
微软自然语言理解平台LUIS:从零开始,帮你开发智能音箱
今年微软开发者大会Build 2017上展示了一款Invoke智能音箱,受到了媒体和大众的广泛关注。近两年,不少大公司纷纷涉足该领域,使得智能音箱逐渐成为一款热门的人工智能家用电器。智能音箱的兴起也改变了人们和家用电器之间的“沟通方式”:从动手到动嘴。“播放一些周杰伦的歌”,“明天北京的天气怎么样”… 对着智能音箱说出自己想让它做的事情,这些之前在科幻电影里才会出现的桥段逐渐变成了现实。那么,智能音箱是如何听懂人类指令的呢?
智能音箱听懂人类指令的过程,其实就是语义理解的过程,可以被分解成为两个子任务:意图识别(intention classification)和实体抽取(entity extraction)。意图识别的目标是甄别用户的对话意图,也就是用户希望完成一件什么工作?而实体抽取的目标则是理解用户对话中所提供的和具体工作相关的参数(实体),例如时间、地点等。比如:“播放一些周杰伦的歌”所对应的意图是“播放音乐”,其中包含一个艺人实体,实体的值是“周杰伦“。然后根据语义理解的结果,智能音箱就可以做出正确的操作来满足用户的需求。

智能音箱的智能程度取决于其能够理解的意图以及实体的数量和复杂度,因此如何高效地开发语义理解模块成为这场智能音箱竞赛中的最关键一环。然而,开发语义理解模块需要自然语言处理(NLP)的专业知识和经验,而这些知识和经验又需要长年累月的积累,所以可以胜任的开发者凤毛麟角,广大非NLP专业的开发者则有心无力。那么如何帮助非NLP专业的开发者解决自然语言理解这一开发瓶颈呢?
微软语言理解智能服务 - LUIS
LUIS (Language Understanding Intelligent Service,https://www.luis.ai) 是微软发布的面向开发者的自然语言语义理解模块开发服务。微软亚洲研究院大数据挖掘组负责研发了LUIS的新一代算法。LUIS的使命是让非NLP专业的开发者能够轻松地创建和维护高质量的自然语言理解模型,并无缝对接到相关的智能应用当中。
通过LUIS平台,非NLP专业的开发者可以轻松创建一个LUIS App,并通过标注所期望的输入(自然语言指令)和输出(意图和实体)来进一步“培养” 它。在整个开发过程中,开发者并不需要了解背后算法的细节,只需要清晰地定义自己需要让机器理解的用户意图和实体即可。下面我们就来介绍一下LUIS的开发流程和其背后的技术细节。
LUIS的开发流程
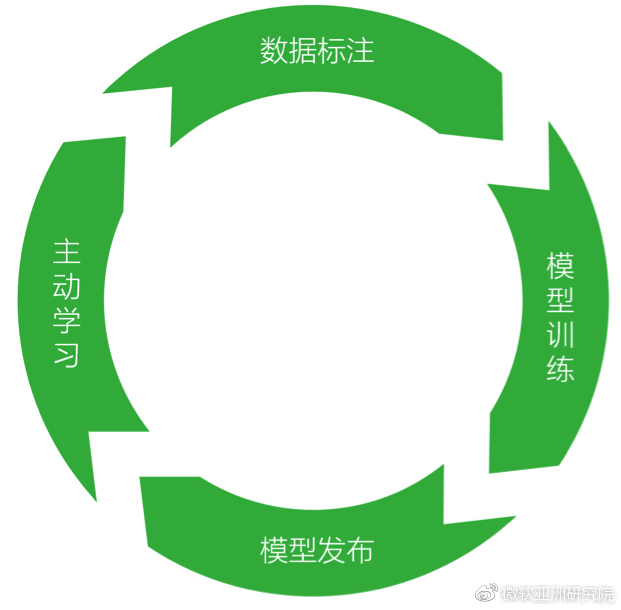
LUIS的开发流程更像是一个教学过程:开发者是老师,LUIS App是学生。老师通过不停地告知学生正确的语义解析结果来完成教学。一个好的教学过程是一个“训练+实践”的闭环:标注一定量的起始数据;训练得到语义理解模型;对模型进行必要的测试;发布模型并应用到真实用户场景;甄选应用日志中的语句;继续标注并更新模型。这个过程周而复始,通过不停地迭代开发,不停地改善理解模型,使其越来越接近人类的理解能力。
数据标注
LUIS开发者可以在界面上轻松地进行在线数据标注。首先,在对应的用户意图中输入自然语言指令,例如:在“播放音乐” 中输入一句“播放一些周杰伦的歌” ;然后,通过鼠标选取实体并指定类型,例如:选择“周杰伦”,指定其为艺人实体。LUIS支持标注数据的导入和导出,因此如果开发者已经有标注过的数据,那么就可以直接转换为LUIS的标注数据JSON格式进行导入。

