

hotspot x86平台的内存屏障的实现
hotspot x86平台上的内存屏障的实现依赖于lock指令,而Intel的lock指令的实现依赖于缓存一致性协议(例如MESI)。
本文只介绍hotspot X86平台的内存屏障的实现,没有任何关于其他平台是怎么实现内存屏障的内容。
一、字节码解释器源码分析验证
hotspot字节码解释器在处理putfield/putstatic的时候,如果要处理的结果是volatile修饰的,那么在处理完成之后还需要调用内存屏障指令OrderAccess::storeload();

CASE(_putfield): CASE(_putstatic): { u2 index = Bytes::get_native_u2(pc+1); ConstantPoolCacheEntry* cache = cp->entry_at(index); if (!cache->is_resolved((Bytecodes::Code)opcode)) { CALL_VM(InterpreterRuntime::resolve_from_cache(THREAD, (Bytecodes::Code)opcode), handle_exception); cache = cp->entry_at(index); } // 省略一些代码 // // Now store the result // int field_offset = cache->f2_as_index(); if (cache->is_volatile()) { switch (tos_type) { ...... // 省略很多代码 } OrderAccess::storeload(); } // 省略很多代码
这里cache->is_volatile()中的cache并不是指CPU cache,而是ConstantPoolCacheEntry。
以32bit机器为例,如果ConstantPoolCacheEntry表示的是字段,那么ConstantPoolCacheEntry的字段信息如下(参考:类的连接之重写(2) - 鸠摩(马智) - 博客园 (cnblogs.com)):
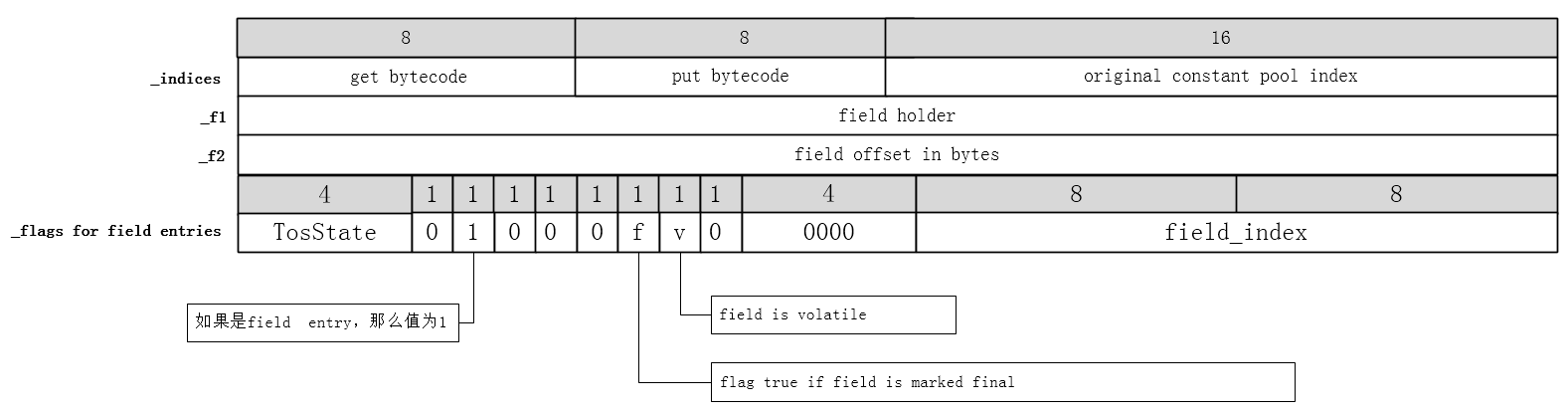
所以,这只是用来判断putfield/putstatic操作的属性是否有volatile修饰(对应的比特位是否置位,即标志有无volatile修饰该字段)。
这有点题外话,当然我们要关注的是最后调用内存屏障指令的代码OrderAccess::storeload()。
