
Python文本统计与分析从基础到进阶
本文分享自华为云社区《Python文本统计与分析从基础到进阶》,作者:柠檬味拥抱。
在当今数字化时代,文本数据无处不在,它们包含了丰富的信息,从社交媒体上的帖子到新闻文章再到学术论文。对于处理这些文本数据,进行统计分析是一种常见的需求,而Python作为一种功能强大且易于学习的编程语言,为我们提供了丰富的工具和库来实现文本数据的统计分析。本文将介绍如何使用Python来实现文本英文统计,包括单词频率统计、词汇量统计以及文本情感分析等。
单词频率统计
单词频率统计是文本分析中最基本的一项任务之一。Python中有许多方法可以实现单词频率统计,以下是其中一种基本的方法:

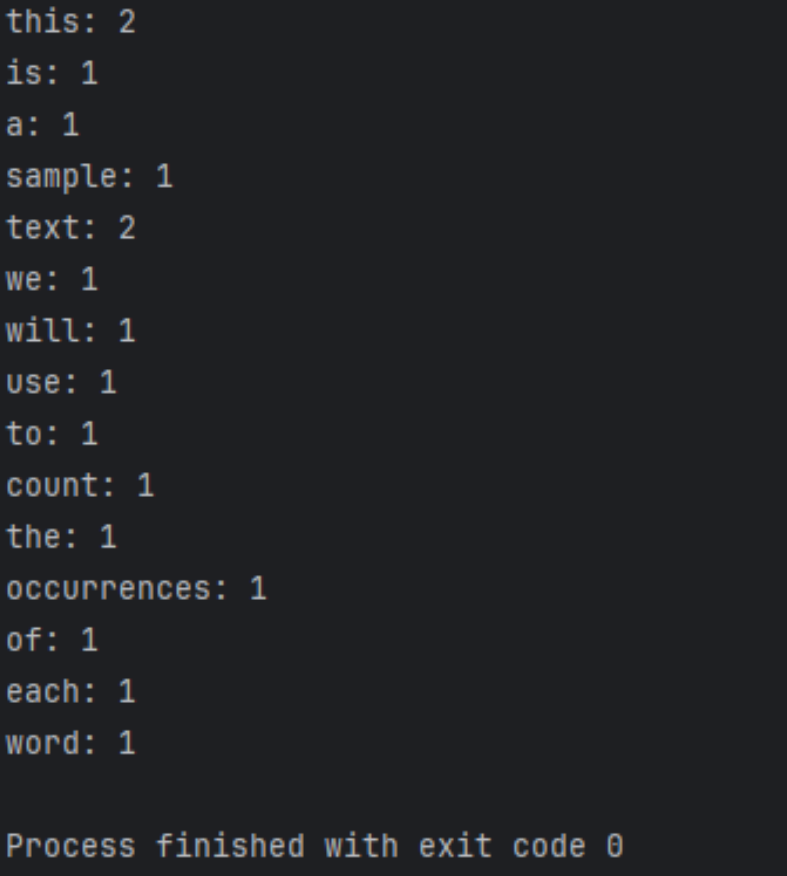
def count_words(text): # 将文本中的标点符号去除并转换为小写 text = text.lower() for char in '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~': text = text.replace(char, ' ') # 将文本拆分为单词列表 words = text.split() # 创建一个空字典来存储单词计数 word_count = {} # 遍历每个单词并更新字典中的计数 for word in words: if word in word_count: word_count[word] += 1 else: word_count[word] = 1 return word_count # 测试代码 if __name__ == "__main__": text = "This is a sample text. We will use this text to count the occurrences of each word." word_count = count_words(text) for word, count in word_count.items(): print(f"{word}: {count}")
这段代码定义了一个函数 count_words(text),它接受一个文本字符串作为参数,并返回一个字典,其中包含文本中每个单词及其出现的次数。下面是对代码的逐行解析:
def count_words(text)::定义了一个函数 count_words,该函数接受一个参数 text,即要处理的文本字符串。
text = text.lower():将文本字符串转换为小写字母,这样可以使单词统计不受大小写影响。
for char in '!"#$%&\'()*+,-./:;<=>?@[\\]^_{|}~’:`:这是一个循环,遍历了文本中的所有标点符号。
text = text.replace(char, ' '):将文本中的每个标点符号替换为空格,这样可以将标点符号从文本中删除。
words = text.split():将处理后的文本字符串按空格分割为单词列表。
word_count = {}:创建一个空字典,用于存储单词计数,键是单词,值是该单词在文本中出现的次数。
for word in words::遍历单词列表中的每个单词。
if word in word_count::检查当前单词是否已经在字典中存在。
word_count[word] += 1:如果单词已经在字典中存在,则将其出现次数加1。
else::如果单词不在字典中,执行以下代码。
word_count[word] = 1:将新单词添加到字典中,并将其出现次数设置为1。
return word_count:返回包含单词计数的字典。
if __name__ == "__main__"::检查脚本是否作为主程序运行。
text = "This is a sample text. We will use this text to count the occurrences of each word.":定义了一个测试文本。
word_count = count_words(text):调用 count_words 函数,将测试文本作为参数传递,并将结果保存在 word_count 变量中。
for word, count in word_count.items()::遍历 word_count 字典中的每个键值对。
print(f"{word}: {count}"):打印每个单词和其出现次数。
运行结果如下
进一步优化与扩展
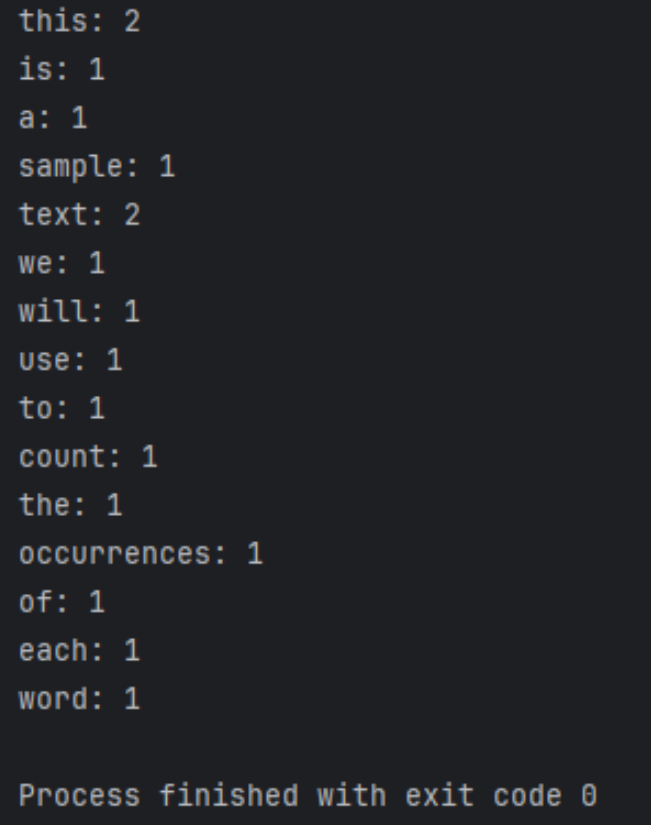
