
动手实践丨轻量级目标检测与分割算法开发和部署(RK3568)
本文分享自华为云社区《自动驾驶(AIOT) - 轻量级目标检测与分割算法开发和部署(RK3568)【玩转华为云】》,作者:HouYanSong。
本文将在ModelArts平台上开发轻量级目标检测与分割算法,并使用ModelBox框架在RK3568开发板上实现模型推理和部署。
数据准备
我们收集了一份200张由Labelme标注的道路图像分割数据集,之后使用脚本将其转换为VOC格式的数据集并进行数据增强:

处理好的数据集已经分享到AI Gallery上,可以使用OBS下载:

算法简介
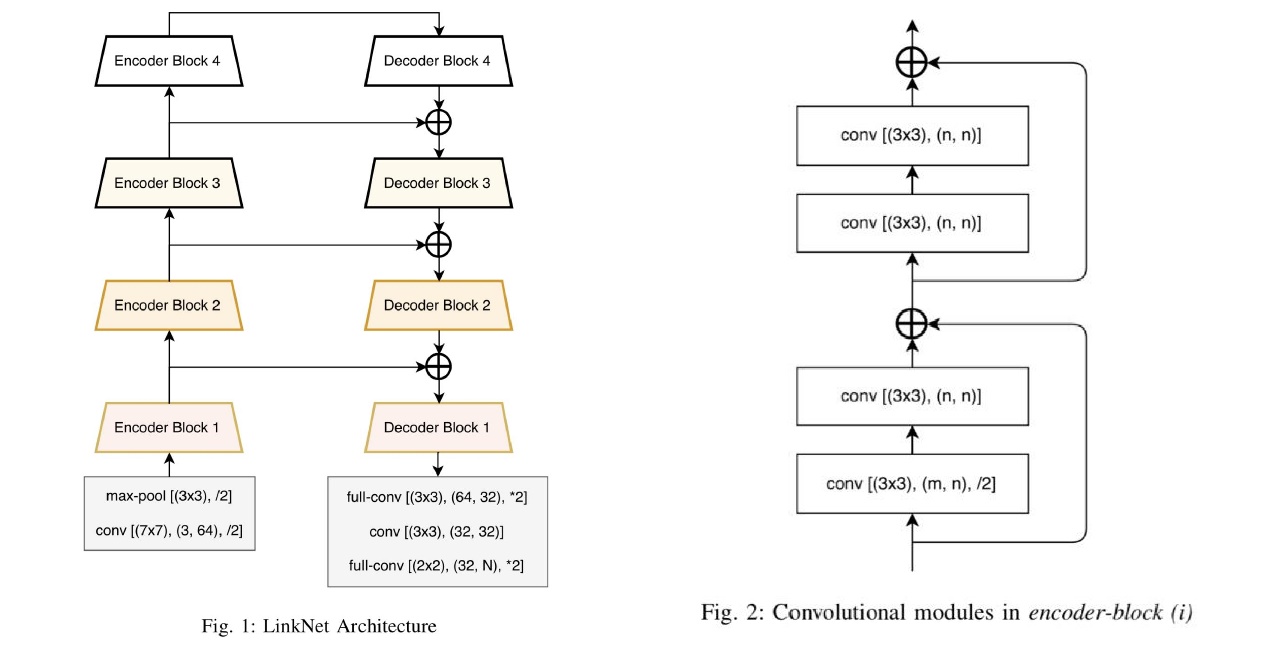
像素级的图像分割不仅需要精确,有时还需要高效以便应用到real-time application比如自动驾驶汽车等。现有的方法可能精度较高但往往参数量巨大,为了解决这个问题,我们使用LinkNet作为主干网络[Fig. 1],中间层[Fig. 2]使用LeakyRelu进行激活,最后一层使用Sigmoid做归一化,并在Encoder Block 4后增添目标检测分支,训练过程中进行梯度裁剪防止梯度爆炸。
云端训练
算法详情可以运行我发布的Notebook,并下载转换好的模型文件:

