告别繁琐,ModelArts一键解决车牌号识别难题
本文分享自华为云社区《基于ModelArts实现车辆车牌号的目标识别》,作者:屿山岛 。
前言
车辆车牌是车辆的唯一身份标识,能够提供车辆的类型、颜色、归属地等信息,对于交通管理、安全监控、智能出行等领域具有重要的应用价值。随着计算机视觉技术的发展,车辆车牌的自动检测和识别成为了一个热门的研究课题,也有许多成熟的商业产品和开源项目。
我对车辆车牌检测和识别的技术原理和应用场景很感兴趣,想要通过实践来提高自己的图像处理和机器学习的能力,同时也想要探索一些新的方法和思路,解决一些实际问题。因此,我选择了华为云的ModelArts平台,利用其提供的数据处理、模型训练、模型管理和模型部署等全流程的支持,实现了一个对车辆车牌的目标检测模型。
在本博客中,我将详细介绍我使用ModelArts平台的过程和经验,包括数据集的准备、模型的选择和修改、训练的参数和结果、部署的方法和效果等,以及遇到的一些问题和解决方案。我希望能够通过本博客,与有兴趣的读者分享和交流,也欢迎大家提出宝贵的意见和建议。
前置工作
首先确保已经完成了华为云账号的开通与认证,并添加用户的访问密钥,以方便使用ModelArts。
数据集的准备
来自于中科大2018年开源的大型国内停车场车牌数据集CCPD(Chinese City Parking Dataset)弥补了上述车牌数据的缺陷,该车牌数据集图片收集自安徽省合肥市的各种街道路边停车场,每个收集员于各自负责的街道不分天气的从早上07:30一直工作到晚上22:00,每当开停车账单时就需要手持特殊设备根据要求拍摄前后车牌图片并进行车牌信息标注,从而在不可确认的拍摄位置、拍摄角度、拍摄光照、拍摄天气、拍摄背景、拍摄街道等约束条件下保障了所获取车牌数据的多样性