先转到OrderAccess.hpp头文件中看看x86平台内存屏障实现的注释,这段注释值得好好读一读《Memory Access Ordering Model》。

x86平台,fence的实现依赖于lock前缀指令。
查看fence()函数,要转到OrderAccess的x86文件中。
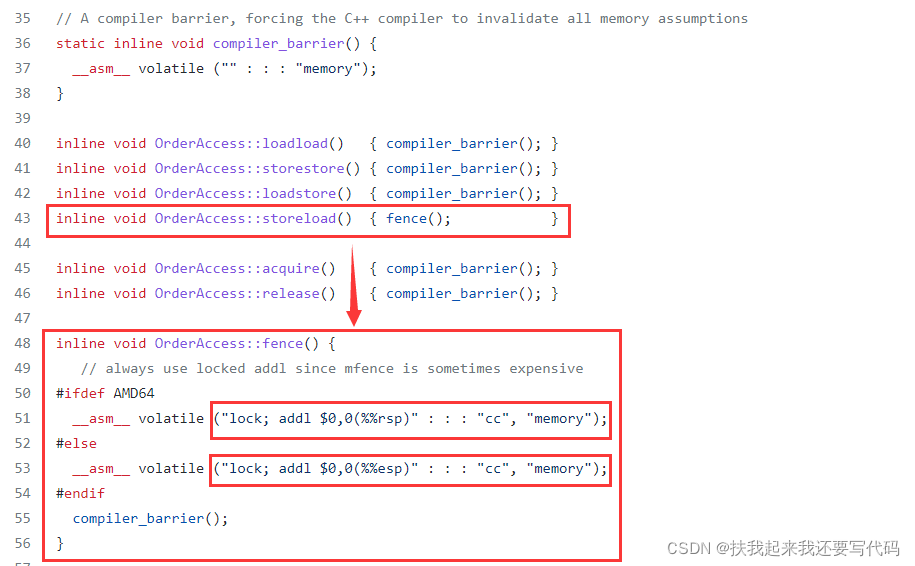
storeload内存屏障的实现是fence()函数,fence()函数的函数体是AT&T的内联汇编,内联汇编的指令是lock前缀指令。
其他内存屏障的实现依赖于C++的编译器屏障,也是一个AT&T的内联汇编,不过这句内联汇编的指令的含义是A compiler barrier, forcing the C++ compiler to invalidate all memory assumptions。
差不多的内容,你在hotspot的模板解释器中也能得以验证。
二、模板解释器源码分析验证
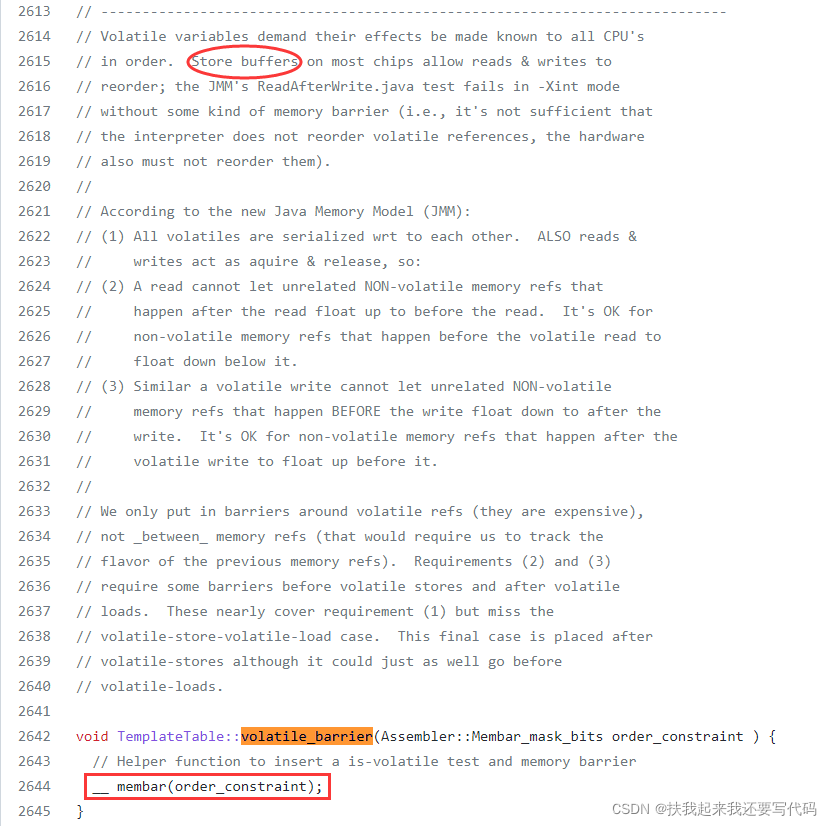
这段注释也值得好好读一读,注释中提到store buffer是导致存储系统重排序的硬件,和invalid queue这个硬件一样,都是在优化MESI总线事务的过程中慢慢演进出来的硬件,这里可以进一步参看《why memory barriers》。
membar函数要转到assembler_x86.cpp文件中,
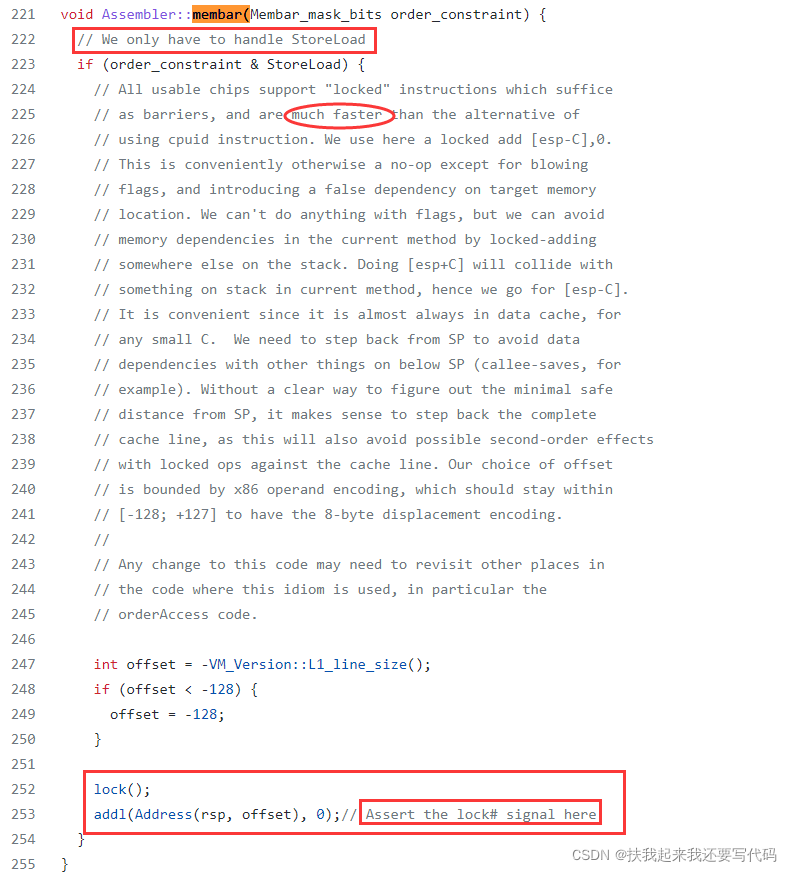
我建议看红框中的注释就可以了,如果接下来你要去深究lock()函数和addl()函数,那是非常底层非常繁复的机器码生成的计算,你要对照二进制表去查找,最终得到的结果和注释一样。
void Assembler::lock() { emit_int8((unsigned char)0xF0); }
emit_int8相关机器码生成的计算方法,你当然可以挑战一下,我给你做个引子:【JVM】模板解释器--如何根据字节码生成汇编码? - foreach_break - 博客园 (cnblogs.com)
通过hotspot字节码解释器和模板解释器的源码分析,我觉得可以得出文首结论中“hotspot x86平台上的内存屏障的实现依赖于lock指令”,至于后半句“Intel的lock指令的实现依赖于缓存一致性协议(例如MESI)”,我们接着往下看。
三、Intel lock前缀指令
首先需要参见以前写的文章:《Intel lock前缀指令》
你可以先看看下面【概述】一节对lock前缀指令的总结,然后再去详细看看文章。
3.1概述
lock前缀指令的作用:turns the instruction into an atomic instruction
Intel CPU手册中讲解lock前缀指令时明确说了,lock前缀指令会将它修饰的指令变为原子指令,其实现在奔腾pro处理器前后的区别如下(奔腾pro处理器代号P6):
1.在P6处理器以前(即奔腾pro)是锁总线:For the Intel486 and Pentium processors, the LOCK# signal is always asserted on the bus during a LOCK operation, even if the area of memory being locked is cached in the processor. 2.在P6及P6处理器以后,如果数据缓存在CPU cache中,那么就不用锁总线,而是通过缓存一致性协议来锁缓存:For the P6 and more recent processor families, if the area of memory being locked during a LOCK operation is cached in the processor that is performing the LOCK operation as write-back memory and is completely contained in a cache line, the processor may not assert the LOCK# signal on the bus. Instead, it will modify the memory location internally and allow it’s cache coherency mechanism to ensure that the operation is carried out atomically. This operation is called “cache locking.” The cache coherency mechanism automatically prevents two or more processors that have cached the same area of memory from simultaneously modifying data in that area.