ONNXRuntime推理:
下载yolo_tf_seg.zip并解压到本地,之后安装opencv、numpy、onnxruntime即可一键运行。
端侧推理

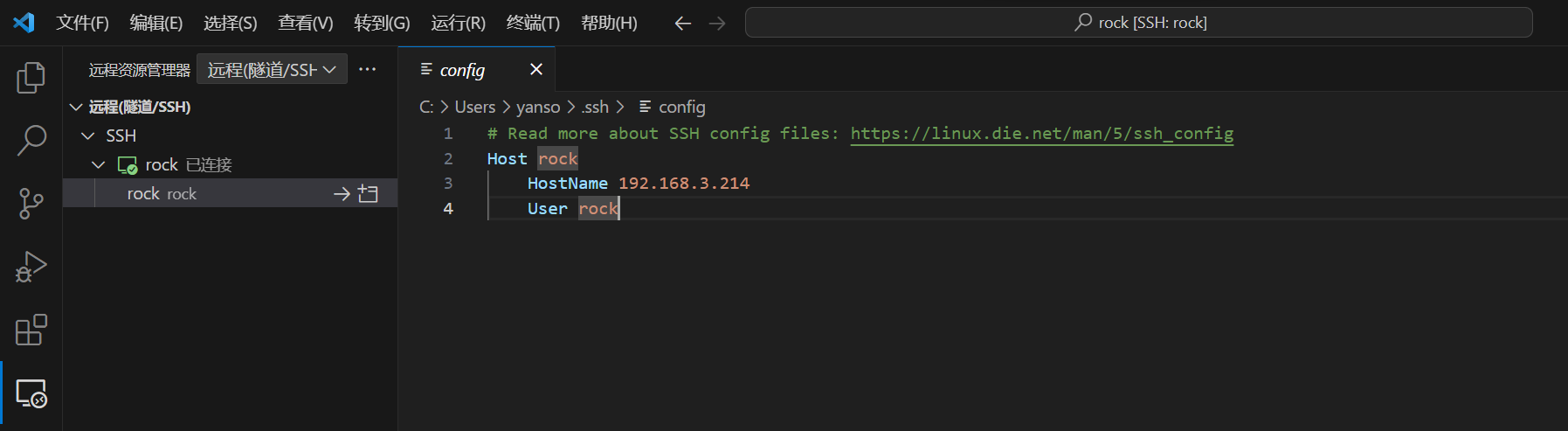
1、我们在VS Code中使用Remote-SSH远程连接ModelBox端云协同AI开发套件(RK3568):
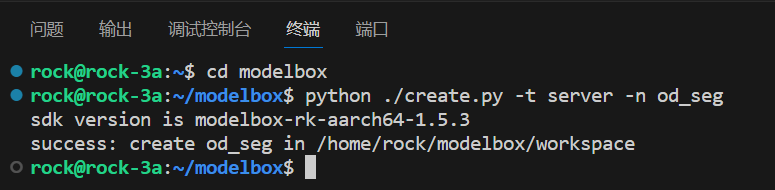
2、在SDK目录下使用create.py脚本创建工程object_detection_seg(od_seg):