本人从github上获取了该数据的2020新版
OBS桶及对象的创建
OBS是ModelArts提供的使用对象存储服务,目的是为了进行数据存储以及模型的备份和快照。本次实验在创建训练数据集之前,需要创建一个OBS桶,然后在OBS桶中创建文件夹用于存放训练文件。
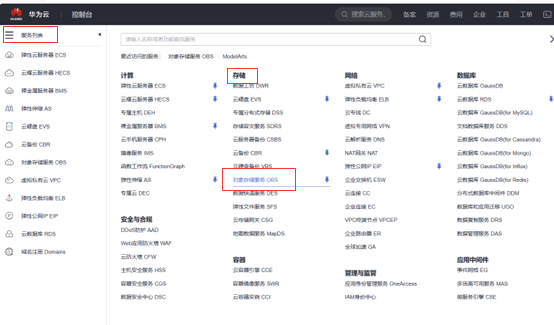
OBS桶的创建
进入服务列表,找到存储服务项,点击对象存储服务OBS
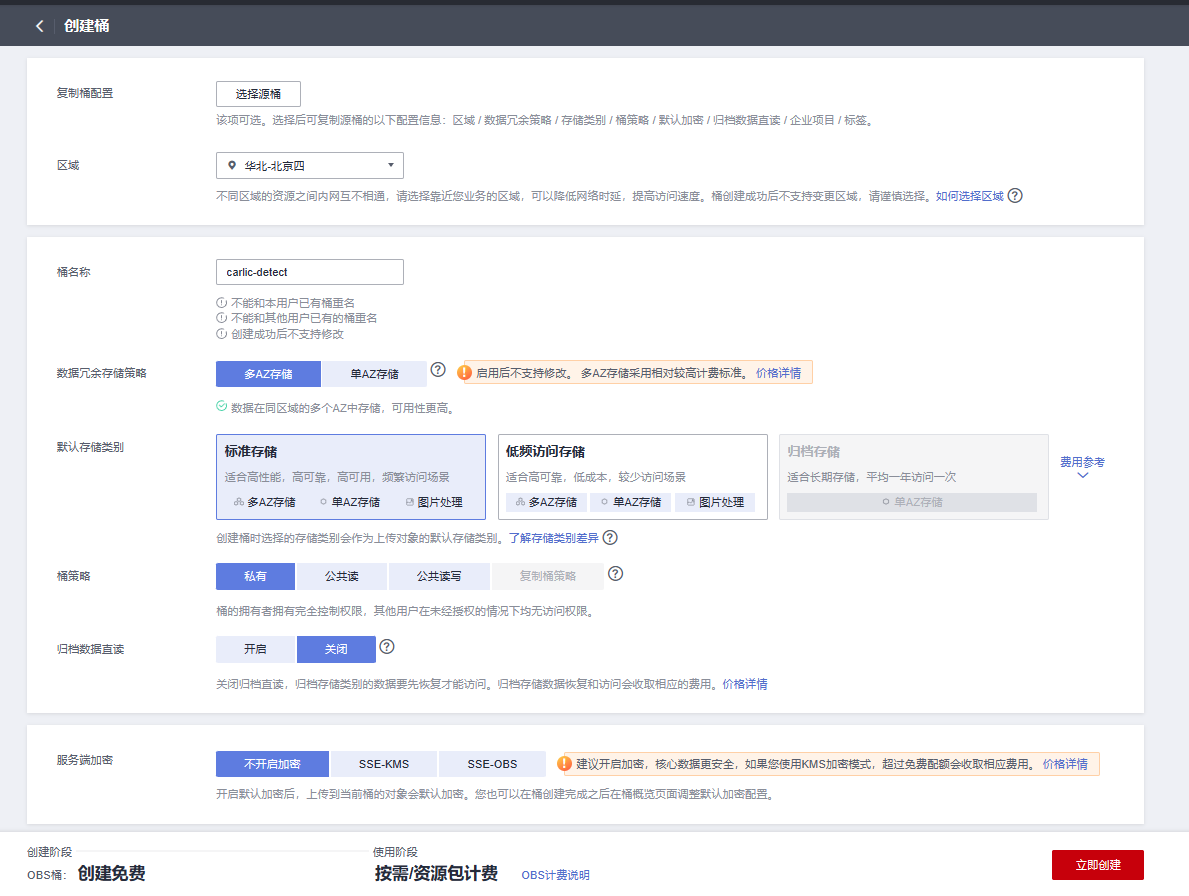
登录OBS管理控制台,在桶列表页面右上角单击“创建桶”,创建OBS桶
填写参数:
• "区域":华北-北京四,后续区域需要选择和OBS桶一致。
• "桶名称":创建桶名称“carlic-detect”,注意重名时可以添加后缀。
• “数据冗余存储策略”:多AZ存储
• “默认存储类型”:标准存储
其他使用默认值即可,确认无误后单击右下角“立即创建”。
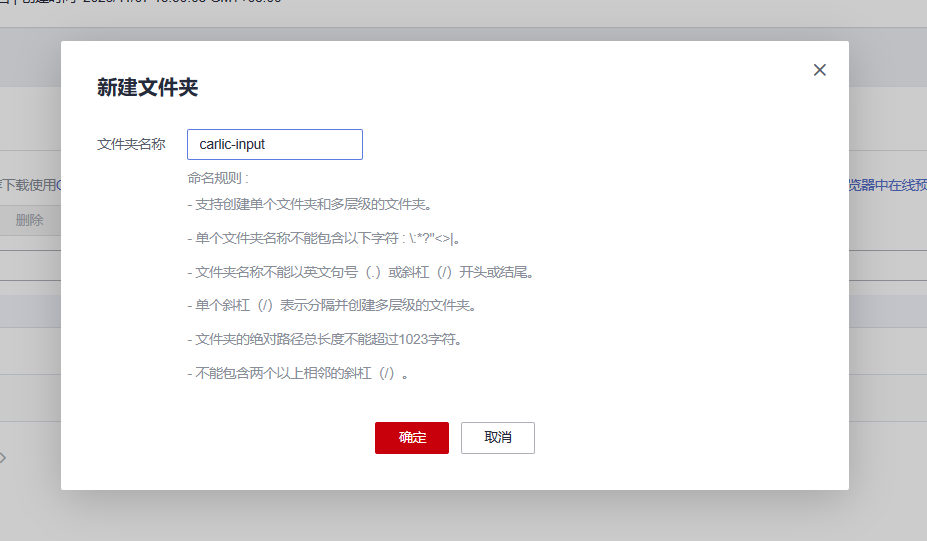
OBS桶中对象的创建
在桶列表页面,单击桶名称,进入该桶的概览页面。单击概览页面的左侧导航的“对象”,在“对象”页面单击新建文件夹,创建OBS文件夹。我们在这里创建两个文件夹,一个用于数据集的输入,一个用于数据集的输出
数据集输入文件夹“carlic-input”
数据集输出文件夹“carlic-output”
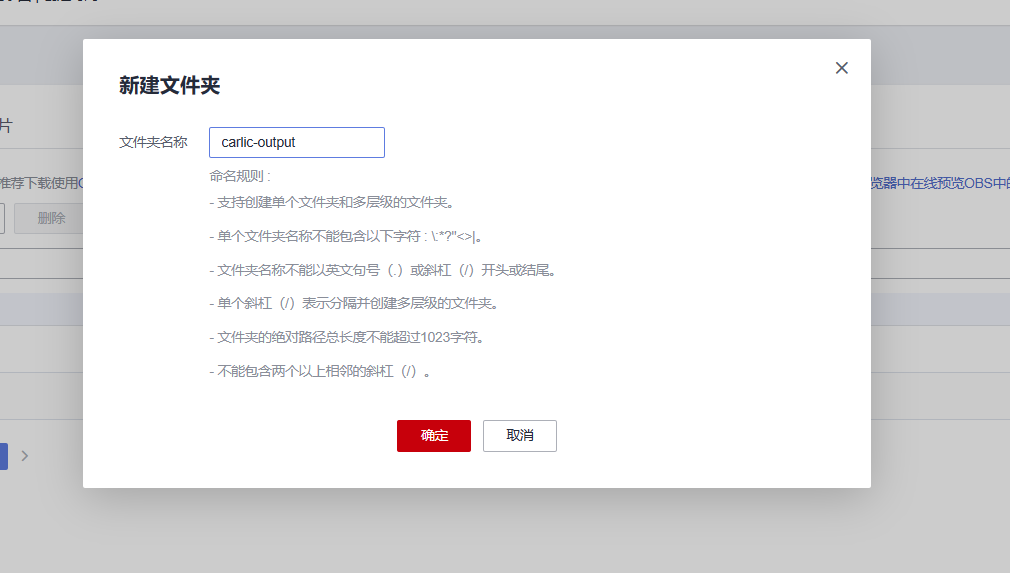
