博客园项目知识点归纳
一、models.py模型及视图函数相关知识
当我们想用到Django自带的自带的用户验证系统,但是django自带的user表又无法完全满足我们的需求时,我们可以考虑扩展django自带的user表
1.扩展django自带用户模型的方法
1、和用户模型一对一链接
标准的Django模型都会有自己的数据库表,并通过OneToOneField与现有用户模型形成一对一的关联。
2、基于扩展AbstractBaseUser来创建的自定义用户模型
在models.py中,我们需要导入AbstractUser模块,并自定义我们自己的表模型,让我们的自定义的表继承AbstractUser
在settings中,我们需要进行设置,AUTH_USER_MODEL = "app01.UserInfo"
[app01/models.py]
from django.contrib.auth.models import AbstractUser class UserInfo(AbstractUser): '''用户信息''' nid = models.BigAutoField(primary_key=True) nickname = models.CharField(verbose_name='昵称', max_length=32) email = models.EmailField(verbose_name='邮箱') tel = models.CharField(verbose_name='手机号码', max_length=11, unique=True, null=True, blank=True) #blank指admin里可以不输入值,null指数据库里可以为空 avatar = models.FileField(verbose_name='头像', upload_to='avatar/', default="avatar/default.png") create_time = models.DateTimeField(verbose_name='创建时间', auto_now_add=True) # mutual_fans = models.ManyToManyField(verbose_name='互粉', to='Article', blank=True) def __str__(self): #不定义此方法则,默认打印对象 return self.username class Meta: #在admin里显示的表名 verbose_name_plural = '用户详情表'
会生成一个UserInfo表,其中包含Django自带user表里所有的字段以及我们自己写的字段(由于我们指定了主键nid,所以不会生成id字段)
这样我们就可以使用django自带的用户认证系统
我们保存到数据库中的密码是要经过加密的,且加密模式要与django一样,这样注册的用户才能通过auth.authenticate认证,所有创建新用户时
#方法一:通过create_user方法创建用户,(推荐此方法)
from django.contrib import auth
user_obj=models.UserInfo.objects.create_user(username=username,password=password,email=email,avatar=avatar_img,nickname=username) #方法二:采用相同的加密方式,将密码转换后,也可直接用普通的创建方式 from django.contrib.auth.hashers import make_password password = make_password(request.POST.get('password')) user_obj=models.UserInfo.objects.create(username=username,password=password,email=email,avatar=avatar_img,nickname=username)
一般查询多于多于修改创建,所以为了避免跨表查询,比如评论数等可以写在article表内,用来存储数据,方便查询
DateTimeField字段设置
自动获取时间并可更改 点击查看
media静态文件配置


Django settings.py 的media路径设置 2013年08月28日 ⁄ 综合 ⁄ 共 1092字 ⁄ 字号 小 中 大 ⁄ 评论关闭 在一个 models 中使用 FileField 或 ImageField 需要以下步骤: 1. 在你的 settings 文件中, 定义一个完整路径给MEDIA_ROOT 以便让 Django在此处保存上传文件. (出于性能考虑,这些文件并不保存到数据库.) 定义MEDIA_URL 作为该目录的公共 URL. 要确保该目录对 WEB 服务器用户帐号是可写的. 2. 在你的 models.py 中添加 FileField 或 ImageField, 并确保定义了upload_to 选项,以告诉 Django 使用MEDIA_ROOT 的哪个子目录保存上传文件. 3. 你的数据库中要保存的只是文件的路径(相对于 MEDIA_ROOT). 要想得到这个文件的路径可以用.url方法。例如,如果models里有一个取名为"photo"的ImageField,可以在Html模板里通过{{object.photo.url}}得到该图片的路径。 settings.py 设置 媒体文件的绝对路径: # Absolute path to the directory that holds media. # Example: "/home/media/media.lawrence.com/" MEDIA_ROOT = 'D:/Python26/Lib/site-packages/django/bin/newproj/media' 媒体文件的相对路径: # URL that handles the media served from MEDIA_ROOT. # Example: "http://media.lawrence.com" MEDIA_URL = '/site_media/' 设置静态文件路径 STATIC_PATH = 'D:/Python26/Lib/site-packages/django/bin/newproj/media' urls.py 影射路径 (r'^site_media/(?P<path>.*)$', 'django.views.static.serve',{'document_root': settings.STATIC_PATH}), 将 MEDIA_URL 的site_media 影射到 settings.STATIC_PATH models.py 上传图片字段设置 photo = models.ImageField('上传图片',upload_to='photos') 相当于传到 D:/Python26/Lib/site-packages/django/bin/newproj/media/photos 目录下,浏览时通过/site_media/photos/ 访问。