存在的疑问有:
lock前缀指令能修饰哪些指令?
lock前缀指令怎么实现原子性的?
Java volatile的实现依赖于lock指令(反汇编就能看到),网上很多文章说volatile不支持原子性,是对的吗?如果不对,怎么理解volatile的原子性?
3.2lock前缀指令能修饰哪些指令
lock前缀指令能够修饰的指令有:The LOCK prefix can be prepended only to the following instructions and only to those forms of the instructions where the destination operand is a memory operand: ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, CMPXCHG16B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG.
其中:
1.XCHG指令无论是否存在lock前缀指令的修饰,都会向CPU的lock引脚发送信号:The XCHG instruction always asserts the LOCK# signal regardless of the presence or absence of the LOCK prefix.
2.修饰BTS指令时,能实现内存的读改写:The LOCK prefix is typically used with the BTS instruction to perform a read-modify-write operation on a memory location in shared memory environment.
3.3lock前缀指令原子性的理解和实现
结论:lock前缀指令的原子性是单操作的原子性。
Intel CPU手册上明确说了lock前缀能将其修饰的指令变成原子指令,所以其拥有的原子性毋庸置疑,网上那么些分析volatile非原子的博客赶紧洗洗睡吧。
先理解lock前缀指令的原子性是单操作原子性,再来看怎么实现。
a.理解单操作原子性
其实很简单,就是只能对单个指令实现原子性,也就是只能对读写volatile修饰的变量的单个store操作或load操作实现原子性。
举个例子,以前在32bit机器上读写64bit的long、double变量都需要volatile来修饰。因为只有32bit的数据总线,一次只能读写一半的值,所以要读写long、double修饰的变量需要操作两次,因此在并发情况下就有可能出现问题,所以需要在访存期间借助lock指令来锁住内存总线,直到先后两次读完数据。
如果你依旧相信网上那些“volatile不支持原子性”的文章,那么我再甩一点证据:
1.JLS6,即Java6语言规范中对long、double读写非原子性的讲解:
章节:8.4 Nonatomic Treatment of double and long Variables
地址:VM Spec Threads and Locks (oracle.com)
8.4 Nonatomic Treatment of double and long Variables If a double or long variable is not declared volatile, then for the purposes of load, store, read, and write operations it is treated as if it were two variables of 32 bits each; wherever the rules require one of these operations, two such operations are performed, one for each 32-bit half. The manner in which the 64 bits of a double or long variable are encoded into two 32-bit quantities and the order of the operations on the halves of the variables are not defined by The Java Language Specification. This matters only because a read or write of a double or long variable may be handled by an actual main memory as two 32-bit read or write operations that may be separated in time, with other operations coming between them. Consequently, if two threads concurrently assign distinct values to the same shared non-volatile double or long variable, a subsequent use of that variable may obtain a value that is not equal to either of the assigned values, but rather some implementation-dependent mixture of the two values. An implementation is free to implement load, store, read, and write operations for double and long values as atomic 64-bit operations; in fact, this is strongly encouraged. The model divides them into 32-bit halves for the sake of currently popular microprocessors that fail to provide efficient atomic memory transactions on 64-bit quantities. It would have been simpler for the Java virtual machine to define all memory transactions on single variables as atomic; this more complex definition is a pragmatic concession to current hardware practice. In the future this concession may be eliminated. Meanwhile, programmers are cautioned to explicitly synchronize access to shared double and long variables.