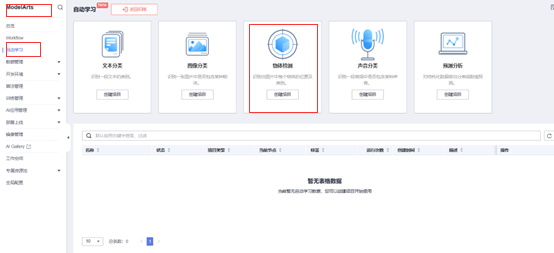
ModelArts自动学习项目的创建
进入ModelArts自动学习版跨,创建物体检测的项目
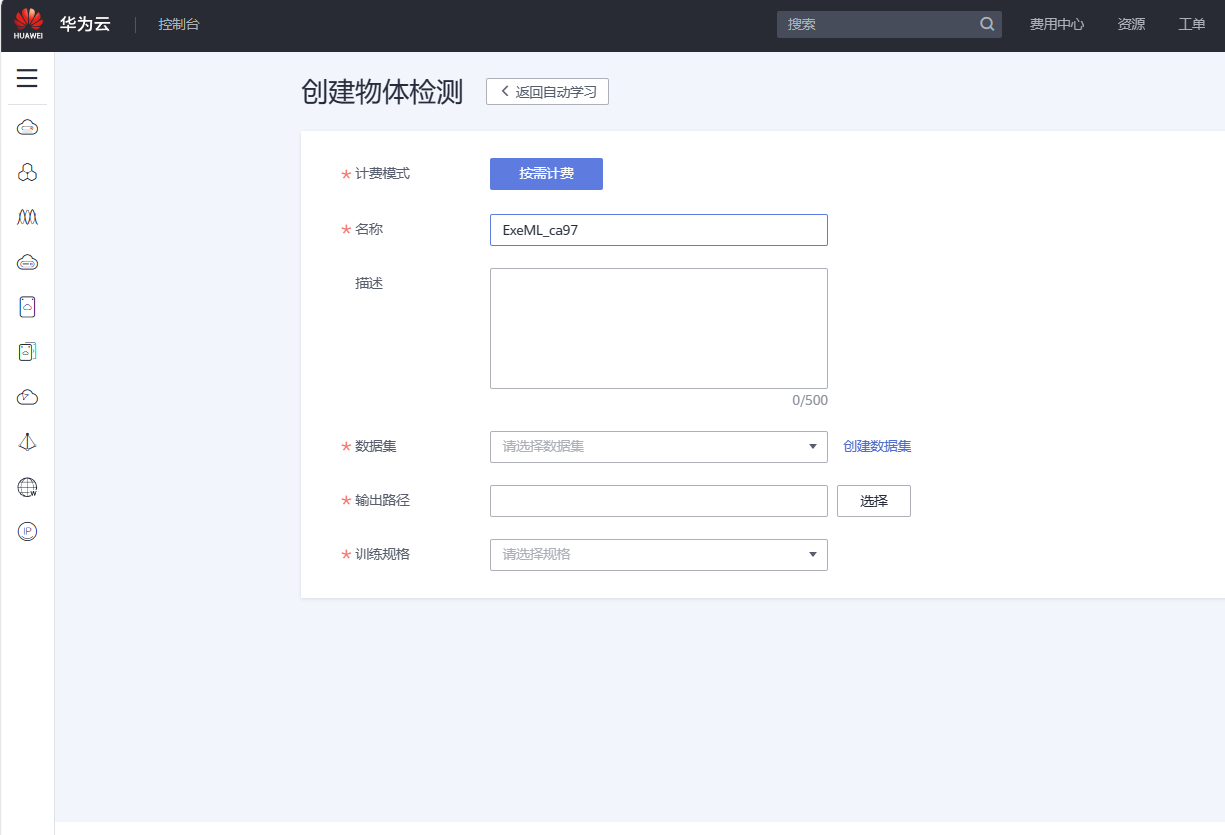
创建物体检测项目的数据集
此时发现我们并没有数据集,所以需要创建数据集。此时点击创建数据集
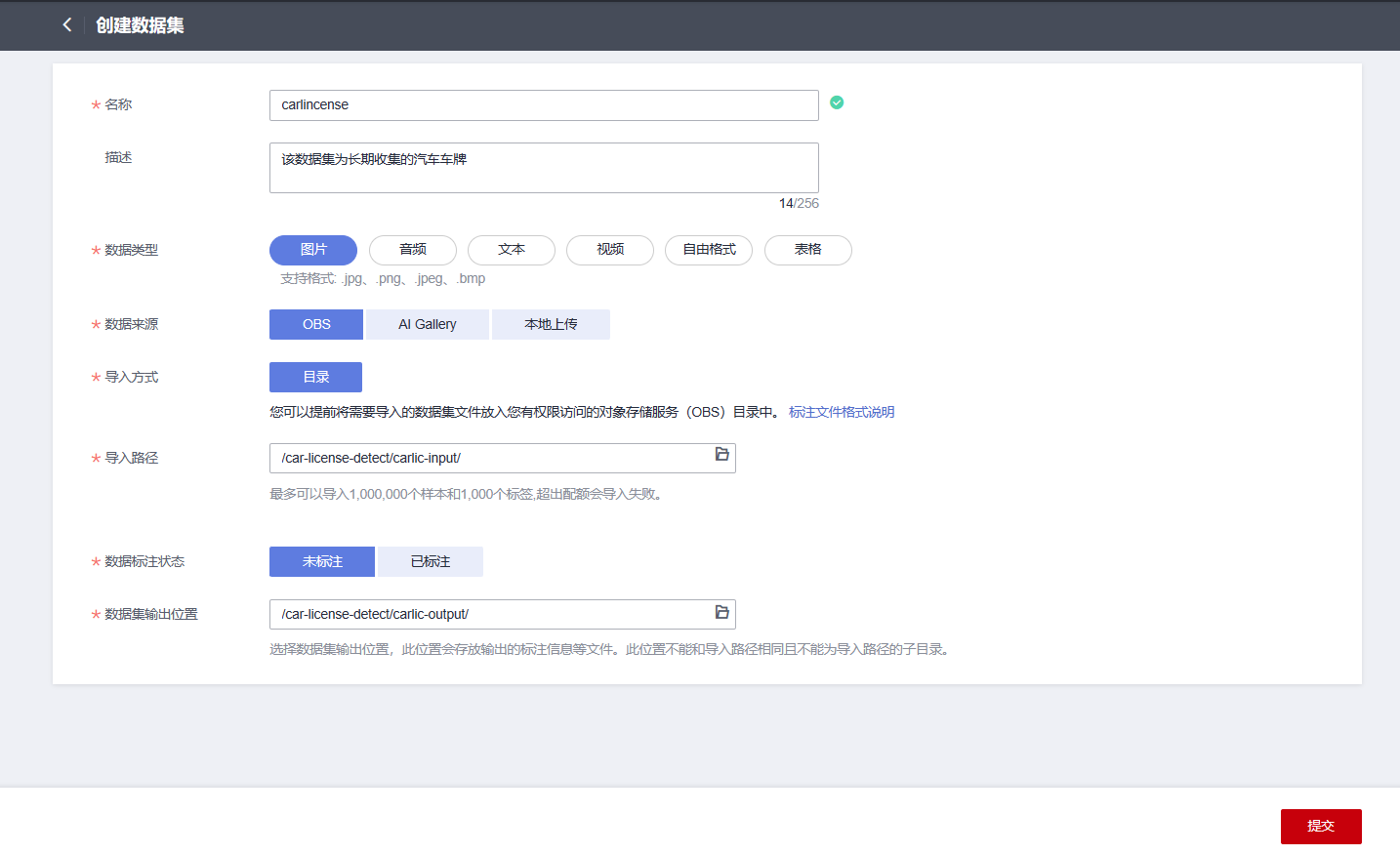
点击后有如下界面,其中各参数为:
• “数据集名称”:carlicense
• “数据类型”:图片
• “数据来源”:OBS
• “导入路径”:选择之前创建OBS桶时创建的carlic-input文件夹
• “数据标注状态“:未标注
• “数据输出位置”:选择之前创建OBS时创建的carlic-output文件夹
再点击右下角提交,数据集创建成功
此时再填入物体检测项目的各个参数信息
• “名称”:carlicense-detect
• “数据集”:选择刚刚创建好的数据集“carlicense”
• “输出路径”:选择所创建OBS桶中的数据输出文件夹“carlic-output”
• “训练规格”:选择限时免费的规格
然后点击右下角的创建项目
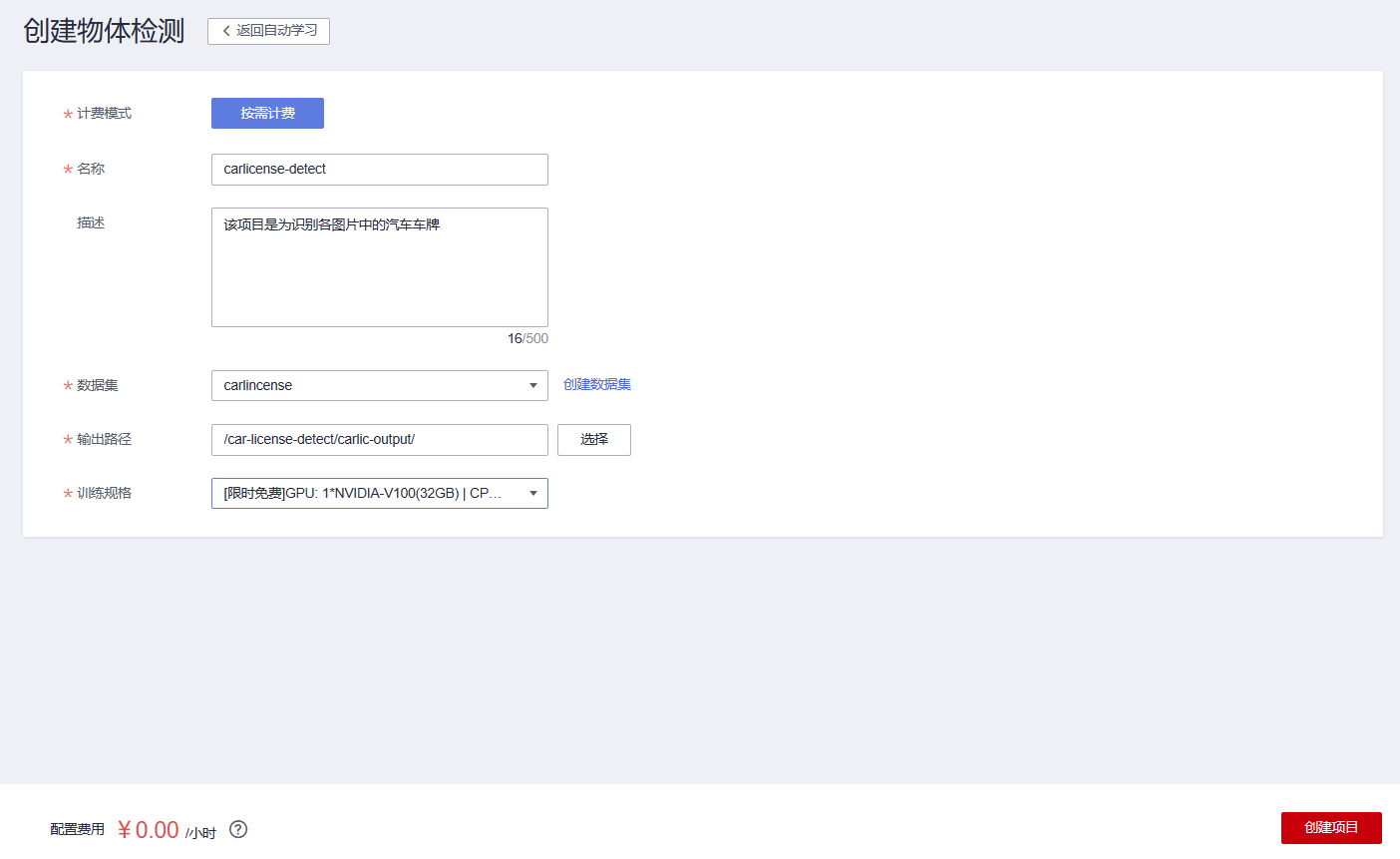
创建项目后得到如下界面:
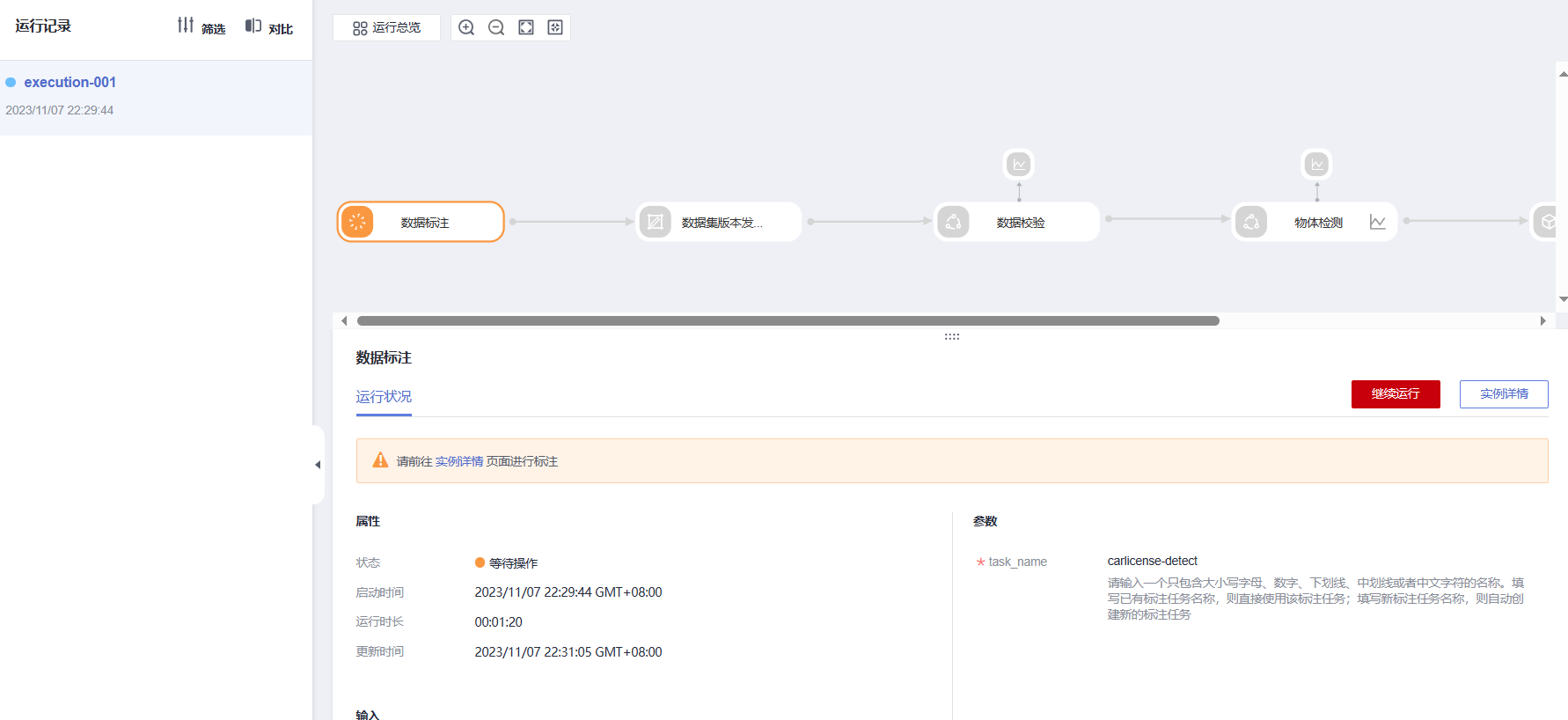
数据的上传与标注
该界面显示我们需要对实例进行标注,点击进入实例详细
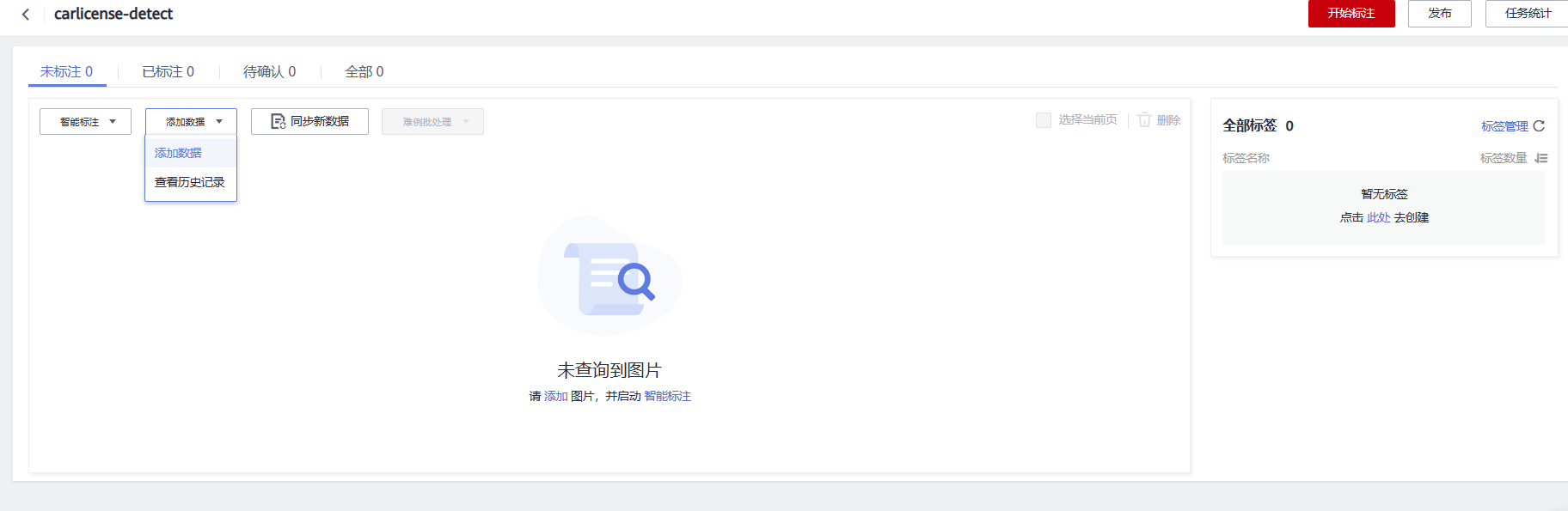
