
MySQL运维基础知识面试问答题
- 主库宕机后,数据可能丢失
- 从库只有一个sql Thread,主库写压力大,复制很可能延时
- 半同步复制---解决数据丢失的问题
- 并行复制----解决从库复制延迟的问题
- 5.5集成到mysql,以插件的形式存在,需要单独安装
- 确保事务提交后binlog至少传输到一个从库
- 不保证从库应用完这个事务的binlog
- 性能有一定的降低,响应时间会更长
- 网络异常或从库宕机,卡主主库,直到超时或从库恢复

主从复制的作用(好处,或者说为什么要做主从)重点!
1、做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。 2、架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。 3、读写分离,使数据库能支撑更大的并发。在报表中尤其重要。 由于部分报表sql语句非常的慢,导致锁表,影响前台服务。如果前台使用master,报表使用slave,那么报表sql将不会造成前台锁,保证了前台速度。
MYSQL复制的几种模式
从 MySQL 5.1.12 开始,可以用以下三种模式来实现: -- 基于SQL语句的复制(statement-based replication, SBR), -- 基于行的复制(row-based replication, RBR), -- 混合模式复制(mixed-based replication, MBR)。 相应地,binlog的格式也有三种:STATEMENT,ROW,MIXED。 MBR 模式中,SBR 模式是默认的。 两种模式各自的优缺点: SBR 的优点: 历史悠久,技术成熟 binlog文件较小 binlog中包含了所有数据库更改信息,可以据此来审核数据库的安全等情况 binlog可以用于实时的还原,而不仅仅用于复制 主从版本可以不一样,从服务器版本可以比主服务器版本高 SBR 的缺点: 不是所有的UPDATE语句都能被复制,尤其是包含不确定操作的时候。 调用具有不确定因素的 UDF 时复制也可能出问题 使用以下函数的语句也无法被复制: * LOAD_FILE() * UUID() * USER() * FOUND_ROWS() 数据表必须几乎和主服务器保持一致才行,否则可能会导致复制出错 执行复杂语句如果出错的话,会消耗更多资源 ================================ RBR 的优点: 任何情况都可以被复制,这对复制来说是最安全可靠的 和其他大多数数据库系统的复制技术一样 多数情况下,从服务器上的表如果有主键的话,复制就会快了很多 从服务器上采用多线程来执行复制成为可能 RBR 的缺点: binlog 大了很多 复杂的回滚时 binlog 中会包含大量的数据 主服务器上执行 UPDATE 语句时,所有发生变化的记录都会写到 binlog 中,而 SBR 只会写一次,这会导致频繁发生 binlog 的并发写问题 UDF 产生的大 BLOB 值会导致复制变慢 无法从 binlog 中看到都复制了写什么语句(加密过的) 当在非事务表上执行一段堆积的SQL语句时,最好采用 SBR 模式,否则很容易导致主从服务器的数据不一致情况发生 另外,针对系统库 mysql 里面的表发生变化时的处理规则如下: 如果是采用 INSERT,UPDATE,DELETE 直接操作表的情况,则日志格式根据 binlog_format 的设定而记录 如果是采用 GRANT,REVOKE,SET PASSWORD 等管理语句来做的话,那么无论如何都采用 SBR 模式记录 注:采用 RBR 模式后,能解决很多原先出现的主键重复问题。
面试题001:请解释关系型数据库概念及主要特点?
关系型数据库模型是把复杂的数据结构归结为简单的二元关系,对数据的操作都是建立一个或多个关系表格上,最大的特点就是二维的表格,通过SQL结构查询语句存取数据,保持数据一致性方面很强大
面试题002:请说出关系型数据库的典型产品、特点及应用场景?
关系型数据库模型是把复杂的数据结构归结为简单的二元关系,对数据的操作都是建立一个或多个关系表格上,最大的特点就是二维的表格,通过SQL结构查询语句存取数据,保持数据一致性方面很强大
面试题003:请解释非关系型数据库概念及主要特点?
非关系型数据库也被称为NoSQL数据库,数据存储不需有特有固定的表结构 特点:高性能、高并发、简单易安装
面试题004:请说出非关系型数据库的典型产品、特点及应用场景?
