


12.MapReduce框架原理
一、MapReduce工作流程
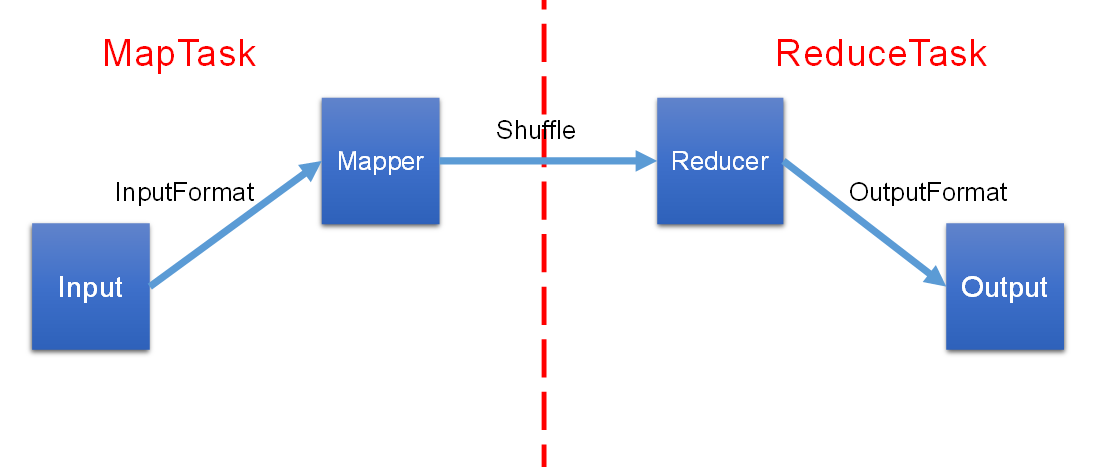 MapTask和Shuffle阶段:
MapTask和Shuffle阶段:
 ReduceTask阶段:
ReduceTask阶段:
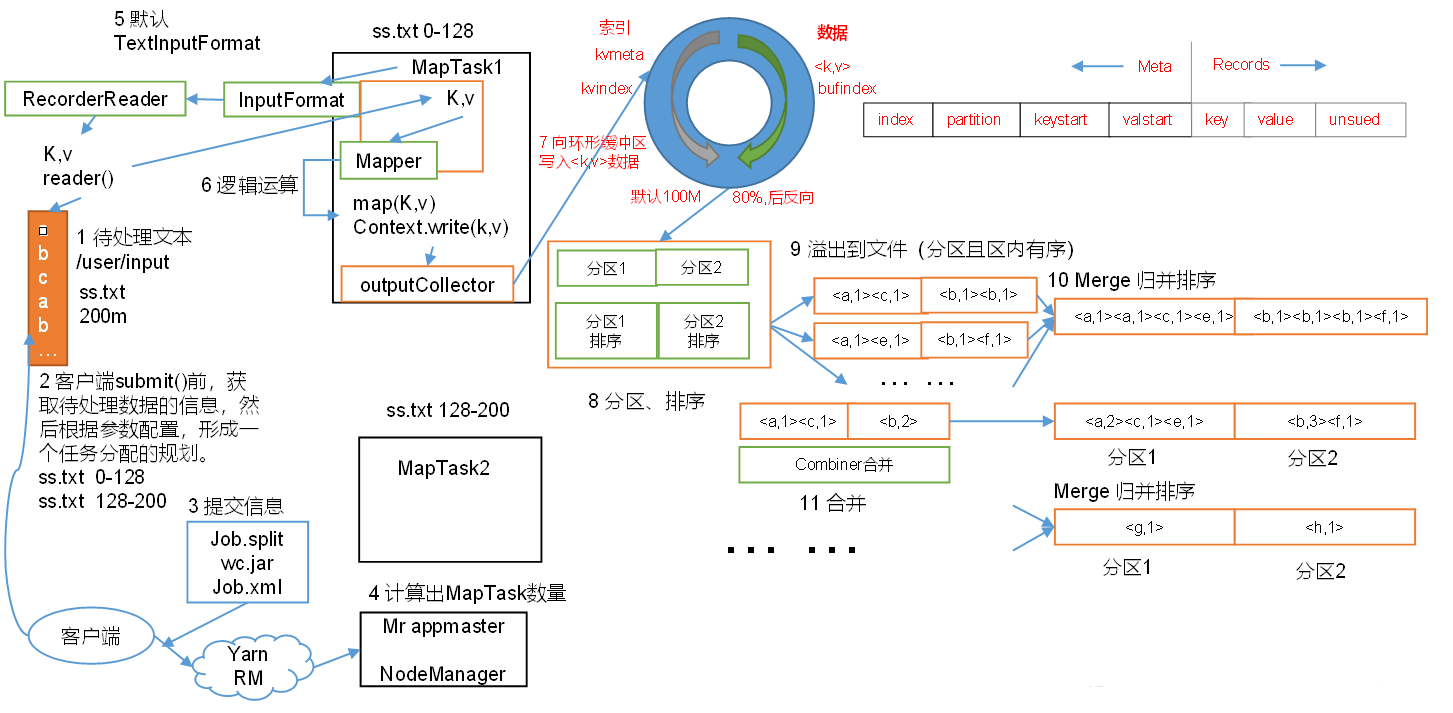
1.1 MapTask工作机制
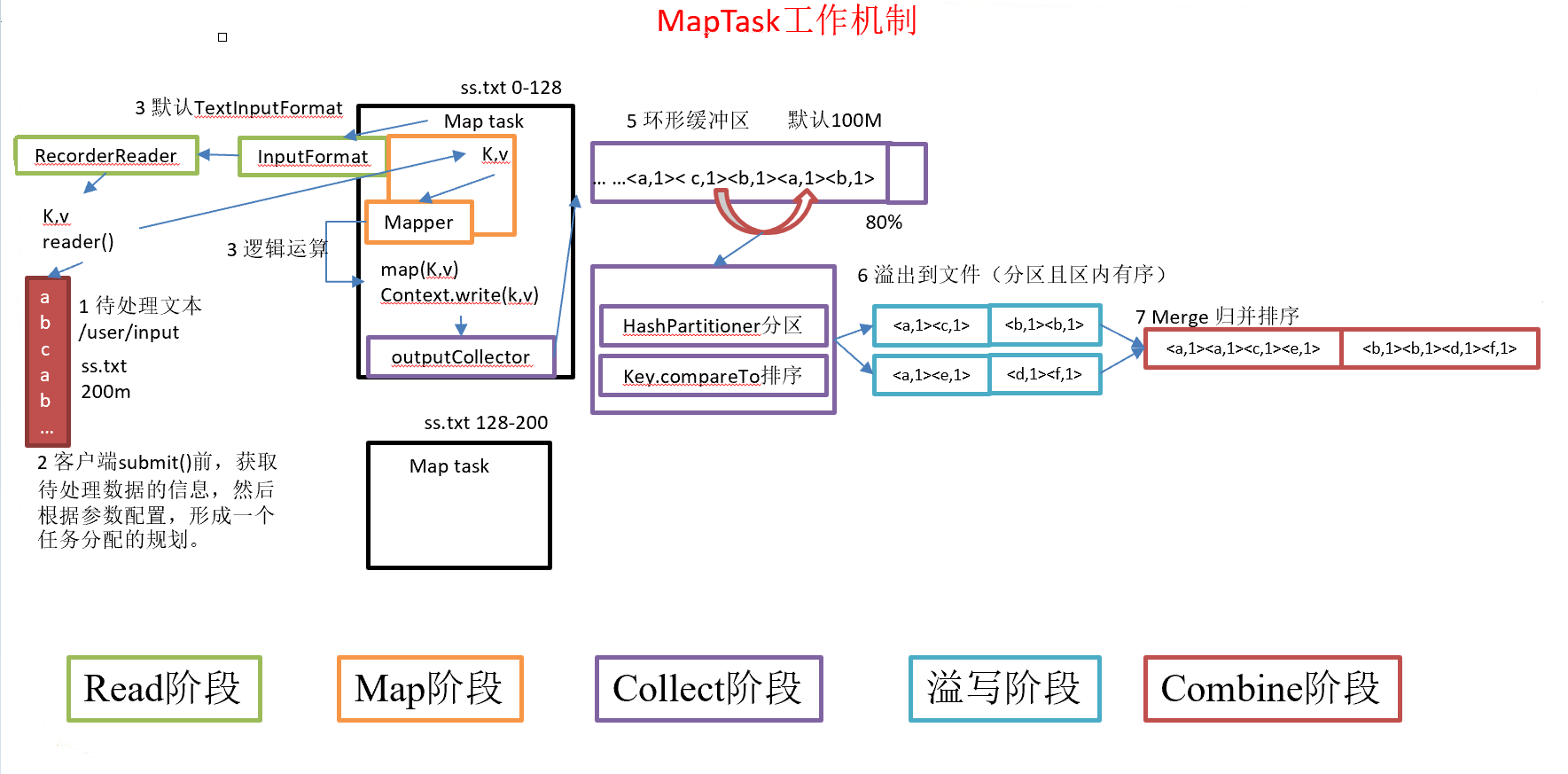
- Read阶段:
MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个KV。 - Map阶段:该节点主要是将解析出的
KV交给用户编写map()函数处理,并产生一系列新的KV - Collect收集阶段:在用户编写