models.FileField和model.ImageField:
upload_to字段,会指定文件上传的文件夹(如果没有此文件夹会在指定的路径自动生成),上传文件时,数据库保存的是图片的地址即avatar/文件名
upload_to设置方法:http://www.cnblogs.com/huchong/p/7894860.html
django对上传文件有一个静态配置,一般上传文件都是放在media文件夹下,直接放在根目录下不太好,一般我们将文件放在我们的app下,所以我们可以建立如下结构
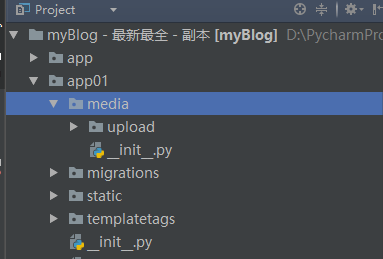
settins.py中
MEDIA_URL='/media/' MEDIA_ROOT=os.path.join(BASE_DIR,'app01','media','upload')
和static文件配置很像,只这样设置还是不行的,因为django有static的处理器,没有media的处理器,我们需要在urls.py中给它加上
from django.views.static import serve from django.conf import settings urlpatterns = [ url(r'^media/(?P<path>.*)$', serve, {"document_root": settings.MEDIA_ROOT}), ]
加上上面的配置才能生效
avatar = models.FileField(verbose_name='头像', upload_to='avatar', default="/avatar/default.png")
会把接收的文件放在media指代的路径与upload_to的拼接:
BASE_DIR+blog+media+uploads+avatar/a.png
avatar字段保存的是:avatar/a.png
使用时,如在注册页面显示我们指定的默认头像
<img src="/media/avatar/default.png" id="avatar_img"> #还可以通过width和height指定图片尺寸
(因为我们已经指定到了upload文件夹,要找到default,还需要往下写一层)
注册页面 头像代替input框
注册页面要想实现头像为默认图片,点击则上传文件的效果
可通过设置input标签的大小和图片的大小一致,并设置绝对定位,让input标签的透明度为0即可
<div class="col-md-10" id="avatar"> <img src="/media/avatar/default.png" alt="" id="avatar_img"> <input type="file" name="avatar" id="id_avatar"> </div> css样式 #id_avatar { position: absolute; top: 0; left: 15px; width: 50px; height: 50px; opacity: 0; } #avatar_img { position: absolute; top: 0; left: 15px; width: 50px; height: 50px; }
头像预览功能
$('#id_avatar').change(function () { //onchange(jquery里不需要on) 改变input输入框内容时执行 var ele_file = $(this)[0].files[0]; //or this.files files是js对象的方法 先找到input里的文件对象 var reader = new FileReader(); //实例化一个对象 reader.readAsDataURL(ele_file); //读出当前input文件的url reader.onload = function () { // onload 属性在对象已加载时触发 $("#avatar_img")[0].src = this.result // 此时this指代reader,reader.result就是文件的地址 } });
点击注册时,要传输文件,此时用ajax提交上传文件
ajax提交上传文件
$(".btn").click(function () { var formData = new FormData(); formData.append('email', $("[name='email']").val()); formData.append('tel', $("[name='tel']").val()); formData.append('username', $("[name='username']").val()); formData.append('nickname', $("[name='nickname']").val()); formData.append('password', $("[name='password']").val()); formData.append('repeat_password', $("[name='repeat_password']").val()); formData.append('avatar', $('#id_avatar')[0].files[0]); formData.append('csrfmiddlewaretoken', $("[name='csrfmiddlewaretoken']").val()); $.ajax({ url: '/reg/', type: 'POST', //headers: {"X-CSRFToken": $.cookie('csrftoken')}, data: formData, contentType: false, processData: false, //一定要加上上面两个设置,不然会报错 success: function (data) { data = JSON.parse(data); if (data.user) { location.href = '/login/' } else { $('span').each(function () { $(this).text(''); $(this).parent().removeClass('has-error') }); console.log(data.errorsList); $.each(data.errorsList, function (i, j) { console.log(i, j); $span = $("<span>"); $span.addClass("pull-right").css("color", "#a94442"); $span.html(j[0]); $("#id_" + i).after($span).parent().addClass("has-error"); if (i == "__all__") { $("#id_repeat_password").after($span).parent().addClass("has-error"); } ; }); } } }) });
form验证时,全局钩子和局部钩子
def clean_email(self): email = self.cleaned_data['email'] is_exsit = models.UserInfo.objects.filter(email=email) if is_exsit: raise ValidationError('邮箱已经存在!') else: return email def clean_username(self): user = self.cleaned_data['username'] is_exsit = models.UserInfo.objects.filter(username=user) if is_exsit: raise ValidationError('登陆用户名已被使用!') else: return user def clean_nickname(self): nickname = self.cleaned_data['nickname'] is_exsit = models.UserInfo.objects.filter(nickname=nickname) if is_exsit: raise ValidationError('显示名称已被使用!') else: return nickname
def clean(self): password = self.cleaned_data.get('password') repeat_password = self.cleaned_data.get('repeat_password') if password != repeat_password: raise ValidationError('确认密码错误') else: return self.cleaned_data
全局钩子是在局部钩子全部验证完后才执行,所以可以验证多组数据,局部钩子只能验证自己的字段
设置联合唯一的方法
class ArticleUp(models.Model): """ 点赞表 """ nid = models.AutoField(primary_key=True) user = models.ForeignKey(verbose_name='点赞人', to='UserInfo', null=True) article = models.ForeignKey(verbose_name='点赞的文章', to='Article', null=True) class Meta: verbose_name_plural = '文章点赞表' unique_together = [ ('user', 'article'), ]
中介模型:自定制多对多关系的关系表,方便扩展
当我们给两张表帮顶对多点关系时,会自动形成第三张关系表,但有时候形成的第三张关系表不能满足我们的需求,比如,我们想要让文章和标签联合唯一,这时自动生成的表结构就不能满足我们的需求,我们可以通过自定制关系表,来达到这个效果
class Article(models.Model): '''文章表''' nid = models.BigAutoField(primary_key=True) title = models.CharField(max_length=50, verbose_name='文章标题') desc = models.CharField(max_length=255, verbose_name='文章描述') create_time = models.DateTimeField(verbose_name='创建时间',default = timezone.now) update_time = models.DateTimeField(verbose_name='最后修改时间', auto_now=True) read_count = models.IntegerField(verbose_name='阅读数', default=0) comment_count = models.IntegerField(verbose_name='评论数', default=0) up_count = models.IntegerField(verbose_name='点赞数', default=0) down_count = models.IntegerField(verbose_name='被踩数', default=0) '''查询多于编辑,避免跨表查询''' category = models.ForeignKey(verbose_name='文章类型', to='Category', to_field='nid', blank=True, null=True) user = models.ForeignKey(verbose_name='所属用户', to='UserInfo', to_field='nid') tags = models.ManyToManyField( to="Tag", through='Article2Tag', # 通过自己建的表Article2Tag来生成这个多对多的关系表,方便扩展 through_fields=('article', 'tag'), ) siteCategory=models.ForeignKey(to='SiteCategory',verbose_name='所属博客系统分类',related_name='article',null=True,blank=True) def __str__(self): return self.title class Meta: verbose_name_plural = '文章表' class Article2Tag(models.Model): nid = models.AutoField(primary_key=True) article = models.ForeignKey(verbose_name='文章', to="Article", to_field='nid') tag = models.ForeignKey(verbose_name='标签', to="Tag", to_field='nid') class Meta: verbose_name_plural = '文章标签表' unique_together = [ ('article', 'tag'), ]