1、memcaced 纯内存 2、redis 持久化缓存 3、mongodb 面向文档 如果需要短时间响应的查询操作,没有良好模式定义的数据存储,或者模式更改频繁的数据存储还是用NoSQL
面试题005:请详细描述SQL语句分类及对应代表性关键字。

sql语句分类如下 DDL 数据定义语言,用来定义数据库对象:库、表、列 代表性关键字:create alter drop DML 数据操作语言,用来定义数据库记录 代表性关键字:insert delete update DCL 数据控制语言,用来定义访问权限和安全级别 代表性关键字:grant deny revoke DQL 数据查询语言,用来查询记录数据 代表性关键字:select
面试题006:请详细描述char(4)和varchar(4)的差别
char长度是固定不可变的,varchar长度是可变的(在设定内)比如同样写入cn字符,char类型对应的长度是4(cn+两个空格),但varchar类型对应长度是2
面试题007:如何创建一个utf8字符集的数据库mingongge?
create database mingongge default charset utf8 collate utf8_general_ci;
面试题008:如何授权mingongge用户从172.16.1.0/24访问数据库。
grant all on *.* to mingongge@'172.16.1.0/24' identified by '123456';
面试题009:什么是MySQL多实例,如何配置MySQL多实例?
mysql多实例就是在同一台服务器上启用多个mysql服务,它们监听不同的端口,运行多个服务进程,它们相互独立,互不影响的对外提供服务,便于节约服务器资源与后期架构扩展 多实例的配置方法有两种: 1、一个实例一个配置文件,不同端口 2、同一配置文件(my.cnf)下配置不同实例,基于mysqld_multi工具
面试题010:如何加强MySQL安全,请给出可行的具体措施?
1、删除数据库不使用的默认用户 2、配置相应的权限(包括远程连接) 3、不可在命令行界面下输入数据库的密码 4、定期修改密码与加强密码的复杂度
面试题011:MySQL root密码忘了如何找回?
参考前面的回答
面试题012:delete和truncate删除数据的区别?
前者删除数据可以恢复,它是逐条删除速度慢 后者是物理删除,不可恢复,它是整体删除速度快
面试题013:MySQL Sleep线程过多如何解决?
1、可以杀掉sleep进程,kill PID 2、修改配置,重启服务
[mysqld] wait_timeout = 600 interactive_timeout=30 #如果生产服务器不可随便重启可以使用下面的方法解决 set global wait_timeout=600 set global interactive_timeout=30;
面试题014:sort_buffer_size参数作用?如何在线修改生效?
在每个connection(session)第一次连接时需要使用到,来提访问性能 set global sort_buffer_size = 2M
面试题015:如何在线正确清理MySQL binlog?
MySQL中的binlog日志记录了数据中的数据变动,便于对数据的基于时间点和基于位置的恢复 但日志文件的大小会越来越大,点用大量的磁盘空间,因此需要定时清理一部分日志信息 手工删除: 首先查看主从库正在使用的binlog文件名称 show master(slave) status\G 删除之前一定要备份 purge master logs before'2017-09-01 00:00:00'; #删除指定时间前的日志 purge master logs to'mysql-bin.000001'; #删除指定的日志文件 自动删除: 通过设置binlog的过期时间让系统自动删除日志 show variables like 'expire_logs_days'; set global expire_logs_days = 30; #查看过期时间与设置过期时间
面试题016:Binlog工作模式有哪些?各什么特点,企业如何选择?
1.Row(行模式); 日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改 2.Statement(语句模式) 每一条修改的数据都会完整的记录到主库master的binlog里面,在slave上完整执行在master执行的sql语句 3.mixed(混合模式) 结合前面的两种模式,如果在工作中有使用函数 或者触发器等特殊功能需求的时候,使用混合模式 数据量达到比较高时候,它就会选择 statement模式,而不会选择Row Level行模式
面试题017:误操作执行了一个drop库SQL语句,如何完整恢复?
1、停止主从复制,在主库上执行锁表并刷新binlog操作,接着恢复之前的全备文件(比如0点的全备) 2、将0点时的binlog文件与全备到故障期间的binlog文件合并导出成sql语句 mysqlbinlog --no-defaults mysql-bin.000011 mysql-bin.000012 >bin.sql 3、将导出的sql语句中drop语句删除,恢复到数据库中 mysql -uroot -pmysql123 < bin.sql
面试题018:mysqldump备份使用了-A -B参数,如何实现恢复单表?