map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的KV分区(调用Partitioner),并写入一个环形内存缓冲区中 - Spill阶段:即“溢写”,当环形缓冲区满后,
MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。 - Combine阶段:当所有数据处理完成后,
MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。 - Reduce阶段:
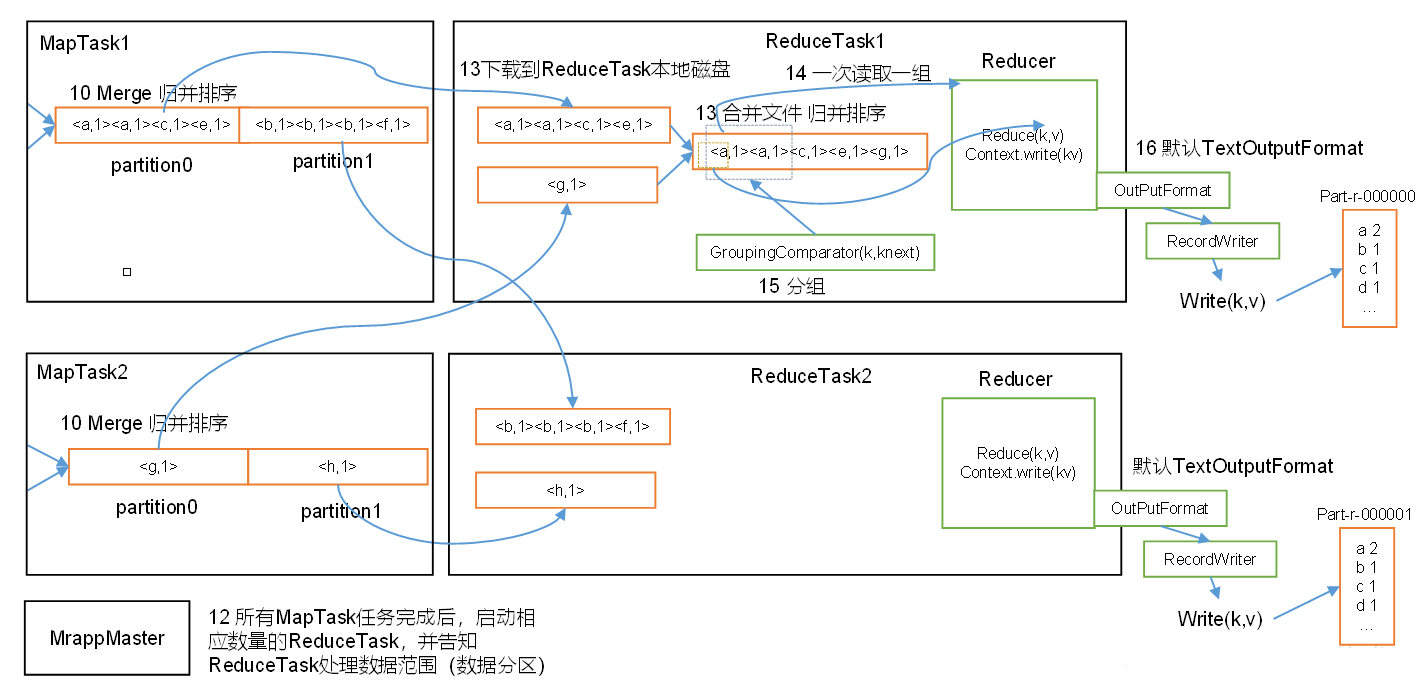
ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据,ReduceTask会将这些文件再进行合并(归并排序),然后进行reduce()的逻辑运算。
1.2 Shuffle工作机制