import re from collections import Counter def count_words(text): # 使用正则表达式将文本分割为单词列表(包括连字符单词) words = re.findall(r'\b\w+(?:-\w+)*\b', text.lower()) # 使用Counter来快速统计单词出现次数 word_count = Counter(words) return word_count # 测试代码 if __name__ == "__main__": text = "This is a sample text. We will use this text to count the occurrences of each word." word_count = count_words(text) for word, count in word_count.items(): print(f"{word}: {count}")
这段代码与之前的示例相比有以下不同之处:
- 使用了正则表达式
re.findall()来将文本分割为单词列表。这个正则表达式\b\w+(?:-\w+)*\b匹配单词,包括连字符单词(如 “high-tech”)。 - 使用了 Python 标准库中的
Counter类来进行单词计数,它更高效,并且代码更简洁。
这个实现更加高级,更加健壮,并且处理了更多的特殊情况,比如连字符单词。
运行结果如下
文本预处理
在进行文本分析之前,通常需要进行文本预处理,包括去除标点符号、处理大小写、词形还原(lemmatization)和词干提取(stemming)等。这样可以使得文本数据更加规范化和准确。
使用更高级的模型
除了基本的统计方法外,我们还可以使用机器学习和深度学习模型来进行文本分析,例如文本分类、命名实体识别和情感分析等。Python中有许多强大的机器学习库,如Scikit-learn和TensorFlow,可以帮助我们构建和训练这些模型。
处理大规模数据
当面对大规模的文本数据时,我们可能需要考虑并行处理和分布式计算等技术,以提高处理效率和降低计算成本。Python中有一些库和框架可以帮助我们实现这些功能,如Dask和Apache Spark。
结合其他数据源
除了文本数据外,我们还可以结合其他数据源,如图像数据、时间序列数据和地理空间数据等,进行更加全面和多维度的分析。Python中有许多数据处理和可视化工具,可以帮助我们处理和分析这些数据。
总结
本文深入介绍了如何使用Python实现文本英文统计,包括单词频率统计、词汇量统计以及文本情感分析等。以下是总结:
单词频率统计:
- 通过Python函数
count_words(text),对文本进行处理并统计单词出现的频率。 - 文本预处理包括将文本转换为小写、去除标点符号等。
- 使用循环遍历文本中的单词,使用字典来存储单词及其出现次数。
进一步优化与扩展:
- 引入正则表达式和
Counter类,使代码更高效和健壮。 - 使用正则表达式将文本分割为单词列表,包括处理连字符单词。
- 使用
Counter类进行单词计数,简化了代码。
文本预处理:
文本预处理是文本分析的重要步骤,包括去除标点符号、处理大小写、词形还原和词干提取等,以规范化文本数据。
使用更高级的模型:
介绍了使用机器学习和深度学习模型进行文本分析的可能性,如文本分类、命名实体识别和情感分析等。
处理大规模数据:
提及了处理大规模文本数据时的技术考量,包括并行处理和分布式计算等,以提高效率和降低成本。
结合其他数据源:
探讨了结合其他数据源进行更全面和多维度分析的可能性,如图像数据、时间序列数据和地理空间数据等。
总结:
强调了本文介绍的内容,以及对未来工作的展望,鼓励进一步研究和探索,以适应更复杂和多样化的文本数据分析任务。
通过本文的学习,读者可以掌握使用Python进行文本英文统计的基本方法,并了解如何进一步优化和扩展这些方法,以应对更复杂的文本分析任务。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【.NET】调用本地 Deepseek 模型
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· 我与微信审核的“相爱相杀”看个人小程序副业
2023-05-06 看华为云Serverless 4大特性如何让软件架构更丝滑
2023-05-06 GaussDB(DWS)字符串处理函数返回错误结果集排查
2023-05-06 分布式场景下,如何对外提供易变的服务,打造可靠的注册中心?
2023-05-06 Istio数据面新模式:Ambient Mesh技术解析
2022-05-06 Open Harmony移植:build lite配置目录全梳理
2022-05-06 解析Java-throw抛出异常详细过程
2022-05-06 云图说|云数据库RDS跨区域备份