数据上传
由于数据集是空的,所以该页面显示未查询到图片,此时我们点击添加数据
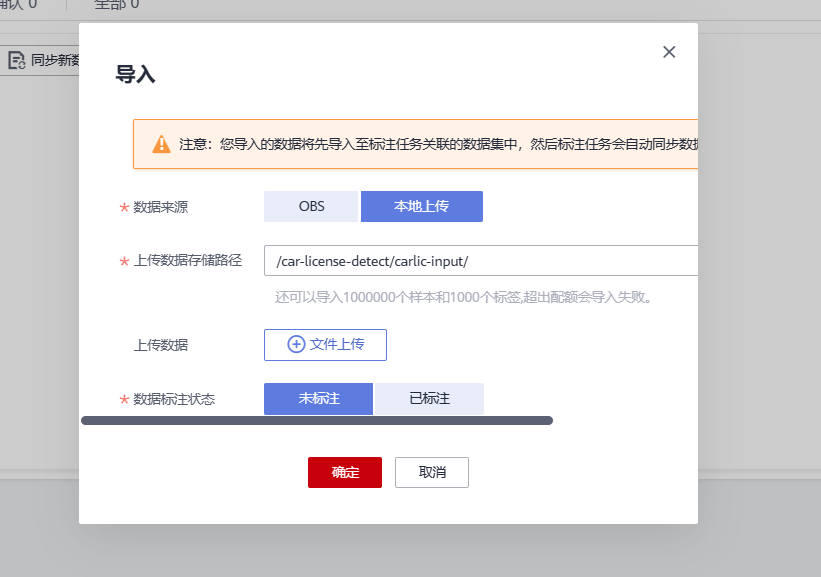
导入数据参数如下:
• “数据来源”:本地上传(因为下载的数据都在本地上,并没有上传至OBS中)
• “上传数据存储路径“:选择之前创建的OBS桶中的数据输入文件夹“carlic-input”
• “数据标注状态“:未标注(数据集的所有数据均为未标注)
然后点击文件上传,将本地文件上传之所创建的OBS桶中的数据输入文件夹中
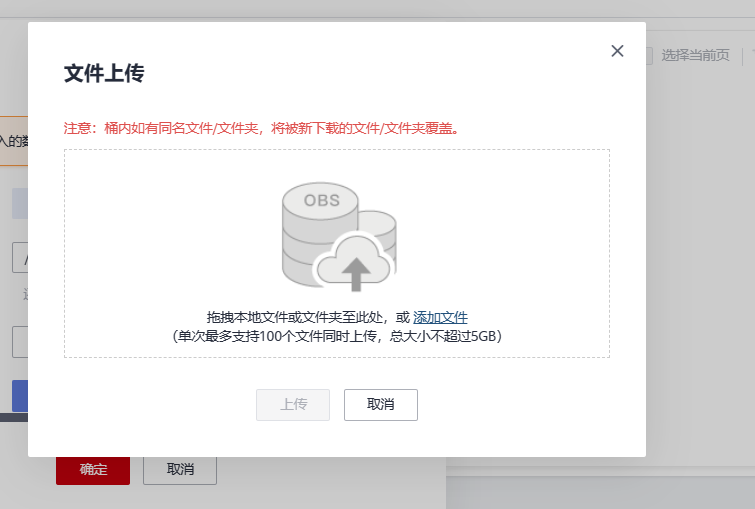
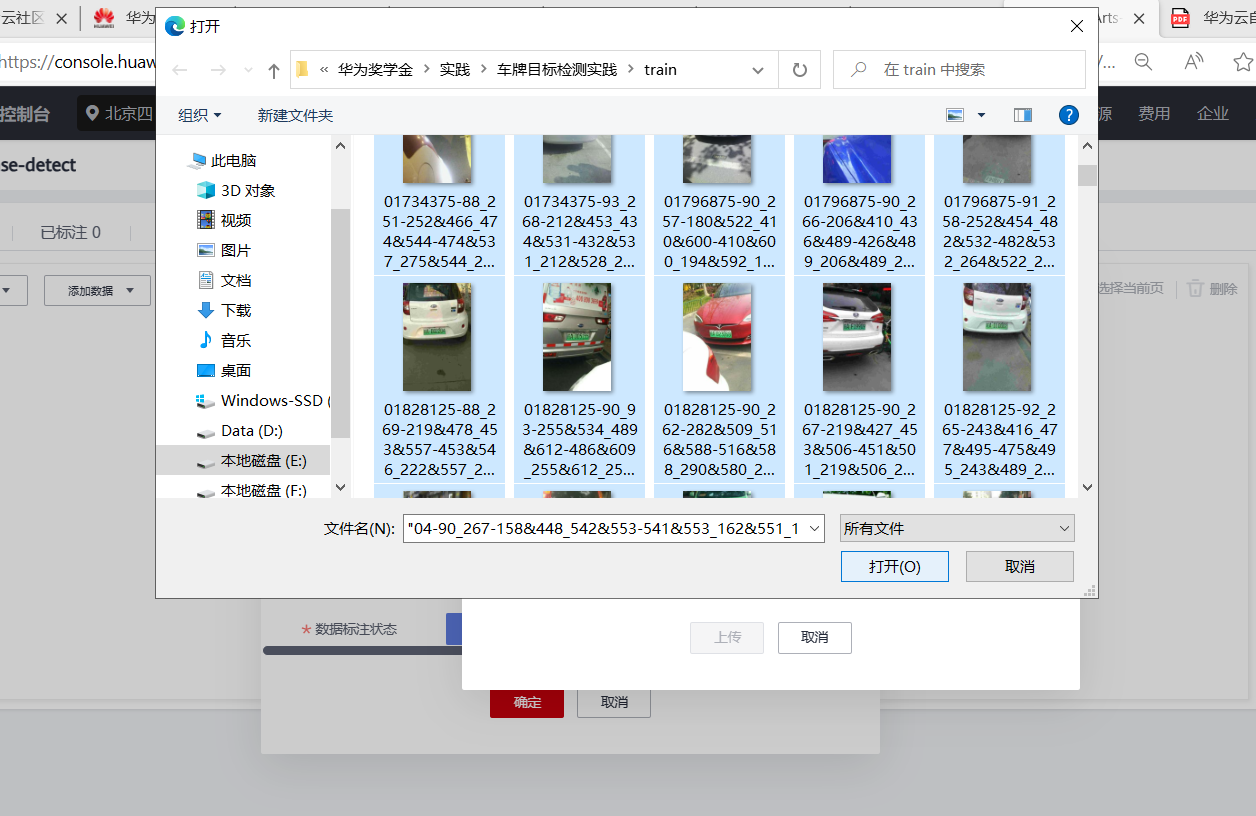
点击添加文件,上传本地的训练数据文件
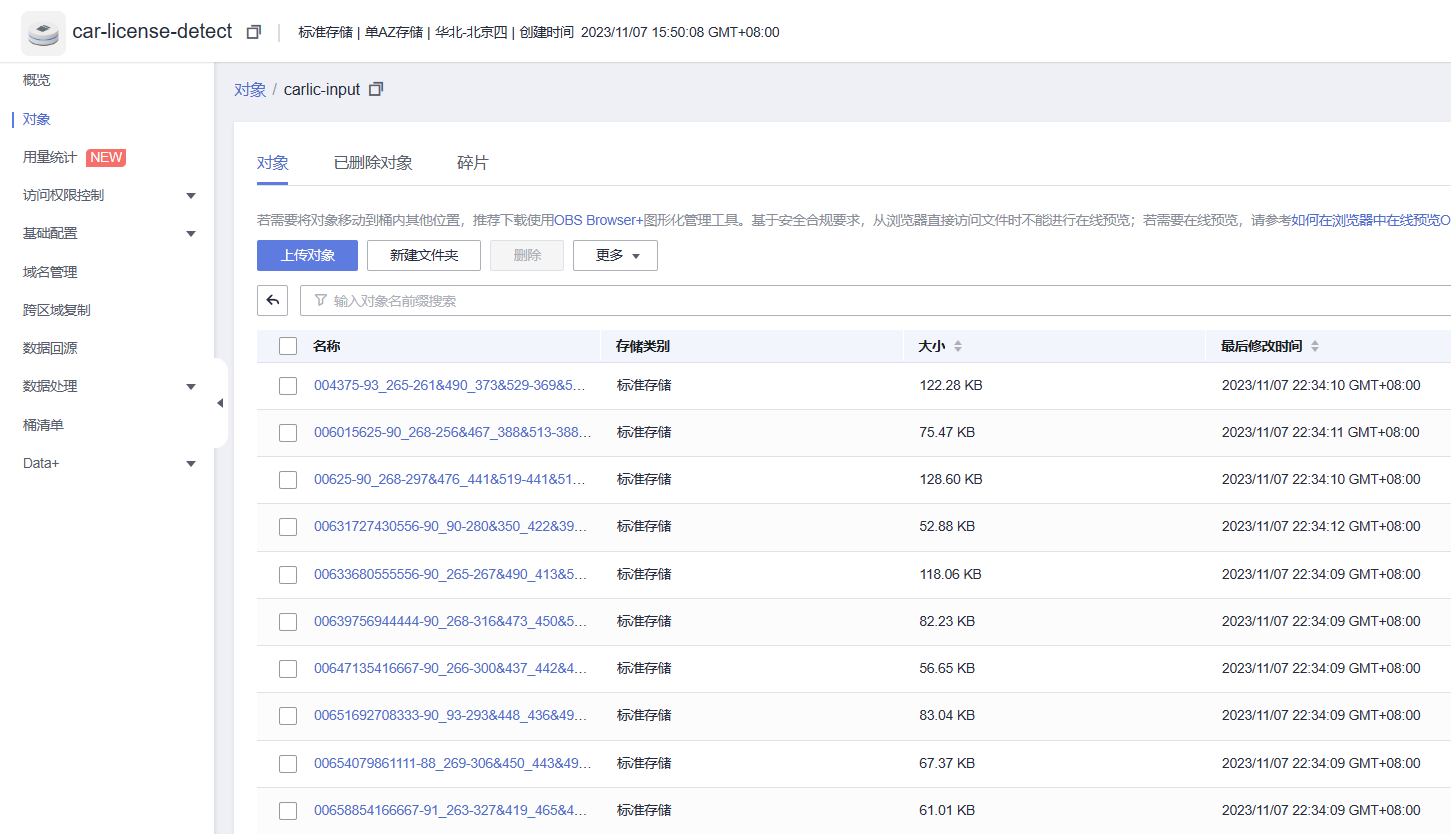
上传结束后我们再点开OBS存储,发现此时的输入文件夹已经有了所用的数据
但是此时实力详细中并没有数据信息,此时我们需要点击数据源同步,将已经上传至OBS桶中的数据全部同步至数据集中
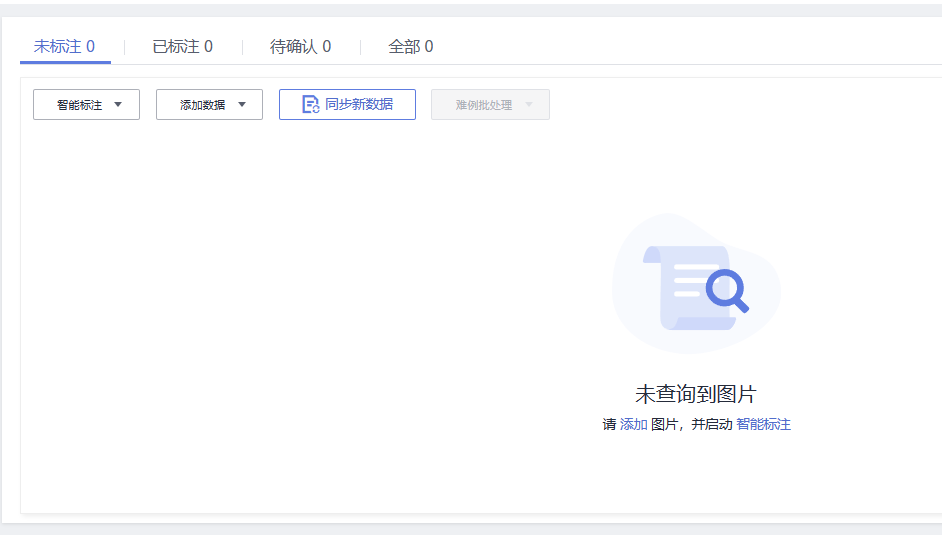
结果如下
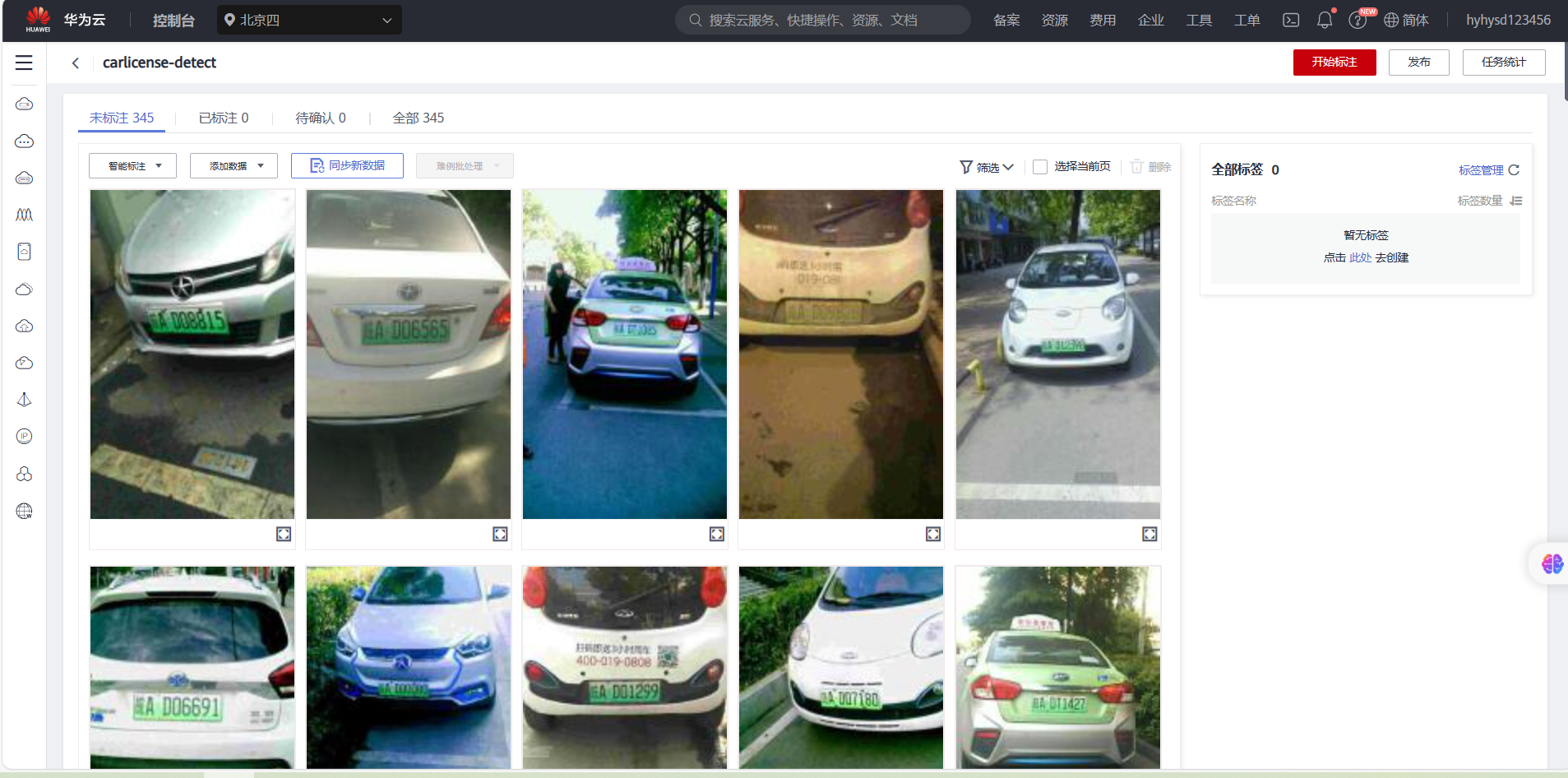
数据标注
接下来要对该数据集中的数据进行数据标注
先进行手动标注
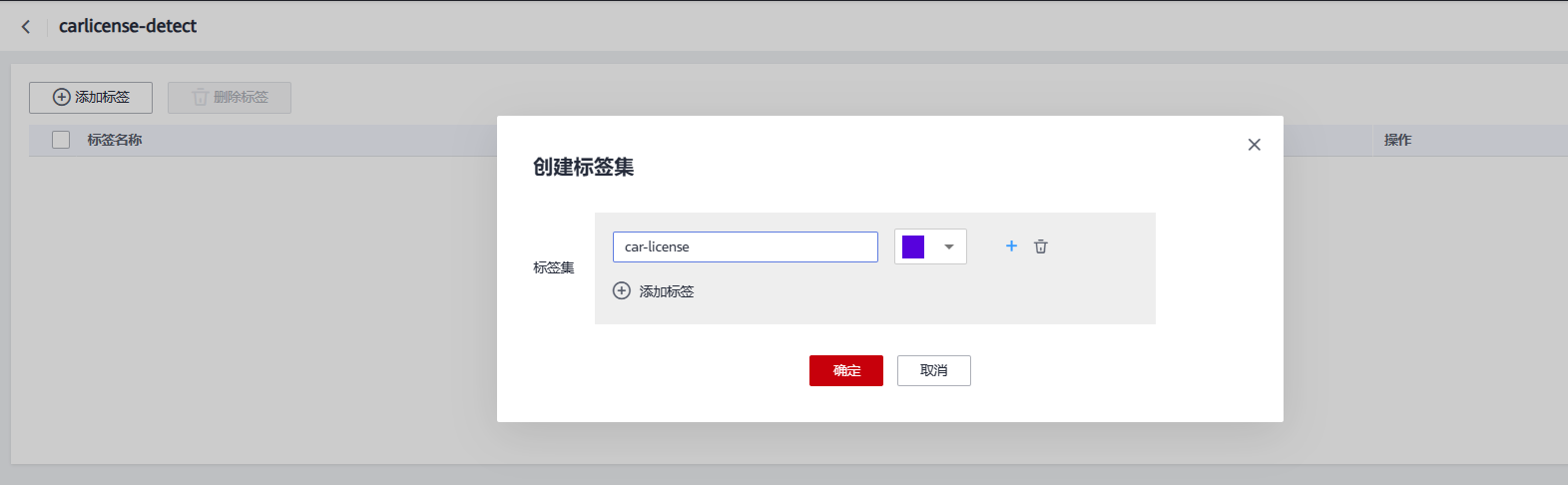
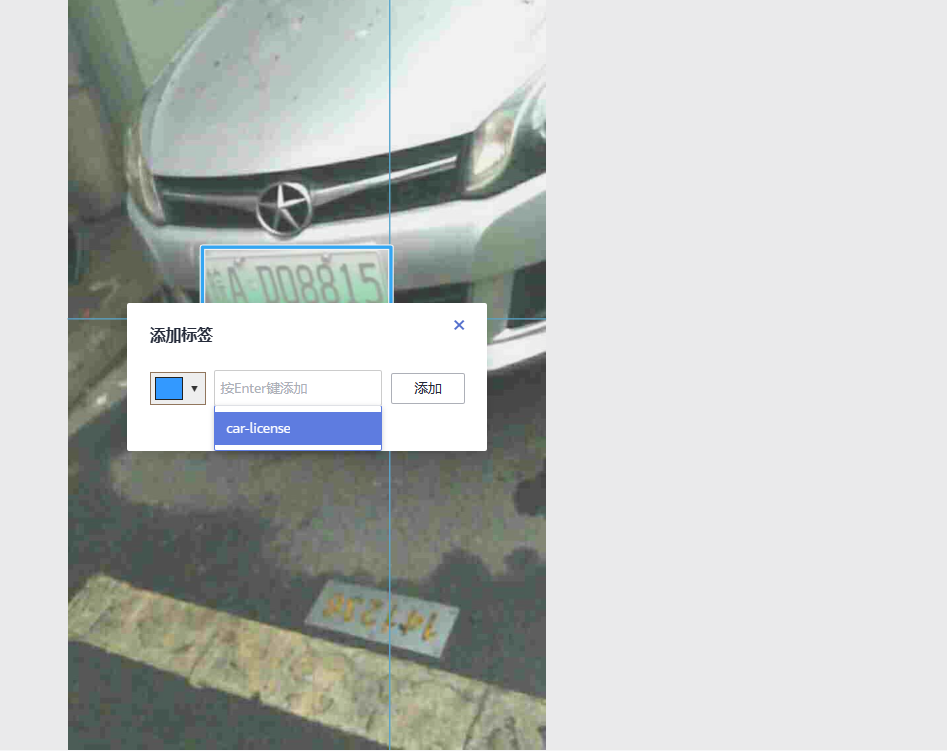