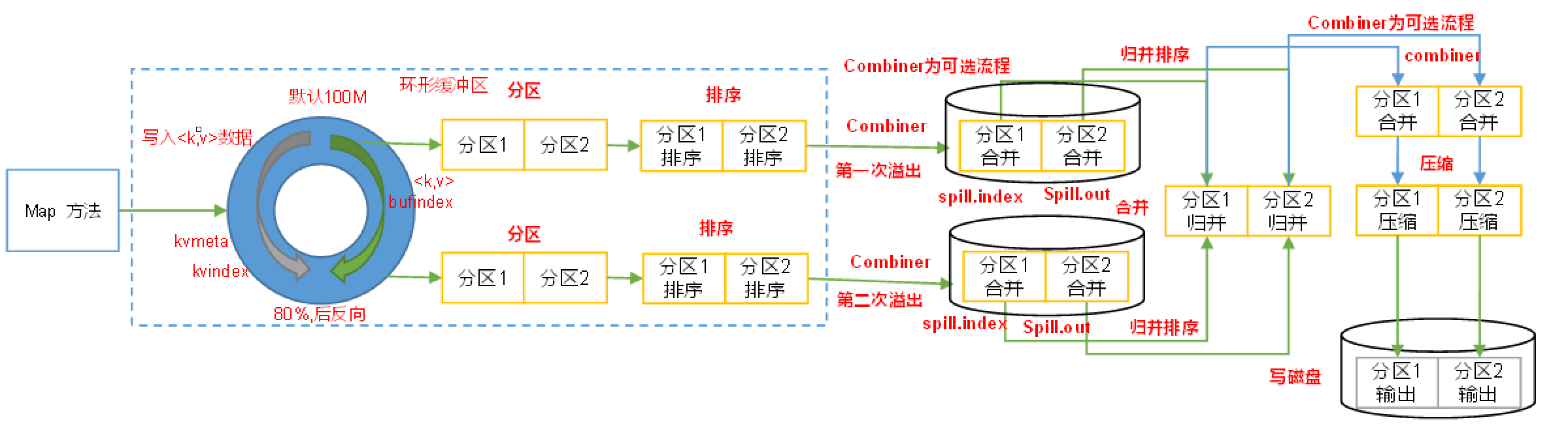
Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘IO的次数越少,执行速度就越快。
缓冲区的大小可以通过参数调整,参数:io.sort.mb默认100M
1.3 ReduceTask工作机制
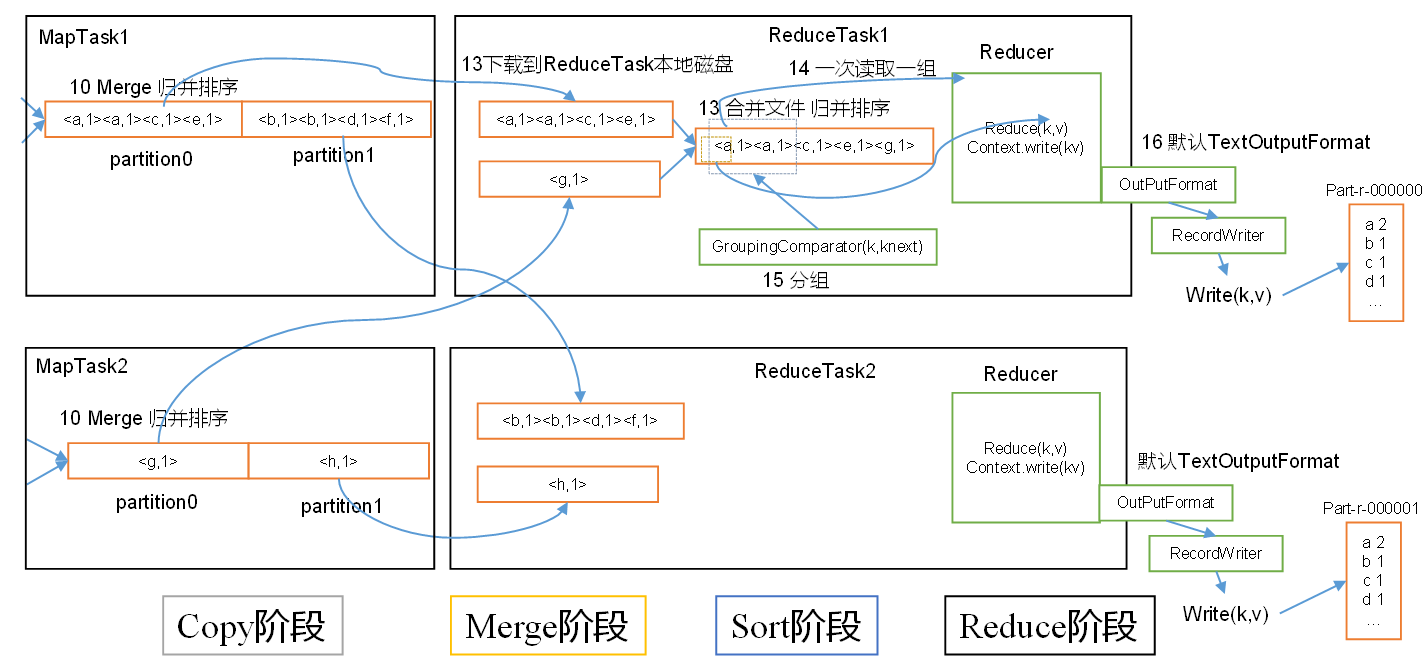
- Copy阶段:
ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中 - Merge阶段:在远程拷贝数据的同时,
ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多 - Sort阶段:按照
MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可 - Reduce阶段:
reduce()函数将计算结果写到HDFS上
二、InputFormat数据输入
InputFormat有两个重要的功能:数据切片和将切片转换为KV。
2.1 数据切片
数据切片是在逻辑上对输入进行分片,并不会在磁盘上将其拆分成片进行存储。(Block是HDFS物理上对数据的拆分)
- 一个
Job的Map阶段并行度由客户端在提交Job时的切片数决定 - 每一个
Split切片分配一个MapTask并行实例处理 - 默认情况下,切片大小=
BlockSize - 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
FileInputFormat切片源码分析(input.getSplits):
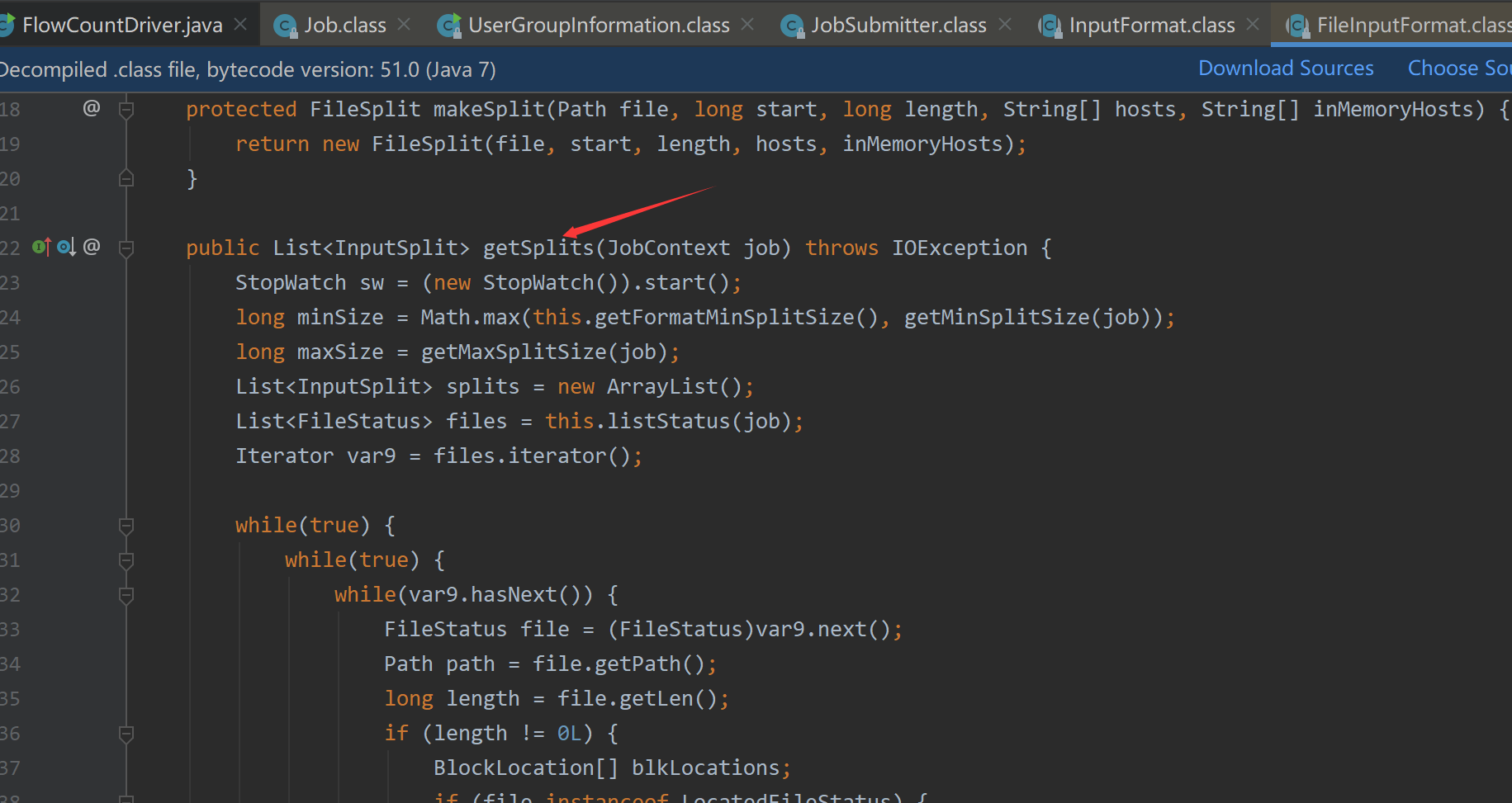
1.程序先找到你数据存储的目录
2.开始遍历处理(规划切片)目录下的每一个文件
- 获取文件大小
file.getLen() - 计算切片大小:
long splitSize = this.computeSplitSize(blockSize, minSize, maxSize);,默认splitSize=maxSize=128M,当blockSize<MaxSize时,splitSize=blockSize。每次切片时,都要判断切完剩下的部分是否大于splitSize的1.1倍,若不大于1.1倍就划分成一块切片 - 将切片信息写到一个切片规划文件
splits中
2.2 FileInputFormat实现类
在运行MapReduce程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。那么针对不同的数据类型,MapReduce是如何读取这些数据的呢?