当我们使用了中介模型后,绑定多对多关系就不能再使用add了,需要在我们自定义的表里面,自己添加数据
django数据库和页面时间显示问题
登陆页面生成验证码及验证
分组查询
聚合: sql: select SUM("price") from book models.Book.objects.all().aggregate(SUM("price")) 分组: class Book: title price pubdate publish=models.ForergnKey("Publish") authorssss=models.ManyTomany("Author") 求一个每一本书的作者个数 Book.objects.all() ----------- select * from Book Book.objects.all().annotate(c=Count("authorssss__name")).valus("c")--------- [book_obj1,book_obj2,.....] 统计每一个出版社的最便宜的书 Publish.objects.all().annotate(c=MIN("book__price")).valus("title","c") # [{"title":"A",c:"123"},{"title":"B","c":"12"},{"title":"C",c:"34"}] # 方式2: Book.objects.all().values("publish__id") -------- [{publish__id:1},{publish__id:2},{publish__id:2},{publish__id:3},{publish__id:1}] Book.objects.all().values("publish__id").annotate(c=MIN("price")).values("c","publish__name")
Django事件回滚
当我们进行数据库操作时,如果两个操作有关联,其中一个操作执行完,准备执行另一个操作的中途出了问题时,就不应该让第一个操作执行成功,应该回滚到第一项操作执行前的状态,此时我们就应该采用事件回滚
from django.db import transaction with transaction.atomic(): comment_obj=models.Comment.objects.create(user_id=user_id,article_id=article_id,content=content) models.Article.objects.filter(nid=article_id).update(comment_count=F('comment_count')+1)
from django.db import transaction from django.db.models import F def comment(request): content = request.POST.get('comment').strip() article_id = request.POST.get('article_id') commentResponse = {"state": True,'comment_list':None,'parent_comment_id':None} if not request.user.is_authenticated() or len(content)==0: commentResponse["state"] = False return commentResponse else: user_id = request.user.nid pid = request.POST.get('parent_comment_id') # print('pid', pid) if pid: #处理子评论 with transaction.atomic(): #事件回滚 comment_obj = models.Comment.objects.create(user_id=user_id, article_id=article_id, content=content,parent_comment_id=pid) models.Article.objects.filter(nid=article_id).update(comment_count=F('comment_count') + 1) commentResponse["parent_comment_content"] = comment_obj.parent_comment.content commentResponse["parent_comment_username"] = comment_obj.parent_comment.user.username # date,time,_=str(comment_obj.create_time).split(':') # commentResponse['comment_time'] = comment_obj.create_time.strftime('%Y-%m-%d %H:%M') # 格式化时间 commentResponse['parent_comment_id']=pid # commentResponse['comment_id']=comment_obj.nid else: #处理的文章评论,即根评论 with transaction.atomic(): #事件回滚 comment_obj=models.Comment.objects.create(user_id=user_id,article_id=article_id,content=content) models.Article.objects.filter(nid=article_id).update(comment_count=F('comment_count')+1) # date,time,_=str(comment_obj.create_time).split(':') commentResponse['comment_time']=comment_obj.create_time.strftime('%Y-%m-%d %H:%M') #格式化时间 commentResponse['comment_id'] = comment_obj.nid # commentResponse['plies']=comment_obj # 格式化SQLite时间的方法,如果是MySql则是用DATE_FORMAT return HttpResponse(json.dumps(commentResponse))