-A 此参数作用是备份所有数据库(相当于--all-databases) -B databasename 备份指定数据(单库备份使用)
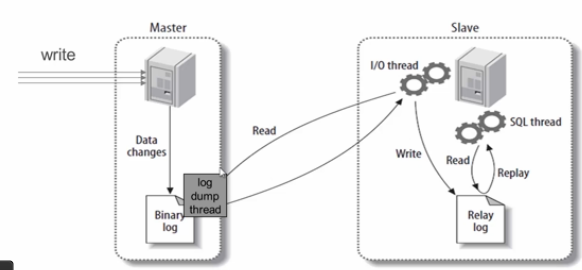
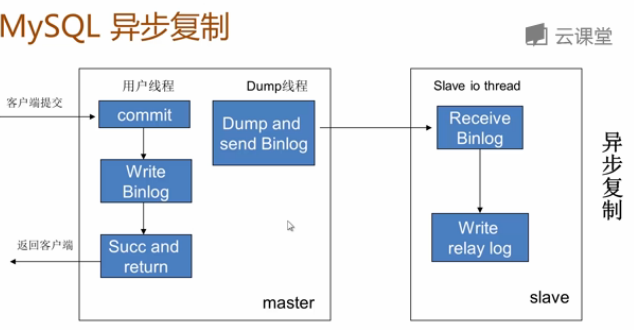
面试题019:详述MySQL主从复制原理及配置主从的完整步骤
主从复制的原理如下: 主库开启binlog功能并授权从库连接主库,从库通过change master得到主库的相关同步信息,然后连接主库进行验证,主库IO线程根据从库slave线程的请求,从master.info开始记录的位置点向下开始取信息,
同时把取到的位置点和最新的位置与binlog信息一同发给从库IO线程,从库将相关的sql语句存放在relay-log里面,最终从库的sql线程将relay-log里的sql语句应用到从库上,至此整个同步过程完成,之后将是无限重复上述过程 完整步骤如下: 1、主库开启binlog功能,并进行全备,将全备文件推送到从库服务器上 2、show master status\G 记录下当前的位置信息及二进制文件名 3、登陆从库恢复全备文件 4、执行change master to 语句 5、执行start slave and show slave status\G
面试题020:如何开启从库的binlog功能?
修改配置文件加上下面的配置 log_bin=slave-bin log_bin_index=slave-bin.index 需要重启服务生效
面试题021:MySQL如何实现双向互为主从复制,并说明应用场景?
双向同步主要应用于解决单一主库写的压力,具体配置如下 主库配置 [mysqld] auto_increment_increment = 2 #起始ID auto_increment_offset = 1 #ID自增间隔 log-slave-updates 从库配置 [mysqld] auto_increment_increment = 2 #起始ID auto_increment_offset = 2 #ID自增间隔 log-slave-updates 主从库服务器都需要重启mysql服务
面试题022:MySQL如何实现级联同步,并说明应用场景?
级联同步主要应用在从库需要做为其它数据库的主库 在需要做级联同步的数据库配置文件增加下面的配置即可 log_bin=slave-bin log_bin_index=slave-bin.index
面试题023:MySQL主从复制故障如何解决?
登陆从库 1、执行stop slave;停止主从同步 2、然后set global sql_slave_skip_counter = 1;跳过一步错误 3、最后执行 start slave;并查看主从同步状态 需要重新进行主从同步操作步骤如下 进入主库 1、进行全备数据库并刷新binlog,查看主库此的状态 2、恢复全备文件到从库,然后执行change master 3、开启主从同步start slave;并查看主从同步状态
面试题024:如何监控主从复制是否故障?
mysql -uroot -ppassowrd -e "show slave status\G" |grep -E "Slave_IO_Running|Slave_SQL_Running"|awk '{print $2}'|grep -c Yes
通过判断Yes的个数来监控主从复制状态,正常情况等于2
面试题025:MySQL数据库如何实现读写分离?
1、通过开发程序实现 2、通过其它工具实现(如mysql-mmm)
面试题026:生产一主多从从库宕机,如何手工恢复?
1、执行stop slave 或者停止服务 2、修复好从库数据库 3、然后重新操作主库同步
面试题027:生产一主多从主库宕机,如何手工恢复?
1、登陆各个从库停止同步,并查看谁的数据最新,将它设置为新主库让其它从库同步其数据
2、修复好主库之后,生新操作主从同步的步骤就可以了
#需要注意的新的主库如果之前是只读,需要关闭此功能让其可写
#需要在新从库创建与之前主库相同的同步的用户与权限
#其它从库执行change master to master_port=新主库的端口,start slave
面试题028:工作中遇到过哪些数据库故障,请描述2个例子?
1、开发使用root用户在从库上写入数据造成主从数据不一致,并且前端没有展示需要修改的内容(仍旧是老数据) 2、内网测试环境服务器突然断电造成主从同步故障
面试题029:MySQL出现复制延迟有哪些原因?如何解决?