2.stockoverflow上对该问题的复现代码:java - long and double assignments are not atomic - How does it matter? - Stack Overflow
3.知乎上的一些问答:(1 封私信 / 70 条消息) 64位JVM的long和double读写也不是原子操作么? - 知乎 (zhihu.com)
理解了lock前缀指令支持单操作原子性后,再来看看怎么实现单操作原子性的。
b.实现单操作原子性
intel CPU手册《卷二:指令集》中的介绍:
Beginning with the P6 family processors, when the LOCK prefix is prefixed to an instruction and the memory area being accessed is cached internally in the processor, the LOCK# signal is generally not asserted. Instead, only the processor’s cache is locked. Here, the processor's cache coherency mechanism ensures that the operation is carried out atomically with regards to memory. See “Effects of a Locked Operation on Internal Processor Caches” in Chapter 8 of Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A, the for more information on locking of caches.
Intel CPU手册《卷三:系统编程》中的分析:
For the Intel486 and Pentium processors, the LOCK# signal is always asserted on the bus during a LOCK operation, even if the area of memory being locked is cached in the processor. For the P6 and more recent processor families, if the area of memory being locked during a LOCK operation is cached in the processor that is performing the LOCK operation as write-back memory and is completely contained in a cache line, the processor may not assert the LOCK# signal on the bus. Instead, it will modify the memory location internally and allow it’s cache coherency mechanism to ensure that the operation is carried out atomically. This operation is called “cache locking.” The cache coherency mechanism automatically prevents two or more processors that have cached the same area of memory from simultaneously modifying data in that area.
锁总线是怎么做到的?
你回看一下《Intel lock前缀指令》中《微机原理》介绍CPU lock引脚的部分,lock前缀指令的执行会向CPU lock引脚发送LT信号(水平触发信号),低电平有效,也就是在lock前缀指令修饰的指令执行期间都会拉低CPU lock引脚的电平,直到lock前缀指令修饰的指令执行完才会撤销。
而CPU在lock信号期间,是不允许其他设备申请获得总线的控制权成为主设备的。
所以在CPU lock引脚lock信号有效期间,只有lock前缀指令修饰的指令才能获得内存总线的访问权。
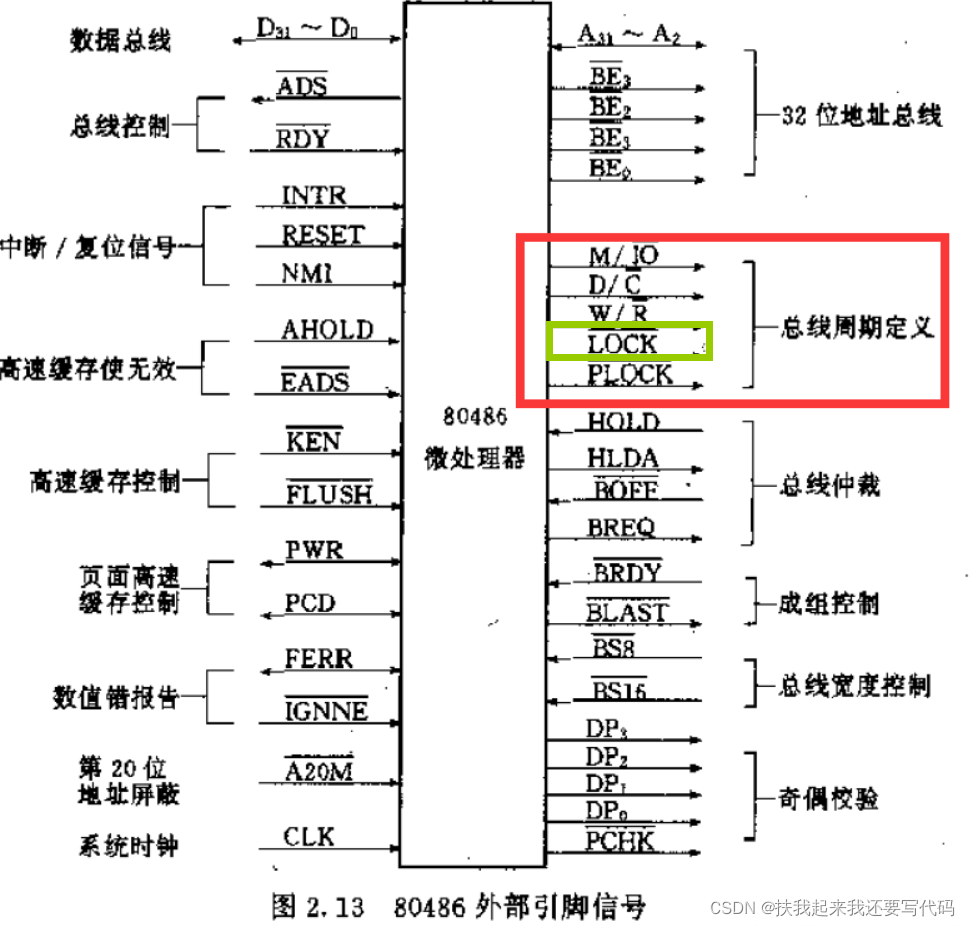
锁缓存是怎么做到的?
