个SQL有一个前提是,商品评论表的主键是customer_id ,且是有覆盖索引(也就是刚刚我们建立的联合索引)
优化原理
先根据过滤条件利用覆盖索引取出主键的comment_id,然后再进行排序,取出我们所需要的数据的行数,然后再和评论表通过主键进行排序来取出其他的字段,
这种方式的数据开销是索引 IO +索引分页后的结果(15行数据)的表的IO,
优点
比改写前的SQL在IO上要节省很多,这种改写方式的优点是在每次翻页的所消耗的资源和时间基本是相同的,不会越往后翻页,效率越差
应用场景:
当查询和排序字段(即where子句和order by子句所涉及的字段),有对应的覆盖索引的情况下使用
并且查询的结果集很大的情况下也是适用于这种情况的
二. 如何删除重复数据
要求
删除评论表中对同一订单同一商品的重复评论,只保留最早的一条
步骤一
查看是否存在对于同一订单同一商品的重复评论,如果存在,进行后续步骤
查询语句:
步骤二
备份product_comment表(避免误删除的情况)
备份语句:
如果提示:
错误代码:1786 Statement violates GTID consistency:CREATE TABLE ... SELECT.
则换用下面的语句
错误原因
这是因为在5.6及以上的版本内,开启了 enforce_gtid_consistency=true 功能导致的,MySQL官方解释说当启用 enforce_gtid_consistency 功能的时候,MySQL只允许能够保障事务安全,并且能够被日志记录的SQL语句被执行,像create table … select 和 create temporarytable语句,以及同时更新事务表和非事务表的SQL语句或事务都不允许执行。
解决办法
方法一
修改 :
配置文件中 :
方法二:
如果表数据量比较大,则使用mysql dump的方式导出成文件进行备份
步骤三
删除同一订单的重复评论
删除语句:
三. 如何进行分区间统计
要求
统计消费总金额大于1000元的,800到1000元的,500到800元的,以及500元以下的人数
SQL语句
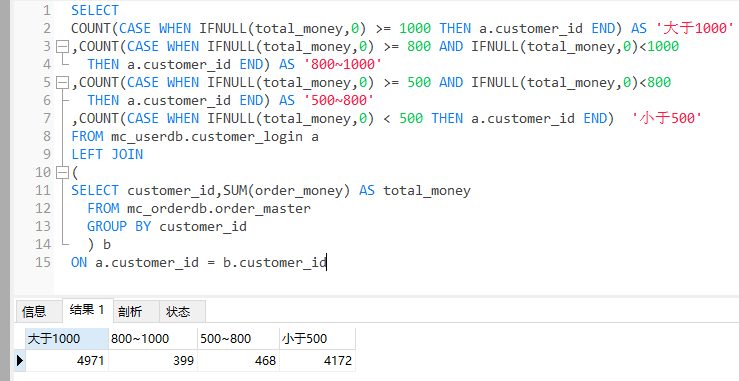
检验一下结果是否正确

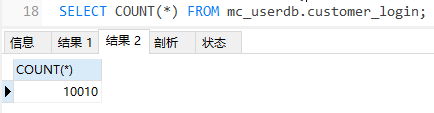
总和是10010,说明查询结果正确
__EOF__

本文链接:https://www.cnblogs.com/huchong/p/10237854.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用