1、需要同步的从库数据太多 2、从库的硬件资源较差,需要提升 3、网络问题,需要提升网络带宽 4、主库的数据写入量较大,需要优配置和硬件资源 5、sql语句执行过长导致,需要优化
面试题030:给出企业生产大型MySQL集群架构可行备份方案?
1、双主多从,主从同步的架构,然后实行某个从库专业做为备份服务器 2、编写脚本实行分库分表进行备份,并加入定时任务 3、最终将备份服务推送至内网专业服务器,数据库服务器本地保留一周 4、备份服务器根据实际情况来保留备份数据(一般30天)
面试题031:什么是数据库事务,事务有哪些特性?企业如何选择?
数据库事务是指逻辑上的一组sql语句,组成这组操作的各个语句,执行时要么成功,要么失败 特点:具有原子性、隔离性、持久性、一致性
面试题032:请解释全备、增备、冷备、热备概念及企业实践经验?
全备:数据库所有数据的一次完整备份,也就是备份当前数据库的所有数据 增备:就在上次备份的基础上备份到现在所有新增的数据 冷备:停止服务的基础上进行备份操作 热备:实行在线进行备份操作,不影响数据库的正常运行 全备在企业中基本上是每周或天一次,其它时间是进行增量备份 热备使用的情况是有两台数据库在同时提供服务的情况,针对归档模式的数据库 冷备使用情况有企业初期,数据量不大且服务器数量不多,可能会执行某些库、表结构等重大操作时
面试题033:MySQL的SQL语句如何优化?
建立主键与增加索引
面试题034:企业生产MySQL集群架构如何设计备份方案?
1、集群架构可采用双主多从的模式,但实际双主只有一主在线提供服务,两台主之间做互备 2、另外的从可做读的负载均衡,然后将其中一台抽出专业做备份
面试题035:开发有一堆数据发给dba执行,DBA执行需注意什么?
1、需要注意语句是否有格式上的错误,执行会出错导致过程中断 2、还需要注意语句的执行时间是否过长,是否会对服务器负载产生压力影响实际生产
面试题036:如何调整生产线中MySQL数据库的字符集。
1、首先导出库的表结构 -d 只导出表结构,然后批量替换 2、导出库中的所有数据(在不产生新数据的前提下) 3、然后全局替换set names = xxxxx 4、删除原有库与表,并新创建出来,再导入建库与建表语句与所有数据
面试题037:请描述MySQL里中文数据乱码原理,如何防止乱码?
服务器系统、数据库、客户端三方字符集不一致导致,需要统一字符
面试题038:企业生产MySQL如何优化(请多角度描述)?
1、提升服务器硬件资源与网络带宽 2、优化mysql服务配置文件 3、开启慢查询日志然后分析问题所在
面试题039:MySQL高可用方案有哪些,各自特点,企业如何选择?
高可用方案有
1、主从架构 2、MySQL+MMM 3、MySQL+MHA 4、mysql+haproxy+drbd 5、mysql+proxy+amoeba
面试题040:如何批量更改数据库表的引擎?
通过mysqldump命令备份出一个sql文件,再使用sed命令替换 或者执行下面的脚本进行修改 #!/bin/sh user=root passwd=123456 cmd="mysql -u$user -p$passwd " dump="mysqldump -u$user -p$passwd" for database in `$cmd -e "show databases;"|sed '1,2d'|egrep -v "mysql|performance_schema"` do for tables in `dump -e "show tables from $databses;"|sed '1d'` do $cmd "alter table $database.$tables engine = MyISAm;" done done
面试题041:如何批量更改数据库字符集?
通过mysqldump命令备份出一个sql文件,再使用sed命令替换sed -i 's/GBK/UTF8/g'
面试题042:网站打开慢,请给出排查方法,如是数据库慢导致,如何排查并解决,请分析并举例?
