
探索大模型和 Multi-Agent 在运维领域的实践
本文分享自华为云社区《LLM 和 Multi-Agent 在运维领域的实验探索》,作者:华为云确定性运维。
自 ChatGPT 问世以来,AI 迎来了奇点 iPhone 时刻,这一年来大模型深入影响企业办公、金融、广告及营销等很多领域,也给运维领域的挑战带来新的解题思路。我们洞察发现大模型给 AIOps 带来新机遇:已有云厂商利用大模型对运维事故进行根因定位并给出故障缓解措施建议,近 7 成以上运维人员对 LLM 的分析结果满意 (>3 分)。我们认为 AIOps 面临以下三大挑战:
挑战 1:针对运维领域海量知识快速获取、辅助诊断和故障分析能力:在大模型如火如荼的时代背景下,运维领域应用 LLM 来获取运维知识,针对故障进行分析和推荐修复方案已是势在必行,如何将 LLM 较为广泛的知识储备(横向能力)与运维领域的专业知识(运维垂域)相结合,对具体故障给出较为准确和可以用作参考和修复操作的指令,是本方案的第一重要能力实现。
挑战 2:针对多模态数据进行快速高效准确的异常检测能力:运维领域有丰富的多损益来源、多类型数据:指标数据(metric)、日志数据(log)以及调用链数据(trace)等多模态运维数据。指标能够反映业务状态和机器性能的时间序列数据;日志是一种程序打印或执行代码输出的非结构化文本;调用链则是在系统完成一次业务调用的过程中,把服务之间的调用信息连接成的一个树状链条。多模态运维数据可以反映系统状态的全方位信息,针对不同模态的数据,智能匹配最优算法得到较为准确的故障检测结果是本方案的第二重要能力实现。
挑战 3:针对多源复杂部署的运维数据进行快速根因定位能力:多模态运维数据一方面能够反映系统状态的全方位信息,另一方面也给故障定位带来很大的困难。针对 log、metric、trace 三方面来源的告警信息进行有效、快速、准确地分析,结合 trace 数据生成的实时拓扑结构图,排除故障传播节点,给出故障根因节点推荐,是本方案的重要能力实现之一。
在真实的运维工作中,IT 系统何时发生故障、发生什么类型的故障都是未知,只能根据以往运维经验和故障现象进行推断,所以针对这一困难,本方案利用 LLM 储备的相关运维知识进行 few-shot tuning 后能够给出初步的故障分类建议,起到辅助运维人员进行故障分析和根因定位的作用。
结合以上问题我们进行深度探索,并总结出一些方案,在此,分享给各位读者。
方案详述
本方案提出以 LLM 为中心结合多模态 Agent 协同的自主决策、自动修复的运维方案,整体架构如图 1 所示,我们重点强调三大关键技术:

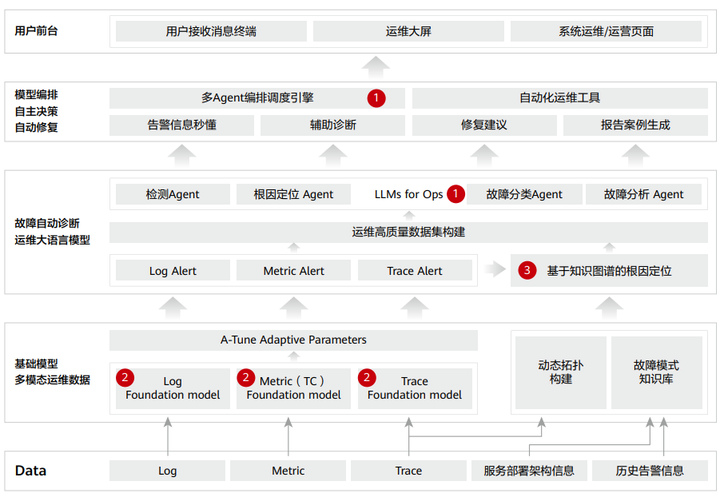
图 1:基于 LLM 和多模态 Agent 协同的自主决策、自动修复运维方案
关键技术 1:具备运维领域知识经验的 LLM
① 梳理异常检测告警信息和运维故障模式,形成运维领域高质量数据集,使用 finetuning+ 外挂企业运维知识库的方案,使得 LLM 具备运维领域故障分析定位能力。
② 使用主管 LLM 对异常问题与子领域 Agent 进行桥接,多个子领域 Agent 协同工作,提升运维效率。
关键技术 2:更全能的多模态数据异常检测基础模型
① 针对成百上千条不同采用频率的 metric 序列采取一定维度聚合的方法,化繁为简,一旦检测出异常,再细化分析关键指标的关键表现。
② 针对半结构化和非结构化日志采取针对性的解析方式:前者注重模板提取,后使用 uADR/sADR 进行异常检测,后者注重语义理解,使用 BigLog 预训练模型结合 Deep SVDD+SAD 进行异常检测。
③ 针对结构化明显的 trace 数据,抽取分离调用关系并定义节点关键数据,通过转化时间序列有效识别异常节点,并通过拓扑关系分析帮助推测可能根因节点及故障传播方向。
关键技术 3:基于知识图谱的根因定位
① 利用 DBSCAN 从时间维度聚类,形成异常事件。
② 利用 Trace 数据实时生成拓扑结构图。
③ 根据故障模式知识库分析故障传播链路。
针对 Log, Metric, Trace 三类运维数据我们分别构建了异常检测基础模型,一但系统接受到异常即会通知 LLM 主管 Agent,主管 Agent 对异常问题进行决策与子领域 Agent 进行桥接,多个子领域 Agent 协同工作,实现运维故障自动诊断和多个任务模型的编排,提升运维效率。