模型训练
LUIS的模型训练过程极其简单,开发者只需点击一下 “训练” 按钮,LUIS便会提供一套全自动的机器学习解决方案:应用深度学习算法,预设绝大部分常用的文本特征,并加入从大数据语料中提取出的语义特征,从而为不同的语义理解场景提供通用的机器学习解决方案。训练的时间会因为标注数据量的不同而各异,标注数据越多,训练所需的时间越长。同时,训练时间还与LUIS App所支持的意图和实体个数相关,意图和实体越多,训练时间也越长。
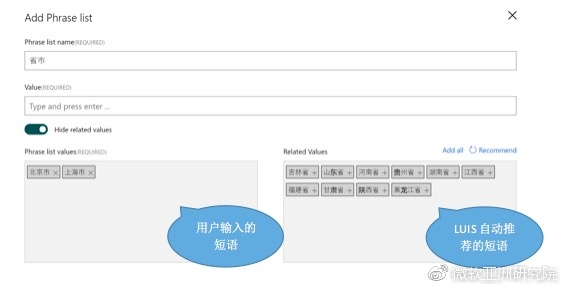
除了预设的特征之外,LUIS还允许用户自定义新的语义特征,包括短语列表特征(phrase list)和正则表达式特征(regular expression)。前者主要用于定义若干短语列表,且通常每一个列表中的短语均可相互替换,而后者主要用于定义若干正则表达式。通过应用这些用户自定义的短语列表特征和模式特征,再结合已有的标记数据,LUIS的深度学习模型就可以增强其自身的泛化能力,从而能够以更少的标记数据训练得到合适的模型,进而达到更好的预测效果。
在定义短语列表特征的过程中,LUIS通过其语义词典(semantic dictionary)挖掘技术,能够根据用户输入的若干短语,自动从海量的网络数据中智能地发现与其相似的短语,并推荐给用户,有效地提升了用户定义短语列表特征的效率。目前该推荐功能主要面向英文语言,我们也正在致力于将其推广到包括中文在内的其他语言。
模型发布
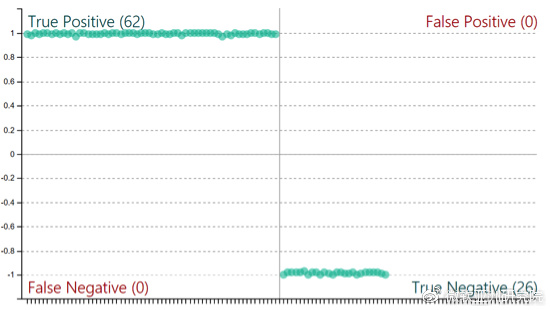
对于训练完成的模型,开发者可以对其进行性能测试。LUIS为开发者提供了两种在线测试方法:交互式测试和批量测试。使用交互式测试时,开发者可以直接输入自然语言语句,然后目测模型输出是否和预期一致。而使用批量测试时,开发者需要上传一份测试数据,LUIS会通过比对模型输出和测试数据的期望输出来给出更为具体的精度和召回率等统计数据,并且LUIS还会对每一项意图和实体的结果绘制出Confusion Matrix来帮助开发者找到有待提高的实例。通过测试的LUIS App只需轻轻一点就可以发布到微软的Azure云平台上,变成一个立即可用的API。开发者通过Http的get方法,就可以将开发的LUIS App接入到其他应用中。
主动学习
LUIS App的开发是一个不停迭代的过程,通过不停地增加标注数据来让其变得更加智能。同时,LUIS希望最大化开发者的标注收益,也就是说,通过更少的标注来获得更大的模型性能提升。发布之后的App会逐渐积累真实用户的请求日志,然后通过主动学习(Active Learning)从这些日志中寻找出对于模型更为有益的语句让开发者标注。实验表明,通过甄选数据的方式,模型的精度和召回率的提升都明显高于随机选择标注数据的方式,这让开发过程变得事半功倍。也正是通过主动学习,LUIS对于训练数据的数量要求大大降低,可以在较少的训练数据下获得不错的性能。
丰富的内建工具
为了帮助用户快速构建其应用,LUIS提供了一系列的内建工具,包括内建应用场景(prebuilt domain)和内建实体(prebuilt entities)。
内建应用场景包括日历(calendar)、天气(weather)等多个较为通用的类别,每一个内建场景均包含了预定义好的意图和实体,用户可直接添加合适的内建场景到其应用中,并进行修改和扩展。
内建实体目前主要包括日期与时间(date time)、基数词(number)、序数词(ordinal)、百分数(percentage)、年龄(age)、温度(temperature)等多种应用较为广泛的类别,用户可以通过勾选添加所需的内建实体到其应用中,无需从头开始自行创建。事实上,大部分LUIS内建实体同时具有识别和解析的功能,能够从输入的语句中抽取出相应的实体内容,并将其解析为标准格式,例如,基数词可以将识别出的3k解析为3000的标准数字形式,便于用户后续的处理。

微软自然语言理解平台LUIS让广大非NLP专业的开发者也可以加入到语义理解模型的开发队伍中来,从而真正让各种应用都实现智能化,创造出更多的用户价值。我们也将不懈努力,将LUIS做的更加易用和高效,让它成为开发者的一款利器。
你也来试试看?官方网站:https://www.luis.ai/