3、创建推理功能单元yolo_tf_seg:

4、将转换好的模型放到yolo_tf_seg目录下,我们的模型有一个输入和两个输出:
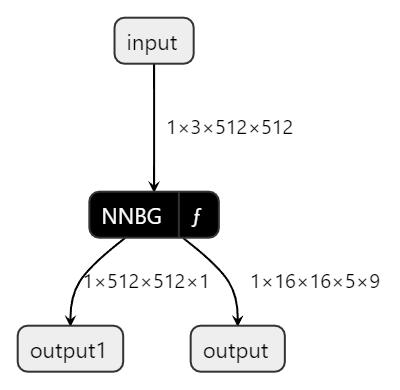
修改配置文件如下: 5、创建后处理功能单元post_process:
5、创建后处理功能单元post_process:
对于后处理功能单元,我们在config中配置参数,接收2个float类型的推理结果,返回类别检测框和图像掩码:
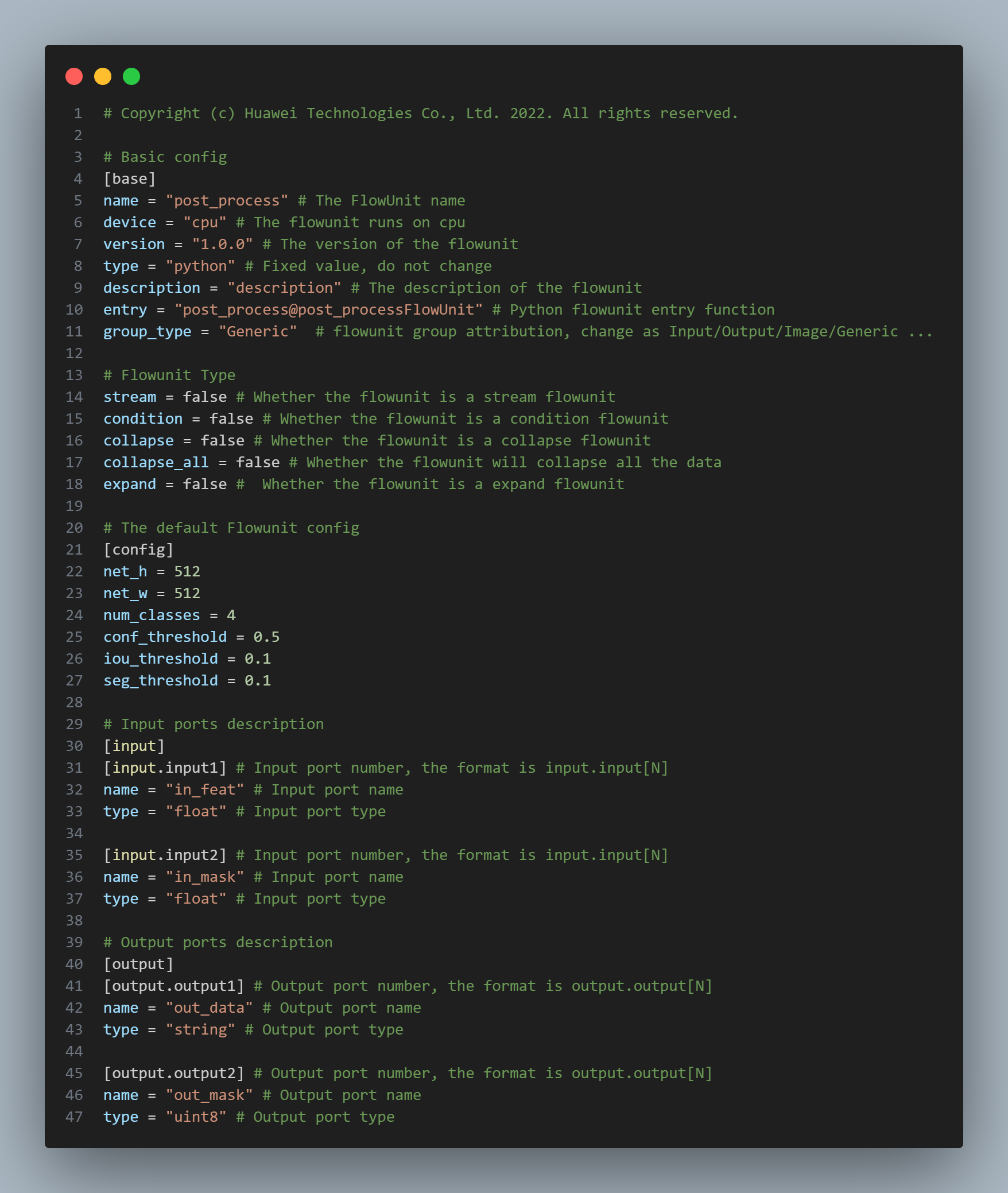