在P6处理器以后,如果lock前缀指令修饰的指令要操作的数据已经保存在CPU cache中了,那么就不再锁总线,而是锁缓存,同样通过lock前缀指令来实现。
通过上面hotspot x86源码分析可知,lock前缀指令在x86平台上是具备内存屏障的能力的。
早期单纯依赖缓存一致性来实现锁缓存:可以参看SMP架构上的缓存一致性协议MESI,这是一个监听协议,用来保证多核CPU cache中多个数据副本的一致性的,MESI参看【并发编程】CPU cache结构和缓存一致性(MESI协议)_厚积薄发者,轻舟万重山-CSDN博客
因为MESI的总线事务相比较CPU的执行速度属于慢速操作,为了不让CPU流水冒泡浪费性能,所以加入了store buffer、invalid queue等硬件来做总线事务两端的加速,这时候就需要内存屏障+缓存一致性协议来达到锁缓存的效果,而lock前缀指令是具备内存屏障的能力的,这时候参看《why memory barriers》
3.4Java volatile是否支持原子性
网上很多博客分析volatile不具备原子性时给的例子都是volatile num,然后num++/--,于是得出结论volatile不具备原子性。
实际上,非局部变量的++/--不是一个操作,而是一组操作。
a.实例属性
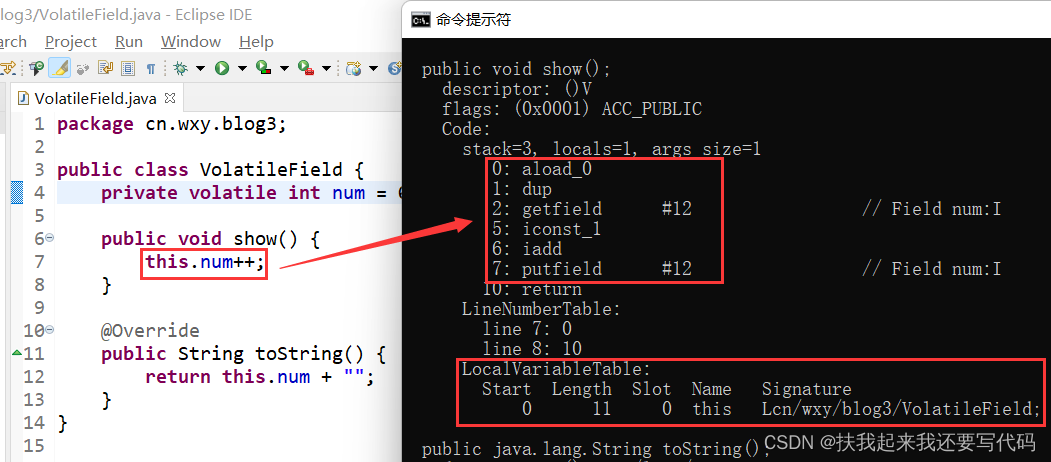
javap工具反编译之后,你可以看到一句this.num++代码实际上对应着hotspot虚拟机6条指令:
aload_0是将show()方法局部变量表slot 0位置存放的this加载到操作数栈的栈顶
dup指令会复制栈顶的值,然后压入栈顶,所以现在栈上有两个this(getfield会用掉一个this,后面putfield会把最后一个this用掉)
有了this就能拿到其对应的属性field了,getfield #12中的#12是常量池的符号链接,指明是哪个类的哪个属性,实际上有"this"这个内存地址,直接就能到堆里面去找到field的值,这一块是对象的内存布局的知识
#12 = Fieldref #1.#13 // cn/wxy/blog3/VolatileField.num:I