1、可以使用top free 等命令分析系统性能等方面的问题 2、如是因为数据库的原因造成的,就需要查看慢查询日志去查找并分析问题所在
MySQL 5.1 中,在复制方面的改进就是引进了新的复制技术:基于行的复制。
MYSQL复制的几种模式
MySQL 5.1 中,在复制方面的改进就是引进了新的复制技术:基于行的复制。
简言之,这种新技术就是关注表中发生变化的记录,而非以前的照抄 binlog 模式。
从 MySQL 5.1.12 开始,可以用以下三种模式来实现:
-- 基于SQL语句的复制(statement-based replication, SBR),
-- 基于行的复制(row-based replication, RBR),
-- 混合模式复制(mixed-based replication, MBR)。
相应地,binlog的格式也有三种:STATEMENT,ROW,MIXED。 MBR 模式中,SBR 模式是默认的。
在运行时可以动态低改变binlog的格式,除了以下几种情况:
. 存储过程或者触发器中间
. 启用了NDB
. 当前会话试用 RBR 模式,并且已打开了临时表
如果binlog采用了 MIXED 模式,那么在以下几种情况下会自动将binlog的模式由 SBR 模式改成 RBR 模式。
. 当DML语句更新一个NDB表时
. 当函数中包含 UUID() 时
. 2个及以上包含 AUTO_INCREMENT 字段的表被更新时
. 行任何 INSERT DELAYED 语句时
. 用 UDF 时
. 视图中必须要求使用 RBR 时,例如创建视图是使用了 UUID() 函数
设定主从复制模式的方法非常简单,只要在以前设定复制配置的基础上,再加一个参数:
binlog_format="STATEMENT"
#binlog_format="ROW"
#binlog_format="MIXED"
当然了,也可以在运行时动态修改binlog的格式。例如
mysql> SET SESSION binlog_format = 'STATEMENT';
mysql> SET SESSION binlog_format = 'ROW';
mysql> SET SESSION binlog_format = 'MIXED';
mysql> SET GLOBAL binlog_format = 'STATEMENT';
mysql> SET GLOBAL binlog_format = 'ROW';
mysql> SET GLOBAL binlog_format = 'MIXED';
两种模式各自的优缺点:
SBR 的优点:
历史悠久,技术成熟
binlog文件较小
binlog中包含了所有数据库更改信息,可以据此来审核数据库的安全等情况
binlog可以用于实时的还原,而不仅仅用于复制
主从版本可以不一样,从服务器版本可以比主服务器版本高
SBR 的缺点:
不是所有的UPDATE语句都能被复制,尤其是包含不确定操作的时候。
调用具有不确定因素的 UDF 时复制也可能出问题
使用以下函数的语句也无法被复制:
* LOAD_FILE()
* UUID()
* USER()
* FOUND_ROWS()
* SYSDATE() (除非启动时启用了 --sysdate-is-now 选项)
INSERT ... SELECT 会产生比 RBR 更多的行级锁
复制需要进行全表扫描(WHERE 语句中没有使用到索引)的 UPDATE 时,需要比 RBR 请求更多的行级锁
对于有 AUTO_INCREMENT 字段的 InnoDB表而言,INSERT 语句会阻塞其他 INSERT 语句
对于一些复杂的语句,在从服务器上的耗资源情况会更严重,而 RBR 模式下,只会对那个发生变化的记录产生影响
存储函数(不是存储过程)在被调用的同时也会执行一次 NOW() 函数,这个可以说是坏事也可能是好事
确定了的 UDF 也需要在从服务器上执行
数据表必须几乎和主服务器保持一致才行,否则可能会导致复制出错
执行复杂语句如果出错的话,会消耗更多资源
RBR 的优点:
任何情况都可以被复制,这对复制来说是最安全可靠的
和其他大多数数据库系统的复制技术一样
多数情况下,从服务器上的表如果有主键的话,复制就会快了很多
复制以下几种语句时的行锁更少:
* INSERT ... SELECT
* 包含 AUTO_INCREMENT 字段的 INSERT
* 没有附带条件或者并没有修改很多记录的 UPDATE 或 DELETE 语句
执行 INSERT,UPDATE,DELETE 语句时锁更少
从服务器上采用多线程来执行复制成为可能
RBR 的缺点:
binlog 大了很多
复杂的回滚时 binlog 中会包含大量的数据
主服务器上执行 UPDATE 语句时,所有发生变化的记录都会写到 binlog 中,而 SBR 只会写一次,这会导致频繁发生 binlog 的并发写问题
UDF 产生的大 BLOB 值会导致复制变慢
无法从 binlog 中看到都复制了写什么语句(加密过的)
当在非事务表上执行一段堆积的SQL语句时,最好采用 SBR 模式,否则很容易导致主从服务器的数据不一致情况发生
另外,针对系统库 mysql 里面的表发生变化时的处理规则如下:
如果是采用 INSERT,UPDATE,DELETE 直接操作表的情况,则日志格式根据 binlog_format 的设定而记录
如果是采用 GRANT,REVOKE,SET PASSWORD 等管理语句来做的话,那么无论如何都采用 SBR 模式记录
注:采用 RBR 模式后,能解决很多原先出现的主键重复问题。
