

MySQL聚族索引、辅助索引、回表和索引覆盖
聚族索引与辅助索引的概念
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据。表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。
辅助索引/非聚簇索引:将数据存储与索引分开,叶结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
主要针对InnoDB引擎,InnoDB的数据文件本身就是按照B+树方式存放的;而MyISAM的数据文件是放在MYD文件中,索引是放在MYI文件中,都是辅助索引
什么是索引覆盖,哪些情况需要回表
索引覆盖:只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。explain的输出结果Extra字段为Using index时,能够触发索引覆盖。
回表查询:先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
辅助索引上没有需要的数据时需要回表,辅助索引的数据包括:主键、索引字段
使用索引覆盖/延迟关联减少回表次数
如果要查询较大数据表的最后几页(偏移量很大),则查询时是先查询满足where条件的记录、回表,再放弃前N页记录的,这样回表次数很多
延迟关联则是:通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据。使用方法类似下面sql:
select * from user a join (select id from user limit 20000, 10) b on a.id=b.id;
select * from user where id in (select id from user limit 20000, 10);
实例:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`department` varchar(255) NOT NULL,
`passwd` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_u` (`name`,`department`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=latin1
insert into user (name,department,passwd) values ('hubery', 'ued', '123');
1、select department from user where name='ued'会用到索引覆盖

2、select department from user where name='ued' and department='ued'会用到索引覆盖
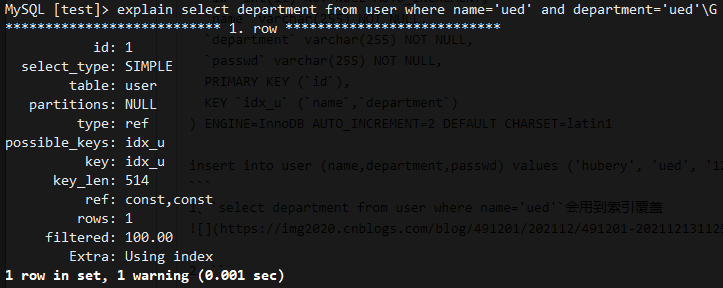
3、select passwd from user where name='ued'不会使用索引覆盖,需要回表
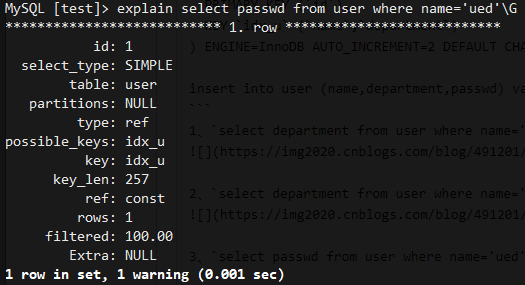
4、select passwd from user where passwd='123'不会使用索引覆盖,需要回表
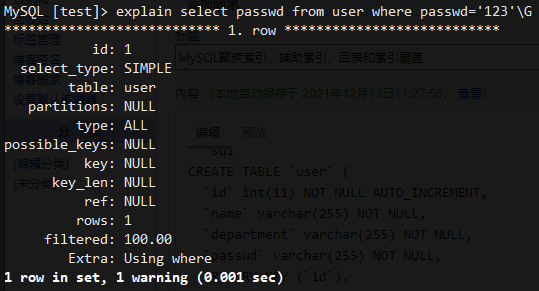
5、select name from user会用到索引覆盖
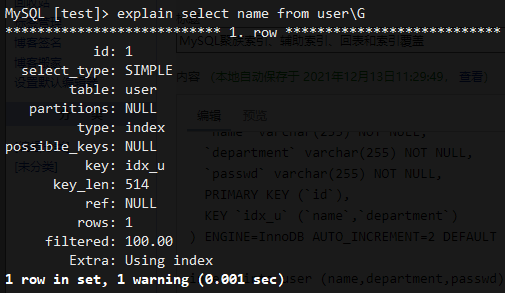
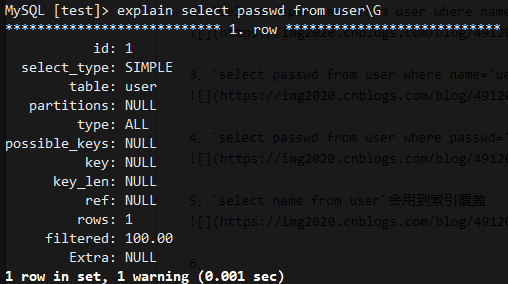
6、select passwd from user不会使用索引覆盖
总结:会用到索引覆盖的情况:
1、查询条件命中索引,且查询字段是这个索引的字段或者主键;
2、没有查询条件,但查询字段是某个索引的字段或者是主键