在进行20多各样例的标注后,我们可以使用ModelArts所提供的工具:智能标注,即通过已标注的样例来自动学习,实现自动化标注
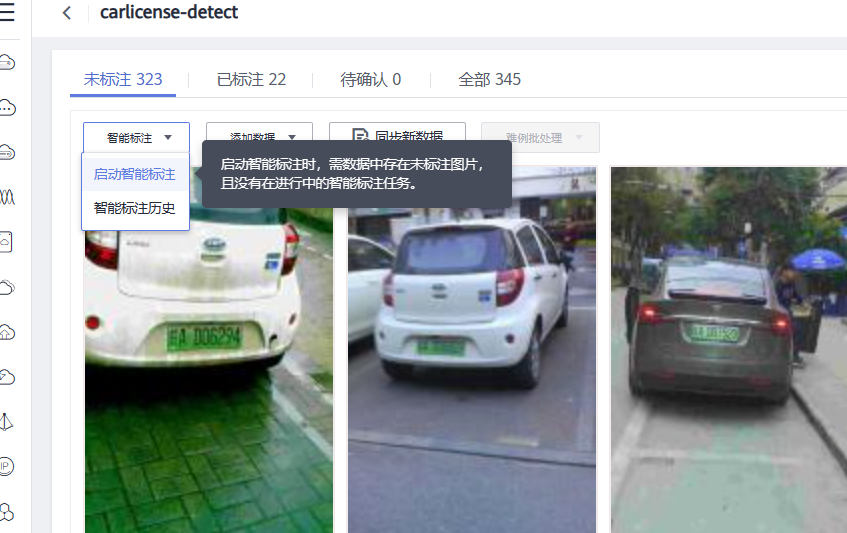
此时我们点击启动智能标注
参数选择如下:
• “智能标注类型”:主动学习(系统自动使用半监督学习,难例筛选等多种手段来进行智能标注,降低人工标注量,帮助用户找到难例)
• “算法类型”:精准型
• “计算结点规格”:任意选择即可
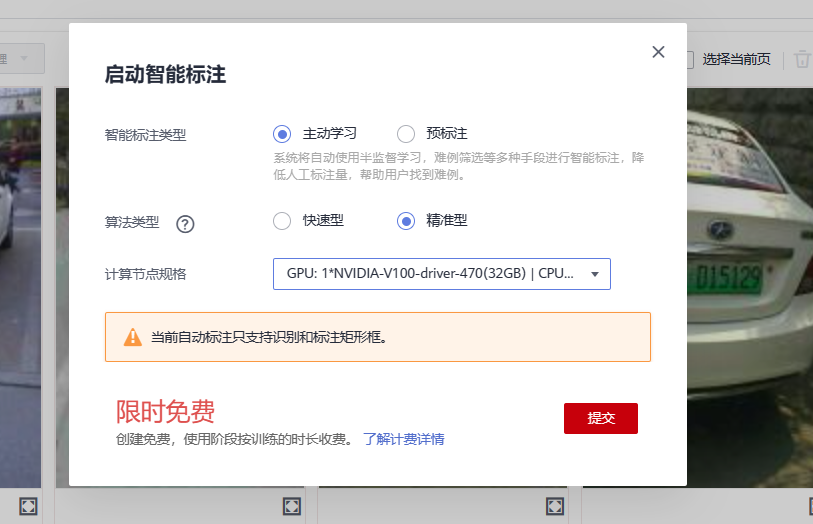
点击提交,得到如下界面
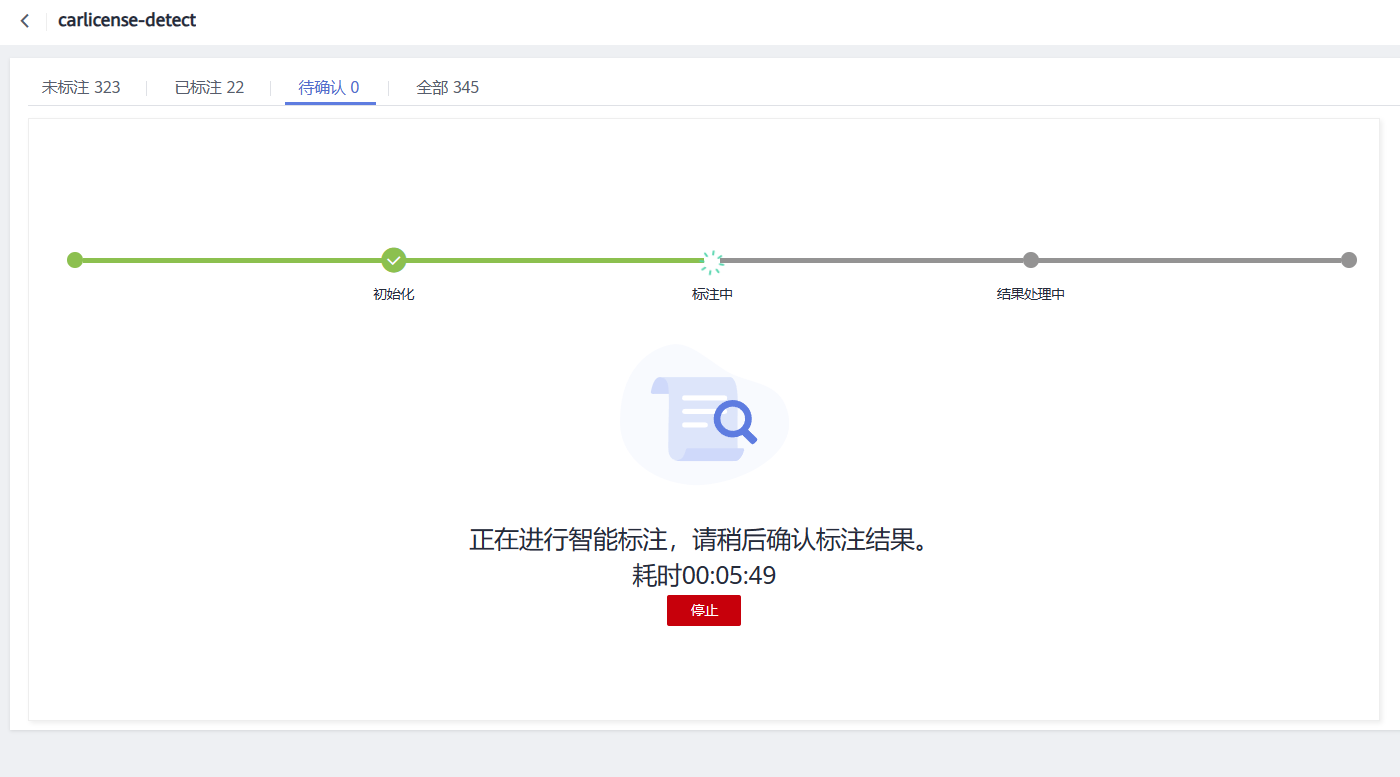
在智能标注完成后,我们需要确认智能标注信息是否正确,以下为智能标注后需要待确认的界面
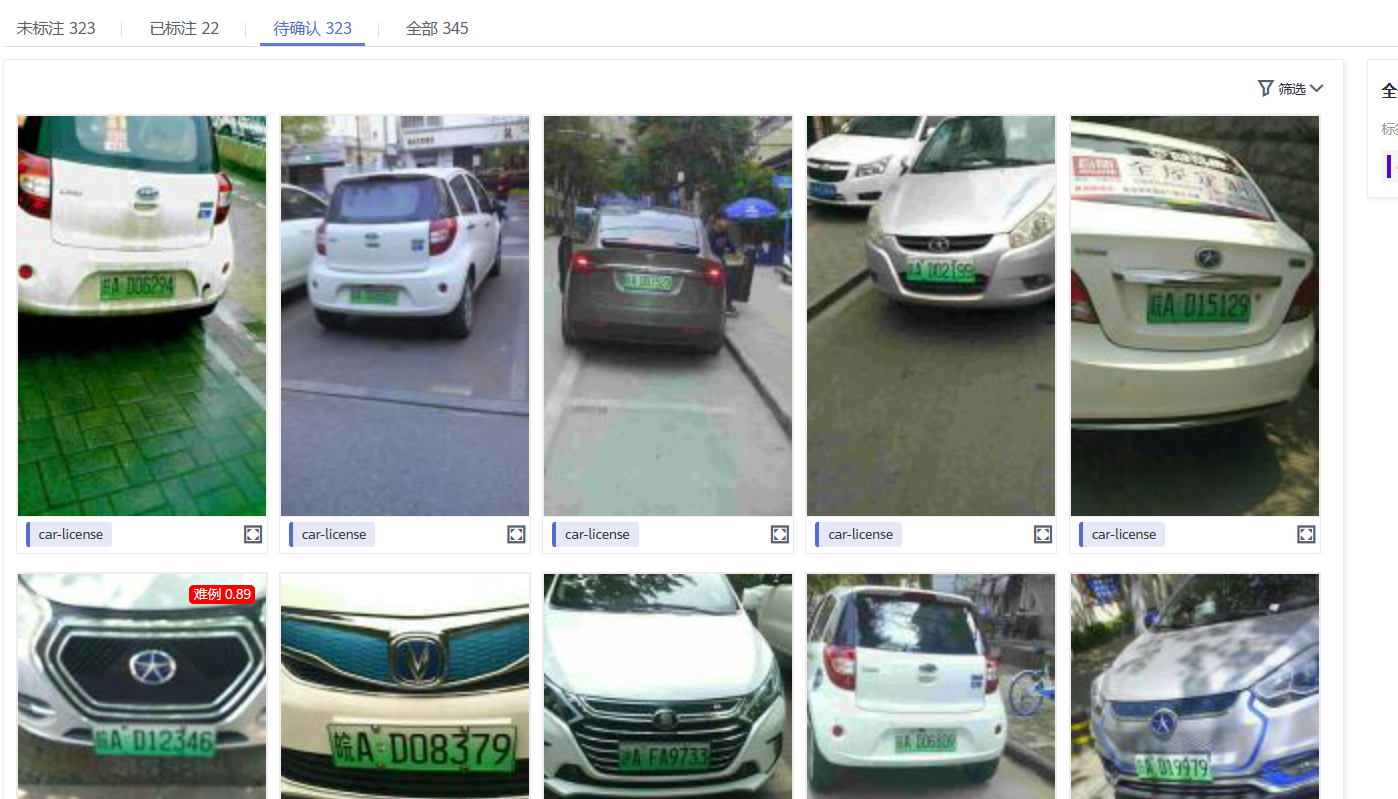
然后我们点击进入具体确认界面
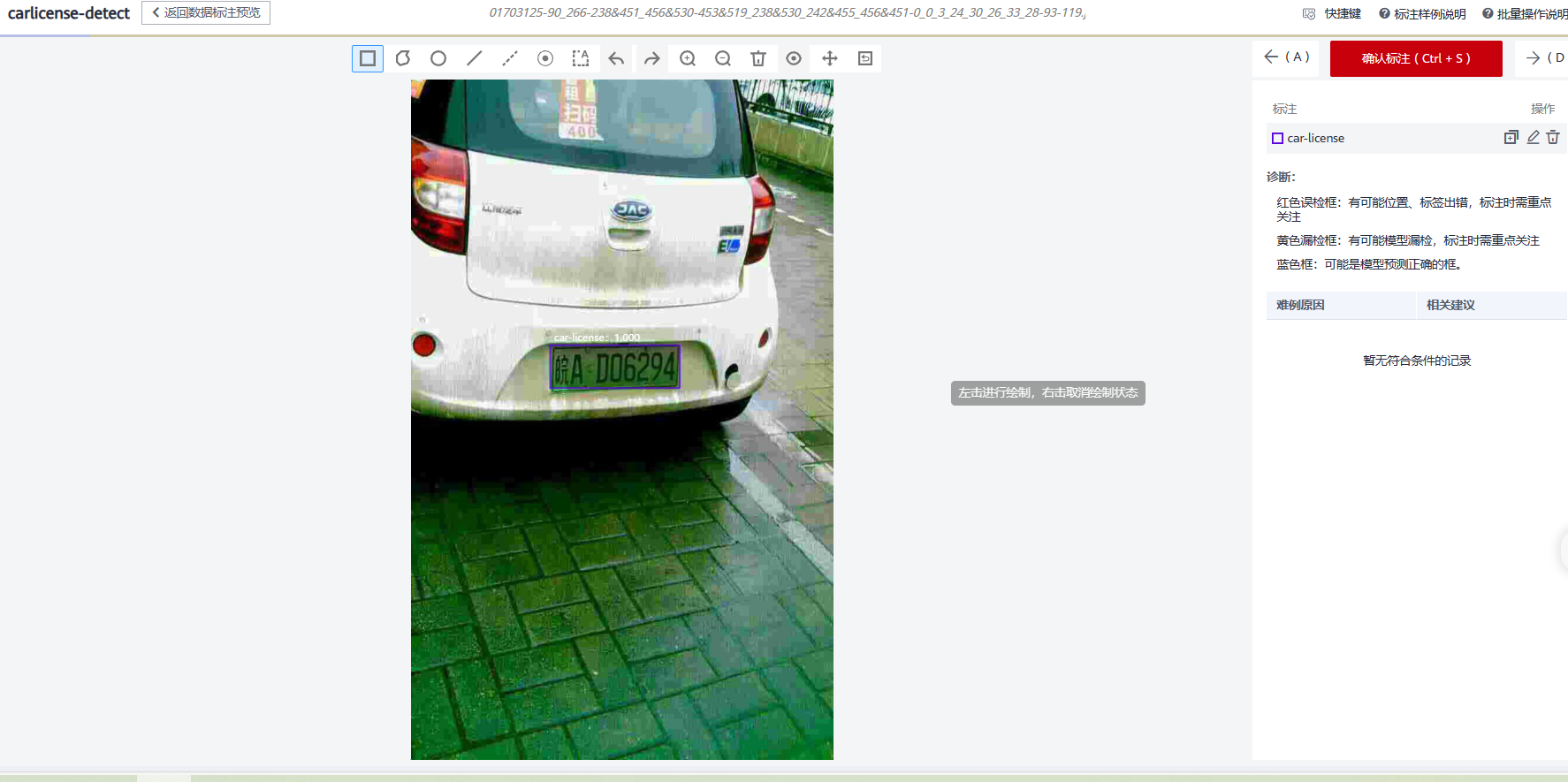
放大后查看该案例的智能标注情况

此图片中对与车牌的智能标注十分准确,但是这并不代表每一张图片都是十分准确的,在本人确认了多张图片的智能标注情况后发现一些常见的易错误标注的现象,过大的车标,车身与车牌类似的矩形广告贴,地表的一些与车牌十分相似的矩形牌号等。

过大的车标

车身矩形小广告-

地表的矩形牌号与车牌十分相似
在进行人工确认和改正后,得到最终的已标注所有的数据集
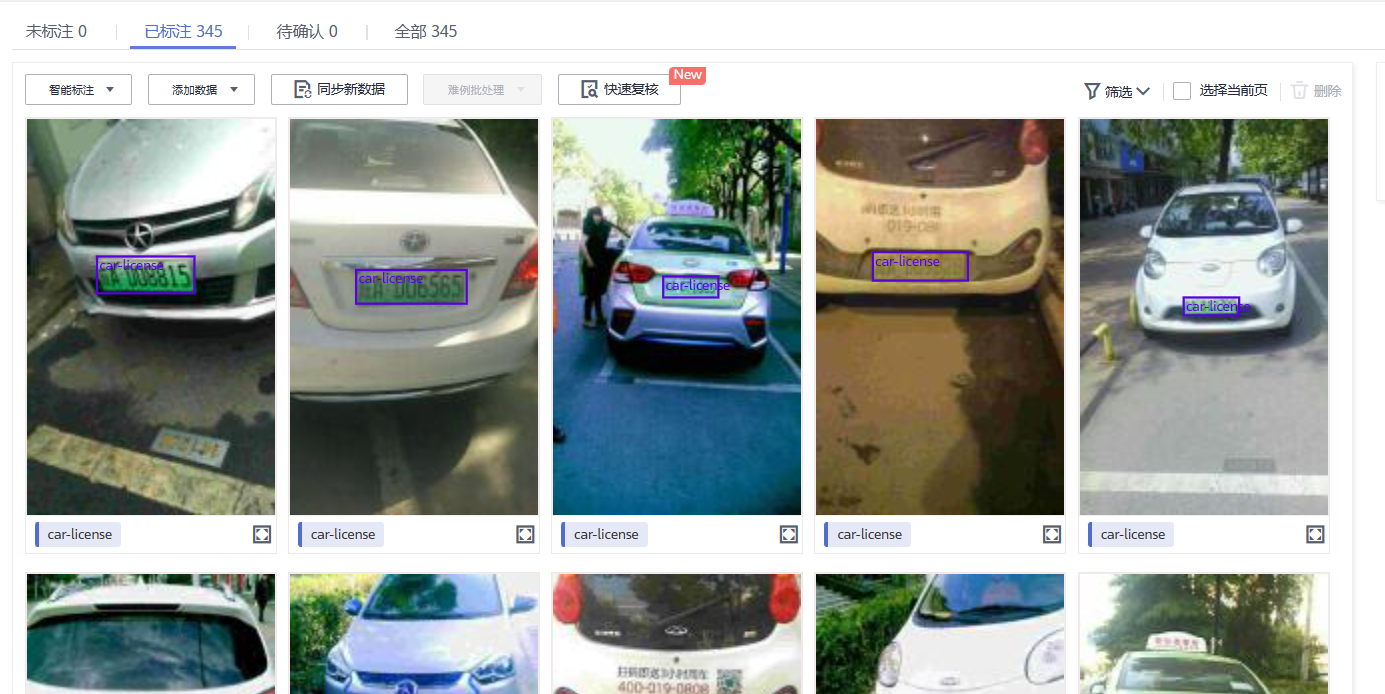
然后再进行对标注数据的快速复核,点击快速复核,得到如下界面,我们发现其中有一些明显不是车标的标注信息
