
数仓性能调优:row_number() over(p)-rn=1性能瓶颈发现和改写套路
1.数仓实践丨主动预防-DWS关键工具安装确认2.一条SQL如何被MySQL架构中的各个组件操作执行的?3.GaussDB(DWS)网络流控与管控效果4.GaussDB(DWS)字符串处理函数返回错误结果集排查5.从缓存的本质说起,说服技术大佬用Redis6.这年头怕数据泄露?全密态数据库:无所谓,我会出手7.华为云新一代分布式数据库GaussDB,给世界一个更优选择8.GaussDB技术解读丨高级压缩9.掌数科技携手华为云GaussDB,助力金融科技创新,联合打造行业标杆10.一文带你全面了解openGemini11.GaussDB(for Redis)多租户:读写权限控制和数据库隔离的完美融合12.5分钟迁移关系型数据库到图数据库13.数仓现网案例丨超大结果集接收异常14.DWS轻量化更新黑科技:宽表加工优化15.数据库行业需要什么样的人才?高校老师这样说16.数仓性能优化:倾斜优化-表达式计算倾斜的hint优化17.GaussDB技术解读系列之SQL Audit,面向应用开发的SQL审核工具18.带你认识数仓的监控系统TopSQL19.带你走进数仓大集群内幕丨详解关于作业hang及残留问题定位20.实时入库不用愁,HStore帮分忧21.openGauss数据库在CentOS上的安装实践22.揭秘华为云GaussDB(for Redis)丨大key治理23.GaussDB(DWS)函数不同写法引发的结果差异24.数仓中典型的几种不下推语句整改案例25.GaussDB技术解读系列之应用无损透明(ALT)26.华为云GaussDB(for Influx)单机版上线,企业降本增效利器来了27.数仓备份经验分享丨详解roach备份原理及问题处理套路28.中国云数据仓库,双第一!29.华为云GaussDB打造最可信的数据库,给世界一个更优选择30.GaussDB技术解读系列:高级压缩之OLTP表压缩31.十年磨一剑的华为云GES,高明在哪32.使用DWS集群,用户被锁定如何解锁33.GaussDB技术解读系列:高安全之密态等值34.GaussDB技术解读:应用无损透明(ALT)35.数仓资源管控理论已掌握,是时候实战了36.row_number函数的不稳定性37.GaussDB技术解读丨数据库迁移创新实践38.聊聊GaussDB AP是如何执行SQL的39.Navicat 携手华为云GaussDB,联合打造便捷高效的数据库开发和建模工具方案40.GaussDB技术解读系列丨运维自动驾驶探索41.一次性全讲透GaussDB(DWS)锁的问题42.GaussDB(DWS)性能调优:Sort+Groupagg聚集引起的性能瓶颈案例43.多主架构:VLDB技术论文《Taurus MM: bringing multi-master to the cloud》解读44.GaussDB(for Redis)游戏实践:玩家下线行为上报45.一文详解数据仓库的物理细粒度备份恢复46.华为云HBase冷热分离最佳实践47.四问复合索引,让你的数据查询速度飞起48.GaussDB(DWS)案例丨MERGE场景下语句不下推引起的性能瓶颈问题49.如何强制SQL走性能更优的hash join50.如何使用GaussDB(DWS)的本地临时表进行数据处理51.华为云GaussDB亮相金融业数据库技术大会52.2个数仓中不等值关联优化案例53.数仓实时场景下表行数估算不准确引起的的性能瓶颈问题案例54.详解GuassDB数据库权限命令:GRANT和REVOKE55.DWS临时内存不可用报错: memory temporarily unavailable56.华为云GaussDB城市沙龙活动走进安徽,助力金融行业数字化转型57.理论+应用,带你了解数据库资源池58.人人用数不用愁,动态数据脱敏为您解忧59.实例讲解数据库的数据去重60.数仓实践丨表扫描时过滤行数过多引起的性能瓶颈问题61.实例详解构建数仓中的行列转换62.Proxy下的Prepare透传,让GaussDB(for MySQL)更稳固,性能更卓越63.浅析KV存储之长尾时延解决办法64.实例讲解数据库的定义重载函数65.详解数据库SQL中的三个语句:DROP、TRUNCATE 、DELETE66.华为云GaussDB助力工商银行、华夏银行斩获“十佳卓越实践奖”67.Navicat 基于 GaussDB 主备版的快速入门68.数仓实时算子难以观测,快来试试算子级监控吧69.列举数据库缓存使用场景实例和命令速查表70.带你认识多模数据库GeminiDB架构与应用实践71.3招解决时序数据高基数难题,性能多维度提升!
