解读TaurusDB二级分区,如何提高查询性能和管理效率
摘要:TaurusDB全面兼容MySQL分区表的语法和功能,支持更加丰富的分区方式和组合策略。
本文分享自华为云社区《【华为云MySQL技术专栏】TaurusDB二级分区,提升企业数据库管理效能》,作者:GaussDB 数据库。

1.背景介绍
随着业务的扩展,表的数据量也会相应增加。当表数据量达到一定规模时,数据库查询性能会成为系统瓶颈。
为了解决这一问题,社区MySQL提出了分区表的概念。分区表通过一个或者多个分区键,按照分区规则,将一个逻辑上的表分割成多个小的物理表。在查询时,MySQL能够根据查询条件,选择对应的一个或者几个分区进行扫描,从而提高查询性能和管理效率。
当前,社区MySQL支持一级和二级分区,其中一级分区类型包括RANGE(基于范围)、LIST(基于枚举)、HASH(基于用户定义的散列函数)、KEY(基于MySQL提供的散列函数);二级分区为组合分区,包括RANGE-HASH、RANGE-KEY、LIST-HASH、LIST-KEY。
但是,不容忽视的是,当一级分区基于RANGE或LIST类型时,二级分区仅能选择HASH或KEY类型,这限制了其在复杂场景下的应用。
为突破这一限制,TaurusDB对二级分区功能进行了显著增强,引入了更多样化的分区选项,显著提升了数据库管理的灵活性,更好地满足了复杂业务场景的需求。
2. TaurusDB分区表功能介绍
分区表作为数据库优化策略之一,其每个被物理分割出来的子分区,都独立存储着表中的一部分数据。除存储层面,在备份、索引等方面,均可独立进行数据操作。
当需要查询某条数据时,只需要知道该条数据位于哪个分区,然后直接在该分区上进行查询即可。对数据量特别大的表,采用分区技术可以大大减少查找的工作量,提高查询效率。
2.1 MySQL分区表原理介绍
| 一级分区
社区MySQL的一级分区,以电商系统中的订单表为例,如图1所示,其中city_name列为订单的地域信息。
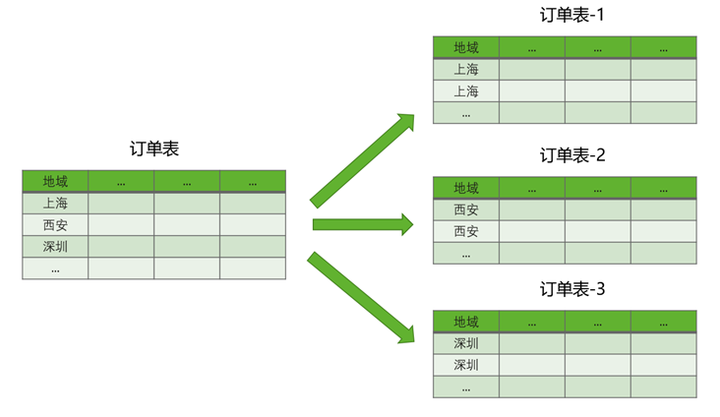
图1 电商系统中的订单表的一级分区示意图
我们可以使用地域信息作为分区键,对订单表进行LIST分区,表定义如下所示:
mysql> CREATE TABLE `orders` ( id INT AUTO_INCREMENT, city_name VARCHAR(50), PRIMARY KEY (id, city_name) ) PARTITION BY LIST COLUMNS(city_name) ( PARTITION pShanghai VALUES IN ('上海'), PARTITION pXian VALUES IN ('西安'), PARTITION pShenzhen VALUES IN ('深圳') );
当需要查询上海地域的某些订单信息,可以根据分区键快速识别到订单表-1,只需对订单表-1进行扫描筛选,便可获取相应的数据。