FileInputFormat常见的接口实现类包括: TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等。
①TextInputFomat
TextInputFormat是默认的FileInputFormat实现类
切片方法: FileInputFormat的切片方法
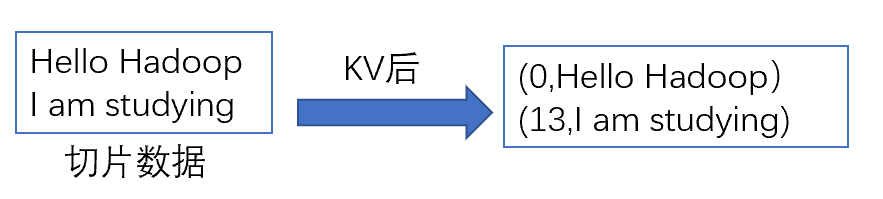
KV方法: LineRecordReader
按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量,LongWritable类型。 值是这行的内容,不包括任何行终止符( 换行符和回车符) ,Text类型。
②KeyValueInputFomat
切片方法: FileInputFormat的切片方法
KV方法: KeyValueLineRecordReader
每一行均为一条记录,被分隔符分割为K、V。可以通过在驱动类中设置
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t"),来设定分隔符。默认分隔符是tab (\t) 。

③NLineInputFomat
切片方法: 自定义切片方法
如果使用NlineInputFormat,代表每个MapTask处理的InputSplit不再按Block块去划分,而是按NlineInputFormat指定的行数N来划分。即输入文件的总行数/N=切片数,如果不整除,切片数=商+1。
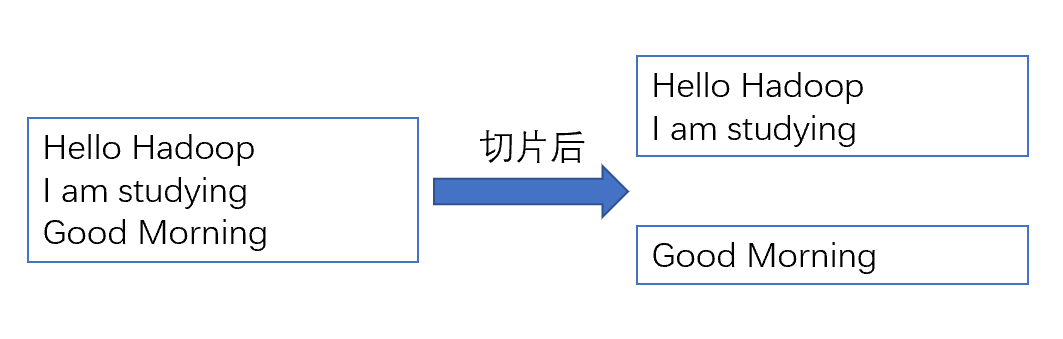
KV方法: LineRecordReader
④CombineFileInputFormat
切片方法: 自定义切片方法
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中。这样多个小文件就可以交给一个MapTask处理
虚拟存储切片最大值设置:CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m

KV方法: LineRecordReader
⑤FixedLengthInputFomat
切片方法: FileInputFormat的切片方法
KV方法: FixedLengthRecordReader
不同于LineRecordReader每次读取一行,FixedLengthRecordReader每次读取指定长度的数据。
⑥SequenceFileInputFormat
切片方法: FileInputFormat的切片方法
KV方法: SequenceFileRecordReader
读取的数据是上一个MapTask处理完的数据
⑦自定义InputFormat案例
自定义InputFormat实现小文件的合并:将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文件,存储的形式为文件路径+名称为key,文件内容为value。
①自定义RecordReader
/**
* 自定义RecordReader处理文件转换为KV
*
* @author HuChan
*/
public class WholeFileRecordReader extends RecordReader<Text, BytesWritable> {
private boolean notRead = true;
private Text key = new Text();
private BytesWritable value = new BytesWritable();
private FSDataInputStream inputStream;
private FileSplit fs;
/**
* 初始化方法,框架在开始的时候会调用一次
*/
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
//转换切片类型到文件切片
fs = (FileSplit) split;
//获取切片获取路径
Path path = fs.getPath();
//通过路径获取文件系统
FileSystem fileSystem = path.getFileSystem(context.getConfiguration());
//开流
inputStream = fileSystem.open(path);
}
/**
* 读取KV值
* 读取到返回true,读完了返回false
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (notRead) {
//读取key
key.set(fs.getPath().toString());
//读value
byte[] bytes = new byte[(int) fs.getLength()];
inputStream.read(bytes);
value.set(bytes, 0, bytes.length);
notRead = false;
return true;
} else {
return false;
}
}
/**
* 获取当前读到的key
*/
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return key;
}
/**
* 获取当前读到的value
*/
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
/**
* 当前数据读取的进度
*/
@Override
public float getProgress() throws IOException, InterruptedException {
return notRead ? 0 : 1;
}
/**
* 关流
*/
@Override
public void close() throws IOException {
//关流
IOUtils.closeStream(inputStream);
}
}
②自定义InputFormat
public class WholeFileInputFormat extends FileInputFormat<Text, BytesWritable> {
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
@Override
public RecordReader<Text, BytesWritable> createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
return new WholeFileRecordReader();
}
}
③Driver设置
public class WholeFileDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(WholeFileDriver.class);
/**
*使用默认的Mapper和Reducer
*/
//job.setMapperClass(WholeFileMapper.class);
//job.setReducerClass(WholeFileReducer.class);
job.setInputFormatClass(WholeFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(BytesWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
FileInputFormat.setInputPaths(job, new Path("D:\\MyFile\\test"));
FileOutputFormat.setOutputPath(job, new Path("d:\\output"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
