

url的三个js编码函数escape(),encodeURI(),encodeURIComponent()简介【转】
引子
浏览器URl地址,上网一定会用到,但是浏览器地址有中文或者浏览器url参数操作的时候,经常会用到encodeURIComponent()和decodeURIComponent()以及encodeURI()等等。关于浏览器参数操作,请看文章http://www.haorooms.com/post/js_url_canshu ,今天主要讲讲escape(),encodeURI(),encodeURIComponent()这几个函数的用法和区别。
为啥会有浏览器编码这一说法
一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。比如,世界上有英文字母的网址 “h ttp://www.haorooms.com”, 但是没有希腊字母的网址“h ttp://www.aβγ.com” (读作阿尔法-贝塔-伽玛.com)。这是因为网络标准RFC 1738做了硬性规定:
原文:"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."翻译:“只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*'(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。”
这意味着,如果URL中有汉字,就必须编码后使用。但是麻烦的是,RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。这导致“URL编码”成为了一个混乱的领域。
下面我们通过介绍escape(),encodeURI(),encodeURIComponent()来说说Javascript浏览器编码方法。
出现浏览器编码的几种情况
1、网址路径中包含汉字
如下图:

h ttp://www.haorooms.com/您好, 在浏览器中显示的是 h ttp://www.haorooms.com/%E6%82%A8%E5%A5%BD 自动对“你好”进行了编码。要是我们浏览器地址中有中文的时候,就要用到url编码了。
2、查询字符串包含汉字
http://www.haorooms.com/search?keywords=您好这样包含查询的的条件的时候,汉字也会被编码。
3、Get方法生成的URL包含汉字
前面说的是直接输入网址的情况,但是更常见的情况是,在已打开的网页上,直接用Get或Post方法发出HTTP请求。
根据台湾中兴大学吕瑞麟老师的试验,这时的编码方法由网页的编码决定,也就是由HTML源码中字符集的设定决定。
<meta http-equiv="Content-Type" content="text/html;charset=xxxx">如果上面这一行最后的charset是UTF-8,则URL就以UTF-8编码;如果是GB2312,URL就以GB2312编码。
举例来说,百度是GB2312编码,Google是UTF-8编码。因此,从它们的搜索框中搜索同一个词“春节”,生成的查询字符串是不一样的。
百度生成的是%B4%BA%BD%DA,这是GB2312编码。Google生成的是%E6%98%A5%E8%8A%82,这是UTF-8编码。所以,结论3就是,GET和POST方法的编码,用的是网页的编码。
4、Ajax调用的URL包含汉字
前面三种情况都是由浏览器发出HTTP请求,最后一种情况则是由Javascript生成HTTP请求,也就是Ajax调用。还是根据吕瑞麟老师的文章,在这种情况下,IE和Firefox的处理方式完全不一样。
举例来说,有这样两行代码:
url = url + "?q=" +document.myform.elements[0].value; // 假定用户在表单中提交的值是“春节”这两个字
http_request.open('GET', url, true);那么,无论网页使用什么字符集,IE传送给服务器的总是“q=%B4%BA%BD%DA”,而Firefox传送给服务器的总是“q=%E6%98%A5%E8%8A%82”。也就是说,在Ajax调用中,IE总是采用GB2312编码(操作系统的默认编码),而Firefox总是采用utf-8编码。
浏览器编码的函数简介escape(),encodeURI(),encodeURIComponent()
1、escape()
escape()是js编码函数中最古老的一个。虽然这个函数现在已经不提倡使用了,但是由于历史原因,很多地方还在使用它,所以有必要先从它讲起。
实际上,escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如“春节”的返回结果是%u6625%u8282,也就是说在Unicode字符集中,“春”是第6625个(十六进制)字符,“节”是第8282个(十六进制)字符。
例如:
javascript:escape("春节");
//输出 "%u6625%u8282"
javascript:escape("hello word");
//输出 "hello%20word"还有两个地方需要注意。
首先,无论网页的原始编码是什么,一旦被Javascript编码,就都变为unicode字符。也就是说,Javascipt函数的输入和输出,默认都是Unicode字符。这一点对下面两个函数也适用。
javascript:escape("\u6625\u8282");
//输出 "%u6625%u8282"
javascript:unescape("%u6625%u8282");
//输出 "春节"
javascript:unescape("\u6625\u8282");
//输出 "春节"其次,escape()不对“+”编码。但是我们知道,网页在提交表单的时候,如果有空格,则会被转化为+字符。服务器处理数据的时候,会把+号处理成空格。所以,使用的时候要小心。
2、encodeURI()
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号“; / ? : @ & = + $ , #”,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。

它对应的解码函数是decodeURI()。

需要注意的是,它不对单引号'编码。
3、encodeURIComponent()
最后一个Javascript编码函数是encodeURIComponent()。与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。
因此,“; / ? : @ & = + $ , #”,这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码。至于具体的编码方法,两者是一样。
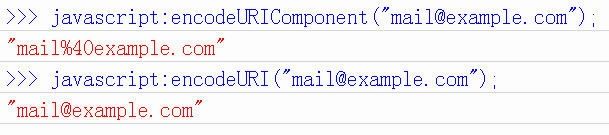
它对应的解码函数是decodeURIComponent()。
encodeURIComponent()相比encodeURI()要更加彻底。
例如:
<html>
<body>
<script type="text/javascript">
var test1="http://www.haorooms.com/My first/";
var nn=encodeURI(test1);
var now=decodeURI(test1);
var test1="http://www.haorooms.com/My first/";
var bb=encodeURIComponent(test1);
var nnow=decodeURIComponent(bb);
</script>
</body>
</html>输出结果是:
http://www.haorooms.com/My%20first/
http://www.haorooms.com/My first/
http%3A%2F%2Fwww.haorooms.com%2FMy%20first%2F
http://www.haorooms.com/My first/总结
escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如"春节"的返回结果是%u6625%u8282,,escape()不对"+"编码 主要用于汉字编码,现在已经不提倡使用。
encodeURI()是Javascript中真正用来对URL编码的函数。 编码整个url地址,但对特殊含义的符号"; / ? : @ & = + $ , #",也不进行编码。对应的解码函数是:decodeURI()。
encodeURIComponent() 能编码"; / ? : @ & = + $ , #"这些特殊字符。对应的解码函数是decodeURIComponent()。
假如要传递带&符号的网址,所以用encodeURIComponent()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架