二 前端页面知识
根据登陆状态,决定显示内容
{% if request.user.is_authenticated %} <li><a href=""><span class="glyphicon glyphicon-user"></span>{{ request.user.username }}</a></li> <li><a href="/logout/">注销</a></li> {% else %} <li><a href="/login/">登录</a></li> <li><a href="/reg/">注册</a></li> {% endif %}
{{request.user.username}} 可以直接在页面获取,不需要视图函数返回值渲染,如果登陆了则显示登录用户的username,否则是显示匿名用户
从数据库中读取头像显示
<img src="{{ article.user.avatar.url }}" alt="" width="60" height="60"> .url直接拿到此时文件的地址
如果是后端通过models.Comment.objects.filter(article_id=article_id).object.values('user_avatar)传到前端,
前端拿到这个时间 var create_time=comment_dict['create_time'].slice(0,16)后
此时不能用.url,因为此时是值不是对象,引用时应为<img src="/media/" ‘+create_time+’ alt="" width="60" height="60">
url反向解析
urlpatterns = [ url(r'^(?P<username>.*)', views.homeSite,name="aaa"), ]
<a href="{% url 'aaa' article.user.username %}"><img src="{{ article.user.avatar.url }}" alt="" width="60" height="60"></a>
前端时间格式过滤
{{ article.create_time|date:"Y-m-d H:i" }} 页面上时间显示的格式为: 年-月-日 时:分
后端处理时间格式
#此时数据库用的是sqlite
comment_obj.create_time.strftime('%Y-%m-%d %H:%M') #格式化时间 # 格式化SQLite时间的方法,如果是MySql则是用DATE_FORMAT
园龄计算需要用到自定义标签以及datetime模块
from django import template from django.utils.safestring import mark_safe import time import datetime register = template.Library() # register的名字是固定的,不可改变 @register.filter def filter_time(t): t1=datetime.datetime(year=t.year,month=t.month,day=t.day) #将creat_time实例化成datetime对象 t2=datetime.datetime.now() return t2-t1 @register.filter def my_slice(s): time=str(s) a,b=time.split(',') a=int(a.split()[0]) time=divmod(a,360) year = 0 if time[0] > 0: year=str(time[0])+'年' time_month = divmod(time[1], 30) month = 0 if time_month[0] > 0: month = str(time_month[0])+'个月' day = str(time_month[1])+'天' filter_time='' if year: filter_time+=year if month: filter_time+=month filter_time+=day return filter_time
前端数字类型格式转化
parseInt() 或者 Numeber()
跳转到页面内某一位置的方法
回复评论按钮中的知识点
可以用a标签的锚点,
<a href="#comment"> 点击则跳转到id为comment的位置</a>
如果是跳转到一个input框里,则可以通过
$("#comment").focus(); //跳转到comment里光标此时的位置
母版继承外的又一种方式
当页面上有些内容是好多个页面都会用到的时候,除了可以建立母版,并继承外,还可以通过让这个几个页面都走同一个视图函数,在视图函数里改变需要改变的渲染的结果,在前端页面上即可实现类似的效果,如:在个人首页或者系统首页,有好多分类,点击不同分类,会有不同的结果,但是左侧分栏栏不变,则可使用此方法
from django.conf.urls import url from app01 import views urlpatterns = [ url(r'^poll/$',views.poll), url(r'^comment/$',views.comment), url(r'^(?P<username>.*)/(?P<condition>tag|category|date)/(?P<para>.*)',views.homeSite), #个人首页分类地址 url(r'^(?P<username>.*)/p/(?P<para>.*)',views.articleDetail), #文章具体内容地址 url(r'^(?P<username>.*)', views.homeSite,name="aaa"), #个人首页地址 ]