三、Shuffle机制
MapReduce确保每个Reducer的输入都是按键排序的。系统执行排序的过程(即将Map输出作为输入传给Reducer)称为Shuffle。
3.1 Partition分区
默认的Partition分区,key.haCode() & Integer.MAX_VALUE这个值一定是正值,取模就是分区号,默认的是无法控制K存到具体的分区。
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
3.2 自定义Partitioner
实操: 手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中。
自定义Partitioner:
public class FlowPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int i) {
//获取电话号码的前三位
String preNum = text.toString().substring(0, 3);
int partitionNum = 4;
switch (preNum) {
case "136":
partitionNum = 0;
break;
case "137":
partitionNum = 1;
break;
case "138":
partitionNum = 2;
break;
case "139":
partitionNum = 3;
break;
}
return partitionNum;
}
}
驱动添加设置:
//设置Partitioner
job.setPartitionerClass(FlowPartitioner.class);
//设置reduce task的数量
job.setNumReduceTasks(5);
进行测试:
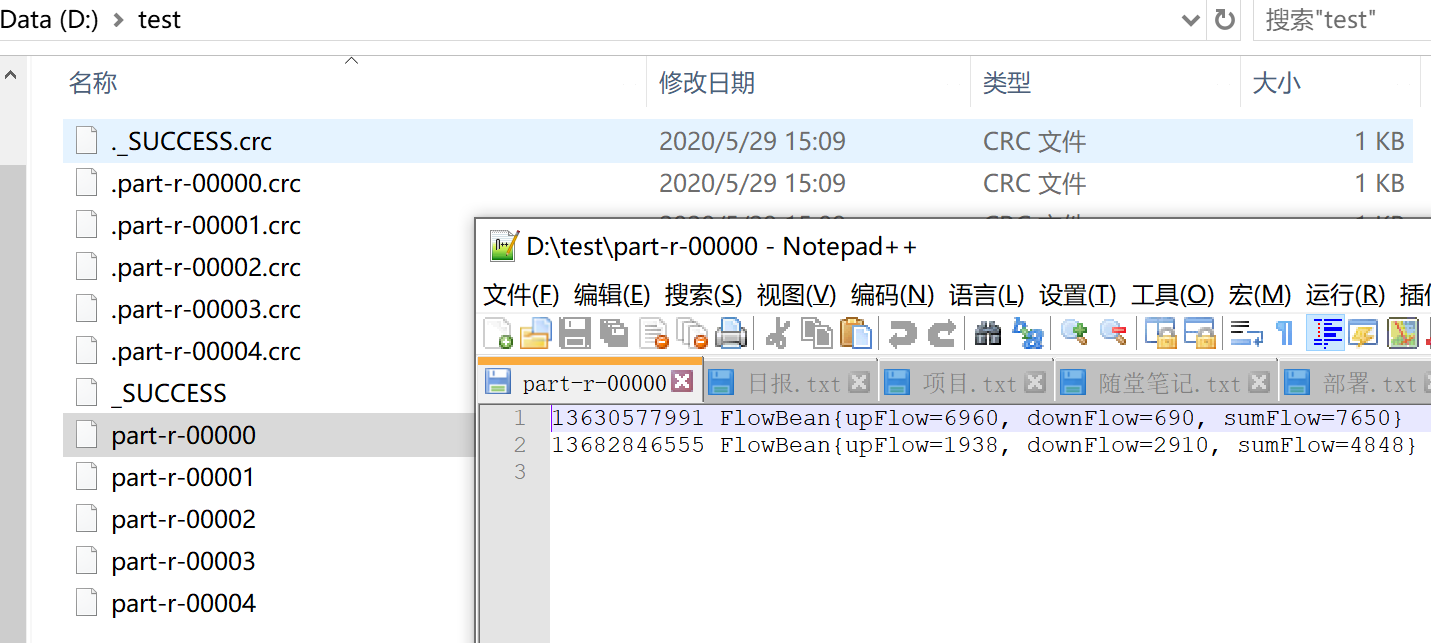
注意:
- 如果
ReduceTask的数量>getPartition的结果数,则会多产生几个空的输出文件part-r-000xx - 如果
1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会报错 - 如果
ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件part-r-00000
3.3 排序
排序是MapReduce框架中最重要的操作之一。MapTask和ReduceTask均会对数据按照key进行排序,该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。默认的排序是按照字典顺序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓存区,当环形缓存区使用率达到一定阈值后,再对缓存区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则放到磁盘上,否则放到内存中。如果磁盘上文件数目达到一定阈值,则进行一次合并以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次合并并归并排序。
排序的分类:
①部分排序:MapReduce根据输入记录的键对数据集排序,保证输出的每个文件内部排序。
②全排序: 最终输出结果只有一个文件,文件内部有序。实现方式是只设置一个ReduceTask,但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
③辅助排序(GroupingComparator分组): 在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
④二次排序: 在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
①WritableComparable全排序和区排序
实体类实现WritableComparable<T>接口,重写compareTo()方法
@Override
public int compareTo(FlowBean o) {
return Long.compare(o.getSumFlow(), this.sumFlow);
}
②GroupingComparator分组(辅助排序)
根据以下订单求出每个订单中最大商品金额,期望输出数据:
0000002 2
0000004 4
| 订单id | 商品id | 金额 |
|---|---|---|
| 0000001 | sku001 | 1 |
| 0000001 | sku002 | 2 |
| 0000002 | sku003 | 3 |
| 0000002 | sku004 | 4 |
需求分析:
- 利用订单
id和成交金额作为key,可以将Map阶段读取到的所有订单数据按照id升序排序,如果id相同再按照金额降序排序,发送到Reduce - 在
Reduce端利用groupingComparator将订单id相同的kv聚合成组,然后取第一个即是该订单中最贵商品
订单信息OrderBean类:
public class OrderBean implements WritableComparable<OrderBean> {
private int order_id; // 订单id号
private double price; // 价格
public OrderBean() {
super();
}
public OrderBean(int order_id, double price) {
super();
this.order_id = order_id;
this.price = price;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(order_id);
out.writeDouble(price);
}
@Override
public void readFields(DataInput in) throws IOException {
order_id = in.readInt();
price = in.readDouble();
}
@Override
public String toString() {
return order_id + "\t" + price;
}
public int getOrder_id() {
return order_id;
}
public void setOrder_id(int order_id) {
this.order_id = order_id;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
// 二次排序
@Override
public int compareTo(OrderBean o) {
int result;
if (order_id > o.getOrder_id()) {
result = 1;
} else if (order_id < o.getOrder_id()) {
result = -1;
} else {
// 价格倒序排序
result = price > o.getPrice() ? -1 : 1;
}
return result;
}
}
Mapper类:
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> {
OrderBean k = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 截取
String[] fields = line.split("\t");
// 3 封装对象
k.setOrder_id(Integer.parseInt(fields[0]));
k.setPrice(Double.parseDouble(fields[2]));
