百万级超长序列大模型训练如何加速,硬核解读MindSpeed方案
摘要:针对现有长序列训练场景的痛点,MindSpeed在并行算法、计算效率、内存占用以及通信四个维度系统性优化大模型长序列训练效率,支持大模型百万级长序列训练。
1 长序列已经成为主流大模型能力之一
23年底Gemini1.5 Pro发布以来,大模型序列长度迅速增长,处理超长序列上下文(Context)已经成为了目前主流闭源和开源大模型的重要能力之一,在模型规模不变的情况下,增大序列长度可以显著提升模型效果。同时,多模态大模型由于需要处理视频、语音等超长时序信号,模型的上下文窗口需要持续增大。为了保持大模型在超长序列场景的性能,在预训练以及微调过程中,通常会加入部分长序列输入对模型进行训练。目前,主流大模型均已支持128K及以上的序列长度输入。
2 长序列分布式训练面临的挑战
在长序列训练场景,大模型的训练开销(内存和计算量)会以非线性的速度增长,为长序列训练带来巨大挑战。为了加速大模型长序列训练效率,业界提出了多种上下文并行(Context Parallelism,CP)加速方案,对模型的输入上下文窗口进行切分,通过分布式并行技术将计算和内存切分到多个设备,降低每个设备上的负载。目前主流大模型加速库均提供了上下文并行方案以加速长序列训练效率,例如DeepSpeed的Ulysses和Megatron的Ring Attention。
然而,在实际使用场景中,两种方案存在各自的局限性。
Ulysses会对注意力头进行切分,在4D并行场景中,张量并行(TP)也会对注意力头进行切分,因此上下文并行(CP)的维度会受到注意力头数()的限制,从而影响到上下文窗口的有效扩展。
Ring Attention不涉及对注意力头的切分,因此理论上最大序列并行维度不受限,能够实现上下文窗口的无限拓展。然而,在实际应用中,P2P通信需在序列长度足够大的情况下才能被计算过程所掩盖。此外,与集合通信相对,P2P通信在利用通信带宽方面存在局限性。再者,分块注意力计算对于特定位置编码、注意力掩码(attention mask)和注意力算法泛化能力较弱,因此针对不同的应用场景可能需要对分块算法进行专门的调整。
3 MindSpeed长序列训练加速方案
针对现有长序列训练场景的痛点,MindSpeed在并行算法、计算效率、内存占用以及通信四个维度系统性优化大模型长序列训练效率,支持大模型百万级长序列训练。
3.1 并行算法--同时支持三种上下文并行算法/兼容专家并行
MindSpeed同时支持了Ulysses,Ring Attention上下文并行方案,同时还支持混合上下文并行方案[3]。该方案对Ulysses和Ring Attention进行了融合嵌套,通过混合排布AllToAll通信和P2P通信,提升了跨节点场景上下文并行的通信效率,同时缓解了Ulysses方案最大并行维度受到注意力头数限制的问题。
此外,MindSpeed上下文并行兼容专家并行。专家并行是稀疏专家模型(MoE)训练场景中常用的分布式并行加速方案。在MoE训练场景下,MindSpeed可以同时开启上下文并行和专家并行加速万亿MoE超长序列训练场景。
3.2 计算优化—支持FlashAttention
FlashAttention(FA)[4]通过IO感知的分块注意力算法,大幅提升了整体注意力计算效率。MindSpeed长序列训练加速方案使用了昇腾亲和的FlashAttention算子对注意力计算进行加速,大幅提升注意力计算效率。
3.3 内存优化--ALiBi和Reset Attention Mask压缩
在长序列训练场景,注意力掩码带来的内存开销巨大。例如当序列长度为256K时,一个完整的注意力掩码的大小是,存储成本过高。
ALiBi和Reset Attention Mask是长序列训练场景两种常用的技术,MindSpeed针对这两种场景提供了Mask压缩方案,实现内存优化,支撑昇腾上典型长序列训练场景。
3.3.1 ALiBi 位置编码压缩
为了更好的解决位置编码的外推能力,扩展上下文长度,ALiBi(Attention with Linear Biases)[5]通过向注意力分数的每一项添加一个线性偏置项来引入位置信息,见图3。FA算子通过两个入参可以控制ALiBi生成时位置的偏移,从而在内核通过分片的方式生成小块掩码,避免传入完整的ALiBi偏置矩阵。