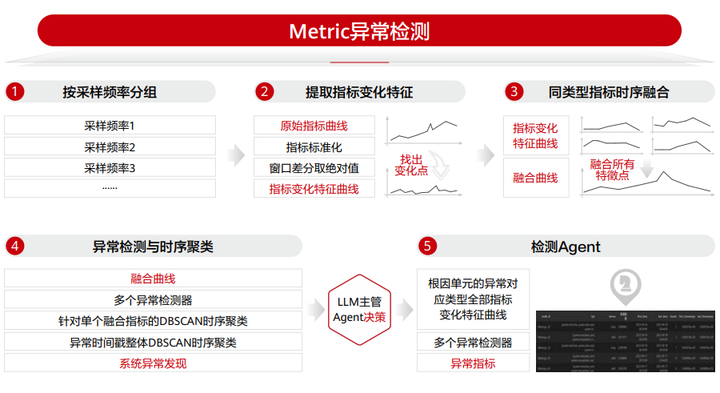
图 2 多模态异常检测 -Metric 基础模型
我们针对不同的数据源分别打造了三个基础模型,首先是 metric 异常检测,我们对不同对象不同采集频率的运维数据进行分组,然后根据指标变化曲线提取不同窗口的差分特征,第三步是将同类型的指标时序进行融合后利用多个异常检测器进行异常检测和时间聚类,一旦发现异常则通知 LLM 主管 Agent 进行决策,检测 Agent 收到详细检测的指令则进一步利用多个异常检测器进行细致的异常检测。

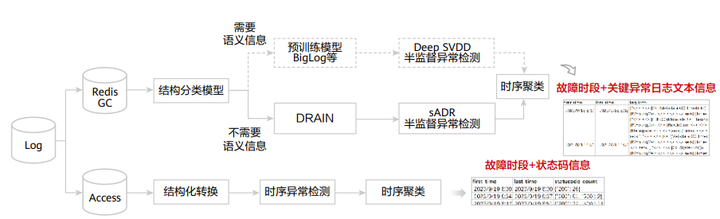
图 3 多模态异常检测 -Log 基础模型
其次是 Log 异常检测,今年的 Log 类型可以分为两大类: Redis GC 和 Access 日志,针对 Redis GC 日志首先使用结构分类模型检测是否需要语义信息,如果需要语义信息,那么则会使用运维领域的预训练语言模型,如 BigLog 等;之后是由 Deep SVDD 进行半监督异常检测,检测出不需要语义信息的部分则使用 DRAIN 进行模板提取后,使用 sADR 进行半监督异常检测;最终对时间进行聚类后输出故障发生的时段和关键异常日志文本信息, 针对 Access 日志我们使用结构化提取成时间序列后进行异常检测,对时间聚类后最终输出故障发生的时段和状态码信息。


图 4 多模态异常检测 -Trace 基础模型
针对 Trace 数据有两部分输出,一部分是根据 Trace 信息实时生成动态拓扑作为根因定位的输入,另一部分针对调用链节点之间的时长构成调用链时间序列进行异常检测。

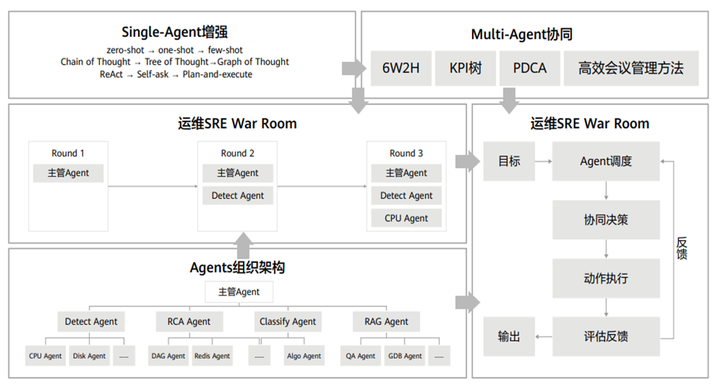
图 5 多 Agent 协同框架:基于企业组织管理方法的高效协同诊断
结合大模型的技术演进趋势,从 zero-shot->one-shot->few-shot,从 Chain of thought->Tree of thought->Graph of thought,从 Single-Agent 增强到 Multi-Agent 协同,Multi-Agent 在激发大模型能力的同时也带来了新的技术挑战,近期业界实践已发现,Multi-Agent 架构如果缺少合理的组织管理与协同沟通方法时,Multi-Agent 的效果可能会比 Single-Agent 更差,我们认为在通过大模型通往 AGI 的道路上,需要将 Agent 当作平等的人类非工具来看待,因此多 Agent 的组织管理与协同需要借鉴管理 “人” 的方法,我们希望在基于 Agents 组织架构上,探索一套基于企业组织管理方法的多 Agent 协同框架,例如通过 KPI 树方法分解任务,通过 PDCA 方法反馈循环提高 Agent 工作效率,通过企业高效会议管理方法来合理组织运维 War Room 的 Agent 进入和退出,实现多 Agent 的高效协同诊断。


