(3) MySQL分区表使用方法
1. 确认MySQL服务器是否支持分区表
命令:

2. MySQL分区表的特点
- 在逻辑上为一个表,在物理上存储在多个文件中
HASH分区(HASH)
HASH分区的特点
- 根据MOD(分区键,分区数)的值把数据行存储到表的不同分区中
- 数据可以平均的分布在各个分区中
- HASH分区的键值必须是一个INT类型的值,或是通过函数可以转为INT类型
如何建立HASH分区表
以INT类型字段 customer_id为分区键
以非INT类型字段 login_time 为分区键(需要先转换成INT类型)
customer_login_log 表如果不分区,在物理磁盘上文件为
如果按上面的建HASH分区表,则有五个文件
演示

使用起来和不分区是一样的,看起来只有一个数据库,其实有多个分区文件,比如我们要插入一条数据,不需要指定分区,MySQL会自动帮我们处理

查询

范围分区(RANGE)
RANGE分区特点
- 根据分区键值的范围把数据行存储到表的不同分区中
- 多个分区的范围要连续,但是不能重叠
- 默认情况下使用VALUES LESS THAN属性,即每个分区不包括指定的那个值
如何建立RANGE分区

如果没有定义p3分区,当插入的customer_id大于29999时会报错,定义了则超过的数据都存入p3中
RANGE分区的适用场景
- 分区键为日期或是时间类型 (可以使得各个分区表的数据比较均衡,如果按上面的例子中以整型id为分区键,假如活跃用户集中在10000-19999之间,则p1中的数据量就会比其他分区的数据量大很多,这就失去了分区的意义;而且按时间类型分区,如果要按时间顺序进行数据的归档,则只需要对某一个分区进行归档就可以了)
- 所有查询中都包括分区键(避免跨分区查询)
- 定期按分区范围清理历史数据
LIST分区
LIST分区的特点
- 按分区键取值的列表进行分区
- 同范围分区一样,各分区的列表值不能重复
- 每一行数据必须能找到对应的分区列表,否则数据插入失败
如何建立LIST分区

如果插入一条login_type为10的数据行,则会报错
3. 如何为登录日志表(customer_login_log)分区
业务场景
- 用户每次登录都会记录customer_login_log日志
- 用户登录日志保存一年,1年后可以删除或者归档
登录日志表的分区类型及分区键
- 使用RANGE分区
- 以login_time为分区键
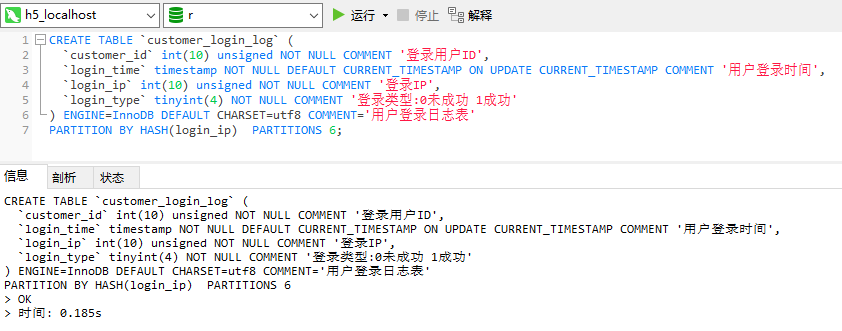
分区后的用户登录日志表
按年份分区存储,所以用YEAR函数进行了转化
插入并查询数据

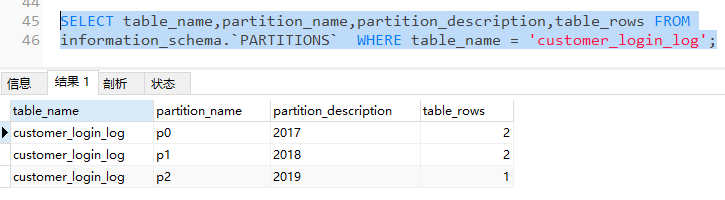
查询指定表中的分区数据情况
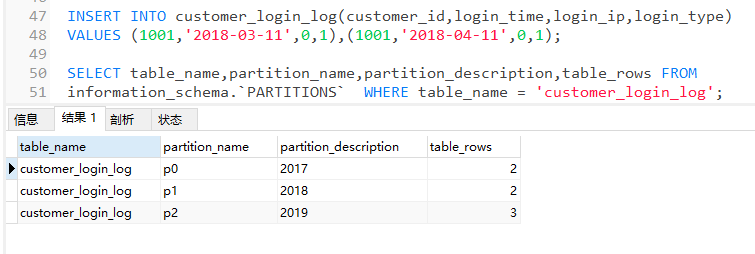
再插入2条18年的日志,会存入p2表中
之前说过建立分区表时,最好建立一个MAXVALUE的分区,这里之所以没有建立,是为了数据维护的方便,如果我们建立了MAXVALUE分区,很容易忽视一个问题,当我们2019年有的数据插入时,会自动存入那个MAXVALUE分区中,之后在做数据维护时会不方便,所以没有建立MAXVALUE分区
而是通过计划任务的方式,在每年年底的时候增加这个分区,比如我们现在在2018年年底,我们需要在日志表中为2019年建立日志分区,否则2019年的日志都会插入失败