getfield指令把num的值加载到栈顶,但得知道是谁的num,所以需要栈顶的this,所以getfield这句指令会先把this出栈找到num,然后把num加载到栈顶,现在栈上有this和栈顶的num
紧接着iconst_1将常量1压栈,现在操作数栈上有三个值,栈顶常量1、属性num和this
iadd指令将栈顶的两个int值出栈(栈顶是常量1和属性num的值),送到CPU的计算单元相加,结果压栈,现在栈上是栈顶相加的值和this
最后putfield需要两个参数,即将刚才压栈的计算结果写到堆内存中this对应的field
所以你看,对于hotspot虚拟机而言,this.num++这句代码不是一个单操作,而是一组操作。
volatile保证的是单操作的原子性,也就是只支持getField/putField的原子性;要保证一组操作的原子性,那就得加锁了,volatile只能保证单操作的原子性。
b.静态属性
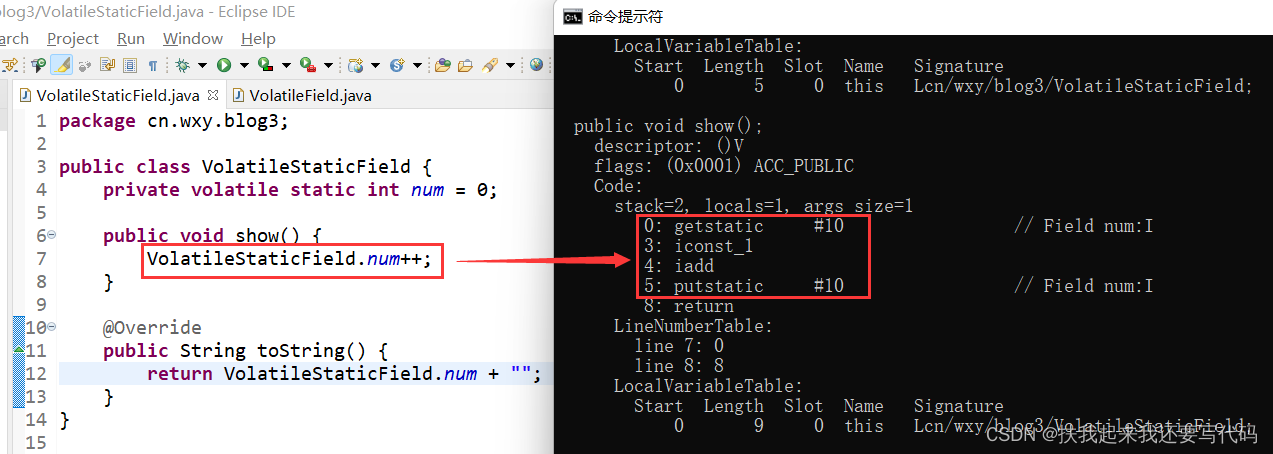
javap工具反编译之后,VolatileStaticField.num++这句代码实际上对应着4条hotspot指令:
getstatic方法区拿到num的值压栈放入栈顶
#10 = Fieldref #1.#11 // cn/wxy/blog3/VolatileStaticField.num:I
#10是常量池的符号链接,static的变量类加载的准备阶段默认初始化,类加载的初始化阶段赋值
iconst_1:常量1压栈,现在栈顶是常量1和num的值
iadd:栈顶的两个操作数出栈(常量1和num的值出栈),送到CPU计算单元相加,结果压栈
putstatic:将栈顶的计算结果写回方法区
同样,这一部分也是为了证明,共享变量的++/--操作不是单操作,而是一组操作。
再次强调,volatile只能保证单操作的原子性,要保证一组操作的原子性,那你需要加锁。
本文摘自,如有侵权,请联系我!!!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?