def homeSite(request,username,**kwargs): # 查询当前用户 current_user=models.UserInfo.objects.filter(username=username).first() current_blog=current_user.blog if not current_user: return render(request,'notFound.html') # 查询当前用户所有文章 article_list=models.Article.objects.filter(user=current_user) # 查询 当前用户的分类归档 from django.db.models import Count,Sum category_list=models.Category.objects.all().filter(blog=current_blog).annotate(c=Count("article__nid")).values_list("title","c") print(category_list) #<QuerySet [<Category: yuan的go>, <Category: yuan的java>]> # 查询当前用户的标签归档 tag_list=models.Tag.objects.all().filter(blog=current_blog).annotate(c=Count("article__nid")).values_list("title","c") print(tag_list) # <QuerySet [('基础知识', 3), ('插件框架', 0), ('web开发', 1)]> # 查询当前用户的日期归档 date_list=models.Article.objects.filter(user=current_user).extra(select={"filter_create_date":"strftime('%%Y/%%m',create_time)"}).values_list("filter_create_date").annotate(Count("nid")) print(date_list) #extra,select里是字典,键可以随便取名,到时候表中会多出这个键的字段,值里是写sql语句,拿到我们经过约束后的结果(此时只是为了格式化时间,之所以要 #两个百分号是与extra的机制有关) ###############################################通过条件,取不同值,在页面上筛选不同的内容跳转 print(kwargs) if kwargs: if kwargs.get("condition")== "category": article_list= models.Article.objects.filter(user=current_user,category__title=kwargs.get("para")) elif kwargs.get("condition")== "tag": article_list= models.Article.objects.filter(user=current_user,tags__title=kwargs.get("para")) elif kwargs.get("condition") == "date": year,month=kwargs.get("para").split("/") article_list= models.Article.objects.filter(user=current_user,create_time__year=year,create_time__month=month) return render(request,"homeSite.html",locals())
views里用到了分组查询
字体上下居中
将 line-height 和height设置一致
或者设置padding
页面跳转回之前的页面
要求:
1 用户登陆后才能访问某些页面,
2 如果用户没有登录就访问该页面的话直接跳到登录页面
3 用户在跳转的登陆界面中完成登陆后,自动访问跳转到之前访问的地址
方法1:根据location.pathname
二、JS中Location属性 属性 描述 hash 设置或返回从井号 (#) 开始的 URL(锚)。如果地址里没有“#”,则返回空字符串。 host 设置或返回主机名和当前 URL 的端口号。 hostname 设置或返回当前 URL 的主机名。 href 设置或返回完整的 URL。在浏览器的地址栏上怎么显示它就怎么返回。 pathname 设置或返回当前 URL 的路径部分。 port 设置或返回当前 URL 的端口号,设置或返回当前 URL 的端口号。 protocol 设置或返回当前 URL 的协议,取值为 'http:','https:','file:' 等等。 search 设置或返回从问号 (?) 开始的 URL(查询部分)。 三、JS中Location对象方法 属性 描述 assign() 加载新的文档。 reload() 重新加载当前文档,相当于按浏览器上的“刷新”(IE)或“Reload”(Netscape)键。 replace() 用新的文档替换当前文档,相当于按浏览器上的“刷新”(IE)或“Reload”键。
|
1
2
3
|
def my_view(request): if not request.user.is_authenticated(): return redirect('%s?next=%s' % (settings.LOGIN_URL, request.path)) |
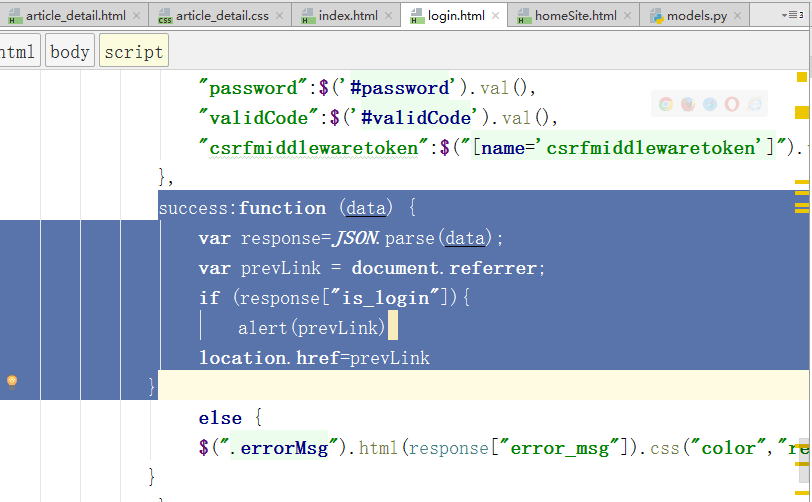
方法2:document.referrer
方法3:根据cookie设置next_path(推荐)
可以避免BUG,比如,在文章详情页面,跳转到登陆页面后,虽然此时地址栏有了参数,但是如果发现此时没有账号,需要注册,去了注册页面后,登陆时,地址栏参数已经没有了
但是设置cookie则可以避免,不设置session的原因是减小服务器的压力,这种操作交给客户端做就行了
要跳回哪个页面,就在进那个页面时,执行的视图函数里设置cookie