我们可以通过下面语句
增加分区
增加分区,并插入数据

删除分区
假如我们现在要删除2016年到2017年间一年的数据,因为我们已经做了分区,所以只需要通过一条语句,删除p0分区即可
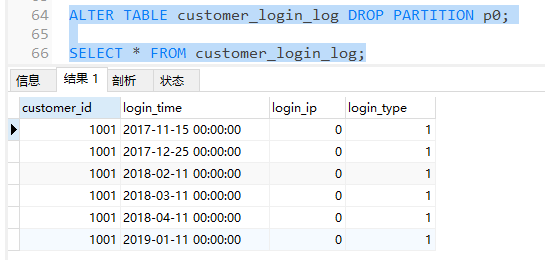
可以发现p0分区已被删除,且2016年的日志全部被清除了
归档分区历史数据
我们可能有另一种需求对数据进行归档
Mysql版本>=5.7,归档分区历史数据非常方便,提供了一个交换分区的方法
分区数据归档迁移条件:
- MySQL>=5.7
- 结构相同
- 归档到的数据表一定要是非分区表
- 非临时表;不能有外键约束
- 归档引擎要是:archive
建表并交换分区
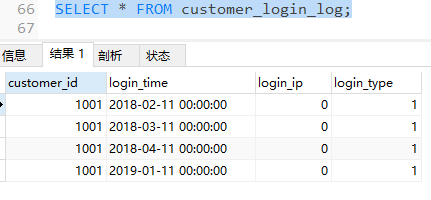
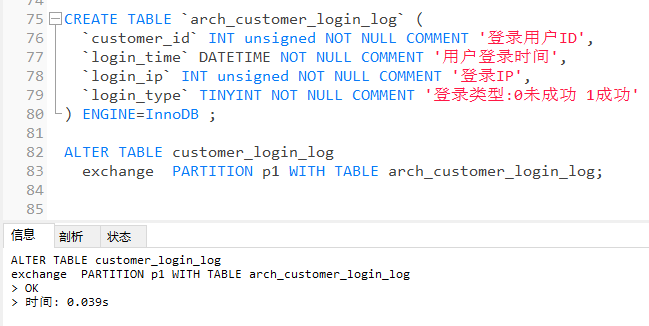
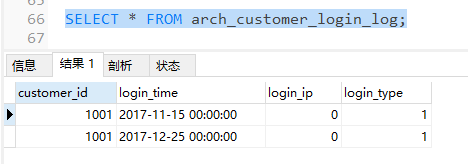
可以发现,原customer_login_log表中的2017年的数据(p1分区中的数据)已转移到了arch_customer_login_log表中,但是p1分区未删除,只是数据转移了,所以我们还需要执行DROP命令删除分区,以免有数据插入其中
将归档数据的存储引擎改为归档引擎
最后我们将归档数据的存储引擎改为归档引擎,命令为
使用归档引擎的好处是:它比Innodb所占用的空间更少,但是归档引擎只能进行查询操作,不能进行写操作
4. 使用分区表的主要事项
- 结合业务场景选择分区键,避免跨分区查询
- 对分区表进行查询最好在WHERE从句中包含分区键
- 具有主键或唯一索引的表,主键或唯一索引必须是分区键的一部分(这也是为什么我们上面分区时去掉了主键登录日志id(login_id)的原因,不然就无法按照上面的按年份进行分区,所以分区表其实更适合在MyISAM引擎中)
关于MyISAM和Innodb的索引区别
1.关于自动增长
myisam引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。
innodb引擎的自动增长咧必须是索引,如果是组合索引也必须是组合索引的第一列。
2.关于主键
myisam允许没有任何索引和主键的表存在,
myisam的索引都是保存行的地址。
innodb引擎如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见)
innodb的数据是主索引的一部分,附加索引保存的是主索引的值。
3.关于count()函数
myisam保存有表的总行数,如果select count(*) from table;会直接取出出该值
innodb没有保存表的总行数,如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了wehre 条件后,myisam和innodb处理的方式都一样。
4.全文索引
myisam支持 FULLTEXT类型的全文索引
innodb不支持FULLTEXT类型的全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。(sphinx 是一个开源软件,提供多种语言的API接口,可以优化mysql的各种查询)
5.delete from table
使用这条命令时,innodb不会从新建立表,而是一条一条的删除数据,在innodb上如果要清空保存有大量数据的表,最 好不要使用这个命令。(推荐使用truncate table,不过需要用户有drop此表的权限)
6.索引保存位置
myisam的索引以表名+.MYI文件分别保存。
innodb的索引和数据一起保存在表空间里。
__EOF__

本文链接:https://www.cnblogs.com/huchong/p/10231719.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
2018-01-07 数据库连接池,本地线程,上下文管理
2018-01-07 Flask快速入门,知识整理
2018-01-07 Flask-配置与调试