72.数仓性能调优:row_number() over(p)-rn=1性能瓶颈发现和改写套路
73.数仓实践丨常量标量子查询做全连接导致整体慢74.细说GaussDB(DWS)的2种查询优化技术75.细说SQL与ETL之间的小秘密76.从概念到实践,带你掌握层次递归查询77.GeminiDB Cassandra接口新特性PITR发布:支持任意时间点恢复78.你的JoinHint为什么不生效79.六步走向无忧,华为云数据库高可用的秘密武器80.数仓调优实践丨SQL改写消除相关子查询81.GaussDB(for MySQL)新特性TDE发布:支持透明数据加密82.详解GaussDB(DWS)通信安全的小妙招:连接认证机制83.GaussDB(for MySQL) RegionlessDB发布:全球数据库技术84.5分钟带您了解DRS录制回放85.ICDM'23 BICE论文解读:基于双向LSTM和集成学习的模型框架86.数仓如何递归查询视图依赖87.支撑核心系统分布式改造,GaussDB为江南农商银行筑稳根基88.近6成金融机构的选择!华为云GaussDB加快金融核心系统转型89.GaussDB(for MySQL)剪枝功能,让查询性能提升70倍!90.2023年度十佳课题公布:华为云GaussDB获权威认可91.详解如何在数仓中搭建细粒度容灾应用92.对话苏光牛:国内数据库市场已进入关键转折点,2024年或是分水岭93.GaussDB通信运维:详解stream连接池设计原理94.GaussDB(for MySQL) Serverless全面商用:无感弹性,极致性价比95.华为云GaussDB支撑农行超级网银业务,性能和稳定性备受认可96.实例详解数据库的游标管理97.数仓实践丨从CU入手优化HStore表98.数仓的等待视图中,为什么会有Hashjoin-nestloop99.如何基于Sharding-JDBC实现GaussDB在客户端应用的读写分离100.如何迅速并识别处理MDL锁阻塞问题本文分享自华为云社区《GaussDB(DWS)性能调优:row_number() over(p)-rn=1性能瓶颈发现和改写套路》,作者:Zawami 。
1、改写场景
本套路应用于子查询中含有row_number() over(partition by order by) rn,并仅把rn列用于分类排序后筛选最大值的场景。
2、性能分析
GaussDB中SQL语句的执行很多时候是流式的,即对每一条数据进行流水加工,各层算子同时在执行,缩短执行耗时。