2、跳转 (从哪来跳那去 window.location.href) --------- key:获取上一次url的路径 1 根据location.pathname: article_detail.html: if 未登录:location.href="/login/?next="+location.pathname // /login/?next=/blog/yuan/articles/1 login.html: if (response["is_login"]){ if(location.search.slice(6)){ // /blog/yuan/articles/1 location.href=location.search.slice(6) } else { location.href="/" } } 2 根据document.referrer: article_detail.html: if 未登录:location.href="/login/" login.html: if (response["is_login"]){ if(document.referrer){ // /blog/yuan/articles/1 location.href=document.referrer } else { location.href="/" } } 3 根据cookie设置next_path views.py : def :articleDetail obj=render(request,"article_detail.html",locals()) obj.set_cookie("next_path",request.path) return obj article_detail.html: if 未登录:location.href="/login/" login.html: if (response["is_login"]){ $.cookie("next_path") if($.cookie("next_path")){ // /blog/yuan/articles/1 location.href=$.cookie("next_path") } else { location.href="/" } }
return HttpResponse(json.dumps()) 和 return JsonResponse(data)的用法区别
def commentTree(request,article_id): # 筛选当前文章的评论 all = models.Comment.objects.filter(article_id=article_id).values('nid', 'content', 'parent_comment_id','user__avatar','user__username','create_time') # print(all) d = {} for i in all: d[i['nid']] = i # print(d) commentTree = [] for k, v in d.items(): v["chidren_commentList"] = [] pid = v['parent_comment_id'] if not pid: commentTree.append(v) else: # print(pid) d[pid]['chidren_commentList'].append(v) # d[pid]['chidren_commentList'].append(v) # print(commentTree) # import json return HttpResponse(json.dumps(commentTree)) # from django.http import JsonResponse # return JsonResponse(commentTree,safe=False) #若对于字典报错则需要加saft=False,用这个,前端不需要parse
我们从数据库取出时间时,用json.dumps()转化出错
提示为:
TypeError: Object of type 'datetime' is not JSON serializable
我们可以使用return JsonResponse(...) ,而且这样在前端ajax中,可以省去Json.parse(data)转化
注意:不要写成 return HttpResponse(JsonResponse(...)) ,这样会让一些数据转化有问题
当我们使用return JsonResponse(...)时,若报错为:
'In order to allow non-dict objects to be serialized set the ' TypeError: In order to allow non-dict objects to be serialized set the safe parameter to False.
我们只需要设置为
return JsonResponse(commentTree,safe=False)
可变数据类型结构变化
# 可变数据类型 [] {} 引用数据时,引用对象的内容变化时,自己也发生变化,不论先后 # 不可变数据类型 数字 字符串 元组 # s="hello".upper() # print(s) # l=[1,2,3] # # c=[4,5] # # l.append(c) # c.append(7) # # print(c) # # print(l) # d1={"name":"yuan"} # d2={"age":12} # d1["xxx"]=d2 # # d2["height"]="180cm" # # print(d1) # {"name":"yuan","xxx":{"age":12,"height":"180cm"}} # d1={1:{"xxx":[12,34]},2:{"xxx":[34,56,[777,888,999],[11,8238,99]]}} # d2={"xxx":[777,888,999,[11,8238,99]]} # d3={"xxx":[11,8238,99]} # # d1[2]["xxx"].append(d2["xxx"]) # d2["xxx"].append(d3["xxx"]) # # print(d1) # {1:{"xxx":[12,34]},2:{"xxx":[34,56,[777,888,999,[11,8238,99]]]}} # print(d2) # {"xxx":[777,888,999,[11,8238,99]]} # print(d3) # d3={"xxx":[11,8238,99]}
textarea插件---Kindeditor
django内文件上传的其他方法,点击查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号