mysql> EXPLAIN SELECT * FROM `orders` WHERE city_name= '上海'; +----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ |1| SIMPLE | orders | pShanghai | index | PRIMARY | PRIMARY | 206 | NULL | 1 |100.00| Using where; Using index | +----+-------------+-----------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 二级分区
社区MySQL的二级分区是在一级分区的基础上,即对已经分区的表进一步细分,这样可以更加灵活地管理数据,提高查询性能。
使用方法示例:
以LIST-HASH分区方式为例,创建一张orders表,以purchase_time的年份信息为一级分区键,以purchase_time的月份信息为二级分区键。
mysql> create table `orders` ( order_id bigint NOT NULL COMMENT '订单编号', city_name varchar(20) NOT NULL COMMENT '所属城市', purchase_time date NOT NULL COMMENT '下单时间' ) partition by list (year(purchase_time)) subpartition by hash (month(purchase_time)) subpartitions 12 ( partition p_2022 values in (2022), partition p_2023 values in (2023), partition p_2024 values in (2024) );
以下是社区MySQL中RANGE、LIST、HASH、KEY四种分区的划分方式及适用场景。
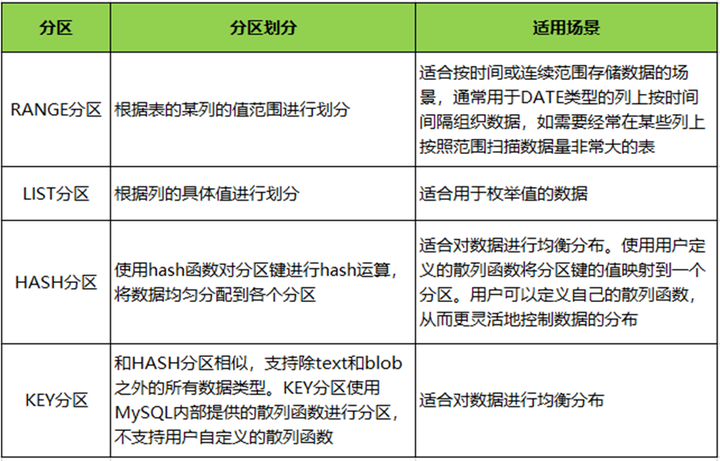
表1 社区MySQL四种分区的划分方式及适用场景
基于一级分区,社区MySQL的二级分区仅支持RANGE-HASH、RANGE-KEY、LIST-HASH、LIST-KEY这四种类型。除了支持的分区组合类型简单之外,在分区划分方式上也不够灵活。如LIST分区,如果数据不在枚举值范围内,将无法插入到表中,这在处理复杂数据分布时,会构成了明显的限制。
2.2 TaurusDB二级分区增强
TaurusDB分区表完全兼容社区MySQL的语法和功能。同时,在功能上进行了功能增强,支持更加丰富的分区表类型及组合。具体而言,
(1)TaurusDB对LIST和RANGE分区表分别做了拓展,新增了LIST DEFAULT HASH和INTERVAL RANGE两种分区表。
(2)支持更丰富的二级分区组合:
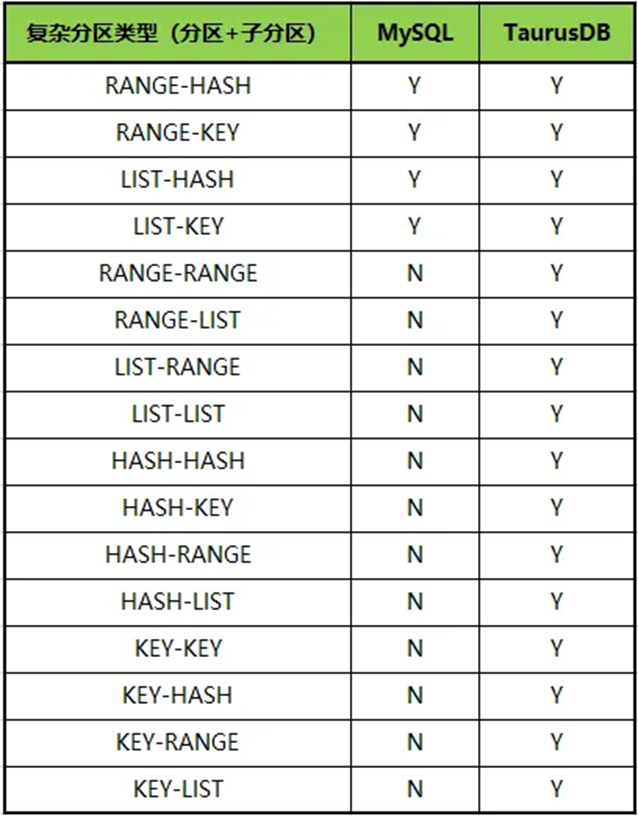
表2 MySQL和TaurusDB支持的分区组合方式
使用方法示例:
创建一张订单表orders,以城市city_name为一级分区列,下单的年份时间year(purchase_time)为二级分区列。