对应的逻辑代码如下:
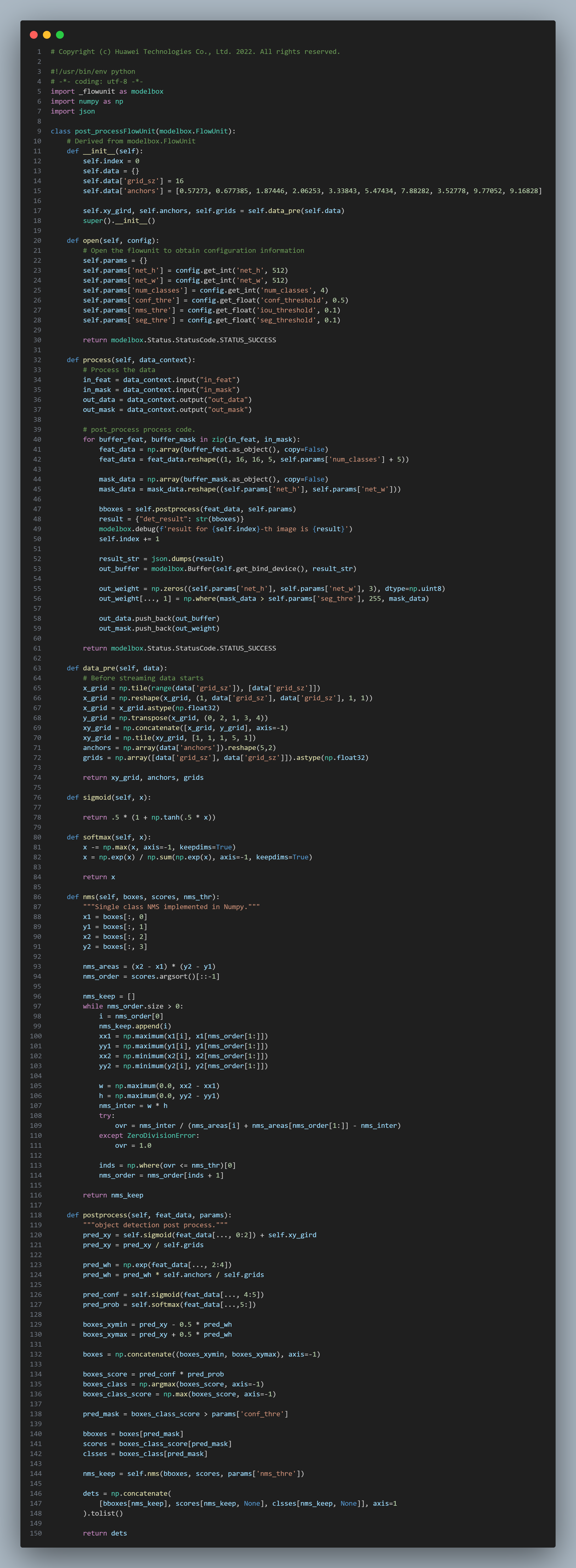
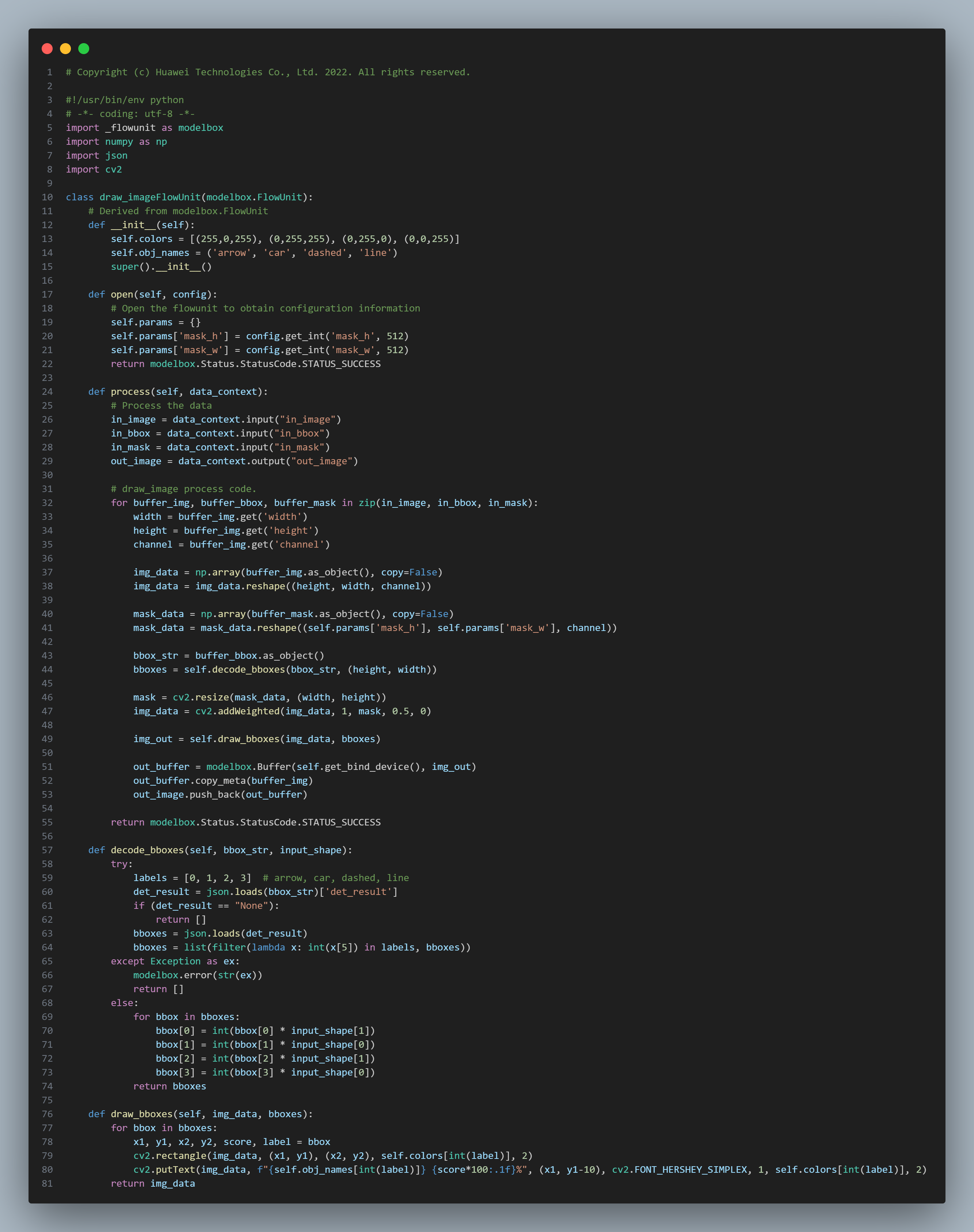
6、创建绘图功能单元draw_image:

对于绘图功能单元,我们接收解码后的原始图像和目标检测框以及分割图像,对应的配置文件如下:
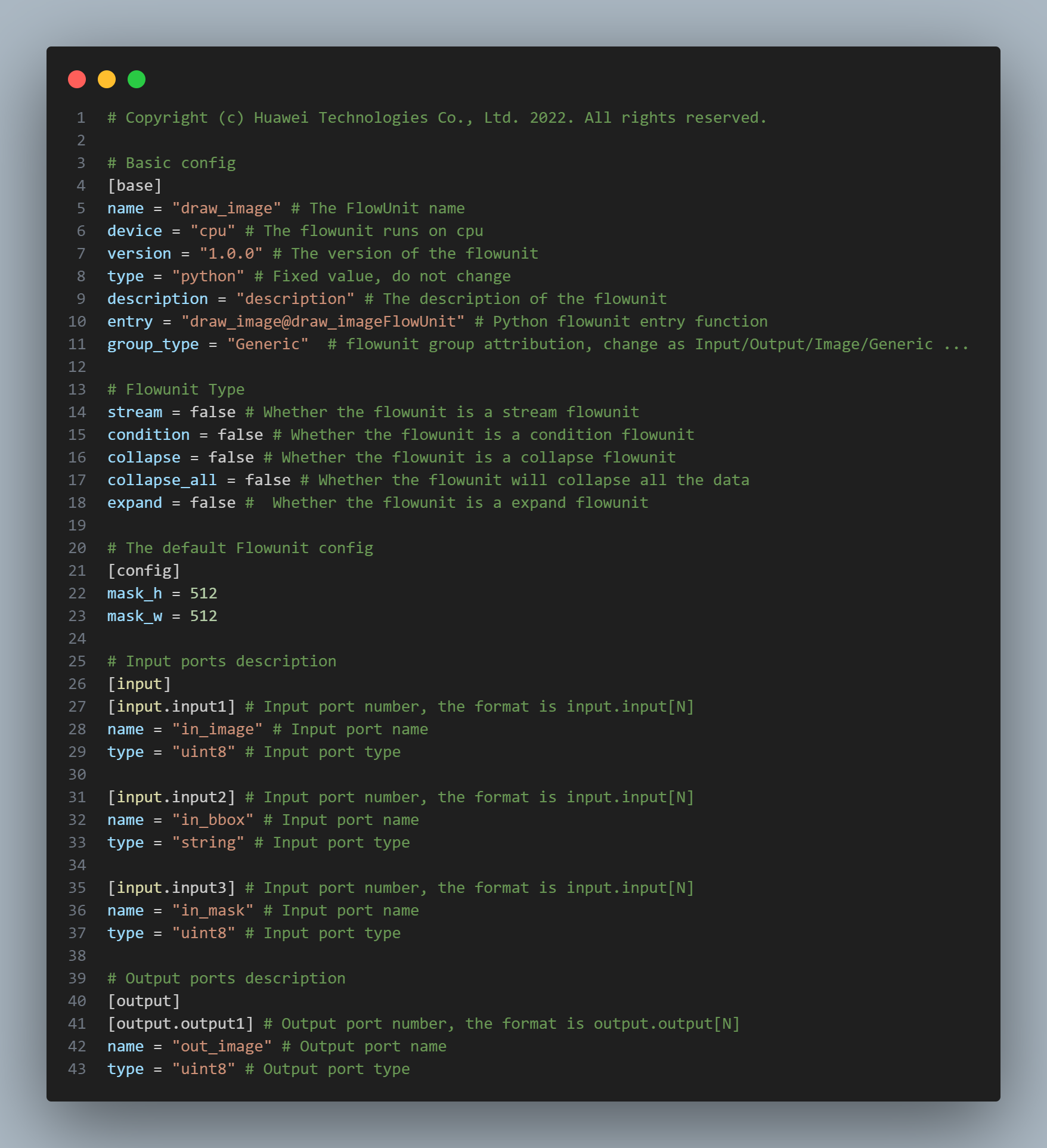
接下来补充逻辑代码生成新的图像:
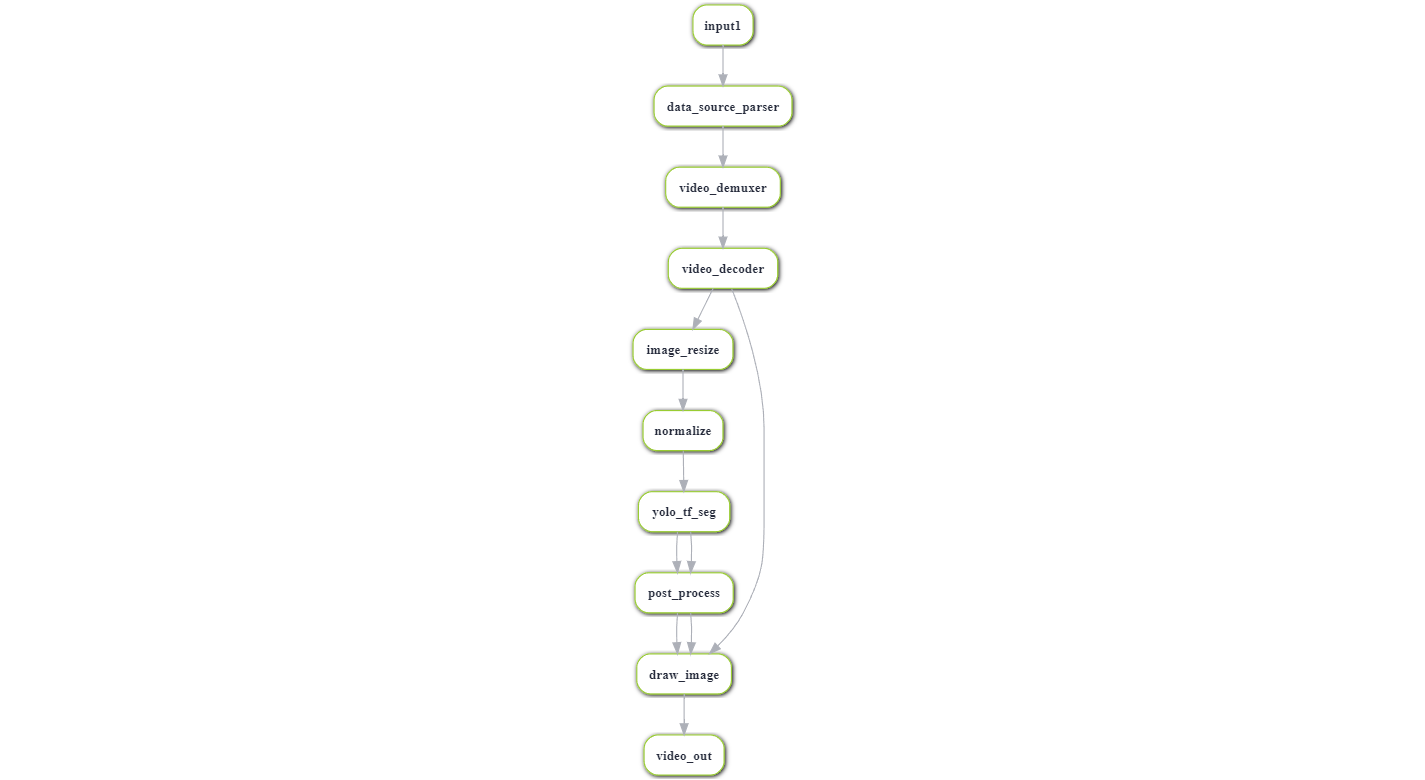
7、查看流程图:
代码如下:
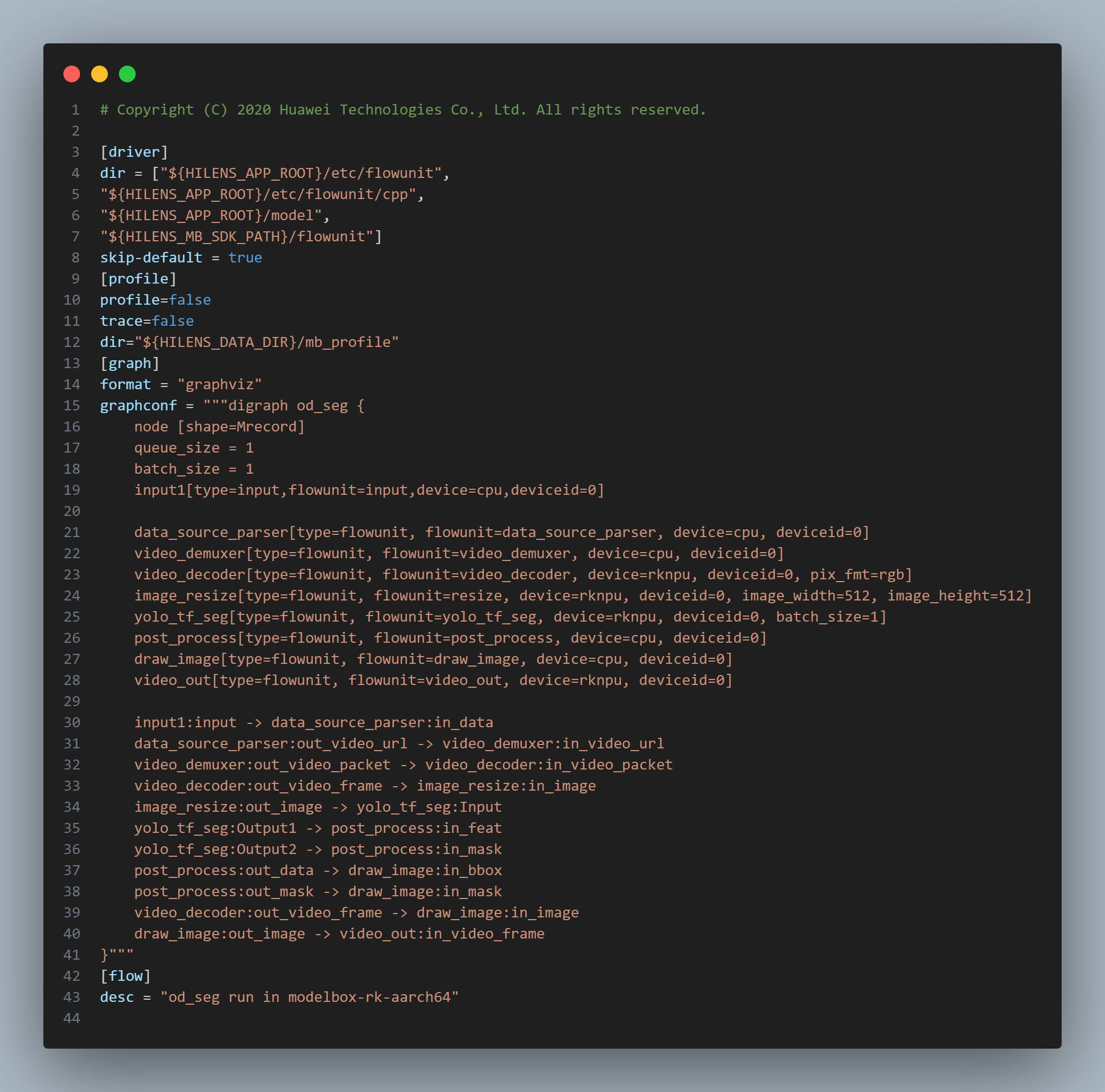
8、配置输入和输出,运行应用:
9、我们可以在Chrome浏览器chrome://tracing/中加载性能统计文件:
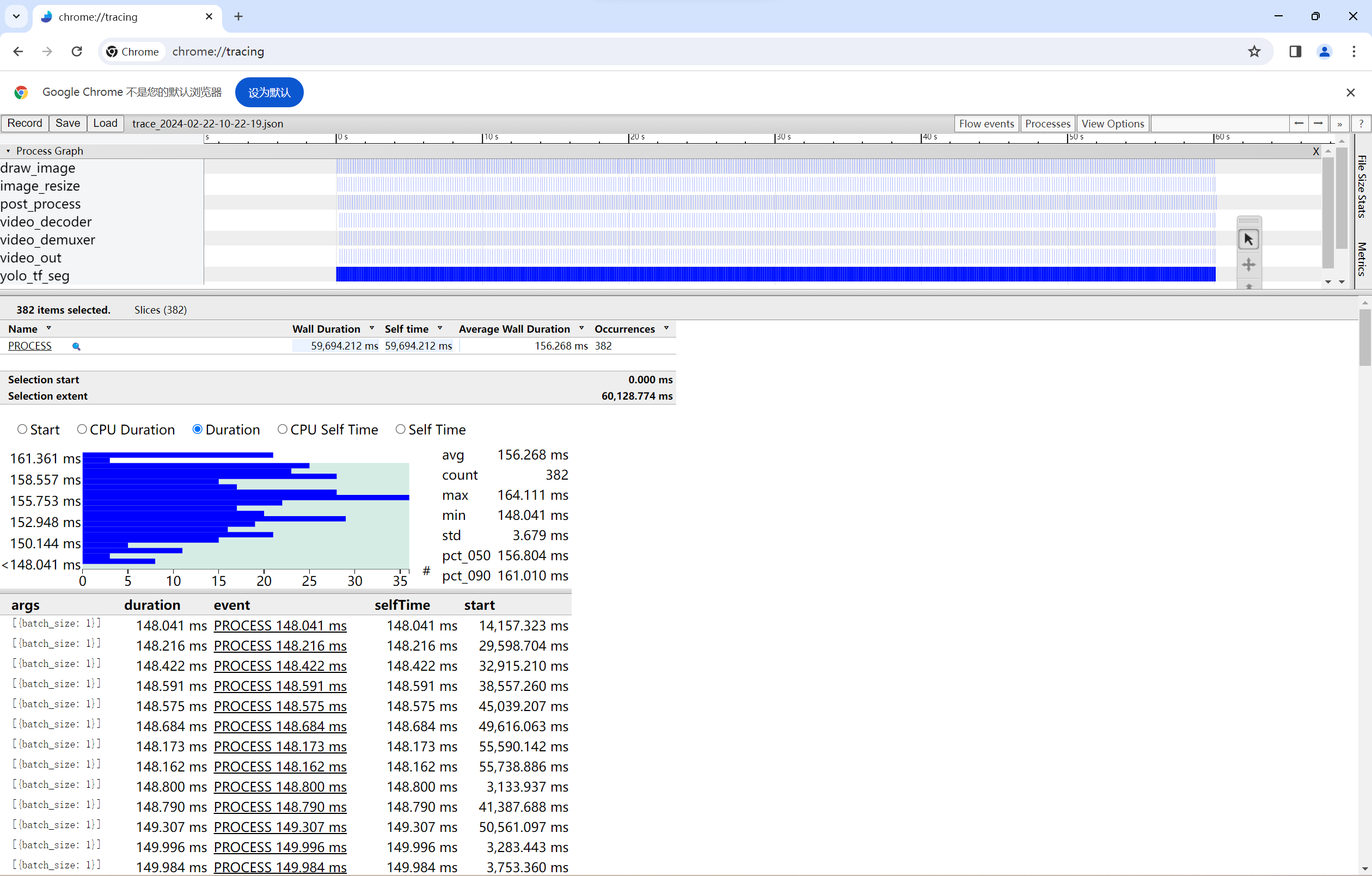
通过分析耗时最久的是推理功能单元,720p视频检测帧率在6fps左右。
小结:
本文总体而言并没有太多的创新点,是一个纯工程化的项目,主要工作是将学术界的优秀论文落地到边缘设备上,通过对网络的魔改,得到一个兼顾精度、速度和体积的目标检测和分割模型,在模型量化过程中会出现精度损失,后续会通过优化算法以及选择不同的量化算法kl_divergence(feature分布不均匀时可以得到较好的改善效果)继续提高模型的检测效果,复现本案例所需资源(代码、模型、测试数据等)均可从object_detection_seg.zip获取。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【.NET】调用本地 Deepseek 模型
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· 我与微信审核的“相爱相杀”看个人小程序副业
2022-02-26 梦幻联动!金蝶&华为云面向大企业发布数据库联合解决方案
2022-02-26 亿级数据量场景下,如何优化数据库分页查询方法?
2022-02-26 掌握这20个JS技巧,做一个不加班的前端人
2022-02-26 权威可信 | 华为云云测通过中国电子技术标准院软件测试工具能力评价
2021-02-26 用Vue3构建企业级前端应用,TS能让你更轻松点
2021-02-26 华为云GaussDB(for openGauss)商用啦!
2021-02-26 让 AI “潜入”物流中心,你的快递很快就到!