但是在一些场景下,需要先取得前一个算子的全部结果集,然后才能够进行下一步的加工;窗口函数就是其中的一种。
观察执行计划可以看到,SQL会在计算得到rn列后,再同本层查询其它列进行关联。由于存在窗口函数,必须先把51号算子先执行完,然后才能进行关联,造成性能瓶颈。
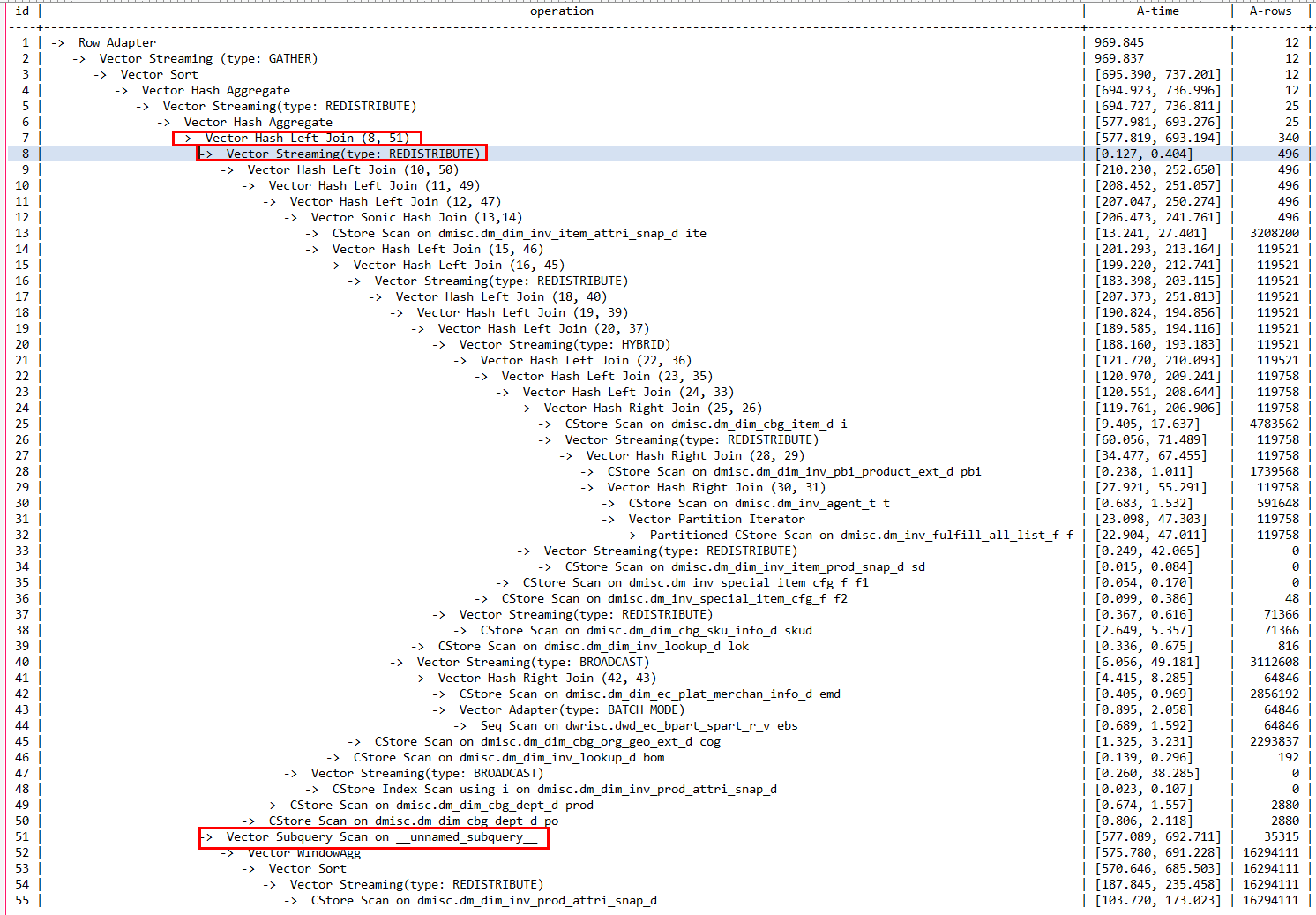
通过去窗口函数改写,我们可以使得分类汇总同明细数据之间的关联流水执行。
改写前局部SQL

SELECT PROD_EN_NAME, PROD_LIFE_CYCLE_STATUS FROM ( SELECT PROD_EN_NAME, LIFE_CYCLE AS PROD_LIFE_CYCLE_STATUS, DEL_FLAG, ROW_NUMBER ( ) OVER ( PARTITION BY PROD_EN_NAME ORDER BY RUN_DATE DESC ) RN FROM DMISC.DM_DIM_INV_PROD_ATTRI_SNAP_D WHERE DATA_TYPE = 1 AND DEL_FLAG = 'N' AND RUN_DATE <= CAST ( '2023-06-11' || ' 00:00:00' AS TIMESTAMP ) ) WHERE RN = 1
改写后局部SQL
WITH T AS ( SELECT PROD_EN_NAME, MAX ( LIFE_CYCLE ) AS PROD_LIFE_CYCLE_STATUS, RUN_DATE FROM DMISC.DM_DIM_INV_PROD_ATTRI_SNAP_D WHERE DATA_TYPE = 1 AND DEL_FLAG = 'N' AND RUN_DATE <= CAST ( '2023-06-11' || ' 00:00:00' AS TIMESTAMP ) GROUP BY PROD_EN_NAME, RUN_DATE ) SELECT PROD_EN_NAME, PROD_LIFE_CYCLE_STATUS FROM T WHERE (PROD_EN_NAME, RUN_DATE) IN (SELECT PROD_EN_NAME, MAX(RUN_DATE) FROM T GROUP BY PROD_EN_NAME)
改写解析:这里先把数据根据原SQL中row_number() over()的partition列和order列进行去重,由于原SQL未定义LIFE_CYCLE的排序方式,改写既可以使用MAX也可以使用MIN函数来进行聚合。然后再对去重后的数据进行过滤,过滤条件显然。