// 4 写出
context.write(k, NullWritable.get());
}
}
OrderSortGroupingComparator类:
public class OrderGroupingComparator extends WritableComparator {
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean aBean = (OrderBean) a;
OrderBean bBean = (OrderBean) b;
int result;
if (aBean.getOrder_id() > bBean.getOrder_id()) {
result = 1;
} else if (aBean.getOrder_id() < bBean.getOrder_id()) {
result = -1;
} else {
result = 0;
}
return result;
}
}
Reducer类:
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
Driver类:
public class OrderDriver {
public static void main(String[] args) {
...
// 设置reduce端的分组
job.setGroupingComparatorClass(OrderGroupingComparator.class);
...
}
}
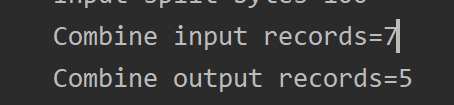
3.4 Combiner合并
Combiner是MR程序中Mapper和Reducer之外的一种组件,其父类就是Reducer。Combiner在每一个MapTask所在的节点运行,Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减少网络传输量。
自定义WordcountCombiner :
public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//1、汇总
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
v.set(sum);
context.write(key, v);
}
}
驱动类中指定Combiner:
job.setCombinerClass(WordCountCombiner.class);
使用前:

使用后:
四、OutputFormat接口实现类
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了OutputFormat接口,下面我们介绍几种常见的OutputFormat实现类。
- 文本输出TextOutputFormat
默认的输出格式是TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把它们转换为字符串。 - SequenceFileOutputFormat
SequenceFileOutputFormat将它的输出写为一个顺序文件。如果输出需要作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。 - 自定义OutputFormat
根据用户需求,自定义实现输出。
4.1 自定义OutputFormat
使用场景: 为了实现控制最终文件的输出路径和输出格式,可以定义OutputFormat
自定义OutputFormat步骤:
- 自定义一个类继承
FileInputFormat - 改写
RecordWriter,重写write()方法
案例:
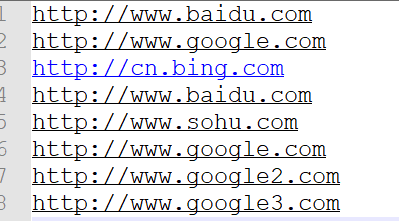
过滤输入的log.txt,包含google的网站输出到d:/google.log,不包含google的网站输出到d:/other.log。
Mapper类:
public class FilterMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, NullWritable.get());
}
}
Reducer类:
public class FilterReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
Text k = new Text();
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//获取行
String line = key.toString();
line = line + "\r\n";
k.set(line);
context.write(k, NullWritable.get());
}
}
自定义RecordWriter:
public class FilterRecordWriter extends RecordWriter<Text, NullWritable> {
FSDataOutputStream os1 = null;
FSDataOutputStream os2 = null;
public FilterRecordWriter(TaskAttemptContext job) {
//1.获取文件系统
FileSystem fs;
try {
fs = FileSystem.get(job.getConfiguration());
os1 = fs.create(new Path("d:/output/google.log"));
os2 = fs.create(new Path("d:/output/other.log"));
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
if (key.toString().contains("google")) {
os1.write(key.toString().getBytes());
} else {
os2.write(key.toString().getBytes());
}
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
IOUtils.closeStream(os1);
IOUtils.closeStream(os2);
}
}
自定义FileOutputFormat:
public class FilterOutputFormat extends FileOutputFormat<Text, NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
return new FilterRecordWriter(job);
}
}
驱动Driver
public class FilterDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FilterDriver.class);
job.setMapperClass(FilterMapper.class);
job.setReducerClass(FilterReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 要将自定义的输出格式组件设置到job中
job.setOutputFormatClass(FilterOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("D:\\MyFile\\test"));
//指定_SUCCESS文件的位置
FileOutputFormat.setOutputPath(job, new Path("d:\\output"));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}