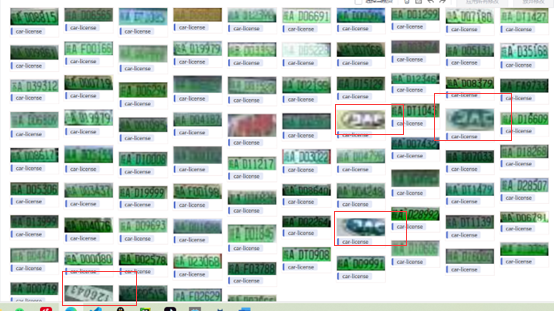
点击其中一个得到如下图片标注

说明在确认标注过程中出现了纰漏,然后只需要对这些错误标注进行修改或者删除即可
进入工作流
在成功标注完数据后,我们便可以进入workflow流中开始工作
首先是数据集版本发布
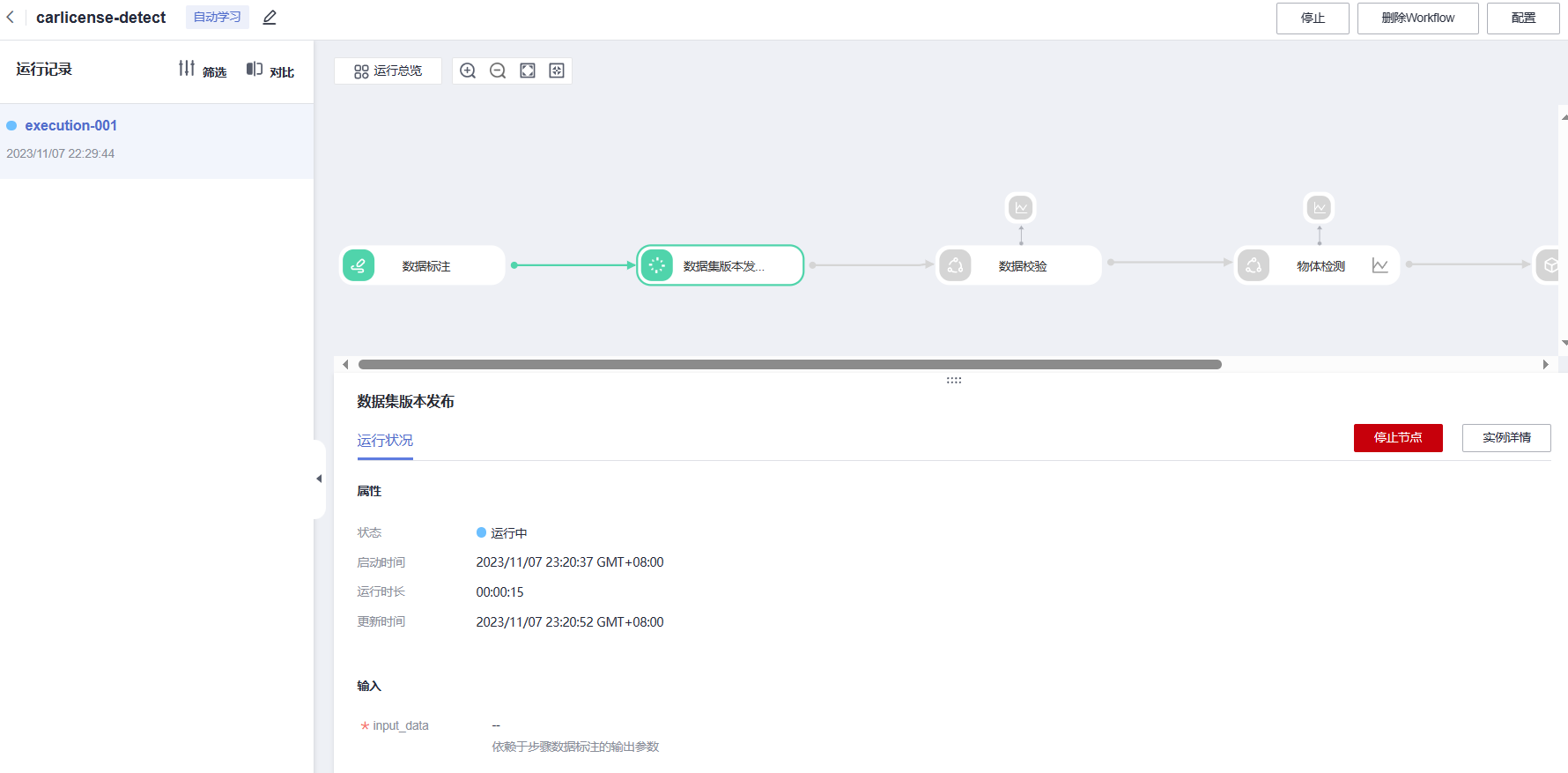
然后是数据校验
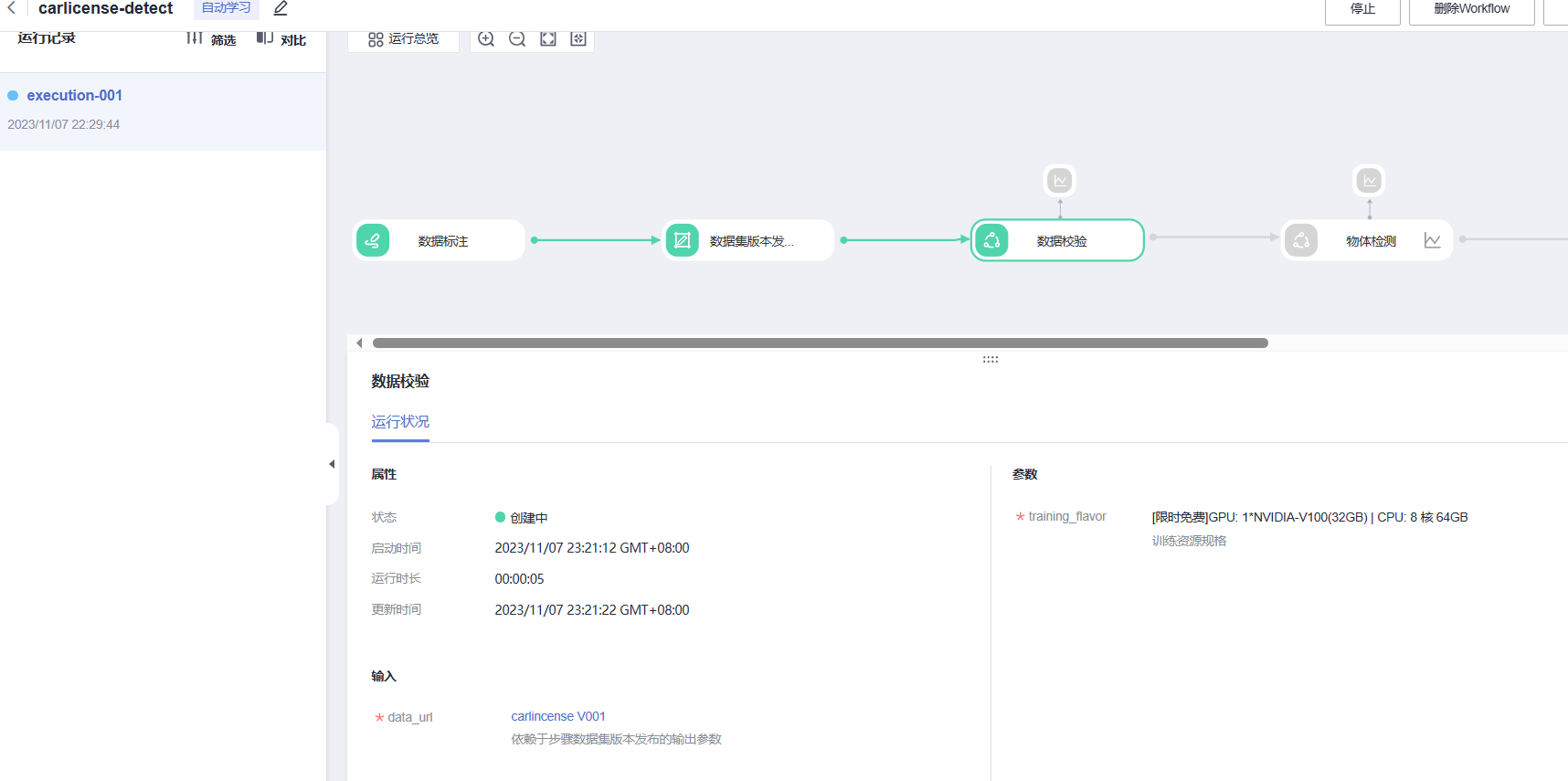
同时我们可以查看后台的工作记录,跟进工作流的进度
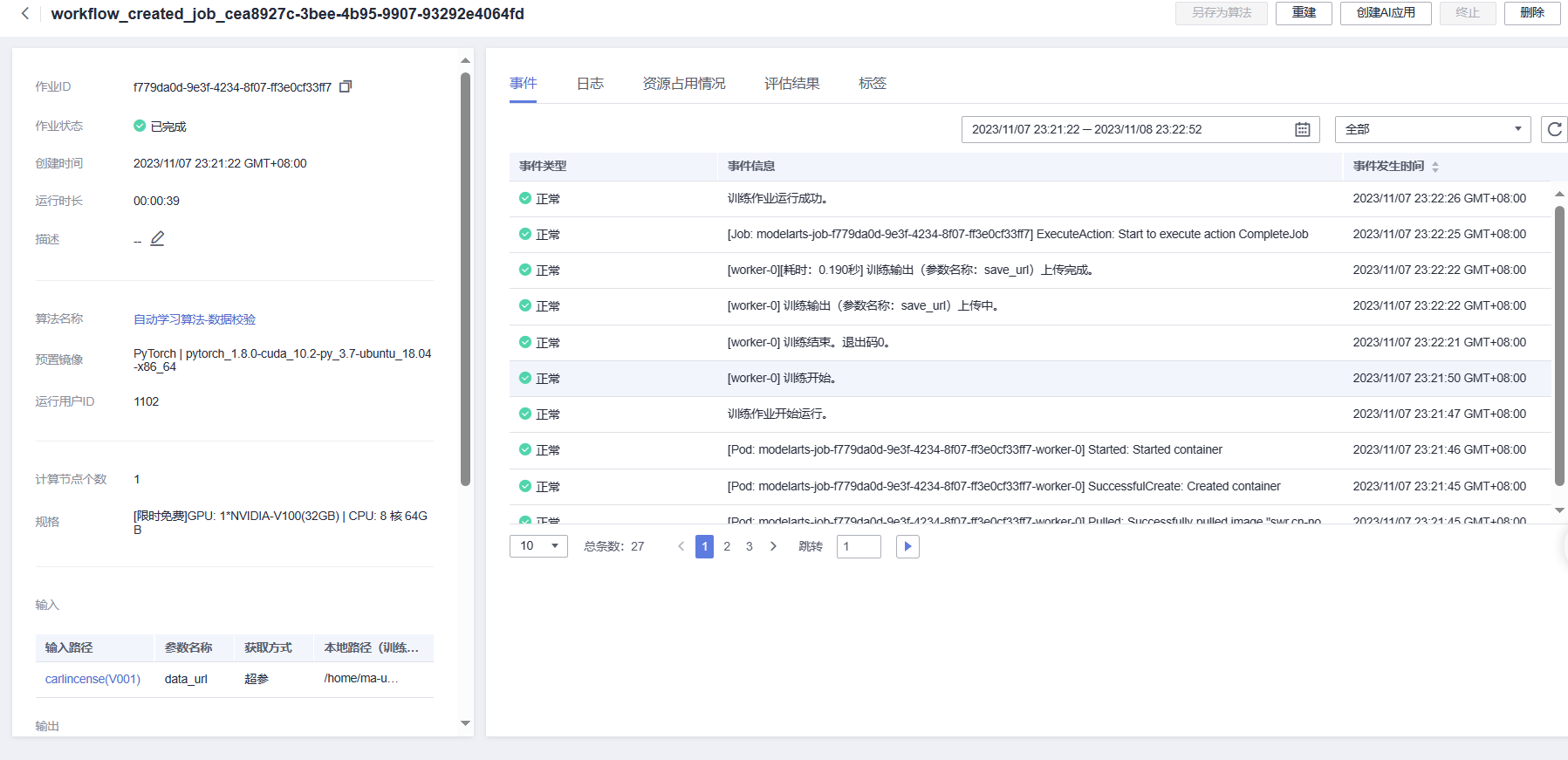
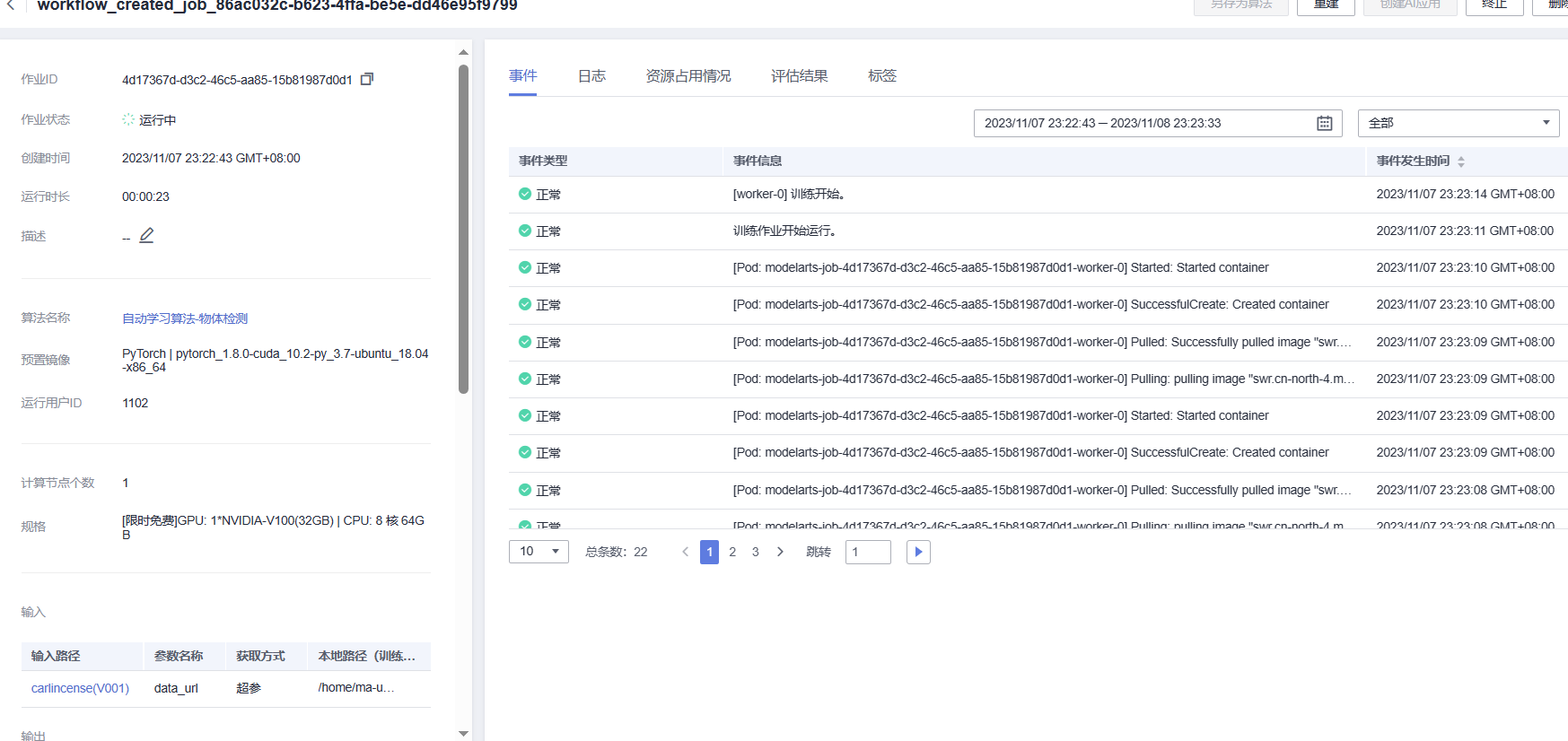
然后就是模型的训练工作
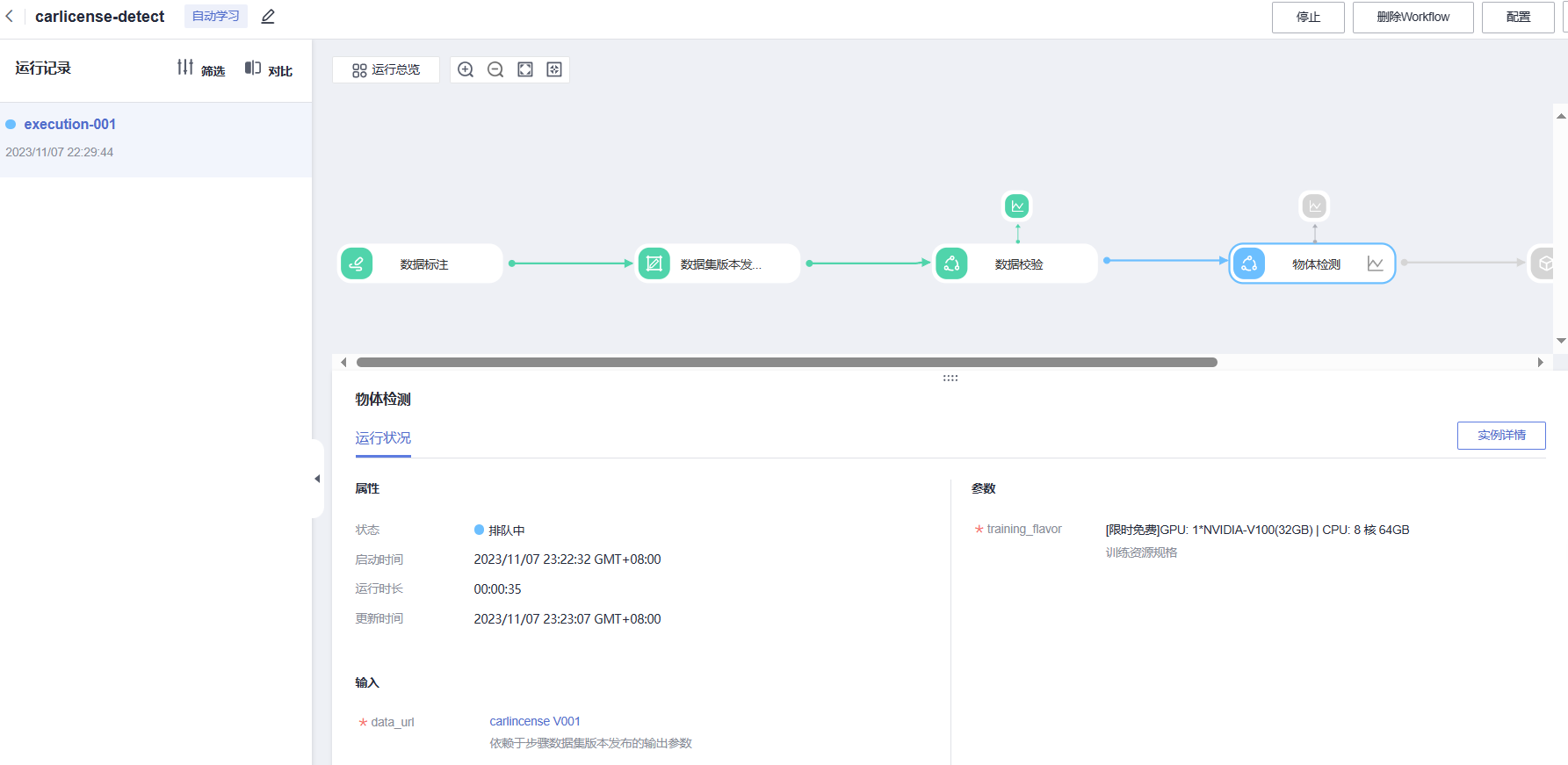
模型训练
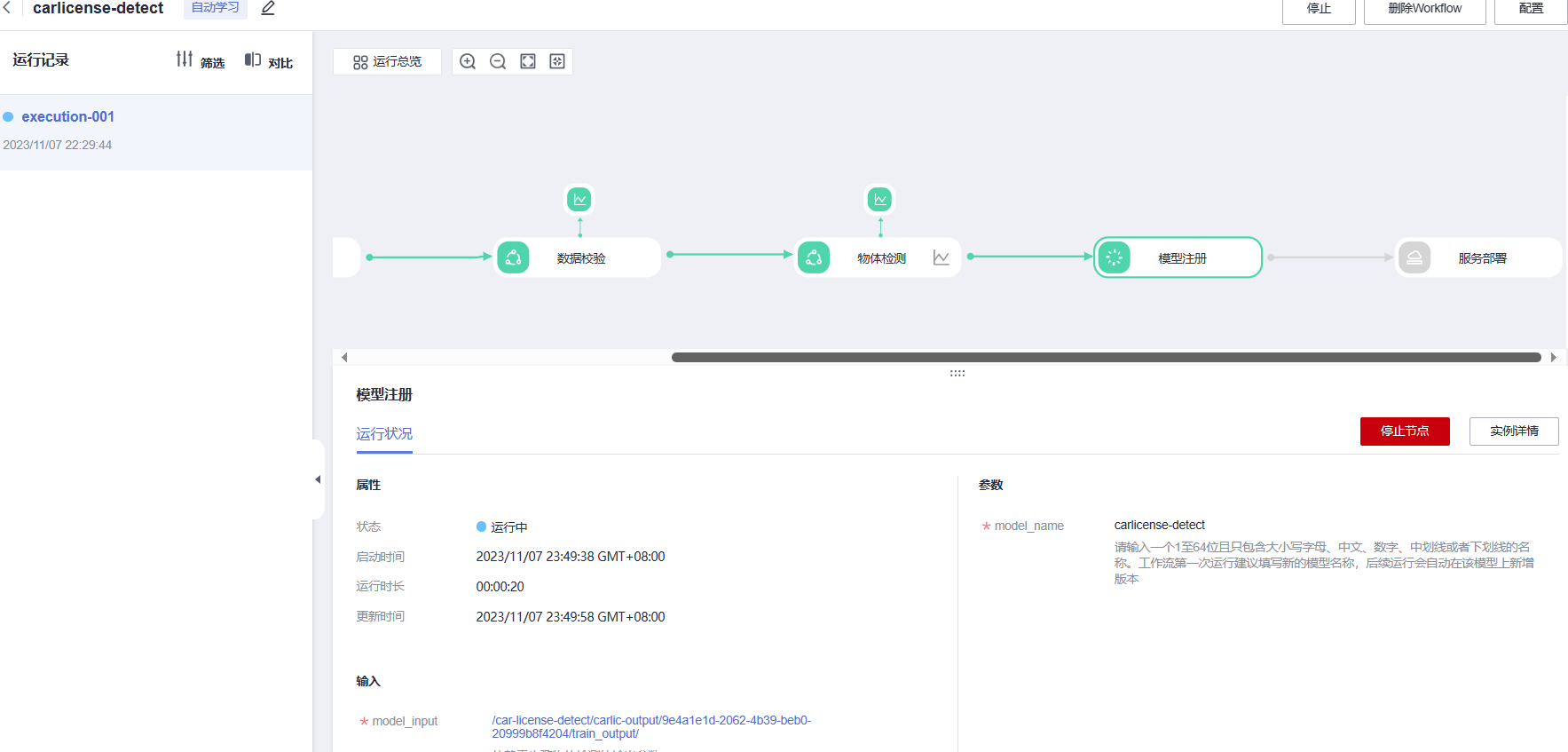
接下来是模型注册工作
模型部署
最后是模型部署工作
模型部署的参数选择如下:
• “AI应用来源”:我的AI应用
• “资源池”:公共资源池
• “是否自动停止”:是,选择在一小时后停止运行
其他参数保持默认即可
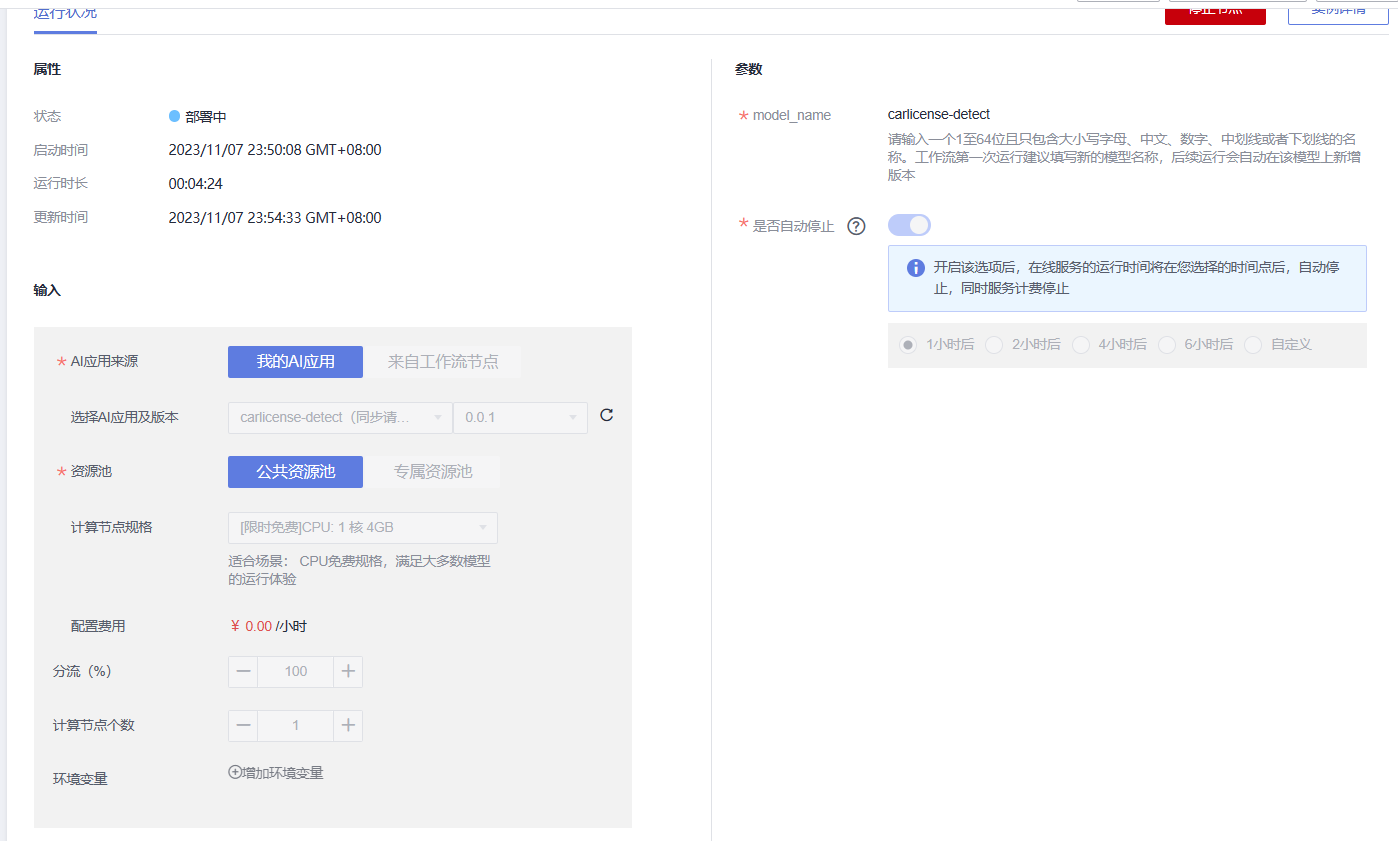
在部署过程中我们可以查看一些基本信息,同时跟踪部署情况事件:
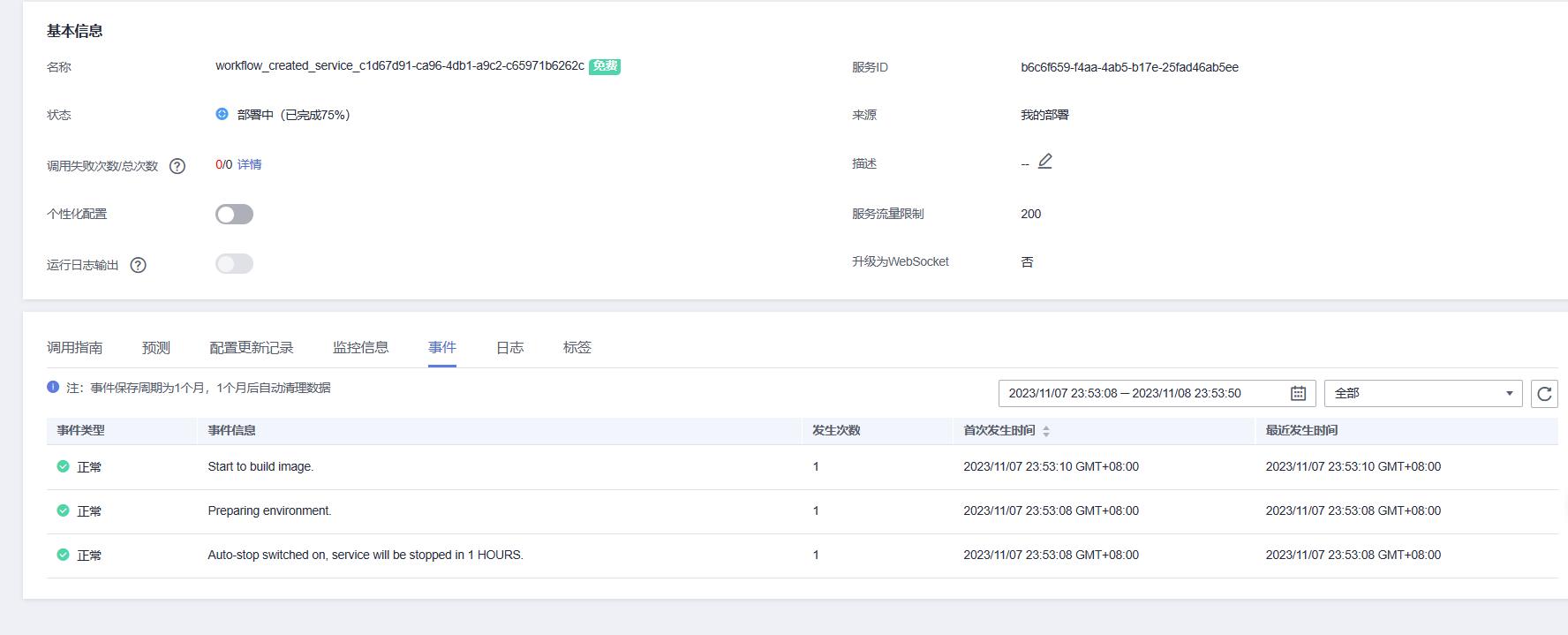
在部署成功后,我们可以查看部署成功的AI应用,部署的AI应用信息如下