使用这种修改方法,修改前后的全量执行计划已在附件中给出。
这种改写方式解决了上层算子等窗口函数的问题。我们发现,一些业务场景下对不涉及聚合的其它列,比如上面例子中的LIFE_CYCLE并不敏感,且还需要进行进一步聚合的,那么对本层子查询中的去重其实没有硬性需求。可以进一步去除这层去重。
WITH T AS ( SELECT PROD_EN_NAME, LIFE_CYCLE AS PROD_LIFE_CYCLE_STATUS, RUN_DATE FROM DMISC.DM_DIM_INV_PROD_ATTRI_SNAP_D WHERE DATA_TYPE = 1 AND DEL_FLAG = 'N' AND RUN_DATE <= CAST ( '2023-06-11' || ' 00:00:00' AS TIMESTAMP ) ) SELECT PROD_EN_NAME, PROD_LIFE_CYCLE_STATUS FROM T WHERE (PROD_EN_NAME, RUN_DATE) IN (SELECT PROD_EN_NAME, MAX(RUN_DATE) FROM T GROUP BY PROD_EN_NAME)
改写后执行计划如下:
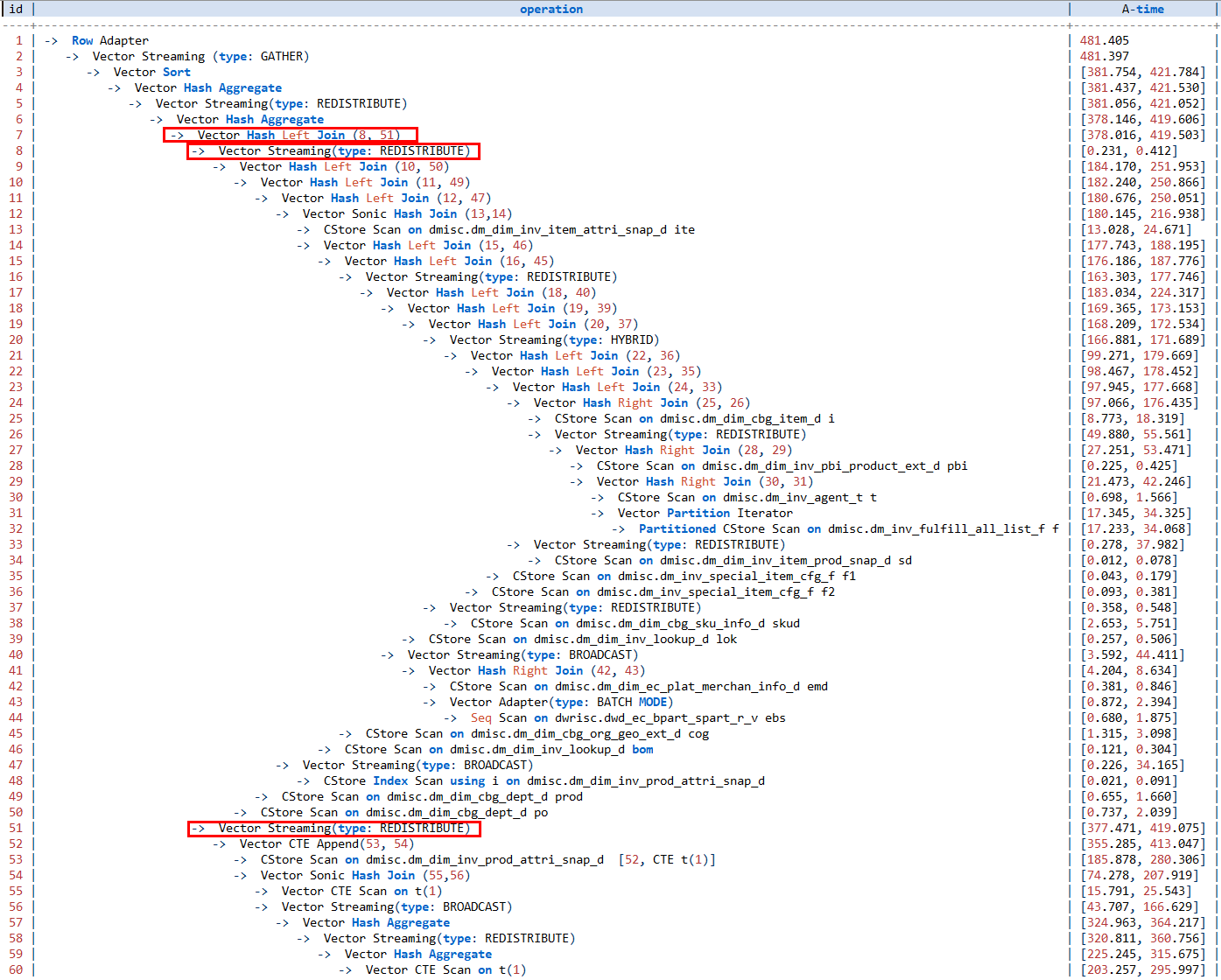
可以看到,执行计划中虽然51层算子只快了200ms,但由于减少阻塞,1~7层算子的执行时间缩短了,总体比原先快了约480ms。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【.NET】调用本地 Deepseek 模型
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· 我与微信审核的“相爱相杀”看个人小程序副业
2022-11-28 千年荒漠变绿洲,看沙漠“卫士”携手昇腾AI植起绿色希望
2022-11-28 探讨Morest在RESTful API测试的行业实践
2022-11-28 FCOS论文复现:通用物体检测算法
2020-11-28 如何应对Spark-Redis行海量数据插入、查询作业时碰到的问题
2020-11-28 数仓搬迁:从方法到实践,带你解决数据一致性对比
2020-11-28 讲真,你知道Python咋来的吗?
2020-11-28 白皮书丨关于工业互联网,你想知道的都在这儿