mysql> create table `orders` ( order_id bigint NOT NULL COMMENT '订单编号', city_name varchar(20) NOT NULL COMMENT '所属城市', purchase_time date NOT NULL COMMENT '下单时间' ) partition by list columns (city_name) subpartition by range (year(purchase_time)) ( partition p_shanghai values in ('上海') ( subpartition shanghai_2022 values less than (2023), subpartition shanghai_2023 values less than (2024), subpartition shanghai_2024 values less than (2025) ), partition p_shenzhen values in ('深圳') ( subpartition shenzhen_2022 values less than (2023), subpartition shenzhen_2023 values less than (2024), subpartition shenzhen_2024 values less than (2025) ), partition p_xian values in ('西安') ( subpartition xian_2022 values less than (2023), subpartition xian_2023 values less than (2024), subpartition xian_2024 values less than (2025)) );
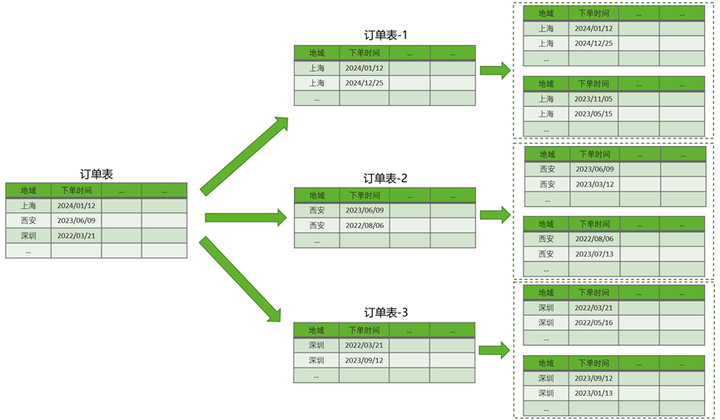
图2 电商系统中的订单表的二级分区示意图
创建的订单表orders根据地域信息进行一级分区之后,再根据下单的年份时间进一步细分,每张子分区小表存储着某个地域某年的订单数据。当需要频繁查询分析某个城市某个年份订单的统计信息时,二级分区表的分区剪枝技术,可以根据分区键的值计算出数据存放的子分区,大大提高查询效率。
下面主要针对LIST DEFAULT HASH和INTERVAL RANGE分区表做详细的介绍。
2.3 LIST DEFAULT HASH分区表
LIST DEFAULT HASH是在同一层级上支持两种分区类型:LIST和HASH。首先将数据根据LIST规则进行分区,所有符合特定LIST分区条件的数据将被分配到相应的LIST分区中。对于不符合LIST分区规则的数据,将会被放在DEFAULT分区里,DEFAULT分区如果有多个分区则根据HASH规则计算。
使用方法示例:
创建一张名为orders的表,以city_name为分区键,将相同地域的城市订单信息存放在同一个分区中。如果city_name不在LIST分区枚举的范围里,则统一划分到DEFAULT分区中。