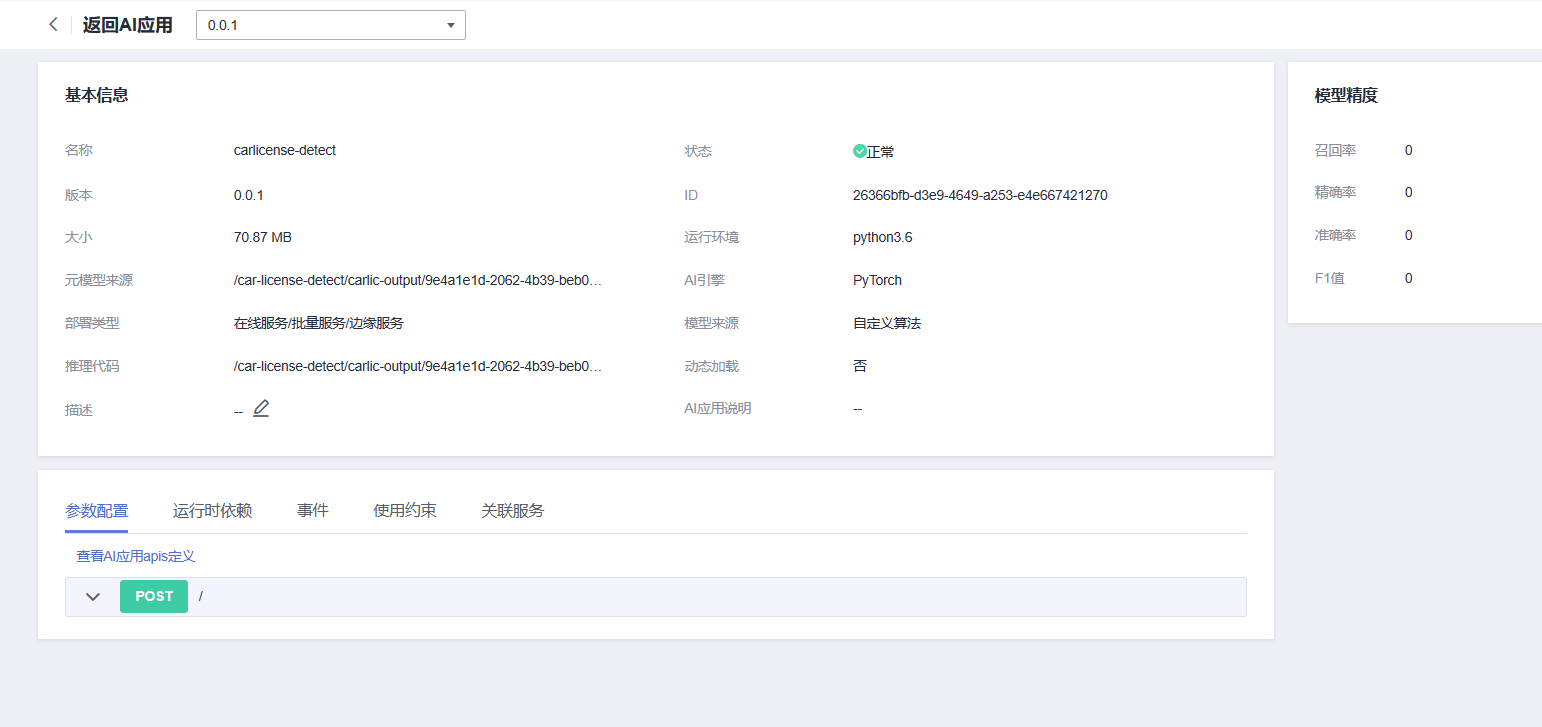
同时在该AI应用状态改变为运行中后,我们便可以开始进行我们的车辆车牌目标识别的实践了
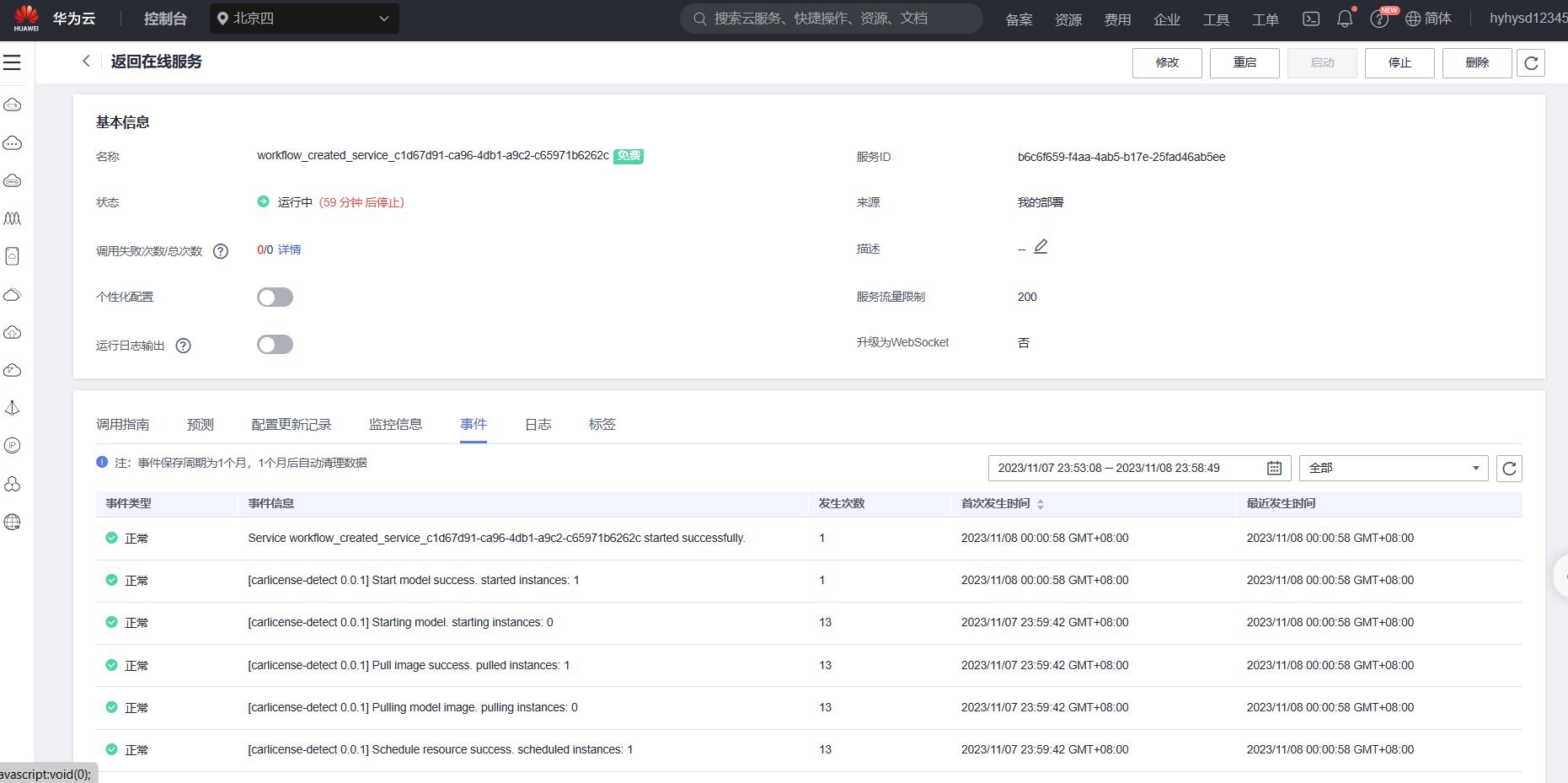
结果检测
将图片上传至该AI应用进行目标检测,得到结果如下
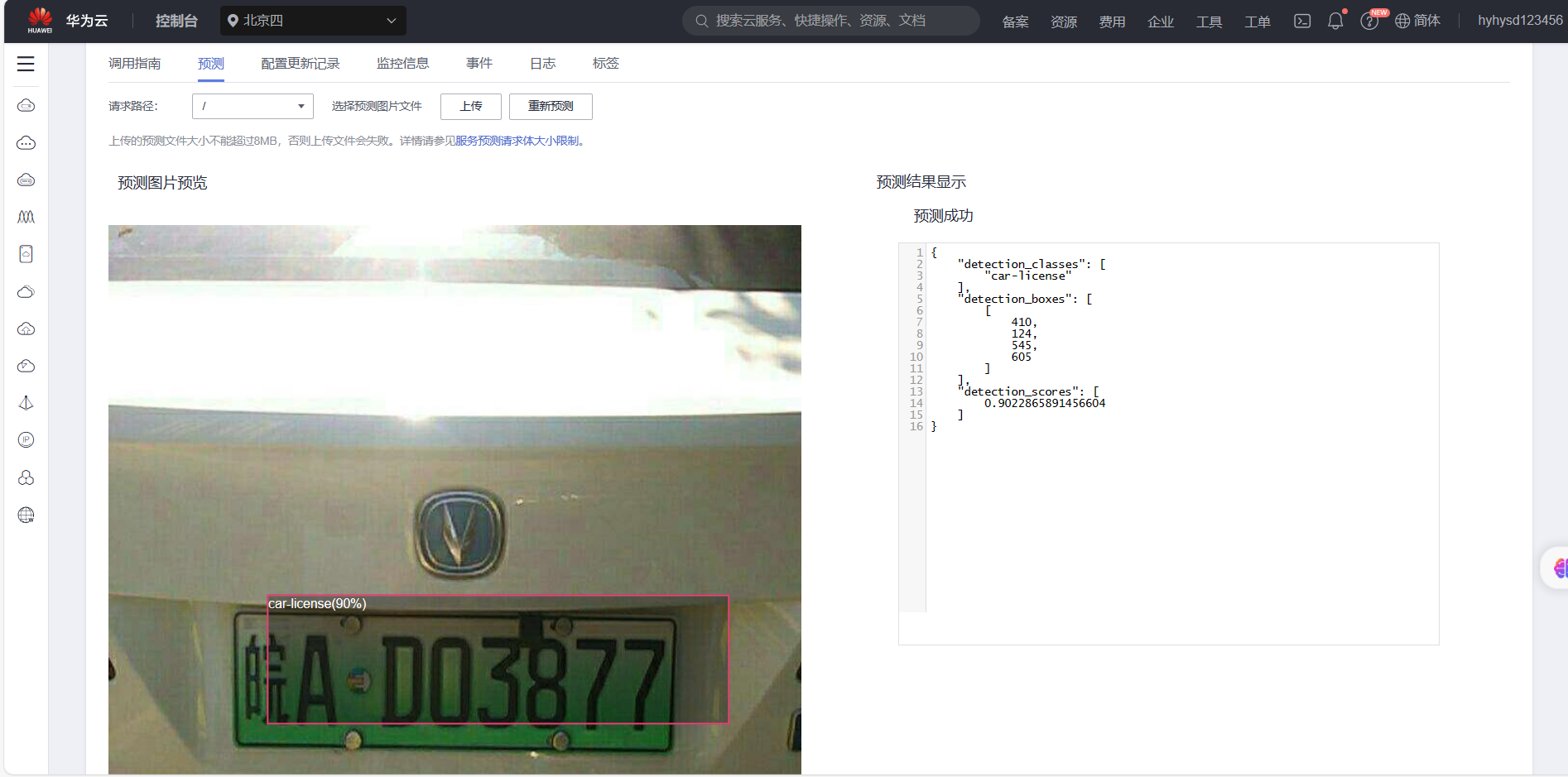
发现检测的大致位置是正确的,但是精准度不高,于是再上传图片进行几次车牌的检测:
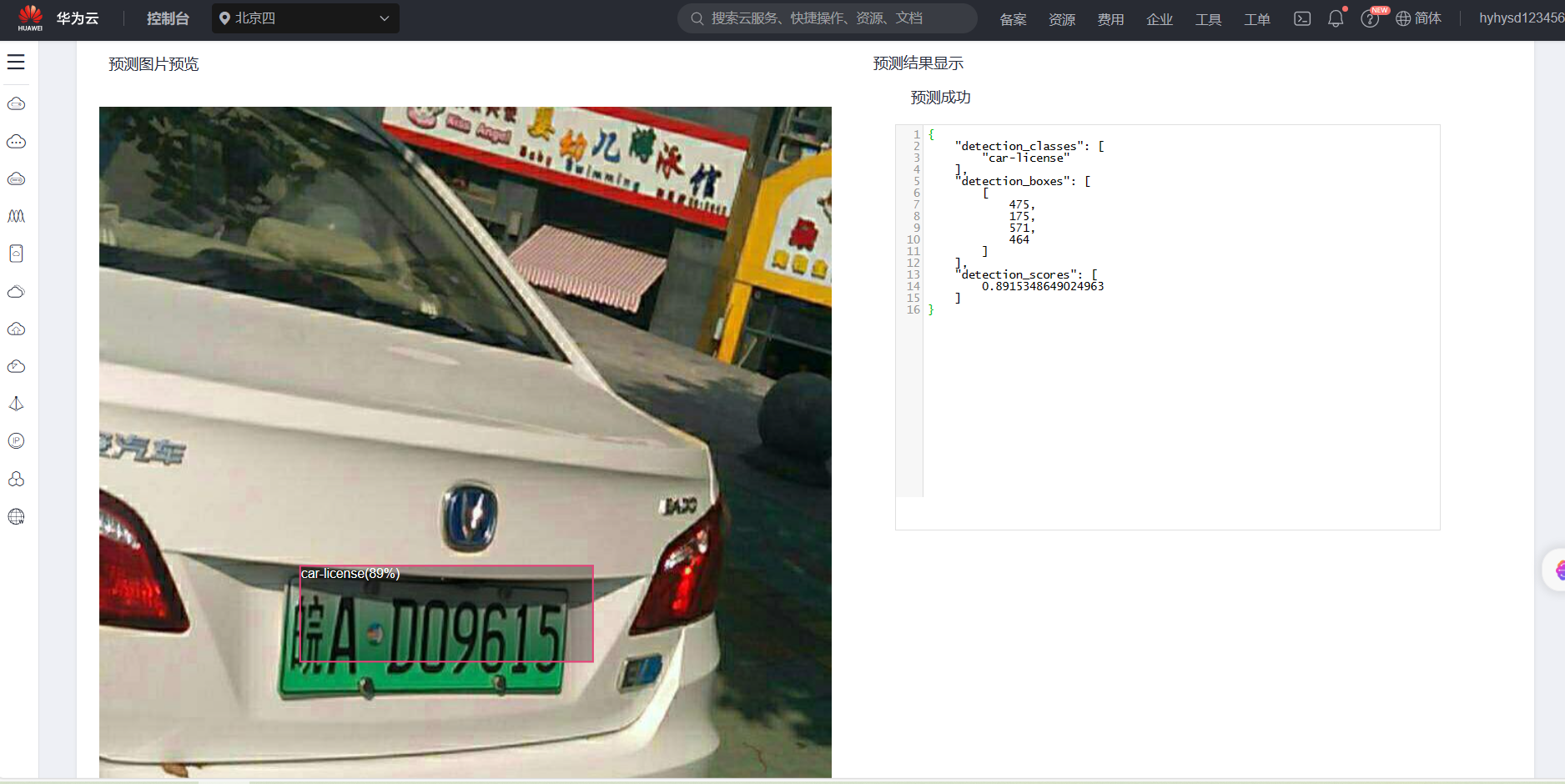
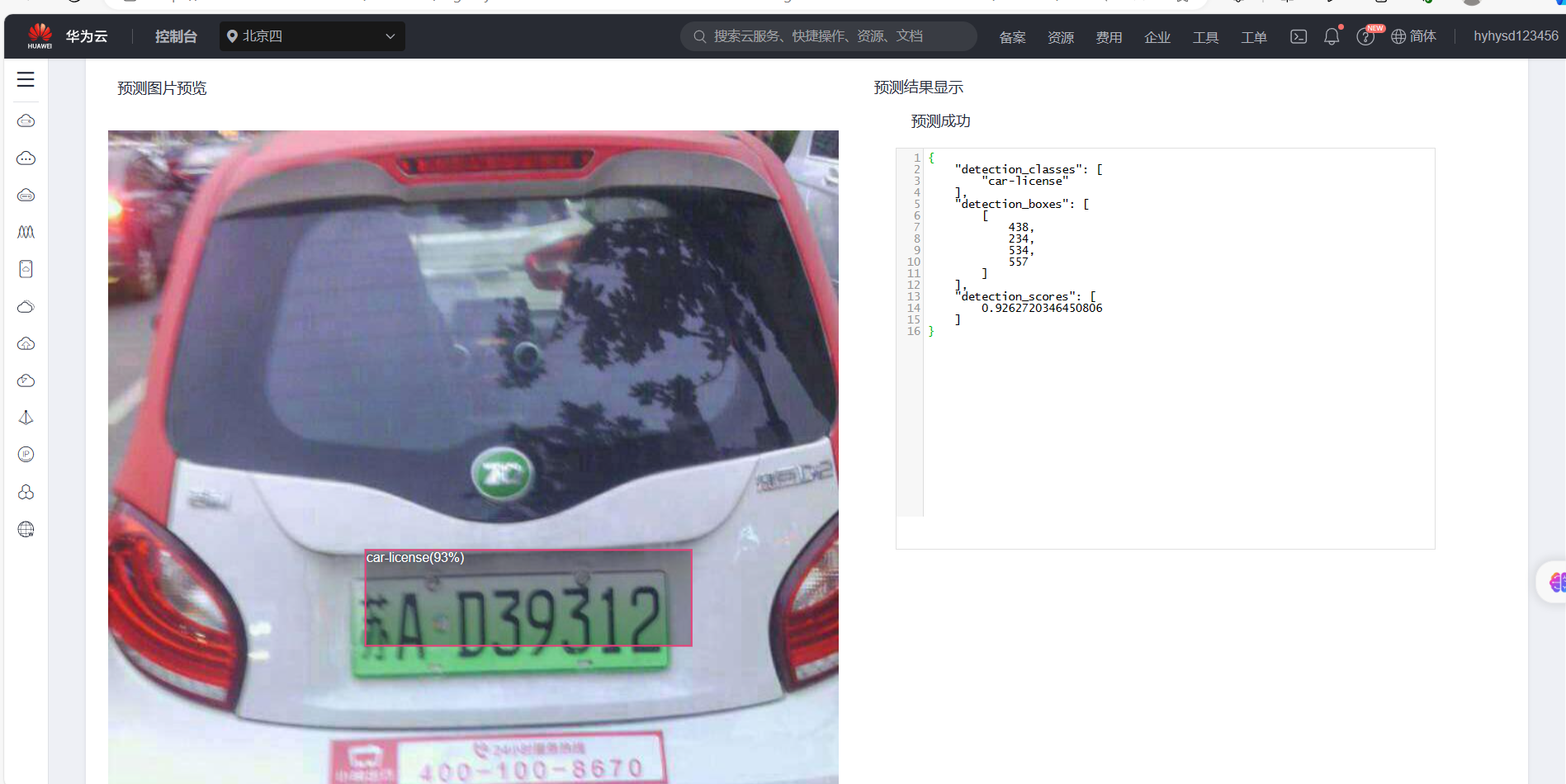
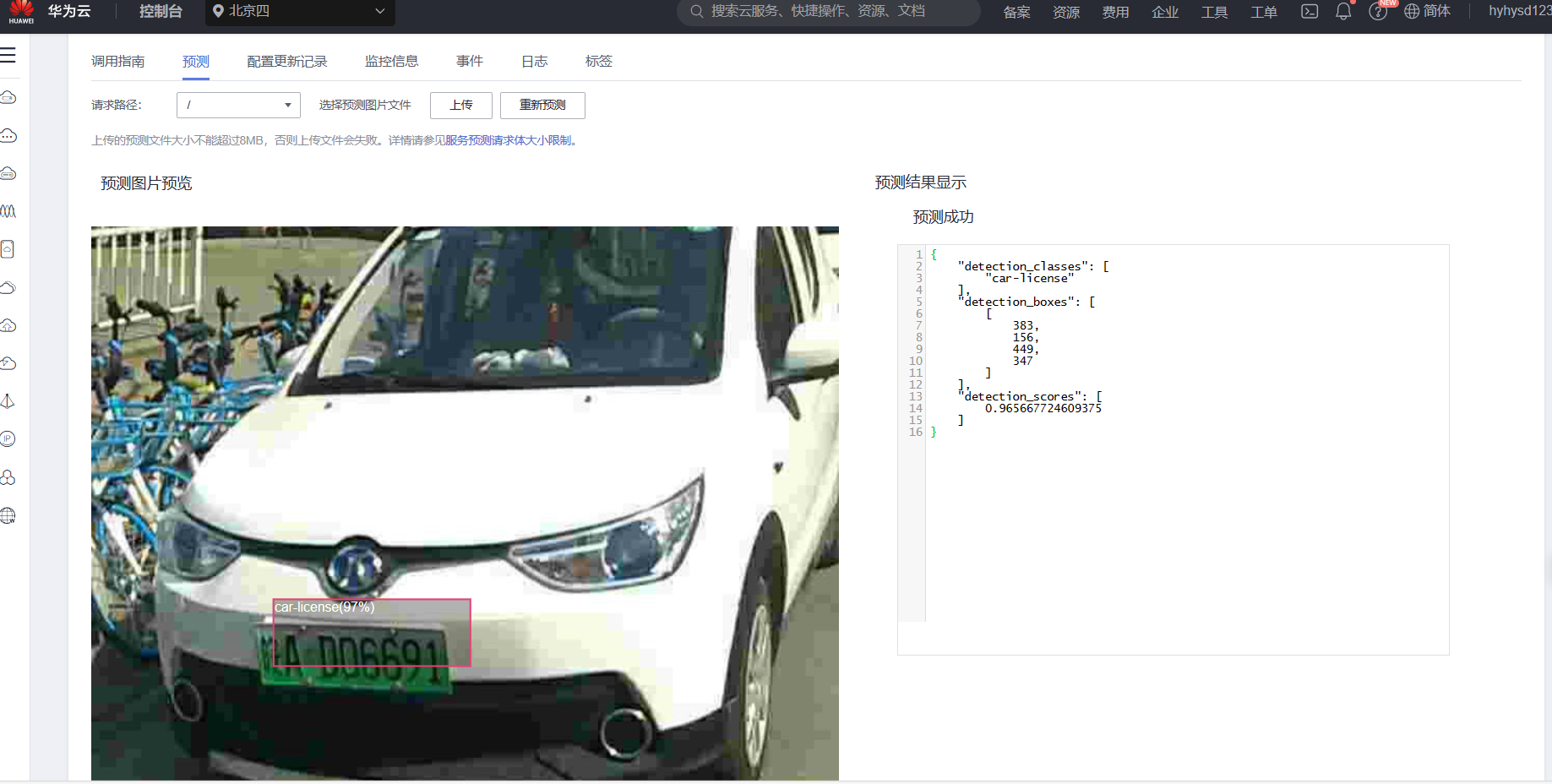
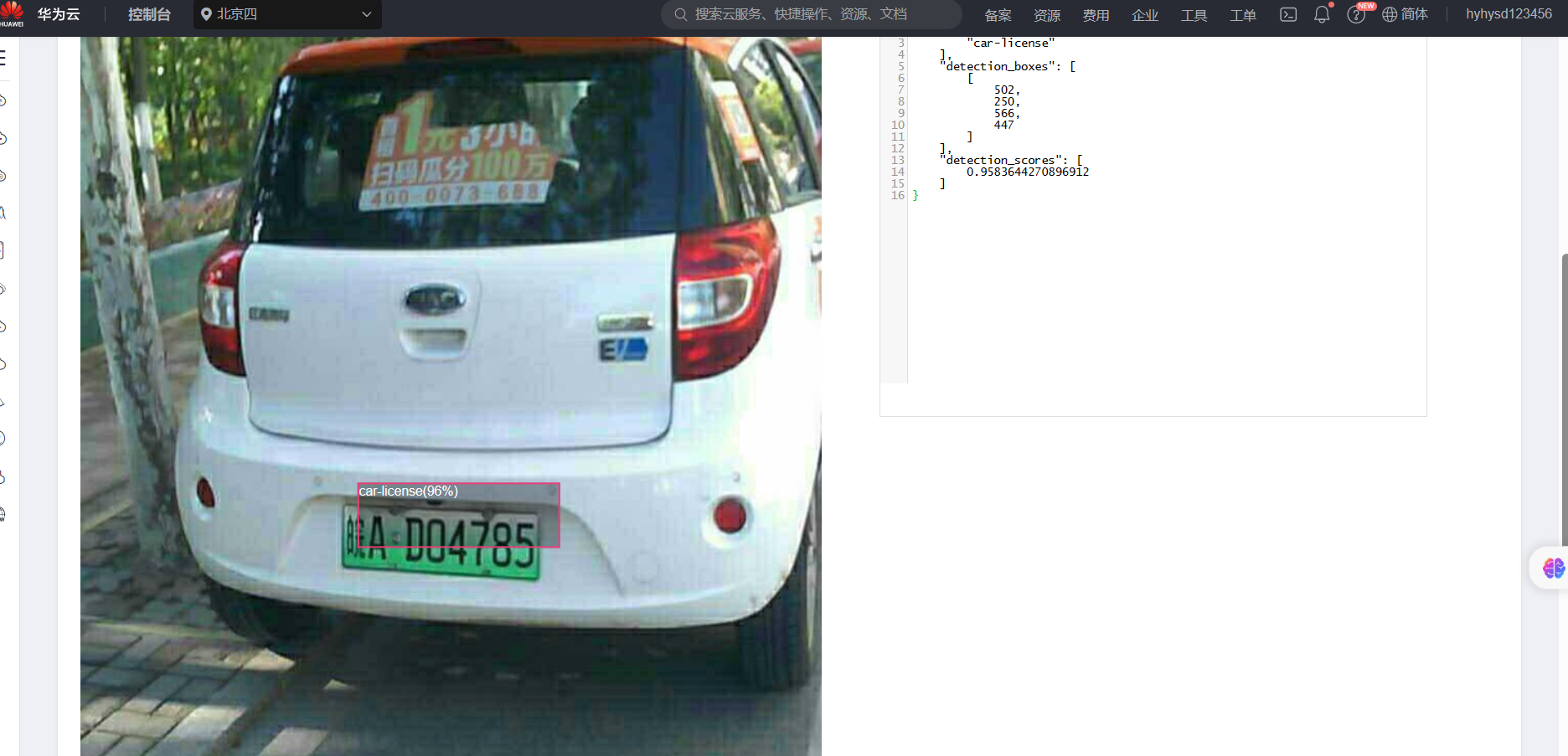
发先该模型的检测结果都是大致位置正确,但是不够精确,这说明该模型的精准度不够搞,还需要进一步改进。
对于出现该问题的原因,我猜测可能有以下几个原因:
1、数据集问题
2、数据处理算法设计和实现问题
3、算法设计和实现问题
4、超参设置问题
5、环境问题
……
在后续的实验中,会对该模型进行进一步优化,推出新的模型版本和应用版本。
资源释放
到此,该实践已完成,接下来我们需要对申请的各种资源进行释放
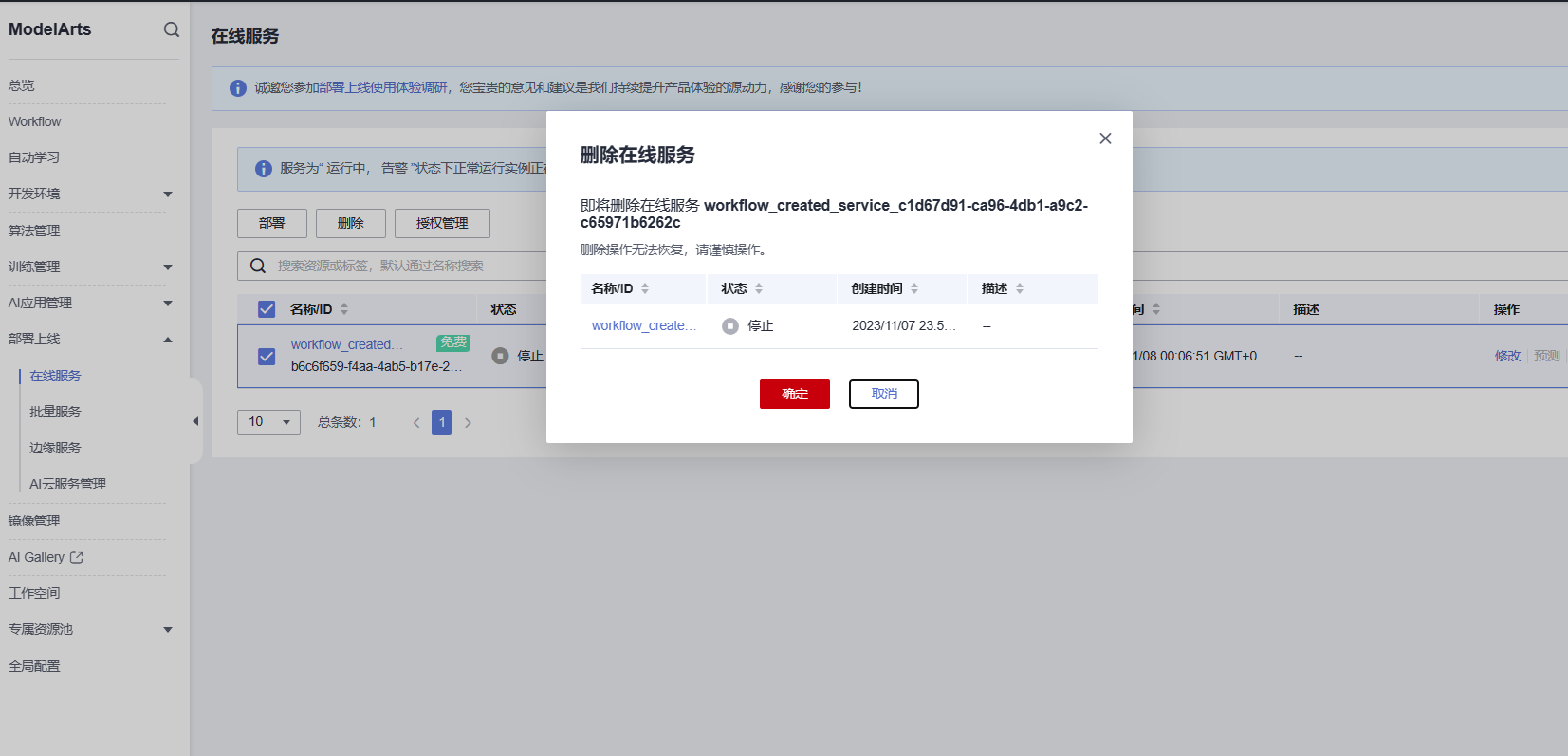
删除创建的在线服务
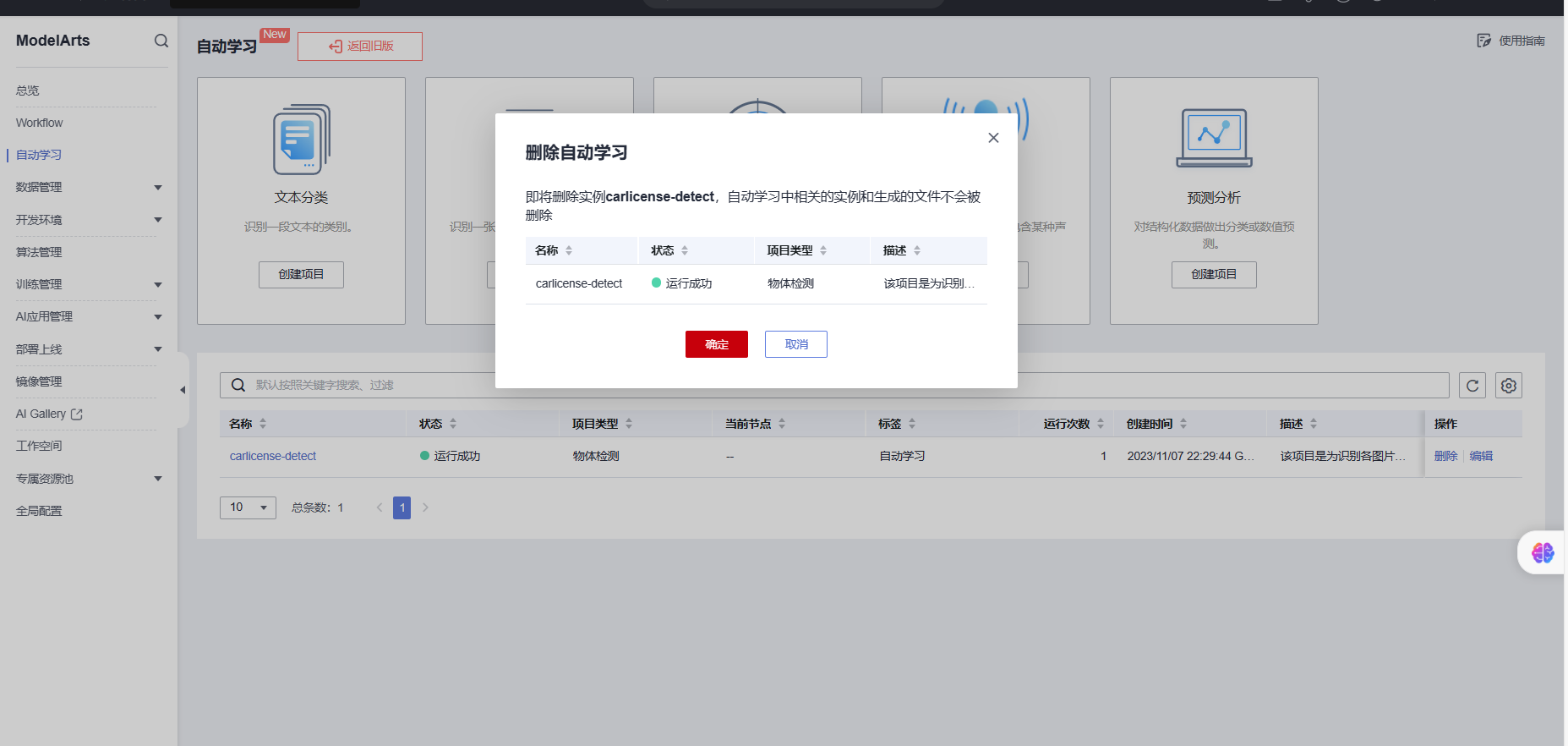
删除创建的自动学习项目
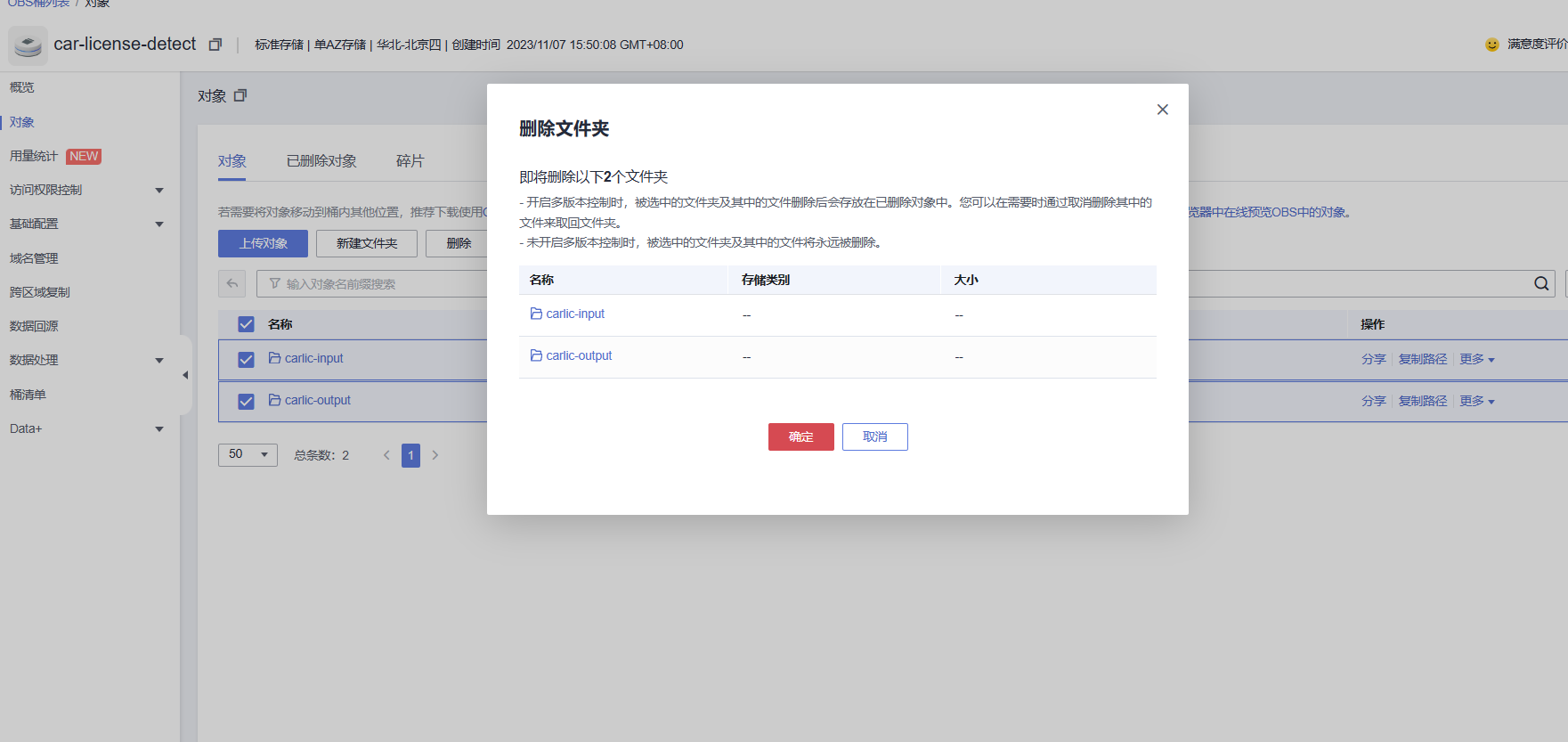
