
如何基于Sharding-JDBC实现GaussDB在客户端应用的读写分离
摘要:使用sharing-jdbc中间件实现GaussDB读写分离操作,在服务器资源吃紧与高并发场景下可以考虑采用读写分离架构减轻负载。
本文分享自华为云社区《GaussDB读写分离最佳实践》,作者: HuaweiCloudDeveloper。
1 问题现象
在通常的TP业务中,大多数数据使用都是select查询操作,而修改数据的操作(update, insert, delete)仅占很少的一部分。如果读,写数据操作都放在主库上执行,在服务器资源紧张与业务流量上升的情况下,有可能引发主节点性能瓶颈。所以需要对大量的读数据(select查询)操作进行分流,数据库读写分离技术应运而生。
GaussDB读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
2 技术背景
在电商项目中,在使用数据库时有些采用主从复制、读写分离的架构。对数据库的读和写都在同一个数据库服务器中,特定业务场景中不能满足实际需求。无论在安全性、高可用性还是高并发等各个方面都是不能满足实际需求的。因此,通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发能力。
3 处理过程
3.1 GaussDB JDBC读写分离参考配置方案
为实现读写分离,您需要结合第三方读写分离框架配置2个jdbc-url数据源,1个连接集群所有DN节点并设置targetServerType=master,一个连接只读备节点。这样可以实现写操作时,自动连接到主节点,需要只读操作时,自动连接到只读备节点。
读写主机的JDBC参考连接串:
jdbc:postgresql://{DN1_IP:PORT,DN2_IP:PORT,DN3_IP:PORT}/{db_name}?targetServerType=master& {param=value}
只读备机的JDBC参考连接串:
jdbc:postgresql://{DN1_IP:PORT,DN2_IP:PORT,DN3_IP:PORT}/{db_name}?targetServerType= slave& {param=value}
3.2 GaussDB集中式Sharding-JDBC读写分离实践
在数据库的高并发读写场景中,我们会采用读写分离技术。读写分离指的是利用数据库主从技术(把数据复制到多个节点中),分散读多个库以支持高并发的读,而写只在master库上。GaussDB的主从技术只负责对数据进行复制和同步,而读写分离技术需要业务应用自身去实现。
有些中间件可以帮助我们快速的实现该功能,本案例使用Sharding-JDBC来帮助我们快速的实现读写分离。 Sharding-JDBC会根据SQL语句中的操作类型(读或写)来决定将请求路由到哪个数据库服务器上。具体而言,如果请求是读请求,Sharding-JDBC会将其路由到只读数据库节点上;如果请求是写请求,Sharding-JDBC会将其路由到写数据库节点上。
在具体客户业务实现中,不同的读写分离中间件原理大同小异,案例都可参考。
备注:shardingshpere低版本JDBC连接串不支持多IP格式,已知不支持的有3.1,4.1,已知支持的有5.1;
4 处理结果
以下案例为springboot2.6.5+sharding-jdbc5.2.0+mybatis-plus3.5.9+GaussDB集中式505.2实现;
案例操作的表定义:
CREATE TABLE emp ( empno int , empname varchar(128) ); INSERT INTO emp VALUES (1, 'q1'); INSERT INTO emp VALUES (2, 'q2'); INSERT INTO emp VALUES (3, 'q3'); INSERT INTO emp VALUES (4, 'q4'); INSERT INTO emp VALUES (5, 'q5'); INSERT INTO emp VALUES (6, 'q6'); INSERT INTO emp VALUES (7, 'q7'); INSERT INTO emp VALUES (8, 'q8'); INSERT INTO emp VALUES (9, 'q9');
4.1 JDBC数据源配置
以下配置文件中sharding-jdbc不同版本读写分离配置可能有差异,重点关注主备数据源配置即可;
当前集中式集群中xxx.11为主节点,xxx.182,xxx.152为备节点
读写配置