mysql> CREATE TABLE `orders` ( city_name CHAR(50), order_time INT ) PARTITION BY LIST COLUMNS (city_name) ( PARTITION p_jiangsu VALUES IN ('无锡','苏州','南京'), PARTITION p_shanxi VALUES IN ('西安','宝鸡','榆林'), PARTITION p_guangdong VALUES IN ('深圳','珠海','东莞'), PARTITION p_others DEFAULT PARTITIONS 3 );
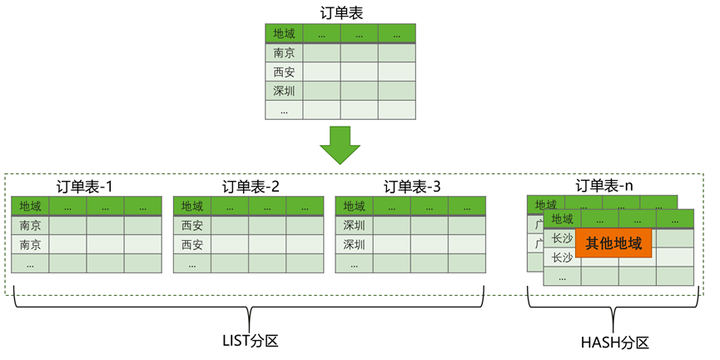
图3 LIST DEFAULT HASH分区示意图
适用场景:
这种分区方式适用于想依据LIST规则进行分区,但是分区键字段又无法全部枚举,或者枚举值非常多,而对应的数据量又很少的场景。尤其是当数据分布符合二八定则,即20%的分区键值包含了80%的数据量,而剩余80%的分区键包含了20%的数据量时,推荐使用LIST DEFAULT HASH分区方式。
具体而言,就是将80%的数据将按照LIST规则进行分区,把不符合LIST规则的数据放到默认的DEFAULT分区中,再按照HASH规则进行分区。
示例说明:
以订单系统为例,经常需要根据下单城市进行数据分析,可以使用LIST分区方式,以城市信息作为分区键对数据进行划分。但是,将所有城市都枚举出来过于繁琐,且可能存在大城市订单远高于小城市订单数量的情况。因此,这种情况就可以使用LIST DEFAULT HASH的分区方式,将大城市订单分别放在独立分区中,其他小城市统一存放在DEFAULT分区中。
2.4 INTERVAL RANGE分区表
INTERVAL RANGE分区表是RANGE分区表功能的拓展。对于RANGE分区表,当插入数据时,如果插入的数据超出当前已存在分区的范围,将无法插入,并且会返回错误。而对于INTERVAL RANGE分区表,当新插入的数据超过现有分区的范围时,允许数据库根据INTERVAL子句提前指定的规则来添加新分区。
使用方法示例:
创建一张sales表,以order_time作为分区键,按间隔划分sales表。
mysql> CREATE TABLE `sales` ( id BIGINT, uid BIGINT, order_time DATETIME ) PARTITION BY RANGE COLUMNS(order_time) INTERVAL(MONTH, 1) ( PARTITION p0 VALUES LESS THAN('2021-10-1'), PARTITION P1 VALUES LESS THAN('2021-11-1') );
向INTERVAL RANGE分区表中插入数据:
INSERT INTO sales VALUES(1, 1010101010, '2021-12-25');
当插入的数据超过已存在的分区范围时,TaurusDB会自动新增分区,并将新数据插入到正确的分区中。该示例中,分区表会自动新增两个分区分别保存11月份和12月份的订单。