删除用于存储服务的OBS桶中的对象
释放资源到此结束,本次实践到此完成。
实践总结
在这篇文章中,我介绍了如何使用华为云技术ModelArts实现车辆车牌的目标识别的实践,并部署上线服务的过程。我首先介绍了车牌目标检测的背景和意义,然后介绍了ModelArts的特点和优势,以及如何使用ModelArts进行数据集的管理、模型的训练、评估和部署。我使用了CCPD数据集,这是一个包含了约30万张中国车牌图片的数据集,它根据图片的复杂度分为了八个类别。我使用了YOLOv5作为目标检测的模型,它是一个基于PyTorch的轻量级、高效的目标检测框架。我在ModelArts上进行了模型的训练和评估,得到了较高的精度和召回率。我还展示了如何使用ModelArts的在线服务功能,将模型部署为一个可调用的API,实现了车牌的实时检测。
通过这次实践,我深刻地体会到了ModelArts的强大和便捷。ModelArts为我提供了一个一站式的端到端的机器学习平台,让我可以在一个统一的界面上完成数据集的管理、模型的训练、评估和部署的全流程。ModelArts还提供了丰富的预置算法和模型,以及高性能的计算资源和存储空间,让我可以快速地搭建和运行我的模型,节省了时间和成本。ModelArts的在线服务功能也让我可以轻松地将我的模型转化为一个可用的服务,实现了车牌目标检测的应用场景。我认为ModelArts是一个非常适合机器学习爱好者和开发者的平台,它可以帮助我们实现更多的机器学习的创新和价值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号