jdbc-url: "jdbc:postgresql://xxx.11:30100,xxx.182:30100,xxx.152:30100/hr?targetServerType=master&{param=value}"
只读配置:
jdbc-url: "jdbc:postgresql://xxx.182:30100/hr?{param=value}" spring: shardingsphere: datasource: names: master,slave1,slave2 ## 数据源别名 master: type: com.zaxxer.hikari.HikariDataSource driver-class-name: org.postgresql.Driver jdbc-url:jdbc:postgresql://xxx.11:30100,xxx.182:30100,xxx.152:30100/hr?targetServerType=master&logger=Slf4JLogger" username: hr password: "xxx" slave1: type: com.zaxxer.hikari.HikariDataSource driver-class-name: org.postgresql.Driver jdbc-url: "jdbc:postgresql://xxx.182:30100/hr?logger=Slf4JLogger" username:hr password: "xxx" slave2: type: com.zaxxer.hikari.HikariDataSource driver-class-name: org.postgresql.Driver jdbc-url: "jdbc:postgresql://xxx.152:30100/hr?logger=Slf4JLogger" username: hr password: "xxx" rules: readwrite-splitting: data-sources: master-slave: props: auto-aware-data-source-name: master load-balancer-name: round_robin read-data-source-names: slave1,slave2 write-data-source-name: master props: sql-show: true shardingshpere <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId> <version>5.2.0</version> </dependency>
4.2 测试写入业务
执行一个只有写入的业务,在日志中可以看到该语句在xxx.11(主节点)这个读写节点上执行并成功插入,实现了写分离。
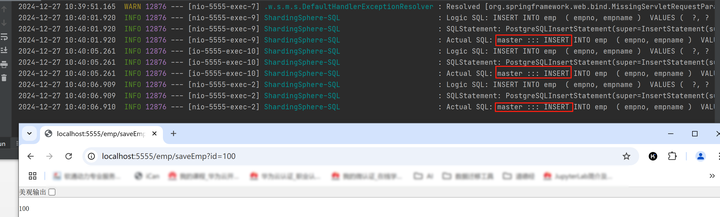
4.3 测试只读业务
执行一个只有查询的业务,在日志中可以看到该语句在xxx.182(备节点)这个只读节点上执行并成功查询,实现了读分离。
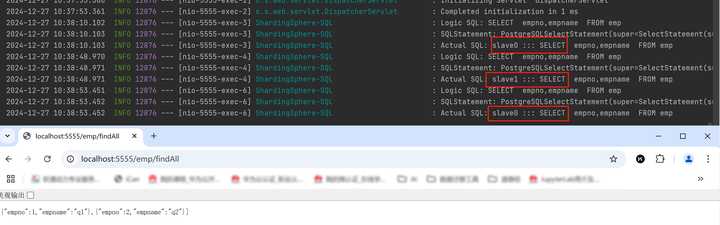
4.4 测试读写混合业务(无事务)
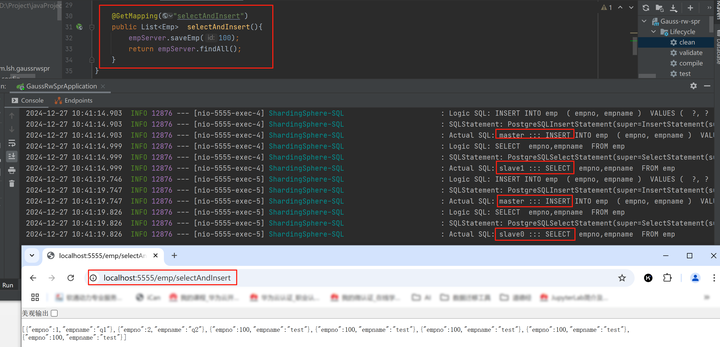
执行一个读写混合业务,但是没有事务控制,先插入数据再查询,在日志中可以看到插入数据在xxx.11(主节点)节点上执行,读取数据在xxx.182(slave0)或 xxx.152( slave1)上执行,实现了读写分离。
4.5 测试读写混合业务(有事务)
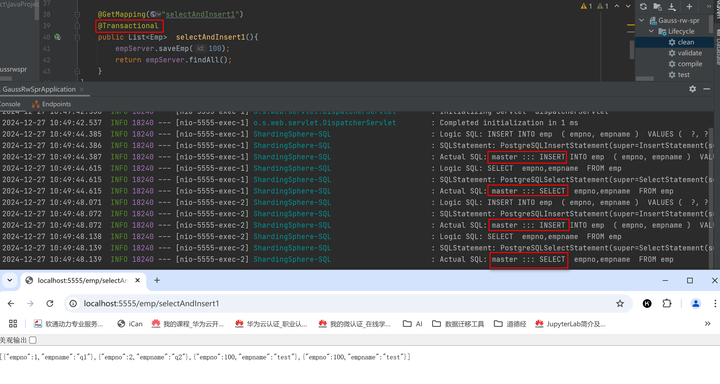
执行一个读写混合业务,但是整个业务有事务控制,先插入数据再查询,在日志中可以看到插入数据在xxx.11(主节点)节点上执行,读取数据在xxx.182(备节点)上执行,当一个事物中有读有写时,不进行读写分离。
4.6 测试总结
当业务中有只写操作时,自动读取主节点;
当业务中只有读操作时,自动读取只读备节点;
当业务中有读写操作但是没事务时,自动根据读写语句进行读写分离;
当一个事务中有读写操作并且有事务控制时,自动读取主节点;
5 简单总结
经过上面的简短实验,使用sharing-jdbc中间件实现GaussDB读写分离操作,在服务器资源吃紧与高并发场景下可以考虑采用读写分离架构减轻负载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号