图1: ALiBi通过偏置矩阵添加线性偏置示意图[5]
然而,Ring Attention方案针对负载不均衡问题对序列划分进行了调整,在该切分方式下,q、k、v是并不连续的(如图4中cp0的0,7块),无法直接通过内核分片方式生成小块掩码。

图2: Ring Attention负载均衡场景支持ALiBi编码压缩计算流程图
为了保持原有负载均衡逻辑,同时不传入完整ALiBi 偏置矩阵降低内存开销,MindSpeed采取了将不连续的块再次拆分的策略,见图2。具体来说,如果当前分块满足连续条件(例如cp3的所有块),或者对于每一行的内部连续(如cp0第2块第2行),则可以直接使用内核生成策略;否则进行进一步拆分,直到满足连续条件,再使用内核生成策略进行生成。如图所示,每一个黑色框内的部分单独计算(白色被掩码掉的部分不参与运算)。
在使用ALiBI位置编码的场景下,相比未做上述优化,完全节省掩码矩阵的内存开销,即 S × S =SS。
3.3.2 Reset Attention Mask压缩
为了缓解长序列训练场景同一序列内文档数量过多,文档间互相干扰的问题,Llama 3.1在预训练过程中使用了Reset Attention Mask。根据Llama 3.1技术报告显示,使用Reset Attention Mask在长序列训练中十分重要[6]。Reset Attention Mask在每个文档的末尾重置注意力,仅保留文档内部的注意力。图3给出了一个例子,文档1的长度为2,文档2的长度为4,文档3的长度为2,所有跨文档的注意力分数均会被掩盖(图3中0表示掩盖)。
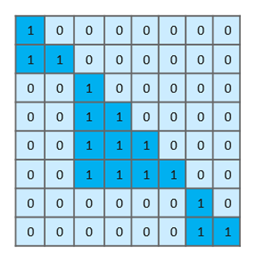
图3: Reset Attention Mask示意图
在该场景下,Ring Attenton的切分会导致部分计算步骤的掩码不规则,无法利用FA的稀疏模式和掩码压缩。MindSpeed通过保留每个Token所属的文档ID,在每个Ring Attention步骤分片计算出当前步骤的分片掩码,无需保留完整掩码。在使用Reset Attention Mask场景下,该优化将注意力掩码的内存开销从S×S 降低到,其中P为上下文并行的维度。
3.4 通信优化--P2P分流并发
MindSpeed采用了send/recv分流并发的思想优化了Ring Attention中的P2P通信,充分利用设备间的通信带宽,减少未被计算掩盖的通信时长,提升整体训练效率。图4, 5中红框部分为未掩盖通信部分。

图4: 未优化前通信算子执行流图

图5: 优化后通信算子执行流图
4 MindSpeed简介
MindSpeed是昇腾AI面向大模型分布式训练提供的加速套件,提供丰富的大模型分布式加速算法、支持开源分布式框架平滑接入、支持算法二次开发,使能昇腾分布式加速技术快速应用。
欢迎加入和体验:https://gitee.com/ascend/MindSpeed
5 参考链接
[1] DEEPSPEED ULYSSES: SYSTEM OPTIMIZATIONS FOR ENABLING TRAINING OF EXTREME LONG SEQUENCE TRANSFORMER MODELS. https://arxiv.org/pdf/2309.14509
[2] Ring Attention with Blockwise Transformers for Near-Infinite Context. https://arxiv.org/pdf/2310.01889
[3] USP: AUnified Sequence Parallelism Approach for Long Context Generative AI.
https://arxiv.org/pdf/2405.07719
[4] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. https://arxiv.org/pdf/2205.14135
[5] Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. https://openreview.net/forum?id=R8sQPpGCv0
[6] The Llama 3 Herd of Models. https://ai.meta.com/research/publications/the-llama-3-herd-of-models/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号