mysql> CREATE TABLE `sales` ( id BIGINT, uid BIGINT, order_time DATETIME ) PARTITION BY RANGE COLUMNS(order_time) INTERVAL(MONTH, 1) ( PARTITION p0 VALUES LESS THAN('2021-10-1'), PARTITION P1 VALUES LESS THAN('2021-11-1'), PARTITION _p20211201000000 VALUES LESS THAN ('2021-12-01 00:00:00'), PARTITION _p20220101000000 VALUES LESS THAN ('2022-01-01 00:00:00') );
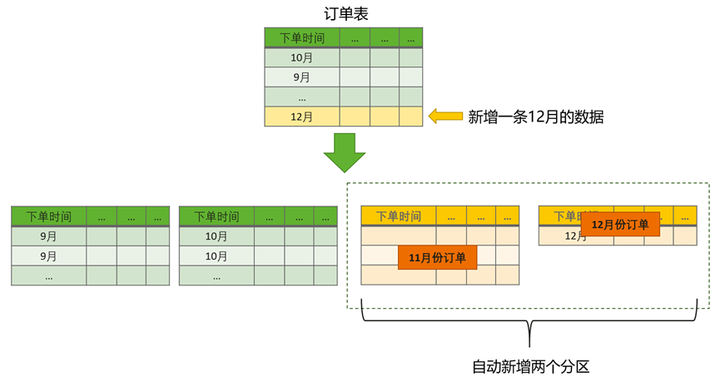
图4 INTERVAL RANGE分区示意图
适用场景:
INTERVAL RANGE分区方式适用于那些按时间维度维护,需要定期手动增加分区来插入新数据的场景。
示例说明:
在订单系统中,以订单时间为分区键,需要通过每天新增一个分区来保存当天的订单。采用INTERVAL RANGE分区方式,当插入一条订单信息时,如果该订单时间不属于任何一个当前已有的分区范围,系统会自动增加一个新分区来保存该数据,从而避免数据不能及时插入的情况发生,减轻DBA的日常维护负担。
3. 应用场景
日志系统
在大型应用中,日志数据的规模是非常庞大的。可以根据时间范围进行分区,将近期被频繁访问的日志数据存放在一个或者多个分区中,来提高查询性能。对于过期需要被清除的日志,也可以通过直接删除分区来实现数据的快速灵活管理,而不影响整张表。
邮件系统
在邮件系统中,用户经常访问和修改的数据是近期的邮件。可以根据时间范围对表进行分区,将旧数据归档到某几个分区中,将常用的数据和不常访问的数据分隔开来。
电商平台
随着业务的发展,电商平台的订单数据量也会不断增加,这会导致查询性能逐渐下降。可以通过对时间范围进行分区,比如每一个月为一个分区,这样方便查询特定时间段内的订单数据或者统计每月的销售情况。此外,也可以通过地域信息进行分区,根据不同地区的业务需求进行针对性的管理和优化。
同时,还可以使用HASH分区,对订单ID进行HASH运算,将数据均匀地分配到不同的分区中,方便提高并发查询的性能,避免某个分区数据过多而导致性能瓶颈。
4. 总结
社区MySQL分区表为提升大型数据表的查询性能提供了一种有效途径,具有提升查询效率、简化数据管理、增强并发性能、灵活数据管理的优势。而TaurusDB全面兼容MySQL分区表的语法和功能,支持更加丰富的分区方式和组合策略。TaurusDB具体创新点如下:
1)更加灵活的分区划分:针对RANGE分区,TaurusDB拓展了INTERVAL RANGE分区,允许分区表根据提前指定的规则自动添加分区。针对LIST分区拓展了LIST DEFAULT分区,数据在枚举值之外也可顺利添加到分区表中。
2) 更加丰富的分区组合方式:TaurusDB提供了多达16种分区组合方式,帮助用户应对复杂场景的提供选择。
总之,TaurusDB新增的更为丰富二级分区,为数据管理提供了更加灵活和高效的解决方案,不仅提升了系统性能,还优化了数据管理流程,充分满足了现代企业对数据管理的高要求和多样化需求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号