图 6 多 Agent 协同故障诊断
这里我们用一张流程图详细阐述多 Agent 是如何协同工作的。系统发现 Weblogic16 和 17 发现异常,主管 Agent 收到异常通知后,从企业内源的知识库中获取到这两个节点是关键节点,组织检测 Agent、根因定位 Agent、故障分析 Agent 等开始工作。检测 Agent 此时根据故障知识树首先执行磁盘检测发现异常程度高,得到高优先级结论,不用进一步检查 CPU 指标,检测 Agent 会输出详细的针对这两个节点的所有异常指标、异常发生时间及异常程度等。根因 Agent 根据详细检测的结果分析出根因节点为 Weblogic 16,故障分类 Agent 根据根因节点信息及异常指标的描述异常程度判断为磁盘故障,故障分析 Agent 这时会给出针对此故障的详细分析报告,包含故障爆炸半径以及修复建议等。
方案创新性、通用性及实用性


最后,我们方案创新地提出基于企业组织管理方法的多 Agent 协同框架,让复杂运维任务处理更高效;使用多 Agent 协同完成运维主流程:异常检测 -> 根因定位 -> 故障分类 -> 故障分析 -> 修复建议;构建的多模态异常检测基础模型,包含 Trace、Metric、Log 数据处理能力,开箱即用;框架与算法不依赖具体特定应用场景,结合大模型实现较强的泛化能力;故障诊断报告体现可解释的故障爆炸半径,为实际生产运维故障快速恢复提供有力依据;各模块松耦合可插拔,可以全面应用于各类场景故障快速恢复需求,已在一些多场景落地实践。
【参考文献】
_1.Zhang S, Pan Z, Liu H, et al. Efficient and Robust Trace Anomaly Detection for Large-Scale Microservice Systems. ISSRE, 2023. _
_2.Li D, Zhang S, Sun Y, et al. An Empirical Analysis of Anomaly Detection Methods for Multivariate Time Series. ISSRE, 2023. _
_3.Wang Z, Liu Z, Zhang Y, et al. RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models. arXiv, 2023. _
_4.Jin P, Zhang S, Ma M, et al. Assess and Summarize: Improve Outage Understanding with Large Language Models. ESEC/FSE, 2023. _
_5.Chen Y, Xie H, Ma M, et al. Empowering Practical Root Cause Analysis by Large Language Models for Cloud Incidents. arXiv, 2023. _
_6.Zhou X, Li G, Sun Z, et al. D-Bot: Database Diagnosis System using Large Language Models. arXiv, 2023. _
_7.Zhou X, Li G, Liu Z. Llm as dba. arXiv, 2023. _
_8.Wen Q, Gao J, Song X, et al. RobustSTL: A robust seasonal-trend decomposition algorithm for long time series. AAAI, 2019. _
_9.Liu Y, Tao S, Meng W, et al. LogPrompt: Prompt Engineering Towards Zero-Shot and Interpretable Log Analysis. arXiv, 2023. _
_10.Tao S, Liu Y, Meng W, et al. Biglog: Unsupervised large-scale pre-training for a unified log representation. IWQoS, 2023. _
_11.Ma L, Yang W, Xu B, et al. KnowLog: Knowledge Enhanced Pre-trained Language Model for Log Understanding. ICSE, 2023. _
_12.Zhong Z, Fan Q, Zhang J, et al. A Survey of Time Series Anomaly Detection Methods in the AIOps Domain. arXiv, 2023. _
_13.Wu H, Hu T, Liu Y, et al. Timesnet: Temporal 2d-variation modeling for general time series analysis. ICLR, 2023. _
14.Yu G, Chen P, Li P, et al. Logreducer: Identify and reduce log hotspots in kernel on the fly. ICSE, 2023.


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
2023-09-19 3步体验在DAYU200开发板上完成OpenHarmony对接华为云IoT
2023-09-19 教你用API插件开发一个AI快速处理图片小助手
2023-09-19 聚焦企业开放OpenAPI痛难点,华为云API Explorer助力构建API门户
2022-09-19 跟我学Python图像处理丨关于图像金字塔的图像向下取样和向上取样
2022-09-19 新消费时代,零售业的进与退?
2022-09-19 带你掌握如何使用CANN 算子ST测试工具msopst
2022-09-19 2022 IDC中国未来企业大奖优秀奖颁布,华为云数据库助力德邦快递获奖